U-Net网络
一、基本架构
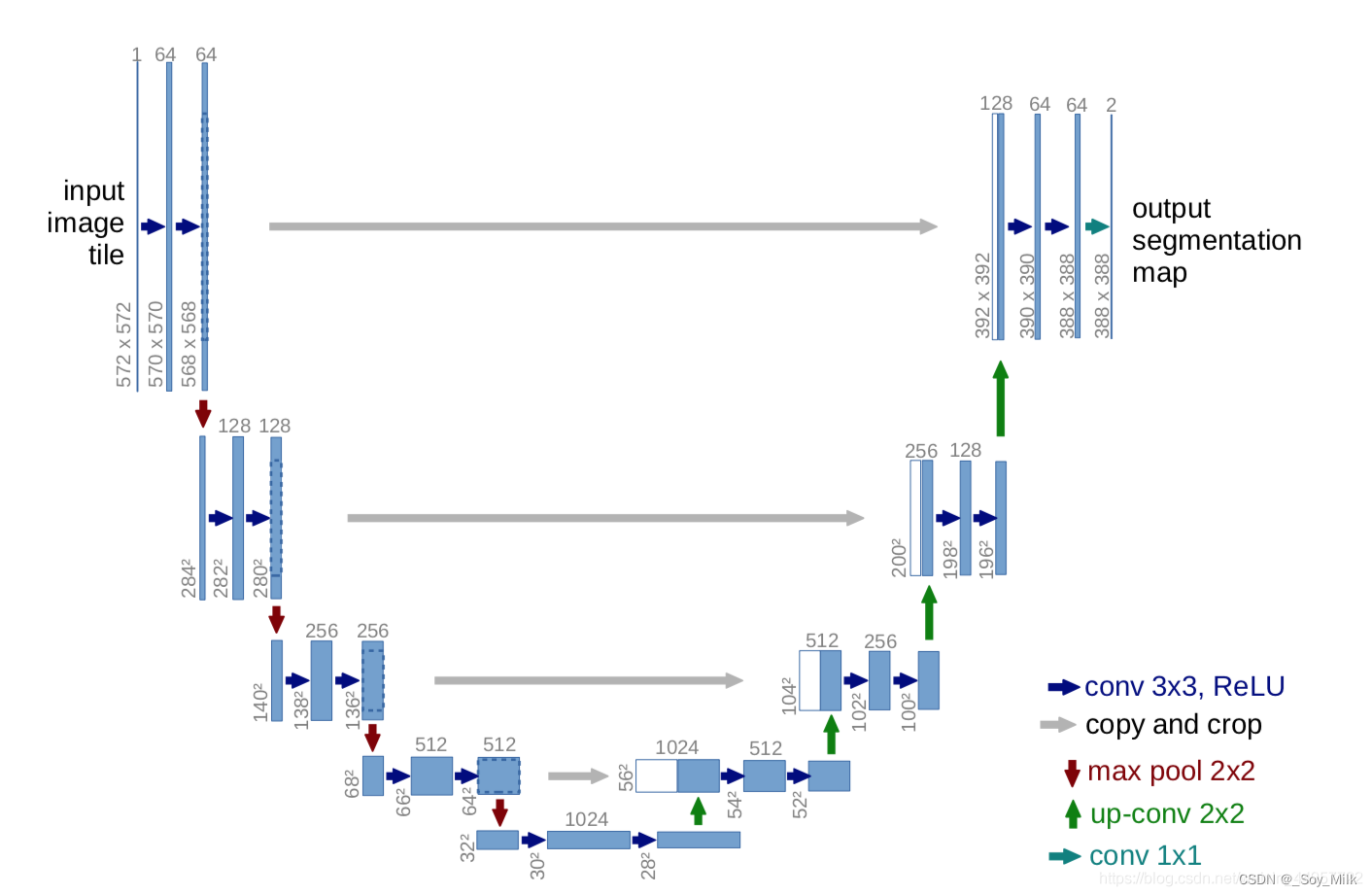
各个箭头的解释:
- conv 3 * 3, ReLU:表示通过一个3 * 3的卷积层,并且该层自动附带一个非线性激活层(
ReLu)- copy and crop:表示进行裁剪然后再进行拼接(在
channel的维度上进行拼接)- max pool 2 * 2:表示通过一个2 * 2的最大池化下采样层,(这一个步骤可以通过一个卷积层进行实现,如果使用最大池化下采样层则会导致丢失
pixel(像素)信息)- up-conv 2 * 2:表示一个上采样过程,可以使用转置卷积来实现,也可以使用最邻近插值法来实现,由于使用转置卷积会导致出现很多空洞,因此我们使用最邻近差值法。
- conv 1 * 1:表示一个卷积核大小为1 * 1 的卷积层,作用主要是改变维度(即
channel的大小)
在实际代码中构建网络时,我们一共为U-Net网络构建了三个模块:
- 蓝色箭头:我们构建为卷积块,并且使用
padding直接进行填充,这样做不会使图片的分辨率发生改变。 - 红色箭头:我们构建为下采样块,并且使用的是卷积的操作进行的下采样,因为最大池化层会使得丢失太多的图片信息。
- 绿色箭头:我们构建为上采样块,并且与灰色箭头一同实现,上下样的过程中,我们使用的是最邻近插值法。
二、理论分析:
论文解读
对于一个高分辨率的图像,如果直接输入网络则会爆显存,因此需要每次将该图像的一小部分输入网络,并且要求每次输入的一小部分需要与之前输入的部分有重叠,这样做可以很好的利用图像的边缘信息。具体方式如下:
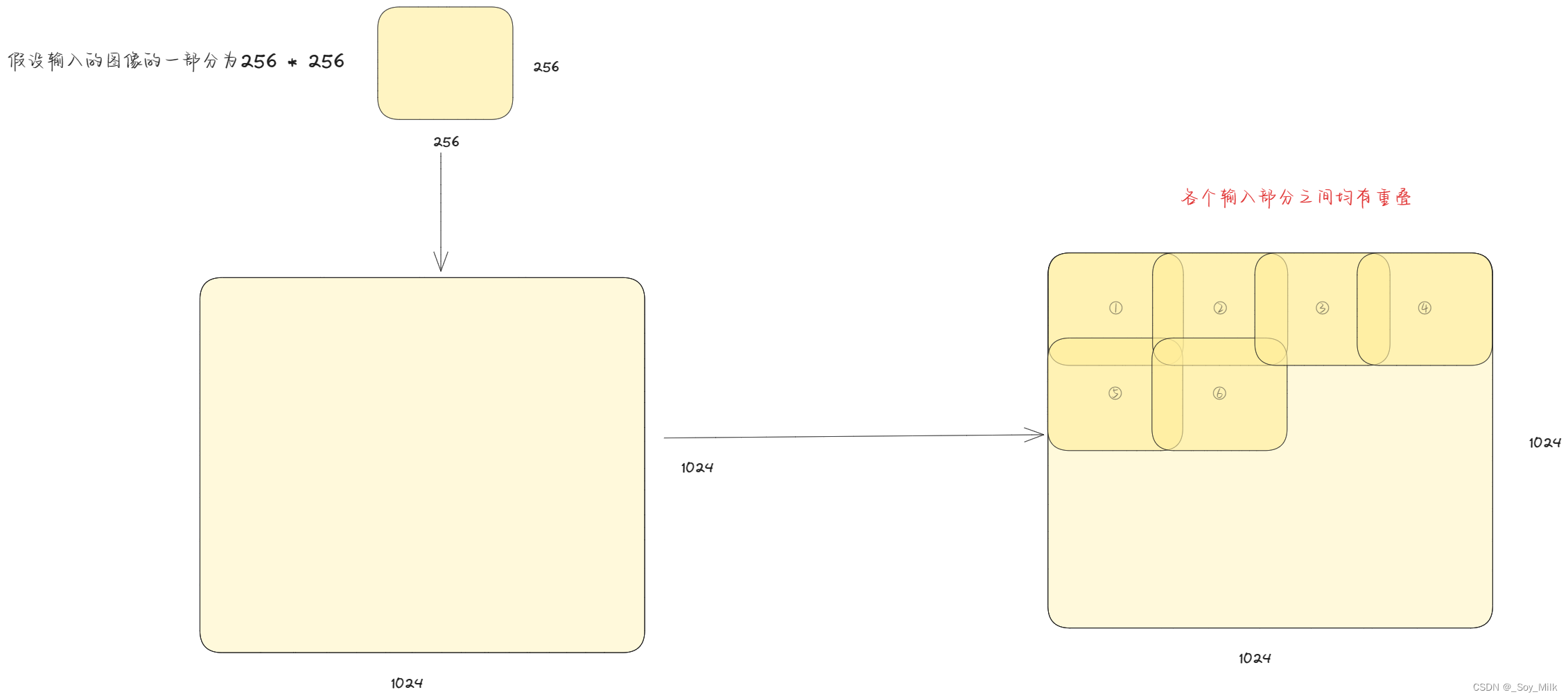
上图展示了将一个1024 * 1024分辨率的图像进行拆分为N个256 * 256分辨率大小的部分,然后再输入到网络中。
预测边缘图像:

由于该论文用于医学图像分割领域,作者研究发现,对于细胞与细胞之间的区域分割是有一定困难的,因此,作者提出了Pixel-Weight lose weight的一个方案,也就是在细胞与细胞之间的这些背景区,我们给它施加一个更大的权重,而对于大片的背景区,我们就给它施加一个比较小的权重。
实验分析:
由U-Net网络的架构可以看出,网络的核心是构建了三个模块,即:3 * 3的卷积层构成的卷积块、下采样块、上采样块,由于网络多次使用这三个模块,因此我们可以将这三个模块进行封装。
计算卷积后图像的宽度和高度(公式一):
I n p u t : ( N , C i n , H ( i n ) , W ( i n ) ) Input:(N, C_{in}, H_(in), W_(in)) Input:(N,Cin,H(in),W(in))
O u t P u t : ( N , C ( o u t ) , H ( o u t ) , W ( o u t ) ) OutPut:(N, C_(out), H_(out), W_(out)) OutPut:(N,C(out),H(out),W(out))
H ( o u t ) = [ H ( i n ) + 2 × p a d d i n g [ 0 ] − d i l a t i o n [ 0 ] × ( k e r n e l s i z e [ 0 ] − 1 ) − 1 s t r i d e [ 0 ] + 1 ] H_(out) = [\frac{H_(in) + 2 \times padding[0] - dilation[0] \times (kernel_{size[0]} - 1) - 1}{stride[0]} + 1] H(out)=[stride[0]H(in)+2×padding[0]−dilation[0]×(kernelsize[0]−1)−1+1]
·W ( o u t ) = [ W ( i n ) + 2 × p a d d i n g [ 1 ] − d i l a t i o n [ 1 ] × ( k e r n e l s i z e [ 1 ] − 1 ) s t r i d e [ 0 ] − 1 ] W_(out) = [\frac{W_(in) + 2 \times padding[1] - dilation[1] \times (kernel_{size[1]} - 1)}{stride[0]} - 1] W(out)=[stride[0]W(in)+2×padding[1]−dilation[1]×(kernelsize[1]−1)−1]
参数解释:
padding是填充的大小,dilation是空洞卷积的大小(即卷积核各个单元之间有多少个间隔),kernel_size是卷积核的大小。空洞卷积:
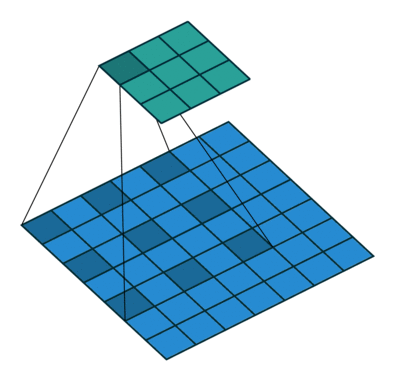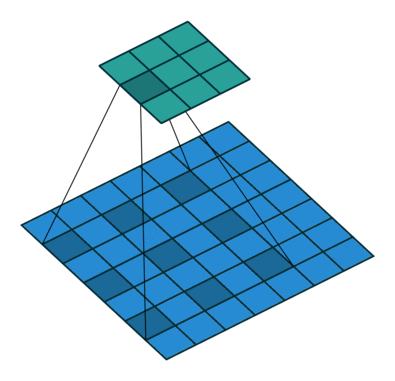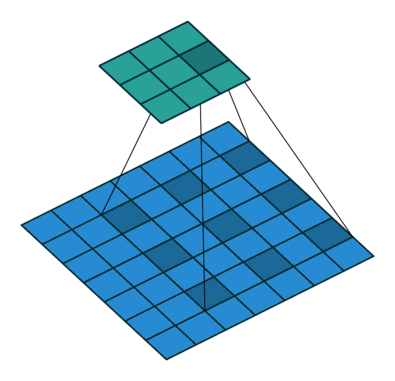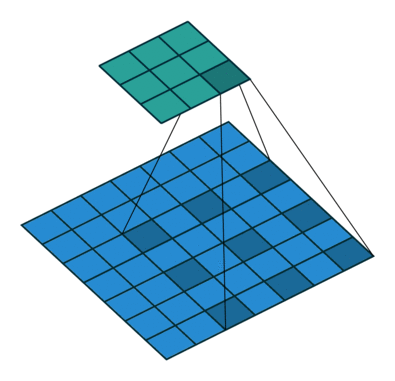
1. 卷积块
-
首先定义一个Convolution(卷积层),卷积核大小为3 * 3(即:
kernel_size = 3),分析U-Net架构图(输入:[1, 572, 572]==> 输出:[64, 570, 570])可以得到,channel的维度由1 上升到了64,所以定义64个卷积核,由于后面的copy and crop拼接的时候还需要进行裁剪,会导致很麻烦,因此现在的主流的方式是将卷积层加上一个padding,即通过卷积层后不会改变图像的高和宽,并且会在卷积核与 ReLU 之间加上一个BN(Batch normalization),由于没有使用空洞卷积,默认dilatation = 1,由**(公式一)**可以得到stride = 1,padding = 1,这样保证了卷积后图像的高度和宽度不会改变。 -
然后再添加一个Batch normalization层进行归一化处理,这样的好处是加快收敛。
-
再添加一个Dropout层,Dropout 是一种正则化技术,通过在训练过程中随机丢弃一部分神经元的输出,可以减少过拟合并提升模型的泛化能力。
-
最后添加一个LeakReLU层
LeakyReLU 函数在处理负值时不像 ReLU 那样完全将其置零,而是允许一小部分负输入信息的线性泄漏。这有助于缓解ReLU 死亡问题,即神经元可能陷入零激活状态,使得模型难以学习。
数学上,LeakyReLU 函数的定义如下:
f(x) = max(ax, x)
其中:
-
x 表示函数的输入,
-
a 是一个小常数(通常是一个小的正值,如 0.01),它代表函数负值部分的斜率。
由于U-Net网络每次需要添加两次卷积层,因此需要将上述定义的卷积层再次重复一次
-
卷积块代码:
class Conv_Block(nn.Module):
def __init__(self, in_channel, out_channel):
super(Conv_Block, self).__init__()
self.layer = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=1, padding=1, padding_mode='reflect', bias=False), # 填充模式padding_mode='reflect'表示边界向内复制, 第二个参数out_channel表示卷积核的数量
nn.BatchNorm2d(out_channel), # 归一化处理,参数为特征图的通道数
nn.Dropout(0.3), # 这条语句的作用是创建一个丢弃比例为0.3的 Dropout 层,也就是30%的输入将被随机置为0。。Dropout 是一种正则化技术,通过在训练过程中随机丢弃一部分神经元的输出,可以减少过拟合并提升模型的泛化能力
nn.LeakyReLU(),
nn.Conv2d(out_channel, out_channel, kernel_size=3, stride=1, padding=1, padding_mode='reflect', bias=False),
nn.BatchNorm2d(out_channel),
nn.Dropout(0.3),
nn.LeakyReLU()
)
def forward(self, x):
return self.layer(x)
2. 下采样块
由于最大池化丢弃了太多的特征,因此我们使用一个3 * 3 的卷积来进行最大池化
- 首先定义一个3 * 3 的卷积核,并且通过U-Net网络的结构图(输入:
[64, 568, 568]==> 输出:[64, 284, 284])可以知到,相当于将图像的宽度和高度进行了减半,因此我们在卷积核中设置padding = 1,stride = 2。 - 然后添加一个Batch Normalization层
- 最后添加一个LeakReLU层
下采样块代码:
class DownSample(nn.Module):
def __init__(self, channel):
super(DownSample, self).__init__()
self.layer = nn.Sequential(
# 最大池化时,通道数量不变
nn.Conv2d(channel, channel, kernel_size=3, stride=2, padding=1, padding_mode='reflect', bias=False),
# 'reflect' 模式意味着在边缘周围反射输入图像的像素值。这种模式可以减少边缘效应,并且有助于保持特征图的边界信息。
nn.BatchNorm2d(channel),
nn.LeakyReLU()
)
def forward(self, x):
return self.layer(x)
3. 上采样块
由于使用转置卷积会导致出现很多空洞,因此我们使用最邻近差值法
- 首先使用最邻近插值法对输入的特征图进行处理(Pytorch中的方法是:
nn.Functional()函数)。 - 然后使用一个1 * 1的卷积将图像进行升维。
- 最后将与该层对应的层在
channel维度上进行拼接(Pytorch中的方法是:torch.cat())。
上采样块代码:
class UpSample(nn.Module):
def __init__(self, channel):
super(UpSample, self).__init__()
self.layer = nn.Conv2d(channel, channel // 2, kernel_size=1, stride=1)
def forward(self, x, feature_map):
up = F.interpolate(x, scale_factor=2, mode='nearest') # 参数解释:scale_factor :变为原来的2倍, mode :使用什么方式,这里为使用最邻近插值法
out = self.layer(up)
# 实现拼接
return torch.cat((out, feature_map), dim=1) # [N, C, H, W] 在通道的维度进行拼接
U-Net的整体定义
- 首先定义一个卷积层,后面连接一个下采样层,重复4次。
- 然后添加一个卷积层。
- 再添加一个上采样层,后面连接一个卷积层,重复4次。
- 最后添加一个3 * 3的卷积层,将维度映射为(
RGB)3个channel。
U-Net整体代码:
class Unet(nn.Module):
def __init__(self):
super(Unet, self).__init__()
self.c1 = Conv_Block(3, 64)
self.d1 = DownSample(64)
self.c2 = Conv_Block(64, 128)
self.d2 = DownSample(128)
self.c3 = Conv_Block(128, 256)
self.d3 = DownSample(256)
self.c4 = Conv_Block(256, 512)
self.d4 = DownSample(512)
self.c5 = Conv_Block(512, 1024)
# 开始进行上采样
self.u1 = UpSample(1024)
self.c6 = Conv_Block(1024, 512)
self.u2 = UpSample(512)
self.c7 = Conv_Block(512, 256)
self.u3 = UpSample(256)
self.c8 = Conv_Block(256, 128)
self.u4 = UpSample(128)
self.c9 = Conv_Block(128, 64)
# 进行输出
self.out = nn.Conv2d(64, 3, (3, 3), 1, 1)
self.Th = nn.Sigmoid() # 由于我们只需要直到图像的蒙版,只需要知到这个像素是黑的还是白的,因此这是一个二分类问题
def forward(self, x):
R1 = self.c1(x)
R2 = self.c2(self.d1(R1))
R3 = self.c3(self.d2(R2))
R4 = self.c4(self.d3(R3))
R5 = self.c5(self.d4(R4))
# 进行上采样
O1 = self.c6(self.u1(R5, R4)) # 进行拼接
O2 = self.c7(self.u2(O1, R3))
O3 = self.c8(self.u3(O2, R2))
O4 = self.c9(self.u4(O3, R1))
return self.Th(self.out(O4))
三、代码实现:
U_Net_model.py
import torch
from torch import nn
from torch.nn import functional as F
# 构建卷积块
class Conv_Block(nn.Module):
def __init__(self, in_channel, out_channel):
super(Conv_Block, self).__init__()
self.layer = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size=(3, 3), stride=1, padding=1, padding_mode='reflect', bias=False), # 填充模式padding_mode='reflect'表示边界向内复制, 第二个参数out_channel表示卷积核的数量
nn.BatchNorm2d(out_channel), # 归一化处理,参数为特征图的通道数
nn.Dropout(0.3), # 这条语句的作用是创建一个丢弃比例为0.3的 Dropout 层,也就是30%的输入将被随机置为0。。Dropout 是一种正则化技术,通过在训练过程中随机丢弃一部分神经元的输出,可以减少过拟合并提升模型的泛化能力
nn.LeakyReLU(),
nn.Conv2d(out_channel, out_channel, kernel_size=3, stride=1, padding=1, padding_mode='reflect', bias=False),
nn.BatchNorm2d(out_channel),
nn.Dropout(0.3),
nn.LeakyReLU()
)
def forward(self, x):
return self.layer(x)
# 最大池化下采样(由于最大池化丢弃了太多的特征,因此我们使用一个3 * 3 的卷积来进行最大池化)
class DownSample(nn.Module):
def __init__(self, channel):
super(DownSample, self).__init__()
self.layer = nn.Sequential(
# 最大池化时,通道数量不变
nn.Conv2d(channel, channel, kernel_size=3, stride=2, padding=1, padding_mode='reflect', bias=False),
nn.BatchNorm2d(channel),
nn.LeakyReLU()
)
def forward(self, x):
return self.layer(x)
# 下采样(由于使用转置卷积会导致出现很多空洞,因此我们使用最邻近差值法)
class UpSample(nn.Module):
def __init__(self, channel):
super(UpSample, self).__init__()
self.layer = nn.Conv2d(channel, channel // 2, kernel_size=1, stride=1)
def forward(self, x, feature_map):
up = F.interpolate(x, scale_factor=2, mode='nearest') # 参数解释:scale_factor :变为原来的2倍, mode :使用什么方式,这里为使用最邻近插值法
out = self.layer(up)
# 实现拼接
return torch.cat((out, feature_map), dim=1) # [N, C, H, W] 在通道的维度进行拼接
class Unet(nn.Module):
def __init__(self):
super(Unet, self).__init__()
self.c1 = Conv_Block(3, 64)
self.d1 = DownSample(64)
self.c2 = Conv_Block(64, 128)
self.d2 = DownSample(128)
self.c3 = Conv_Block(128, 256)
self.d3 = DownSample(256)
self.c4 = Conv_Block(256, 512)
self.d4 = DownSample(512)
self.c5 = Conv_Block(512, 1024)
# 开始进行上采样
self.u1 = UpSample(1024)
self.c6 = Conv_Block(1024, 512)
self.u2 = UpSample(512)
self.c7 = Conv_Block(512, 256)
self.u3 = UpSample(256)
self.c8 = Conv_Block(256, 128)
self.u4 = UpSample(128)
self.c9 = Conv_Block(128, 64)
# 进行输出
self.out = nn.Conv2d(64, 3, 3, 1, 1)
self.Th = nn.Sigmoid() # 由于我们只需要直到图像的蒙版,只需要知到这个像素是黑的还是白的,因此这是一个二分类问题
def forward(self, x):
R1 = self.c1(x)
R2 = self.c2(self.d1(R1))
R3 = self.c3(self.d2(R2))
R4 = self.c4(self.d3(R3))
R5 = self.c5(self.d4(R4))
# 进行上采样
O1 = self.c6(self.u1(R5, R4)) # 进行拼接
O2 = self.c7(self.u2(O1, R3))
O3 = self.c8(self.u3(O2, R2))
O4 = self.c9(self.u4(O3, R1))
return self.Th(self.out(O4))
if __name__ == '__main__':
'''
定义网络的结构使用的代码,整个U-Net网络
'''
x = torch.randn(2, 3, 572, 572)
net = Unet()
print(net(x).shape)
utils.py
utils.py文件用于对输入的图片的shape进行处理
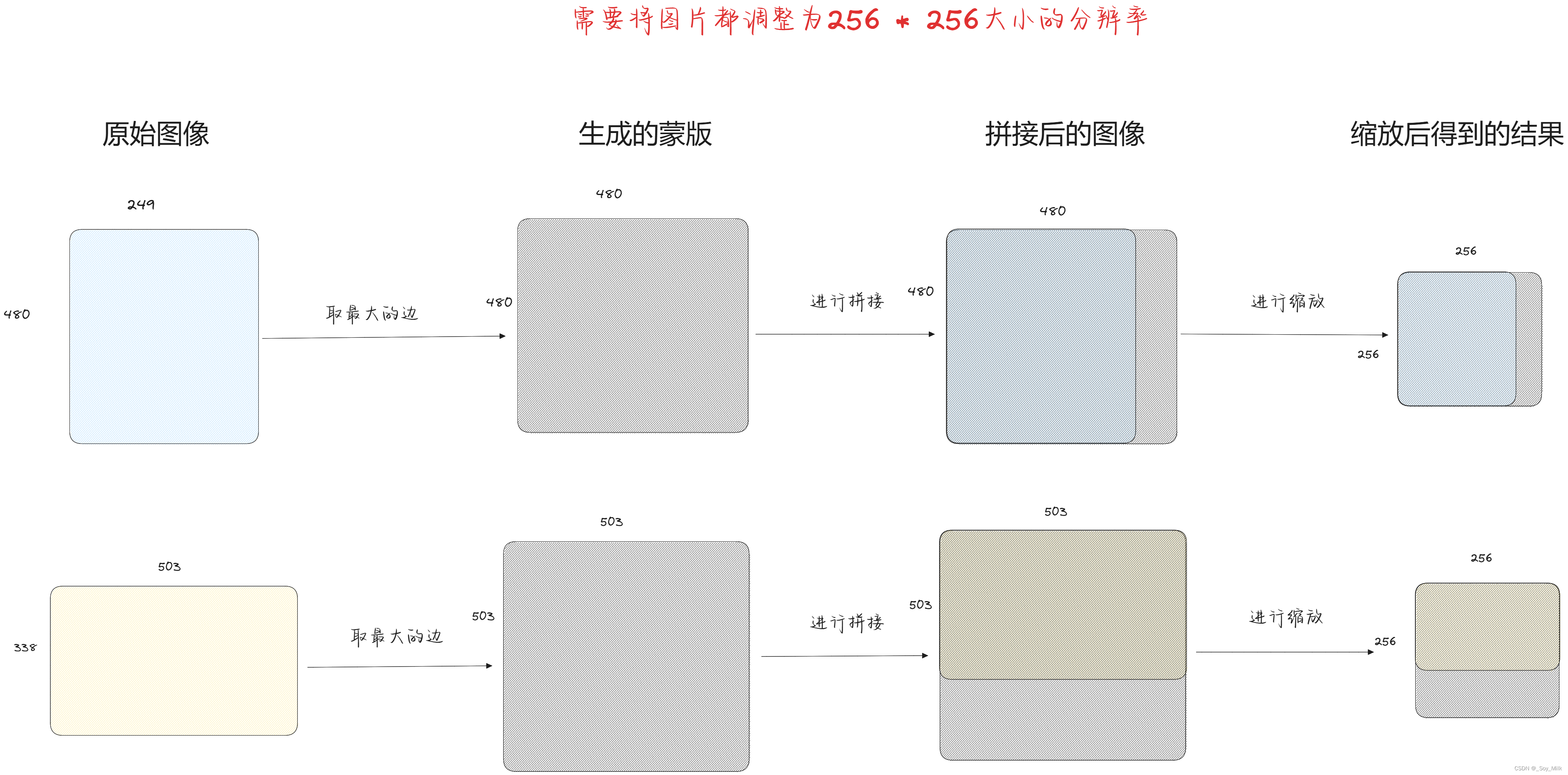
由于直接对图像进行缩放会导致图像进行变形,这就导致图像的特征发生了变化,为了保证图像特征的完整性,我们使用蒙版的方法进行设定输入图像的大小,具体方式如下:
- 首先找到图像中最大的边。
- 然后利用此边设定一个值为0的方形蒙版。
- 将图片粘贴到该蒙版上。
- 对结合后的蒙版进行等比缩放得到需要的图片大小。
from PIL import Image
# 对图片进行缩放
def keep_image_size_open(path, size=(256, 256)):
img = Image.open(path)
# img.size返回的是一个元组,temp获取的是每一张图片的最大长度
temp = max(img.size)
# Image.new(mode, size, color),用于创建一个新的图像。color表示图像的初始颜色
mask = Image.new('RGB', (temp, temp), (0, 0, 0))
'''
mask.paste(im, box, mask=None) 用于将一个图像粘贴到另一个图像上,并可以指定粘贴的位置以及透明度,参数解释:im表示要粘贴的图像,box定义了粘贴位置和大小的矩形框(0, 0)表示从左上角进行粘贴
'''
mask.paste(img, (0, 0))
mask = mask.resize((size)) # 调整大小
return mask
if __name__ == '__main__':
keep_image_size_open("./data/JPEGImages/000033.jpg").show()
My_DataSet.py
import os
from torch.utils.data import Dataset
from utils import *
from torchvision import transforms
# 将数据转换为Tenso类型
transform = transforms.Compose([
transforms.ToTensor()
])
# 定义数据集(图像分割数据集)
class MyDataset(Dataset):
def __init__(self, path):
self.path = path
self.name = os.listdir(os.path.join(path, "SegmentationClass"))
def __len__(self):
return len(self.name)
def __getitem__(self, index):
segment_name = self.name[index] # 格式:xxx.png
# 拼接得到蒙版的地址
segment_path = os.path.join(self.path, 'SegmentationClass', segment_name)
# 拼接得到原图的地址
image_paht = os.path.join(self.path, 'JPEGImages', segment_name.replace('png', 'jpg'))
# 将蒙版与原图进行读取进来
segment_image = keep_image_size_open(segment_path)
image = keep_image_size_open(image_paht)
return transform(image), transform(segment_image)
if __name__ == '__main__':
path = './data'
data = MyDataset(path)
print(data[0][0].shape)
print(data[0][1].shape)
train.py
from torch import nn, optim
import torch
from torch.utils.data import DataLoader
from My_DataSet import *
from net import *
from torchvision.utils import save_image
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
weight_path = 'params/unet.pth'
data_pth = './Data/VOCdevkit/VOC2007'
save_path = 'train_image'
def main():
'''
训练网络使用的代码
'''
data_loader = DataLoader(MyDataset(data_pth), batch_size=2, shuffle=True)
net = Unet().to(device)
# 读取之前训练的权重
if os.path.exists(weight_path):
net.load_state_dict(torch.load(weight_path))
print("SUCCESSFUL LOAD WEIGHT!")
else:
print("NOT SUCCESSFUL LOAD WEIGHT")
# 设置优化器以及损失函数
opt = optim.Adam(net.parameters())
loss_fn = nn.BCELoss()
epochs = 1000
for epoch in range(epochs):
for i, (image, segment_image) in enumerate(data_loader):
image, segment_image = image.to(device), segment_image.to(device)
out_image = net(image)
train_loss = loss_fn(out_image, segment_image)
opt.zero_grad()
train_loss.backward()
opt.step()
# 每训练5个图片输出一次损失
if i % 5 == 0:
print(f'{epoch}-{i}-train_loss---->>{train_loss.item()}')
# 每训练50个图片更新一次权重
if i % 50 == 0:
torch.save(net.state_dict(), weight_path)
# 每训练100个图片
if i % 100 == 0:
_image = image[0]
_segment_image = segment_image[0]
_out_image = out_image[0]
img = torch.stack([_image, _segment_image, _out_image], dim=0)
save_image(img, f'{save_path}/{i}.png')
if __name__ == '__main__':
main()
predict.py
import os.path
import torch
from utils import *
from net import *
from My_DataSet import *
from torchvision.utils import save_image
# 实例化U-Net网络
net = Unet().cuda()
# 读取训练的权重
weights = 'params/unet.pth'
if os.path.exists(weights):
net.load_state_dict(torch.load(weights))
print('SUCCESSFULLY')
else:
print('NO LOADING')
# 输入需要预测的图片的路径
_input = input('please input JPEGImages path:')
# 对图片的格式进行调整
img = keep_image_size_open(_input)
# 指定调用的硬件资源
img_data = transform(img).cuda()
# 在第0维增加一维,因为训练的时候有batch维度,这里需要添加一维
img_data = torch.unsqueeze(img_data, dim=0)
# 得到网络的输出
out = net(img_data)
# 对预测的得到的蒙版进行保存
save_image(out, 'result/result.jpg')
print(out.shape)