上一章我们主要讲搜索引擎和LLM的应用设计,这一章我们来唠唠大模型和DB数据库之间的交互方案。有很多数据平台已经接入,可以先去玩玩再来看下面的实现方案,推荐
- [sql translate]:简单,文本到SQL,SQL到文本双向翻译,新手体验
- [ai2sql]:功能更全,包括语法检查,格式化等
- [chat2query]:可处理复杂query和实时数据
- [OuterBase]:加入电子表格的交互和可视化模块
本章会提到的前置知识点有Chain-of-thought,Least-to-Most Prompt,Self-Consistency Prompt
DB Agent设计
和数据库进行交互的应用设计,主要涉及以下几个子模块
- Decomposition:把SQL生成任务,拆分成先定位表,再定位表字段,最后基于以上信息生成SQL的多个子问题,降低每一步的任务难度,和上文输入的长度
- Schema Linking:数据表较多的数据库,不能一次性把所有表schema都作为上文输入,需要先针对问题筛选相关的数据表和相关字段
- Schema description:如何描述Table和Column让模型更好理解每张表是做什么的,每个字段有哪些含义。以及在真实世界中庞大数据库中的表字段往往存在很多噪音,甚至需要领域知识,和详细字段描述才能明确每张表每个字段究竟是做什么的。
- self-correction:对SQL执行结果,或者代码本身进行自我修正,提高SQL语句准确率
下面我们分别基于C3, DIN-SQL, SQL-PALM,BIRD这四篇论文了解DB应用中可以提升SQL生成效果的各个子模块,前三篇都是基于传统的Spider数据集,BIRD则提出了全新的难度更高更符合真实世界应用的新基准A Big Bench for Large-Scale Database Grounded Text-to-SQLs
DIN-SQL
- DIN-SQL: Decomposed In-Context Learning of Text-to-SQL with Self-Correction
- Spider Benchmark的SOTA模型,提出了问题分解的NL2SQL范式
>
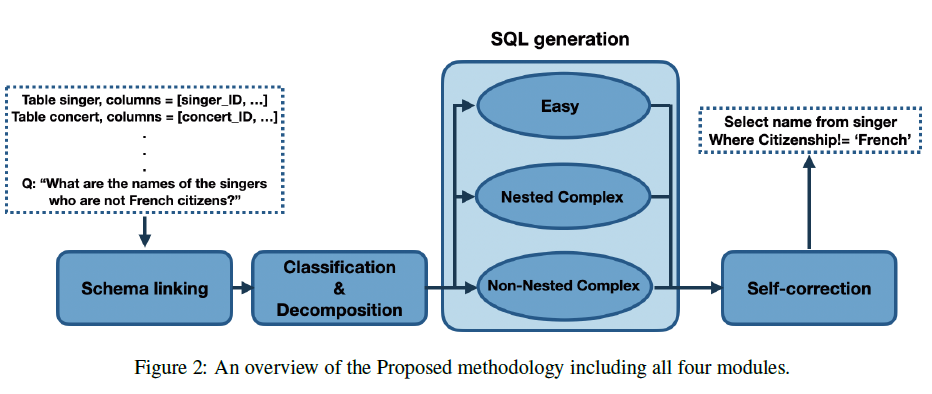
DIN-SQL是当前Spider榜单上的榜一大哥。走的是子问题拆解的方案,把SQL生成的任务像思维链一样拆解成几个固定的任务,串联执行,主要包含以下4个模块
1. Schema Linking
方案是用10-Shot Prompt + zero-shot COT的引导词(Let’s think Step by Step),让模型逐步思考给出针对用户问题,应该查询的表,以及表中需要查询的字段,过滤条件字段,和Join条件字段。
Schema Link的输出会作为后续SQL生成任务的输入,帮助模型先定位字段,再编写SQL。Prompt如下

2. Classification
把用户的提问按查询的难易程度分成以下3类
- easy:单表查询
- medium:允许多表Join,但是没有嵌套查询
- hard:多表Join + 嵌套查询
之所以要进行难易程度划分,其实是后面sql生成部分,每种难度使用了不同的In-Context Few-shot和prompt指令。
3. SQL Generation
对应以上的3种分类,论文采用的3种few-shot-prompt如下
- easy:直接使用指令+表结构+ schema Link + few-shot

- Medium:表结构和schema Link同上,指令加入了zero-shot的思维链激活,思维链每一步对应SQL sub query。But这里有些奇怪的是论文中Medium部分的few-shot很多也是单表查询不需要join的,困惑脸…

- Hard: few-shot是加入多表查询和嵌套结构的样例

4. Self Correction
论文的自修正并未引入SQL执行,只针对SQL本身,修复一些小的语法错误,例如缺少DESC,DISTINCT等,通过zero-shot指令来让模型对生成的SQL直接进行修正。指令如下
instruction = """#### For the given question, use the provided tables, columns, foreign keys, and primary keys to fix the given SQLite SQL QUERY for any issues. If there are any problems, fix them. If there are no issues, return the SQLite SQL QUERY as is.
#### Use the following instructions for fixing the SQL QUERY:
1) Use the database values that are explicitly mentioned in the question.
2) Pay attention to the columns that are used for the JOIN by using the Foreign_keys.
3) Use DESC and DISTINCT when needed.
4) Pay attention to the columns that are used for the GROUP BY statement.
5) Pay attention to the columns that are used for the SELECT statement.
6) Only change the GROUP BY clause when necessary (Avoid redundant columns in GROUP BY).
7) Use GROUP BY on one column only.
"""
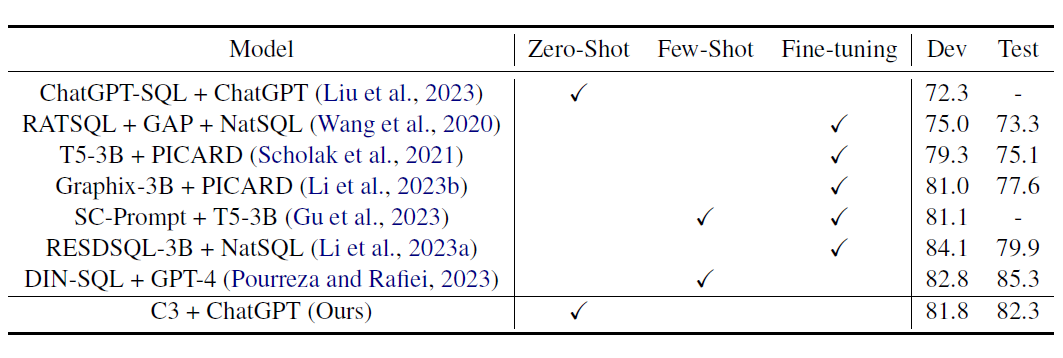
后面的C3和SQL-PALM都是用DIN-SQL作为基准进行评估,所以DIN的效果指标我们直接放到后面的部分。
C3
- C3: Zero-shot Text-to-SQL with ChatGPT
- 通过优化schema description+多路投票的解码方案,用zero-shot prompt基本追平DIN的效果
在DIN-SQL提出的Few-shot方案的基础上,C3使用chatgpt作为基座模型,探索了zero-shot的方案,这样可以进一步降低推理成本。并且在生成效果上和DIN-SQL不相上下。
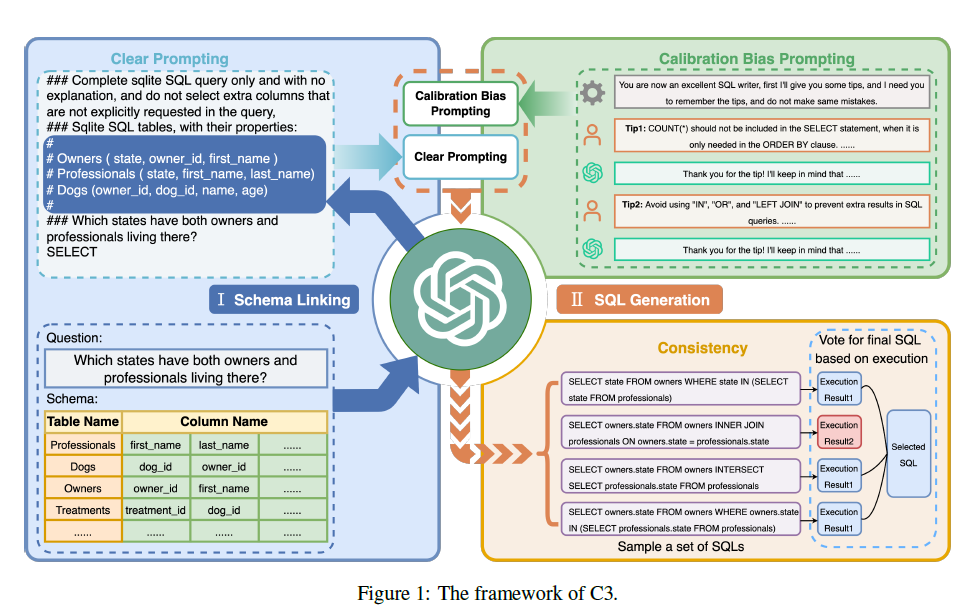
论文实现有很多细节,个人感觉比较重要的是以下两个部分,其他细节不做赘述
Clear Prompting
C3也通过Schema Linking先定位问题相关的数据表和查询字段。不过在指令构建上,论文认为在编写指令时,简洁的文本格式(clear layout),以及不引入不相关的表结构(clear context),会降低模型理解难度,对模型效果有很大提升。下面我们分别看下这两个部分
Clear Layout
后面的SQL-Palm也进行了类似的消融实验,对比符合人类自然语言描述的Table Schema,使用符号表征的prompt效果显著更好,在执行准确率上有7%左右的提升。


Clear Context
把整个数据库的全部表结构放入schema linking Context,一方面增加了推理长度,一方面会使得模型有更大概率定位到无关的查询字段。因此C3通过以下两步先召回相关的数据表和表字段,再进行schema linking
- 数据表召回
C3使用以下zero-shot指令,让大模型基于数据表schema,召回问题相关的数据表。这一步作者采用了self-consistency来投票得到概率最高的Top4数据表。当前的一些开源方案例如[ChatSQL]等,也有采用相似度召回的方案,更适合低延时,面向超大数据库的场景。不过需要先人工先对每张表生成一段表描述,描述该表是用来干啥的,然后通过Query*Description的Embedding相似度来筛选TopK数据表。
instruction = """Given the database schema and question, perform the following actions:
1 - Rank all the tables based on the possibility of being used in the SQL according to the question from the most relevant to the least relevant, Table or its column that matches more with the question words is highly relevant and must be placed ahead.
2 - Check whether you consider all the tables.
3 - Output a list object in the order of step 2, Your output should contain all the tables. The format should be like:
["table_1", "table_2", ...]
"""
- 表字段召回
在以上得到问题相关的数据表之后,会继续执行表字段召回的操作,同样使用了Self-Consistency多路推理投票得到概率最高的Top5字段。这一步同样可以使用相似度召回,尤其在中文场景,以及垂直领域的数据表场景,直接使用字段名并不足够,也需要对表字段名称生成对应的描述,然后使用相似度进行召回。
instruction = '''Given the database tables and question, perform the following actions:
1 - Rank the columns in each table based on the possibility of being used in the SQL, Column that matches more with the question words or the foreign key is highly relevant and must be placed ahead. You should output them in the order of the most relevant to the least relevant.
Explain why you choose each column.
2 - Output a JSON object that contains all the columns in each table according to your explanation. The format should be like:
{
"table_1": ["column_1", "column_2", ......],
"table_2": ["column_1", "column_2", ......],
"table_3": ["column_1", "column_2", ......],
......
}
self-consistency
Schema Linking之后,c3没有像DIN一样去判断问题的难度,而是用统一的zero-Prompt来对所有问题进行推理。不过在推理部分引入了Self-Consistency的多路投票方案。
针对每个问题会随机生成多个SQL,然后去数据库进行执行,过滤无法执行的sql,对剩余sql的执行结果进行分组,从答案出现次数最多的分组随机选一个sql作为最终的答案,也就是基于sql执行结果的major vote方案。
效果上c3在spider数据集上,使用干净简洁的zero-shot-prompt+self-consistency,基本打平了Few-shot的DIN-SQL,
SQL-Palm
- SQL-PALM: IMPROVED LARGE LANGUAGE MODEL ADAPTATION FOR TEXT-TO-SQL
- 尝试了微调方案并显著超越了以上的DIN-SQL
SQL-Palm是谷歌最新的NL2SQL的论文,使用的是他们的Palm2,不过未提供代码。和以上两种方案不同的是,SQL-Palm没有进行问题拆解,而是直接基于few-shot prompt进行sql的推理生成,并且尝试了微调方案,微调后的模型会显著超越DIN-SQL。
指令构建和以上的C3有两点相似
- Self-consistency: 同样使用了基于执行结果的多路投票来选择sql
- clean prompt:同样实验对比了偏向于人类自然表达的表结构表述和符号化的简洁表结构描述,结论和以上C3相同。在有few-shot样本时,指令长啥样影响都不大,在zero-shot指令下,符号化的简洁表结构描述效果显著更好。对比如下上图是符号化表结构,下图是自然语言式的表结构描述


论文同样对模型self-correction做了尝试,尝试方向和DIN不同,不是直接对SQL语句进行校准,而是当SQL执行错误时,基于错误信息让模型进行SQL修正。但是论文提到,并没找到很好的Debug的自修正方案,修正后对效果没有显著提升。
BIRD
- Can LLM Already Serve as A Database Interface?A BIg Bench for Large-Scale Database Grounded Text-to-SQLs
- DuSQL: A large-scale and pragmatic Chinese text-to-SQL dataset.
如果说前三篇还有一丢丢“象牙塔文学”,那BIRD确实一步跨入了纪实文学的领域。论文的核心是推出了新的更贴合实际应用场景的超大规模+存在数据噪声+依赖领域知识的NL2SQL基准数据集。在该数据集上,虽然DIN依旧是SOTA,但是和人工标注的执行准确率对比来看,只能说“前路阻且长”
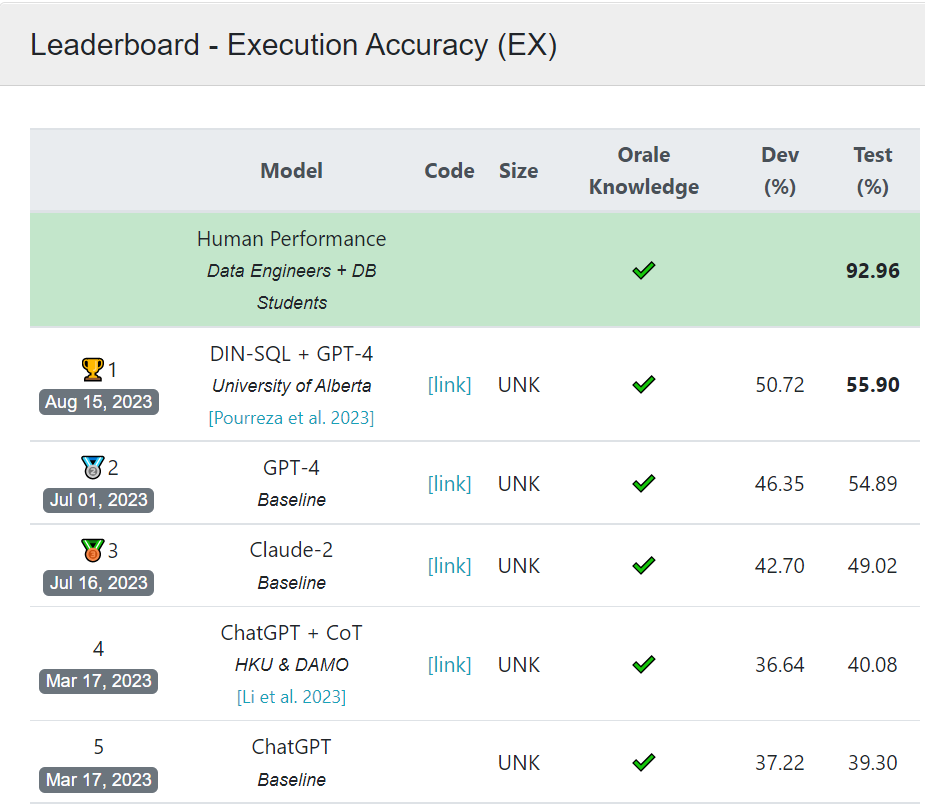
只所以在Spider基准中有85%+执行准确率的SOTA模型,在BIRD里面表现骤降,除了BIRD使用的数据集噪声更多,数据集更大更复杂之外,一个核心原因是现实应用中,只像以上3篇论文那样使用原始表格的schema来描述数据表,是远远不够滴。

往往需要引入额外的表/字段描述,以及领域知识才能让模型更好理解每张表每个字段的作用,包括但不限于以下几个方面
- 表名称/字段缩写(Schema Description):现实场景的table name和column name,往往业务同学自己使用都不知道是啥意思,因此治理后的数据仓库中往往需要人工维护表描述和字段描述。例如b_fund_stock_bond_industry_share_d数据表的描述是每日全量基金股票债券持仓占比的,sw_classify_one_type_name字段的描述是申万一级行业分类,就这?只给表名称你想让模型自己猜到?
- 字段取值说明(Value Illustration):部分表字段的取值是缩写或者专有名词,例如status字段往往会使用代码来指代例如基金申购,赎回等不同状态,这时就需要对字段取值进行说明。
- 领域知识(Domain Knowledge):领域数据库往往需要补充领域知识才能理解,以下Ref1-3的论文有更具体的说明
- 计算类(Numeric Reason):例如如何基金单位净值 = 基金总净值/基金总份额
- 指标类(Indicator):例如询问股票近期波动率,模型需要补充知识说明哪些指标反映波动率
- 指代类(Synonym):例如用户询问某ETF基金,模型需要知道指数基金也是ETF基金的另一种说法
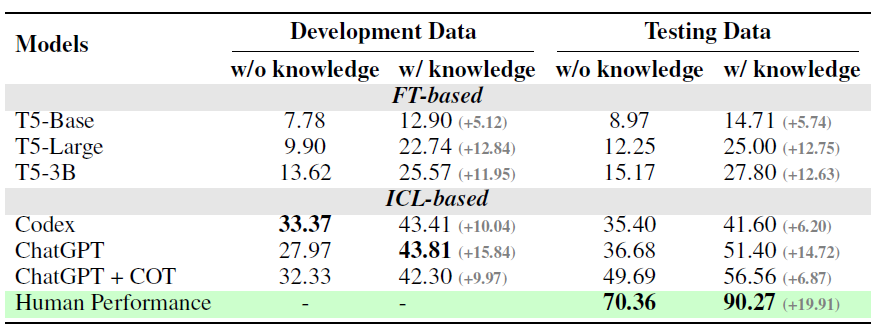
BIRD在人工进行数据标注时,对每张表都提供了对应的以上字段描述和补充知识信息,用来帮助标注同学理解表内容。在使用大模型生成SQL时,以上知识会作为prompt输入模型,如下

并且论文对比了是否使用External Knowledge在测试集和验证集上的效果,提升十分显著。当然因为论文的重点在数据集构建,因此并未对如何更好的引入知识进行更详尽的讨论,期待后文ing~
Reference
- Towards knowledge-intensive text-to-SQL semantic parsing with formulaic knowledge
- Bridging the Generalization Gap in Text-to-SQL Parsing with Schema Expansion
- FinQA: A Dataset of Numerical Reasoning over Financial Data
可能大家都想学习AI大模型技术,也想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把全套AI技术和大模型入门资料、操作变现玩法都打包整理好,希望能够真正帮助到大家。
👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓