MapReduce
包含Google MapReduce基本构架、Hadoop MapReduce基本构架
作业(问答题)
(1)预习论文The Google File System,总结和分析GFS主要特点。
GFS的主要特点包括:
1. 高可靠性和容错性:GFS设计考虑到组件故障是常态,系统中的存储节点和客户端机器数量众多,因此系统必须具备持续监控、错误检测、容错和自动恢复的能力。
2. 大文件支持:GFS中的文件通常都是非常大的,常见的文件大小为多GB。这些文件通常包含许多应用对象,如网页文档。为了管理这些大文件,GFS需要重新考虑I/O操作和块大小等设计参数。
3. 追加写入操作:大多数文件在GFS中是通过追加新数据而不是覆盖现有数据来进行修改的。随机写入几乎不存在,文件通常只被顺序读取。这种访问模式使得追加操作成为性能优化的重点,并且客户端缓存数据块的需求降低。
4. 应用和文件系统API的协同设计:GFS通过协同设计应用和文件系统API来增加系统的灵活性。例如,GFS放宽了一致性模型,简化了文件系统的设计,并引入了原子追加操作,使得多个客户端可以并发地向文件追加数据而无需额外的同步。
5. 高可扩展性和高可用性:GFS可以部署多个集群,每个集群都可以包含上千个存储节点和数百个客户端机器。系统通过阴影主节点机制提供高可扩展性和高可用性。
其他知识点
大规模数据处理时,MapReduce在三个层面上的基本构思
如何对付大数据处理:分而治之 对相互间不具有计算依赖关系的大数据,实现并行最自然的办法就是采取分而治之的策略
上升到抽象模型:Mapper与Reducer MPI等并行计算方法缺少高层并行编程模型,为了克服这一缺陷,MapReduce借鉴了Lisp函数式语言中的思想,用Map和Reduce两个函数提供了高层的并行编程抽象模型
- Map: 对一组数据元素进行某种重复式的处理
- Reduce: 对Map的中间结果进行某种进一步的结果整理
上升到构架:统一构架,为程序员隐藏系统层细节 MPI等并行计算方法缺少统一的计算框架支持,程序员需要考虑数据存储、划分、分发、结果收集、错误恢复等诸多细节;为此,MapReduce设计并提供了统一的计算框架,为程序员隐藏了绝大多数系统层面的处理细节
1.如何提供统一的计算框架
MapReduce提供一个统一的计算框架,可完成:
- 计算任务的划分和调度
- 数据的分布存储和划分
- 处理数据与计算任务的同步
- 结果数据的收集整理(sorting, combining, partitioning,…)
- 系统通信、负载平衡、计算性能优化处理
- 处理系统节点出错检测和失效恢复
2.MapReduce最大的亮点
通过抽象模型和计算框架把需要做什么(what need to do)与具体怎么做(how to do)分开了,为程序员提供一个抽象和高层的编程接口和框架

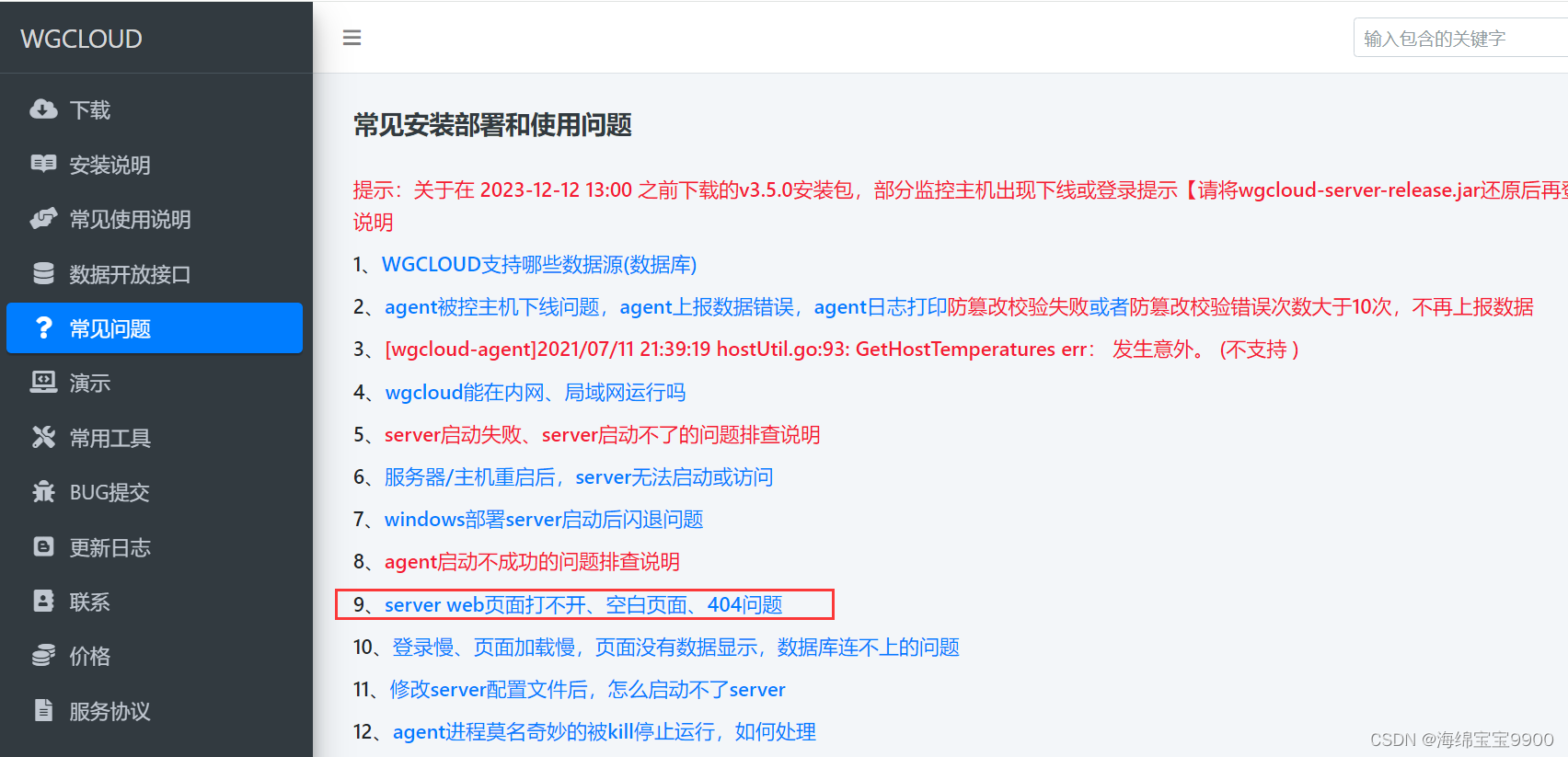
Google MapReduce并行处理的基本过程
- 有一个待处理的大数据,被划分为大小相同的数据块(如64MB),及与此相应的用户作业程序
- 系统中有一个负责调度的主节点(Master),以及数据Map和Reduce工作节点(Worker)
- 用户作业程序提交给主节点
- 主节点为作业程序寻找和配备可用的Map节点,并将程序传送给map节点
- 主节点也为作业程序寻找和配备可用的Reduce节点,并将程序传送给Reduce节点
- 主节点启动每个Map节点执行程序,每个map节点尽可能读取本地或本机架的数据进行计算
- 每个Map节点处理读取的数据块,并做一些数据整理工作(combining, sorting等)并将中间结果存放在本地;同时通知主节点计算任务完成并告知中间结果数据存储位置
- 主节点等所有Map节点计算完成后,开始启动Reduce节点运行;Reduce节点从主节点所掌握的中间结果数据位置信息,远程读取这些数据
- Reduce节点计算结果汇总输出到一个结果文件即获得整个处理结果
相关问题




分布式文件系统GFS的基本工作原理
Google GFS是一个基于分布式集群的大型分布式文件系统,为MapReduce计算框架提供底层数据存储和数据可靠性支撑;
GFS是一个构建在分布节点本地文件系统之上的一个逻辑上文件系统,它将数据存储在物理上分布的每个节点上,但通过GFS将整个数据形成一个逻辑上整体的文件。
廉价本地磁盘分布存储 各节点本地分布式存储数据,优点是不需要采用价格较贵的集中式磁盘阵列,容量可随节点数增加自动增加。
多数据自动备份解决可靠性 采用廉价的普通磁盘,把磁盘数据出错视为常态,用自动多数据备份存储解决数据存储可靠性问题。
为上层的MapReduce计算框架提供支撑 GFS作为向上层MapReduce执行框架的底层数据存储支撑,负责处理所有的数据自动存储和容错处理,因而上层框架不需要考虑低层的数据存储和数据容错问题。
分布式结构化数据表BigTable
详细内容见第6讲课件,不多赘述
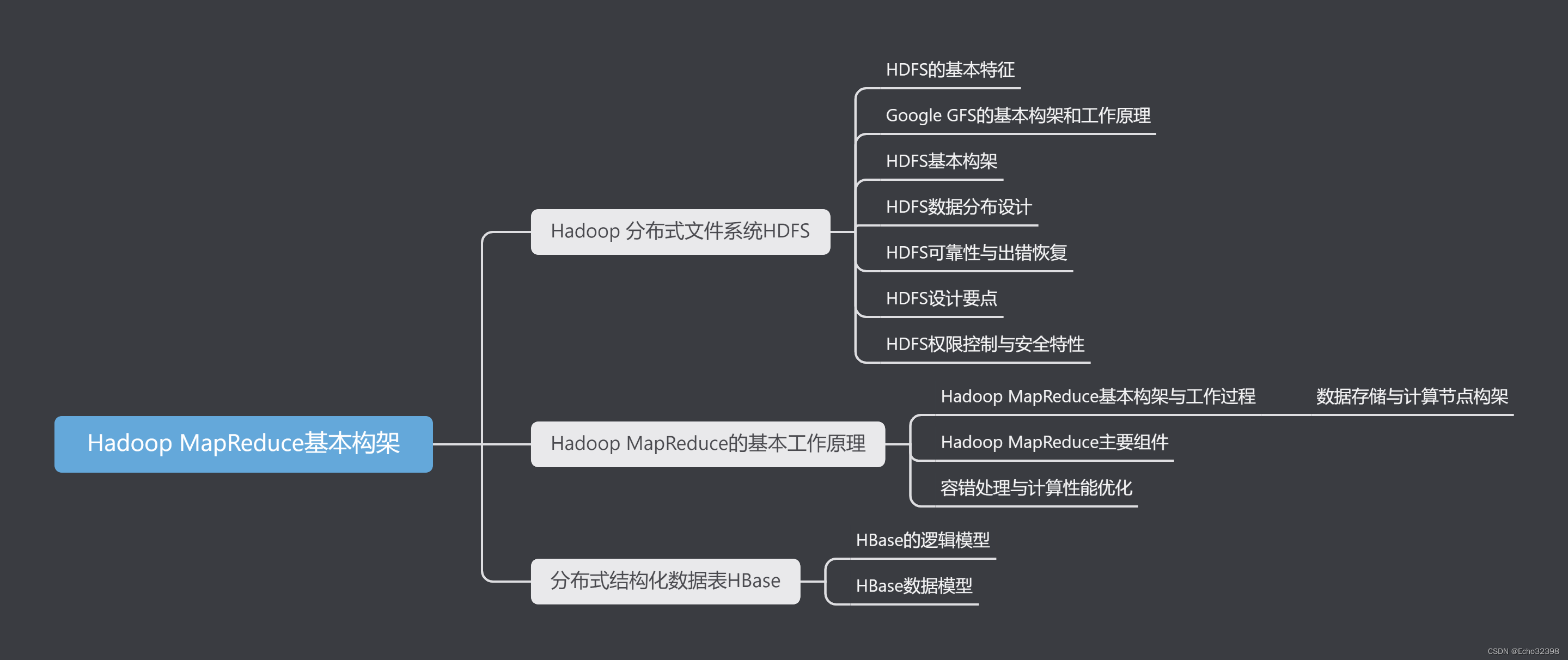
Hadoop MapReduce基本构架
详细内容见第7讲课件,不多赘述(Hadoop主要为课程实验服务)
云计算虚拟化技术
知识点
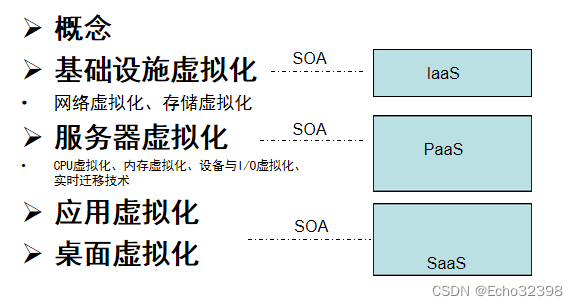
虚拟化技术概念
虚拟化包括三个方面的含义:
- 虚拟化的对象是各种各样的资源;
- 经过虚拟化后的逻辑资源对用户隐藏不必要的实现细节;
- 用户可以在虚拟环境中实现其在真实环境中的部分或全部功能。 ---IBM对虚拟化的定义
资源涵盖的意义包括各种硬件资源,如CPU、内存、存储区、网络设施,或者操作系统、应用程序。
虚拟化的目的:将资源进行抽象化封装成标准的输入输出接口,简化对资源的访问、表示和管理,实现资源使用者和资源具体实现之间的松耦合。
基础设施虚拟化-网络虚拟化
网络虚拟化主要是指抽象出一个网络虚拟层,将网络资源的能力从硬件中剥离出 来,由网络虚拟层来实现原有网络设备所具有的的路由、IP、ACL、拥塞控制 等能力,并对上层应用提供API,实现实现网络能力与硬件的解耦。
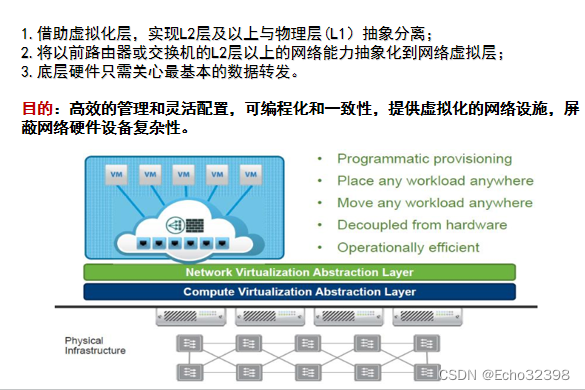
SDN
SDN:软件定义网络
SDN其核心理念是使网络软件化并充分开放,使得网络能够像软件一样便捷、灵活和定制,以此提高网络的创新能力。 实现可编程网络,将原本封闭的网络设备控制面(Control Plane)和数据转发面(DATA Transfer)分离,由集中的控制器来管理,通过开放该控制器来实现网络能力的开放性。
1. 分离控制和转发的功能 2. 控制集中化 3. 提供广泛定义的(软件)接口 ,使得网络可编程

基础设施虚拟化-存储虚拟化
存储虚拟化是指将物理的存储设备抽象成一个存储的逻辑视图,用户可以通过视图中的逻辑接口来访问被整合的存储资源。
1.基于存储设备的存储虚拟化:磁盘阵列技术(RAID)
2.基于网络的存储虚拟化:网络附件存储(NAS)、存储区域网(SAN)
虚拟化目的:将物理存储实体与存储的逻辑表示分离开来,应用服务器只与分配给它们的逻辑卷(或称虚卷)打交道,而不用关心其数据是在哪个物理存储实体上。
存储虚拟化可以将存储利用率提高到80%或更高。
- 存储虚拟化-实现模式
- 基于主机的存储虚拟化
- 基于存储设备的存储虚拟化
- 基于网络的存储虚拟化
- 三种存储虚拟化比较
- 带内虚拟化与带外虚拟化
虚拟化(服务器、应用、桌面)
详细内容见第8讲课件,不多赘述
云计算安全
知识点
什么是云安全
概念:云计算安全 指的是为了保护云环境中的数据、应用程序、以及逻辑和物理层面上的基础设施而制定或实施的策略和技术手段。
概念:安全即服务 也是一类重要的服务模式,它指的是云服务提供商为用户提供基于云的安全服务。
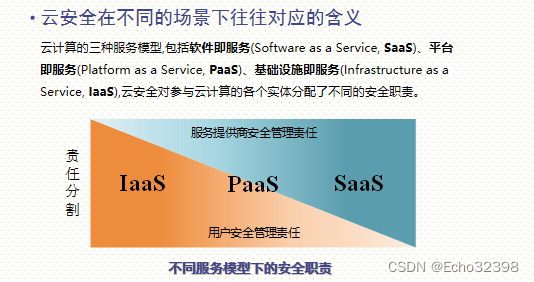
云安全在不同的场景下往往对应的含义
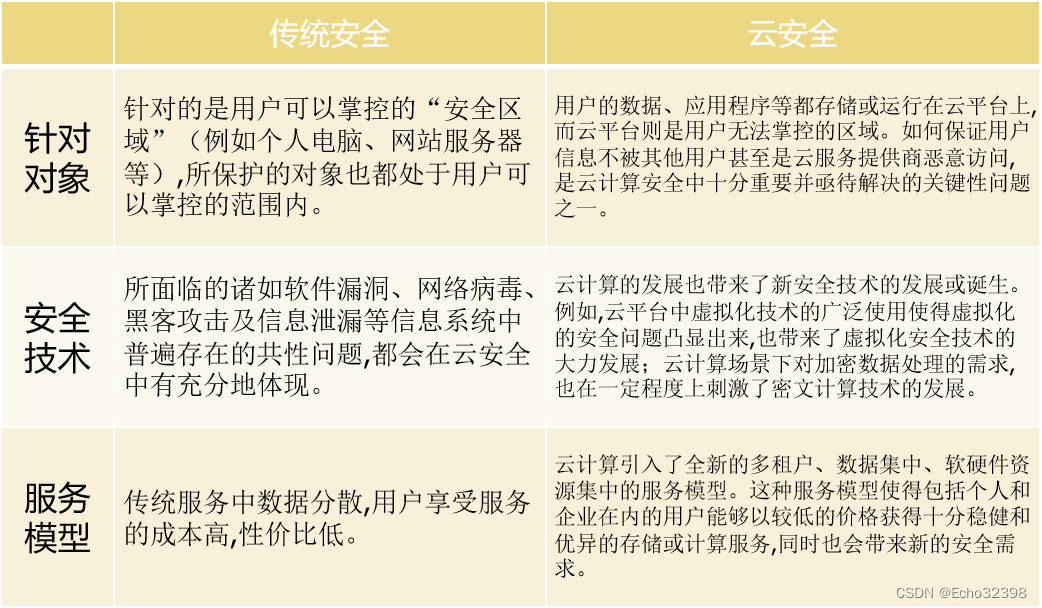
云安全与传统信息安全的异同点

云安全的威胁
具体表现在以下几个方面:
一、由物理计算资源共享带来的虚拟机安全问题;
二、由数据的拥有者与数据之间的物理分离带来的用户数据隐私保护与云计算可用性之间的矛盾;
三、用户行为隐私问题;
四、云计算服务的安全管理方面的问题。
云计算安全技术
虚拟化技术的意义
云计算系统的虚拟化安全问题
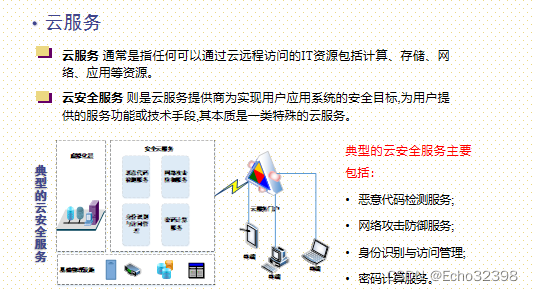
云平台为用户提供的服务

安全即服务
其余知识点参考第9讲