前言
查阅众多开源大模型后,打算动手尝试搭建端侧模型,看看效果。选中MiniCPM主要是因为参数小,同时中文支持相对较好。
首先对按照官网提供的demo进行了尝试,然后在colab中完成了一个webui程序并测试,最后通过docker环境在本地搭建并测试成功。
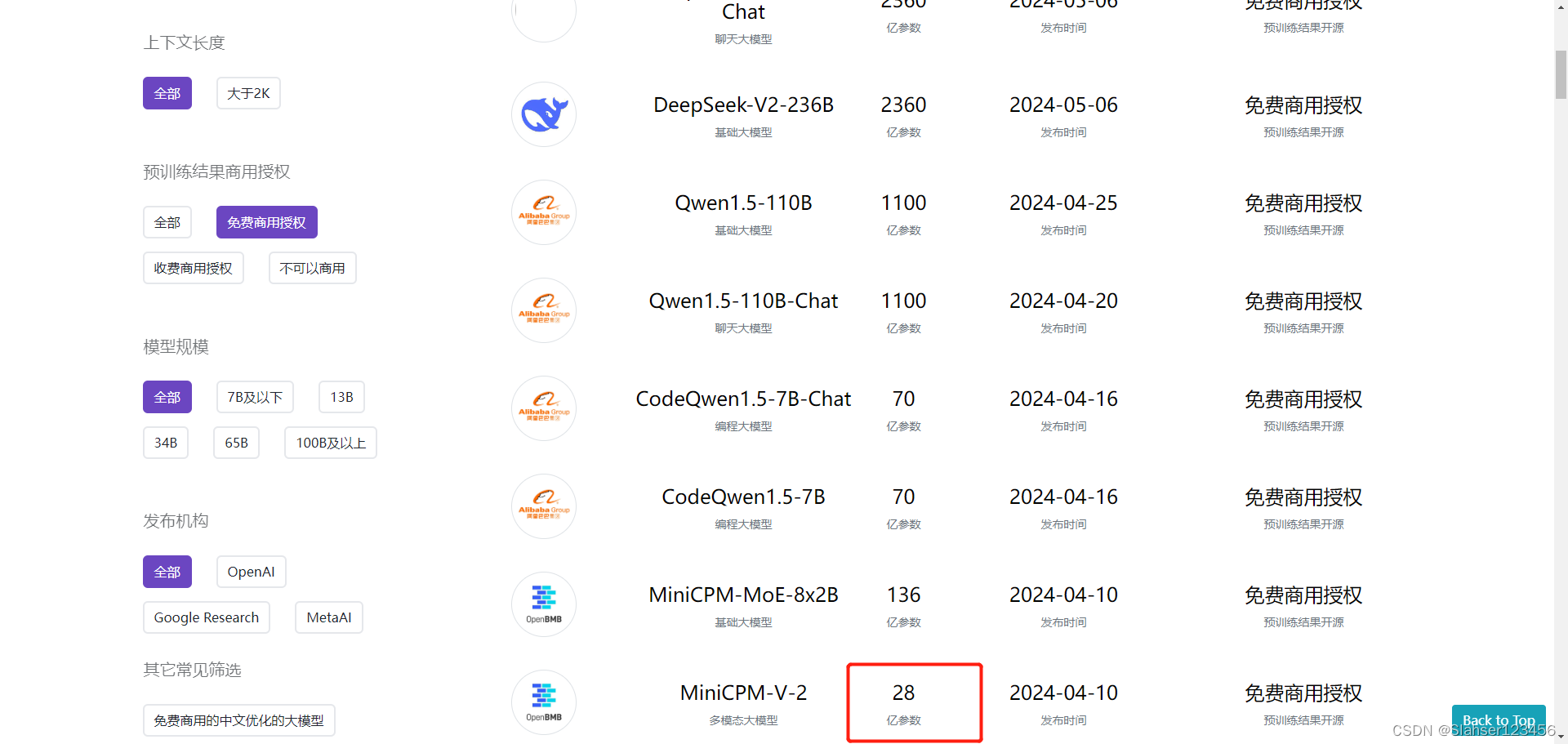
Colab Demo测试
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
torch.manual_seed(0)
path = # model path
tokenizer = AutoTokenizer.from_pretrained(path)
model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.float32, device_map='cuda', trust_remote_code=True)
responds, history = model.chat(tokenizer, "山东省最高的山是哪座山, 它比黄山高还是矮?差距多少?", temperature=0.8, top_p=0.8)
print(responds)编写程序
from typing import List
import argparse
import gradio as gr
import torch
from threading import Thread
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
TextIteratorStreamer
)
import warnings
warnings.filterwarnings('ignore', category=UserWarning, message='TypedStorage is deprecated')
parser = argparse.ArgumentParser()
parser.add_argument("--model_path", type=str, default="")
parser.add_argument("--torch_dtype", type=str, default="bfloat16")
parser.add_argument("--server_name", type=str, default="127.0.0.1")
parser.add_argument("--server_port", type=int, default=7860)
args = parser.parse_args()
# init model torch dtype
torch_dtype = args.torch_dtype
if torch_dtype =="" or torch_dtype == "bfloat16":
torch_dtype = torch.bfloat16
elif torch_dtype == "float32":
torch_dtype = torch.float32
else:
raise ValueError(f"Invalid torch dtype: {torch_dtype}")
# init model and tokenizer
path = args.model_path
tokenizer = AutoTokenizer.from_pretrained(path)
#无显卡auto改为cpu
model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch_dtype, device_map="auto", trust_remote_code=True)
# init gradio demo host and port
server_name=args.server_name
server_port=args.server_port
def hf_gen(dialog: List, top_p: float, temperature: float, max_dec_len: int):
"""generate model output with huggingface api
Args:
query (str): actual model input.
top_p (float): only the smallest set of most probable tokens with probabilities that add up to top_p or higher are kept for generation.
temperature (float): Strictly positive float value used to modulate the logits distribution.
max_dec_len (int): The maximum numbers of tokens to generate.
Yields:
str: real-time generation results of hf model
"""
inputs = tokenizer.apply_chat_template(dialog, tokenize=False, add_generation_prompt=False)
#无显卡去掉.to("cuda")
enc = tokenizer(inputs, return_tensors="pt").to("cuda")
streamer = TextIteratorStreamer(tokenizer)
generation_kwargs = dict(
enc,
do_sample=True,
top_p=top_p,
temperature=temperature,
max_new_tokens=max_dec_len,
pad_token_id=tokenizer.eos_token_id,
streamer=streamer,
)
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
answer = ""
for new_text in streamer:
answer += new_text
yield answer[4 + len(inputs):]
def generate(chat_history: List, query: str, top_p: float, temperature: float, max_dec_len: int):
"""generate after hitting "submit" button
Args:
chat_history (List): [[q_1, a_1], [q_2, a_2], ..., [q_n, a_n]]. list that stores all QA records
query (str): query of current round
top_p (float): only the smallest set of most probable tokens with probabilities that add up to top_p or higher are kept for generation.
temperature (float): strictly positive float value used to modulate the logits distribution.
max_dec_len (int): The maximum numbers of tokens to generate.
Yields:
List: [[q_1, a_1], [q_2, a_2], ..., [q_n, a_n], [q_n+1, a_n+1]]. chat_history + QA of current round.
"""
assert query != "", "Input must not be empty!!!"
# apply chat template
model_input = []
for q, a in chat_history:
model_input.append({"role": "user", "content": q})
model_input.append({"role": "assistant", "content": a})
model_input.append({"role": "user", "content": query})
# yield model generation
chat_history.append([query, ""])
for answer in hf_gen(model_input, top_p, temperature, max_dec_len):
chat_history[-1][1] = answer.strip("</s>")
yield gr.update(value=""), chat_history
def regenerate(chat_history: List, top_p: float, temperature: float, max_dec_len: int):
"""re-generate the answer of last round's query
Args:
chat_history (List): [[q_1, a_1], [q_2, a_2], ..., [q_n, a_n]]. list that stores all QA records
top_p (float): only the smallest set of most probable tokens with probabilities that add up to top_p or higher are kept for generation.
temperature (float): strictly positive float value used to modulate the logits distribution.
max_dec_len (int): The maximum numbers of tokens to generate.
Yields:
List: [[q_1, a_1], [q_2, a_2], ..., [q_n, a_n]]. chat_history
"""
assert len(chat_history) >= 1, "History is empty. Nothing to regenerate!!"
# apply chat template
model_input = []
for q, a in chat_history[:-1]:
model_input.append({"role": "user", "content": q})
model_input.append({"role": "assistant", "content": a})
model_input.append({"role": "user", "content": chat_history[-1][0]})
# yield model generation
for answer in hf_gen(model_input, top_p, temperature, max_dec_len):
chat_history[-1][1] = answer.strip("</s>")
yield gr.update(value=""), chat_history
def clear_history():
"""clear all chat history
Returns:
List: empty chat history
"""
return []
def reverse_last_round(chat_history):
"""reverse last round QA and keep the chat history before
Args:
chat_history (List): [[q_1, a_1], [q_2, a_2], ..., [q_n, a_n]]. list that stores all QA records
Returns:
List: [[q_1, a_1], [q_2, a_2], ..., [q_n-1, a_n-1]]. chat_history without last round.
"""
assert len(chat_history) >= 1, "History is empty. Nothing to reverse!!"
return chat_history[:-1]
# launch gradio demo
with gr.Blocks(theme="soft") as demo:
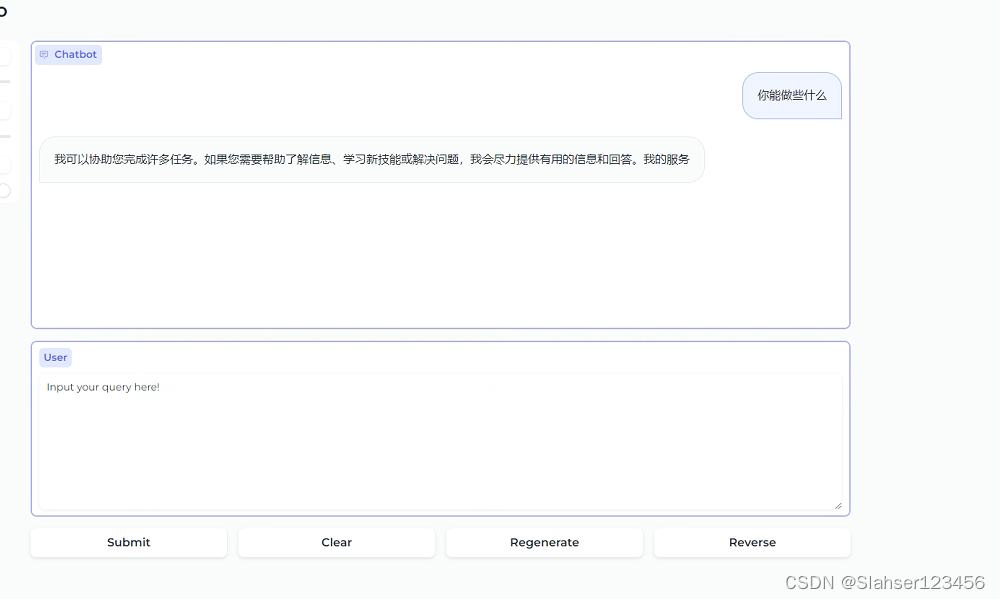
gr.Markdown("""# MiniCPM Gradio Demo""")
with gr.Row():
with gr.Column(scale=1):
top_p = gr.Slider(0, 1, value=0.8, step=0.1, label="top_p")
temperature = gr.Slider(0.1, 2.0, value=0.8, step=0.1, label="temperature")
max_dec_len = gr.Slider(1, 1024, value=1024, step=1, label="max_dec_len")
with gr.Column(scale=5):
chatbot = gr.Chatbot(bubble_full_width=False, height=400)
user_input = gr.Textbox(label="User", placeholder="Input your query here!", lines=8)
with gr.Row():
submit = gr.Button("Submit")
clear = gr.Button("Clear")
regen = gr.Button("Regenerate")
reverse = gr.Button("Reverse")
submit.click(generate, inputs=[chatbot, user_input, top_p, temperature, max_dec_len], outputs=[user_input, chatbot])
regen.click(regenerate, inputs=[chatbot, top_p, temperature, max_dec_len], outputs=[user_input, chatbot])
clear.click(clear_history, inputs=[], outputs=[chatbot])
reverse.click(reverse_last_round, inputs=[chatbot], outputs=[chatbot])
demo.queue()
demo.launch(server_name=server_name, server_port=server_port, show_error=True)Colab程序测试
本地搭建
容器环境
本地搭建一般个人比较倾向使用 Docker 作为运行环境,在投入很少额外资源的情况下,能够快速获得纯净、可复现的一致性非常棒的环境。
除此之外,为了高效运行模型,推荐使用 Nvidia 官方的容器镜像(nvcr.io/nvidia/pytorch:24.01-py3[4])。
我们可以基于上面的内容,快速搭建一个干净、高效的基础运行环境。
考虑到我们可能会将模型应用运行在不同的环境,比如云主机和服务器,它们的网络环境可能有所不同。
当我们本地进行 Docker 镜像构建的时候,配置软件镜像来加速可以大幅改善开发者体验。所以,稍加调整,我们可以得到下面的 Dockerfile 文件:
FROM nvcr.io/nvidia/pytorch:24.01-py3
LABEL maintainer="554686223@qq.com"# setup Ubuntu and PyPi mirrors, refs: https://github.com/soulteary/docker-stable-diffusion-webui/blob/main/docker/Dockerfile.base
ARG USE_CHINA_MIRROR=true
RUN if [ "$USE_CHINA_MIRROR" = "true" ]; then \
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple && \
sed -i 's/security.ubuntu.com/mirrors.tuna.tsinghua.edu.cn/g' /etc/apt/sources.list && \
sed -i 's/archive.ubuntu.com/mirrors.tuna.tsinghua.edu.cn/g' /etc/apt/sources.list; \
fi# install dependencies、
RUN pip install torch==2.2.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
RUN pip install -i https://pypi.tuna.tsinghua.edu.cn/simple transformers==4.37.2 gradio==4.16.0 accelerate==0.26.1
RUN pip uninstall transformer-engine
将上面的内容保存为 Dockerfile,然后执行下面的命令,可以进行镜像构建:
docker build -t my-gpt -f=dockerfile --no-cache .
下载模型
根据自身网络情况,选择HuggingFace、ModelScope、WiseModel中最适合你的模型下载或者在线推理平台。
这里选择了wisemodel,git链接
git clone https://www.wisemodel.cn/OpenBMB/miniCPM-dpo-fp32.git
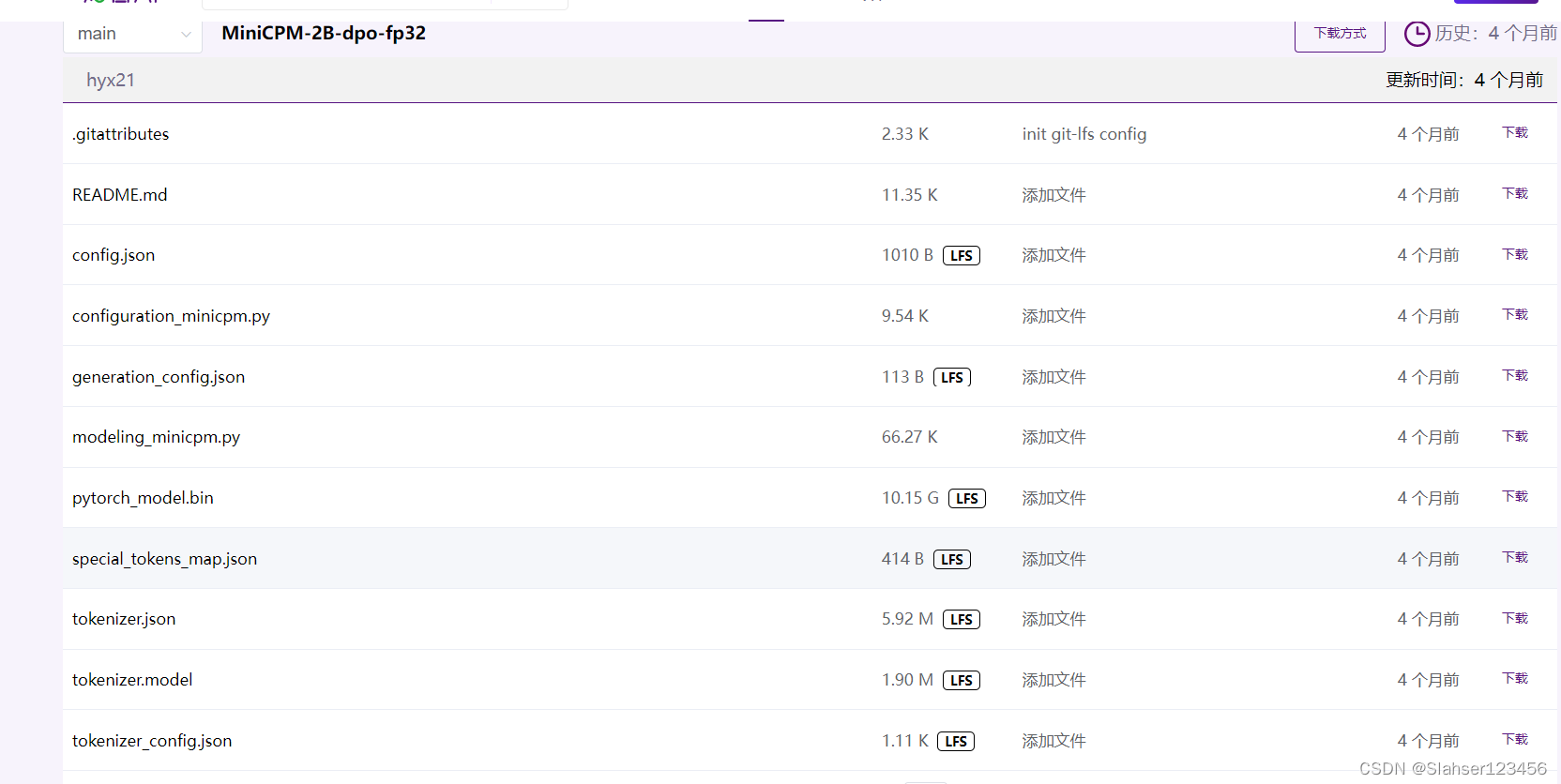
简单测试
启动容器
docker run --rm -it -p 7860:7860 --gpus all --ipc=host --ulimit memlock=-1 -v D:/weiyisoftware/gpttest/gptdocker/models:/app/models -v D:/weiyisoftware/gpttest/gptdocker/workspace:/workspace my-gpt python app.py --model_path=/app/models/OpenBMB/miniCPM-dpo-fp32/ --server_name=0.0.0.0 --torch_dtype=float32
成功后:http://localhost:7860。
ps:因为电脑配置问题,回复很慢。