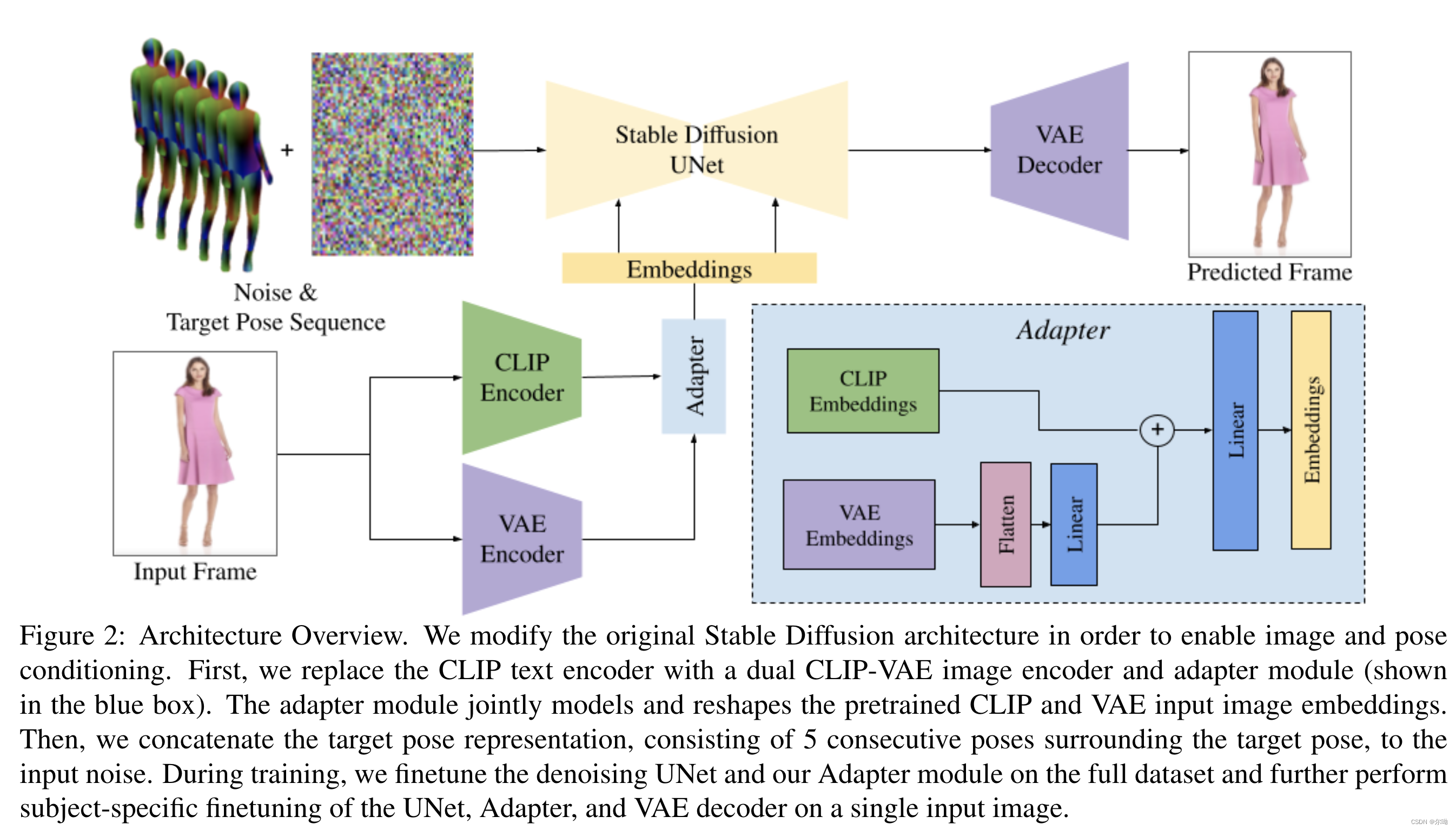
输入参考图片
x
0
x_0
x0和pose序列
{
p
1
,
⋯
,
p
N
}
\{p_1,\cdots,p_N\}
{p1,⋯,pN},输出对应视频
{
x
1
′
,
⋯
,
x
N
′
}
\{x_1',\cdots,x_N'\}
{x1′,⋯,xN′};
模型在推理的时候是帧与帧之间是独立生成的;
将原本的文生图模型改造成pose&image guided video generation model;
methods
appearence控制:Split CLIP-VAE Encoder,之前的方法将图片条件和noised latents结合到一起作为输入,但是这种方法是为了spatial的align,所以本文采取了另一种办法,也就是结合使用CLIP和VAE,最初和VAE embedding相关的权重设置为0,最后得到的embedding
c
I
=
A
(
c
C
L
I
P
,
c
V
A
E
)
c_I = A(c_{CLIP},c_{VAE})
cI=A(cCLIP,cVAE),其中
A
A
A代表adapter;
pose控制:采用五个连续pose帧
c
p
=
{
p
i
−
2
,
p
i
−
1
,
p
i
,
p
i
+
1
,
p
i
+
2
}
c_p=\{p_{i - 2},p_{i - 1},p_i,p_{i + 1},p_{i + 2}\}
cp={pi−2,pi−1,pi,pi+1,pi+2},这些和noised latents concat到一起作为输入,输入修改了以接收额外的10个通道,初始化参数为0;
Pose and Image Classifier-Free Guidance:
ϵ
θ
(
z
t
,
c
i
,
c
p
)
=
ϵ
θ
(
z
t
,
∅
,
∅
)
+
s
I
(
ϵ
θ
(
z
t
,
c
I
,
∅
)
−
ϵ
θ
(
z
t
,
∅
,
∅
)
)
+
s
p
(
ϵ
θ
(
z
t
,
c
I
,
c
p
)
−
ϵ
θ
(
z
t
,
c
I
,
∅
)
)
\epsilon_\theta(z_t,c_i,c_p) = \epsilon_\theta(z_t,\empty,\empty) + s_I(\epsilon_\theta(z_t,c_I,\empty)-\epsilon_\theta(z_t,\empty,\empty)) + s_p(\epsilon_\theta(z_t,c_I,c_p)-\epsilon_\theta(z_t,c_I,\empty))
ϵθ(zt,ci,cp)=ϵθ(zt,∅,∅)+sI(ϵθ(zt,cI,∅)−ϵθ(zt,∅,∅))+sp(ϵθ(zt,cI,cp)−ϵθ(zt,cI,∅)),
s
I
s_I
sI保证和输入图片的appearence相符,
s
p
s_p
sp保证和pose的align;
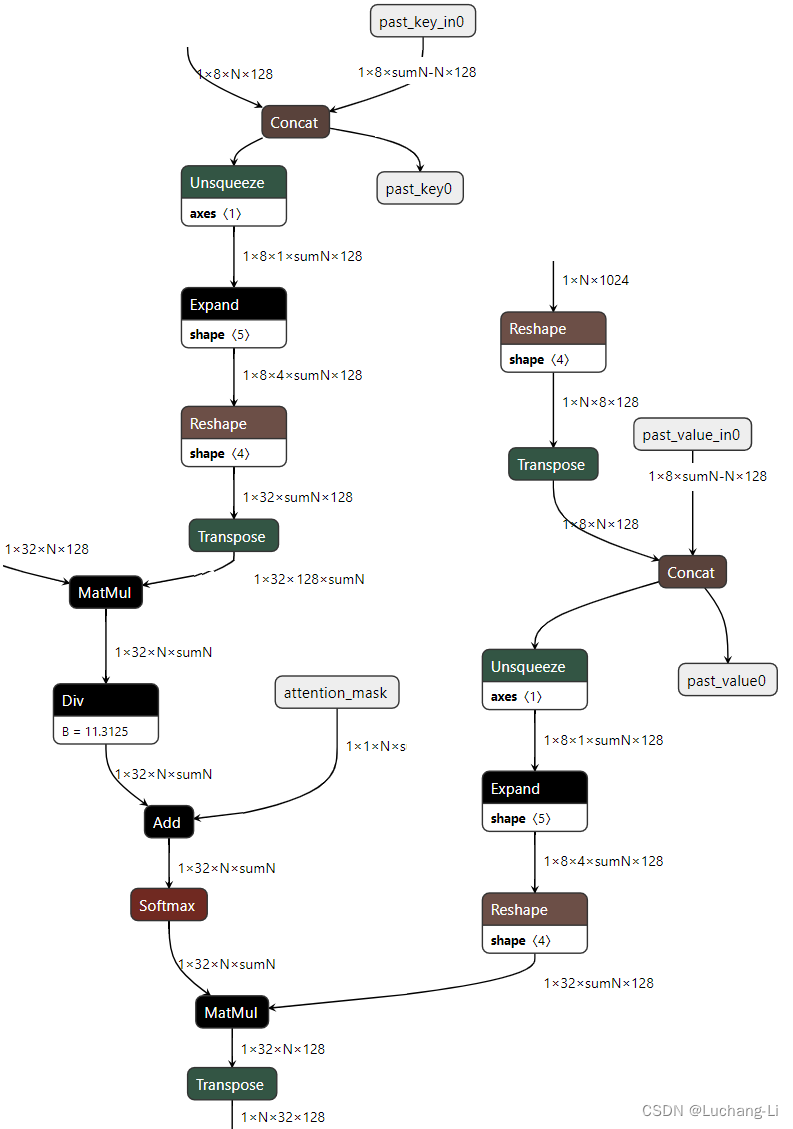
Attention原理和理解
attention原理参考:
Attention Is All You Need
The Illustrated Transformer – Jay Alammar – Visualizing machine learning one concept at a time.
Transformer图解 - 李理的博客
Attention首先对输入x张量乘以WQ, WK, WV得到query,…
Windows 使用技巧
①局域网内共享文件 ②CTRL Y 和 CTRL Z
①局域网内共享文件
第一步: 选择要共享的文件(分享方操作) 第二步: 右键打开属性,选择共享(分享方操作)
第三步: …
Spring 框架是一个广泛使用的 Java 框架,它内部使用了多种设计模式来简化开发过程、提高代码的可维护性和扩展性。 以下是一些在 Spring 框架中常见的设计模式,以及用代码示例来解释它们:
一、工厂模式(Factory Patternÿ…