这个专栏主要关注围绕着AI运用于实际的业务场景所需的系统架构设计。整体基于云原生技术,结合开源领域的LLMOps或者MLOps技术,充分运用低代码构建高性能、高效率和敏捷响应的AI中台。该专栏需要具备一定的计算机基础。
若在某个环节出现卡点,可以回到大模型必备腔调重新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于构建生产级别架构则可以关注AI架构设计专栏。技术宅麻烦死磕LLM背后的基础模型。
训练大型语言模型以及微调的教程比比皆是,但关于在生产环境中部署它们并监控其活动的资料相对稀缺。上个章节提到了未来云原生的AI是趋势,然而涉及到云原生会比较偏技术。而在此之前为了解决大模型部署量产的问题,社区也一直在探索,目前已经有不少的工具可用于这个领域。
今天挑选几个颇具特色的主流部署工具来谈谈,例如vLLM、LLAMA.cpp 和TGI等工具,它们各自都提供各自的部署模式,本文对于数据分析师乃至数据科学家,还是刚接触AI部署的新兵,相信可以为读者打开一扇窗户进行快速的了解。

TGI
Text Generation Inference (TGI) is a toolkit for deploying and serving Large Language Models (LLMs). TGI enables high-performance text generation for the most popular open-source LLMs, including Llama, Falcon, StarCoder, BLOOM, GPT-NeoX, and T5. —HuggingFace
Huggingface TGI是一个用Rust和Python编写的框架,用于部署和提供大型语言模型。它根据HFOILv1.0许可证允许商业使用,前提是它作为所提供产品或服务中的辅助工具。
目前TGI是一个用于部署和服务大型语言模型 (LLM) 的工具包。TGI 为最流行的开源 LLM 提供高性能文本生成,包括 Llama、Falcon、StarCoder、BLOOM、GPT-NeoX 和 T5。
TGI的几项关键技术:
-
支持张量并行推理
-
Safetensors格式的权重加载
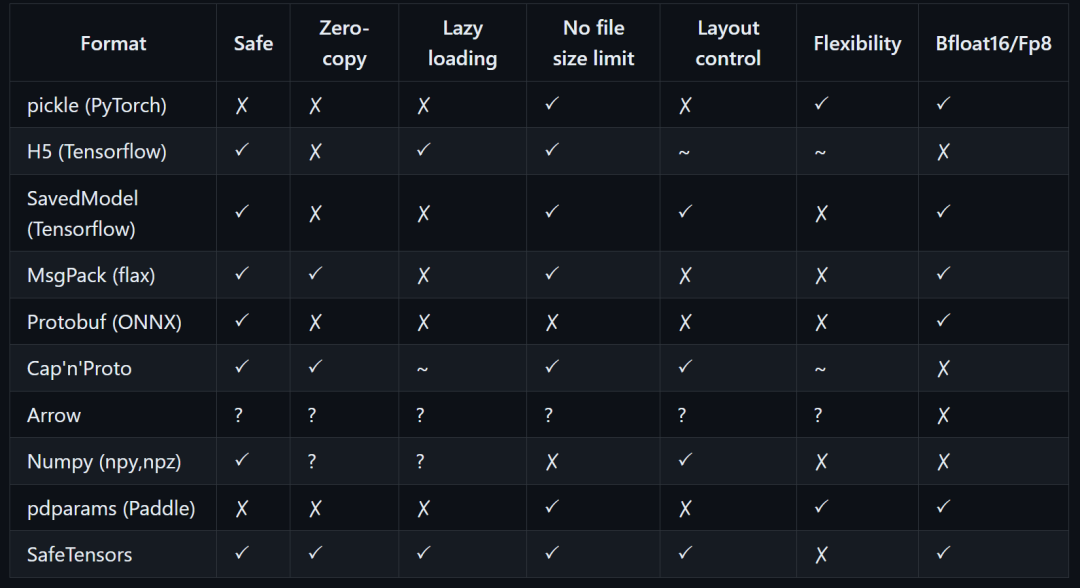
该存储库实现了一种新的简单格式,用于安全地存储张量(而不是 pickle格式),并且在零复制的前提下保持高速。
上图对比了几种格式,从左到右分别为,“是否安全”、“零拷贝”、“延迟加载”、“文件大小限制”、“布局控制”、“灵活度”和“对于BF16和Fp8的支持”
-
支持传入请求Continuous batching以提高总吞吐量
-
在主流的模型架构上使用FlashAttention和PagedAttention用于推理的transformers代码优化。!!并非所有模型都支持这些优化
-
使用bitsandbytes(LLM.int8())和GPT-Q进行量化
-
支持Logits warper
一种对逻辑(logits)进行变换或调整的方法。模型在分类问题中输出的未归一化的概率分布,通常利用softmax将其转换为概率分布。Logits warper包括多种技术,如温度(temperature scaling)、top-p抽样、top-k抽样、重复惩罚等,可以用来调整模型输出。
-
支持微调
目前TGI支持的大模型清单如下,当然也可以部署自定义的模型,只不过性能就未必那么好了。
| Llama Phi 3 Gemma Cohere Dbrx Mamba Mistral Mixtral Gpt Bigcode Phi Falcon StarCoder 2 | Baichuan Qwen 2 Opt T5 Galactica SantaCoder Bloom Mpt Gpt2 Gpt Neox Idefics (Multimodal) Idefics 2 (Multimodal) Llava Next (Multimodal) |

架构与启动
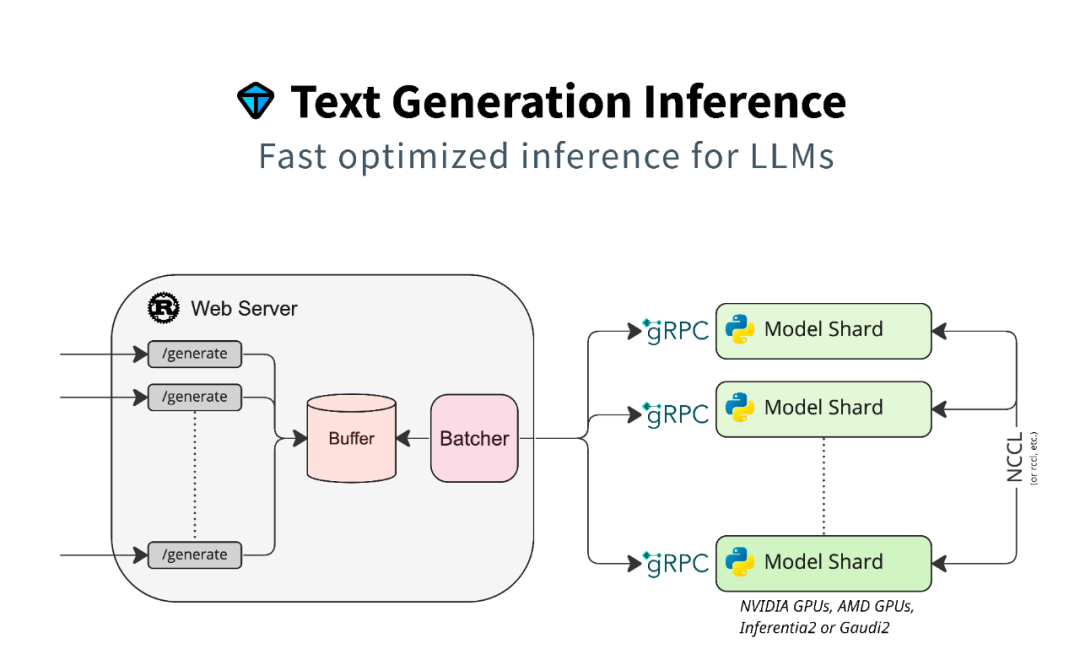
TGI的架构并不复杂,左侧为Web Server,右侧为GPU集群的调度。双方通过gRPC进行通讯,而GPU之间的通讯协议为NCLL。
TGI支持本地部署和Docker启动,实验环境可以直接用docker命令,而在产线环境建议直接采用云原生部署。
docker run --gpus all --shm-size 1g \#可以事先下载好模型-p 8080:80 -v $PWD/$MODEL_PATH:/$MODEL_PATH \#用于存储下载模型转换Safetensors格式后的权重-v $PWD/data:/data \ghcr.io/huggingface/text-generation-inference \--model-id /$MODEL_PATH
启动完毕之后,可以利用Python来访问,(前提是机器的显卡已经完成正确的安装和配置)
import jsonimport requestsurl = "http://localhost:8080/generate"params = {"inputs": "Hello, lubanmocui! ","parameters": {"best_of": 1,"details": True,"return_full_text": True,"decoder_input_details": True,"truncate": 10,"max_new_tokens": 128,"stop": ["\n", "."],"do_sample": True,"temperature": 0.8,"top_k": 10,"top_p": 0.95,},}response = requests.post(url, json=params)result = json.loads(response .text)print(result)
若是显卡的配置不给力的话,还可以通过--quantize的参数设置来解决,TGI会自动对模型进行量化操作。
-
bitsandbytes8-Bit 量化,速度偏慢,但是被支持得最广泛的 -
bitsandbytes-nf44-Bit 量化,大部分的模型都可以直接使用,采用了BNB-NF4的量化方案 -
bitsandbytes-fp44-Bit 量化,和BNB-NF4类似,但是使用标准的4-Bit浮点数类型 -
gptq4-Bit 量化,只能在做过GPTQ Post Training的模型 -
awq4-Bit 量化,类似GPTQ -
eetq8-Bit 量化
当然还有一些其他的参数配置:
docker run --gpus all --shm-size 1g \-p 8080:80 -v $PWD/data:/data \ghcr.io/huggingface/text-generation-inference:latest \--model-id model-ids \--quantize bitsandbytes-nf4 \--max-best-of 1 \--max-concurrent-requests 128 \--max-input-length 3000 \--max-total-tokens 4000 \--max-batch-prefill-tokens 12000
vLLM适用于需要高效内存管理和并行计算的大规模语言模型推理,特别是在资源受限的环境中表现优秀。其主要优势在于高效的内存使用和灵活的并行处理能力,但需要细致的配置和优化。而TGI则专注于提升文本生成任务的推理速度,适用于需要高效文本生成的应用场景。其主要优势在于推理速度优化和模型压缩,但主要针对特定任务进行优化,量化可能会影响模型精度。选择哪一个系统取决于具体的应用需求。







![【代码随想录】【算法训练营】【第21天】 [530]二叉搜索树的最小绝对差 [501]二叉搜索树的众数 [236]二叉树的最近公共祖先](https://img-blog.csdnimg.cn/direct/ed55656873cf4932822eac9381f196c6.png)