定时任务概述
在很多应用中我们都是需要执行一些定时任务的,比如定时发送短信,定时统计数据,在实际使用中我们使用什么定时任务框架来实现我们的业务,定时任务使用中会遇到哪些坑,如何最大化的提高定时任务的性能。
我们这里主要介绍单机和分布式两大类的解决方案,并且简要介绍两类方案中的常见的应用组件或者框架的应用场景和基本的实现原理,重点分析下单机的定时任务的实现原理和优缺点。
为什么需要定时任务
常见场景:
- 某系统凌晨要进行数据备份。
- 某媒体聚合平台,每 10 分钟动态抓取某某网站的数据为自己所用。
- 某博客平台,支持定时发送文章。
- 某基金平台,每晚定时计算用户当日收益情况并推送给用户最新的数据。
等等
定时任务选型
单机定时任务
分布式的定时任务框架也是通过单机的原理而来,这里先介绍单机的几种实现方案,并且简单的对比分析
while+sleep方案
实现一个定时任务,可以采用最简单的while循环加sleep休眠的方案。下面是一个每隔5s休眠一次的定时任务案例
public class Scheduled1 {
private static final long timeInterval = 5000;
public static void main(String[] args) {
new Thread(()->{
while(true){
System.out.println("定时任务每隔"+timeInterval+"毫秒执行一次");
try {
Thread.sleep(timeInterval);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}).start();
}
}
实现还是很简单的,但是有一个问题,如果我们不仅仅只有定时5s的,还有3s、10s、20s的如何解决呢?不能每来一个不同的定时任务都需要新启动一个线程,这样会造成很多缺点:代码量巨大、开启线程很多占用内存、上下文切换频繁等
当然,如果这个方式结合redis的zset一样可以作为一个很好的定时任务方案
Timer定时器
定时计划任务功能在Java中主要使用的就是Timer对象,它在内部使用多线程的方式进行处理,所以它和多线程技术还是有非常大的关联的。在JDK中Timer类主要负责计划任务的功能,也就是在指定的时间开始执行某一个任务,但封装任务的类却是TimerTask类
创建定时任务
通过继承 TimerTask 类并实现 run() 方法来自定义要执行的任务
public class TimeTask1 extends TimerTask {
@Override
public void run() {
System.out.println("定时任务运行了");
}
}
调度定时任务
通过执行Timer.schedule(TimerTask task,Date time) 在执行时间运行任务
public class TimeScheduled {
private static final long timeInterval = 5000;
public static void main(String[] args) {
Timer timer = new Timer();
//延时10毫秒,每隔5s执行一次
timer.schedule(new TimeTask1(),10,timeInterval);
}
}
我们发现和我们第一个方案差不多,但是Timer的方案更加科学高效,我们发现他是可以支持延时执行,并且是可以支持定点执行
缺点
比如一个 Timer 一个线程,这就导致 Timer 的任务的执行只能串行执行,一个任务执行时间过长的话会影响其他任务
Timer 类上的有一段注释是这样写的:
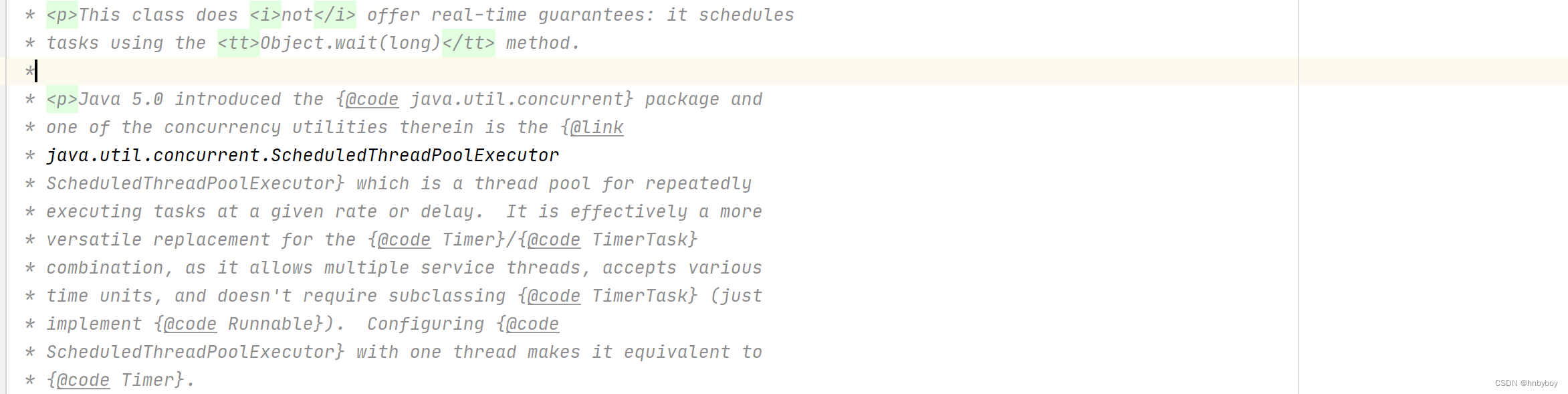
意思就是:ScheduledThreadPoolExecutor 支持多线程执行定时任务并且功能更强大,是 Timer 的替代品
线程池方式
ScheduledExecutorService 是一个接口,有多个实现类,比较常用的ScheduledThreadPoolExecutor ,
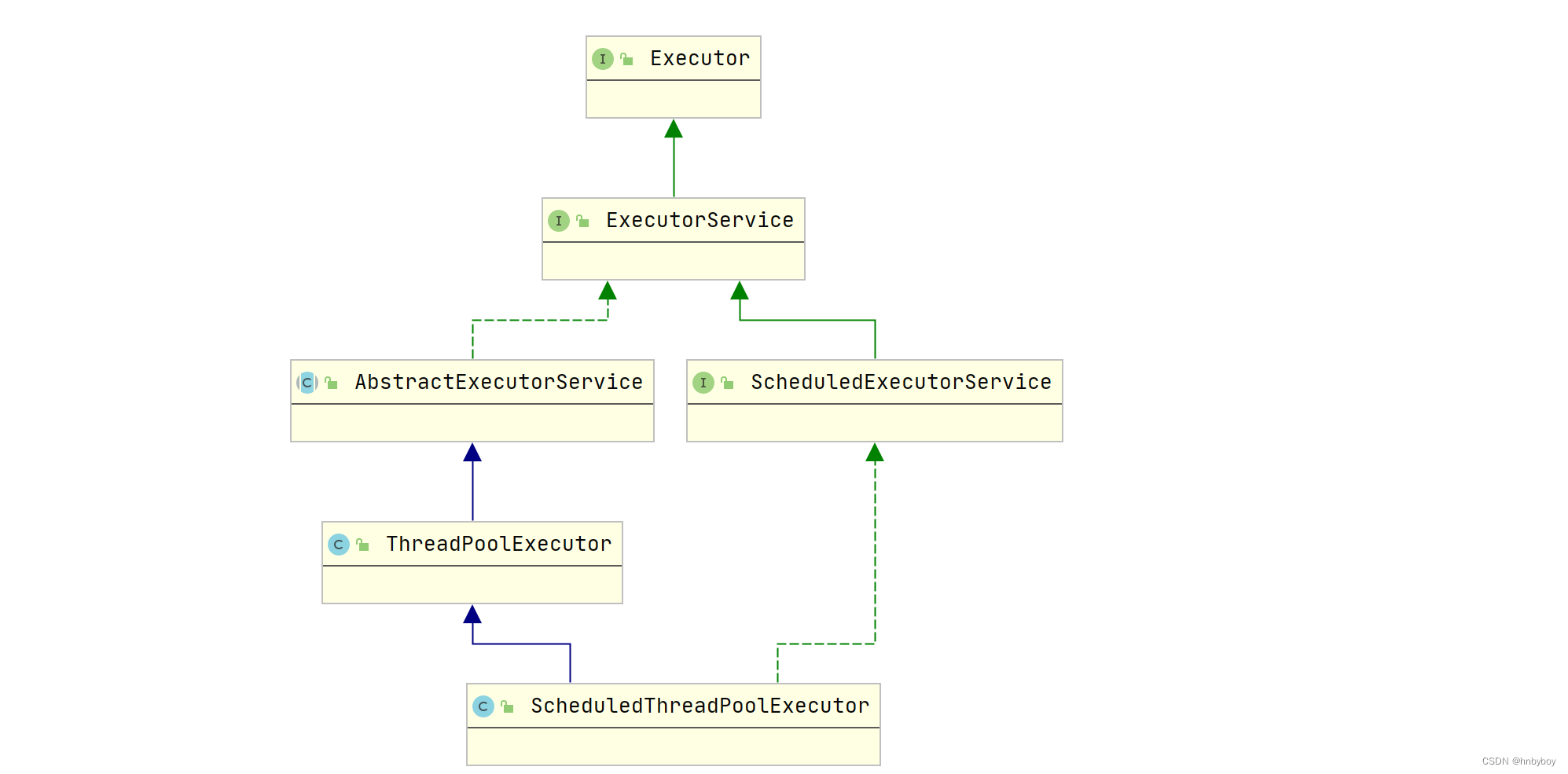
jdk自带的一个类是基于线程池设计的定时任务类,每个调度任务都会分配到线程池中的一个线程去执行,也就是说,任务是并发执行,互不影响
public class ScheduledExecutor {
public static void main(String[] args) {
ScheduledExecutorService service = Executors.newSingleThreadScheduledExecutor();
service.scheduleAtFixedRate(() -> System.out.println("执行任务"), 10, 5, TimeUnit.SECONDS);
}
}
不论是使用 Timer 还是 ScheduledExecutorService 都无法使用 Cron 表达式指定任务执行的具体时间。
SpringTask
SpringTask是Spring自主研发的轻量级定时任务工具,相比于Quartz更加简单方便,且不需要引入其他依赖即可使用
启动SpringTask
在配置类中添加一个@EnableScheduling注解即可开启SpringTask的定时任务
@SpringBootApplication
//启用定时任务的配置
@EnableScheduling
public class SpringTaskApplication {
public static void main(String[] args) {
SpringApplication.run(SpringTaskApplication.class);
}
}
创建任务类
我们直接通过 Spring 提供的 @Scheduled 注解即可定义定时任务,非常方便!
@Component
public class SpringTask {
@Scheduled(cron = "0/5 * * * * ?")
public void testTask() throws InterruptedException {
System.out.println("执行SpringTask任务,时间:" + LocalDateUtils.getLocalDateTimeStr());
}
}
支持Cron表达式
Spring Task 支持 Cron 表达式
Cron 表达式主要用于定时作业(定时任务)系统定义执行时间或执行频率的表达式,非常厉害,你可以通过 Cron 表达式进行设置定时任务每天或者每个月什么时候执行等等操作
推荐一个在线 Cron 表达式生成器:http://cron.qqe2.com/
优缺点
优点:简单,轻量,支持 Cron 表达式
缺点 :功能单一
分布式定时任务
上面提到的一些定时任务的解决方案都是在单机下执行的,适用于比较简单的定时任务场景比如每天凌晨备份一次数据等
如果我们需要一些高级特性比如支持任务在分布式场景下的分片和高可用的话,我们就需要用到分布式任务调度框架了
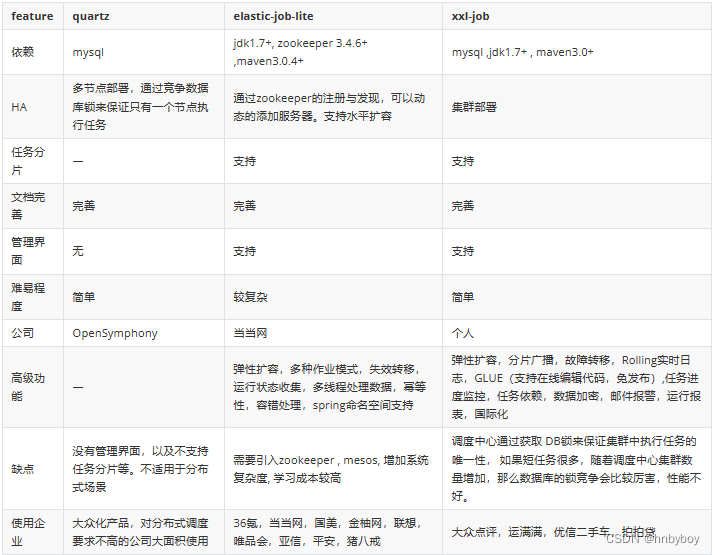
Quartz
Quartz是一个完全由Java编写的开源任务调度的框架,通过触发器设置作业定时运行规则,控制作业的运行时间,其中quartz集群通过故障切换和负载平衡的功能,能给调度器带来高可用性和伸缩性
quartz也是用的比较多的定时任务,很多分布式定时任务或者定制定时任务都是基于quartz来实现的,比如elastic-job就是借鉴quartz来实现的
优缺点
优点:可以与 Spring 集成,并且支持动态添加任务和集群。
缺点 :分布式支持不友好,没有内置 UI 管理控制台、使用麻烦(相比于其他同类型框架来说)
Elastic-Job
Elastic-job是当当网张亮主导开发的分布式任务调度框架,结合zookeeper技术解决quartz框架在分布式系统中重复的定时任务导致的不可预见的错误,功能丰富强大,实现任务高可用以及分片
Elastic-Job 中的定时调度都是由执行器自行触发,这种设计也被称为去中心化设计(调度和处理都是执行器单独完成)。
优缺点总结
优点 :可以与 Spring 集成、支持分布式、支持集群、性能不错
缺点 :依赖了额外的中间件比如 Zookeeper(复杂度增加,可靠性降低、维护成本变高)
XXL-JOB
XXL-JOB 于 2015 年开源,是一款优秀的轻量级分布式任务调度框架,支持任务可视化管理、弹性扩容缩容、任务失败重试和告警、任务分片等功能
不同于 Elastic-Job 的去中心化设计, XXL-JOB 的采用了中心化设计(调度中心调度多个执行器执行任务)
和 Quzrtz 类似 XXL-JOB 也是基于数据库锁调度任务,存在性能瓶颈,不过,一般在任务量不是特别大的情况下,没有什么影响的,可以满足绝大部分公司的要求。
优缺点总结
优点:开箱即用(学习成本比较低)、与 Spring 集成、支持分布式、支持集群、内置了 UI 管理控制台。
缺点:不支持动态添加任务(如果一定想要动态创建任务也是支持的)。
组件对比:
Quartz框架
quartz特点
Quartz是一个优秀的任务调度框架, 具有以下特点
强大的调度功能,例如支持丰富多样的调度方法,可以满足各种常规及特殊需求;
负载均衡
高可用
quartz 架构体系
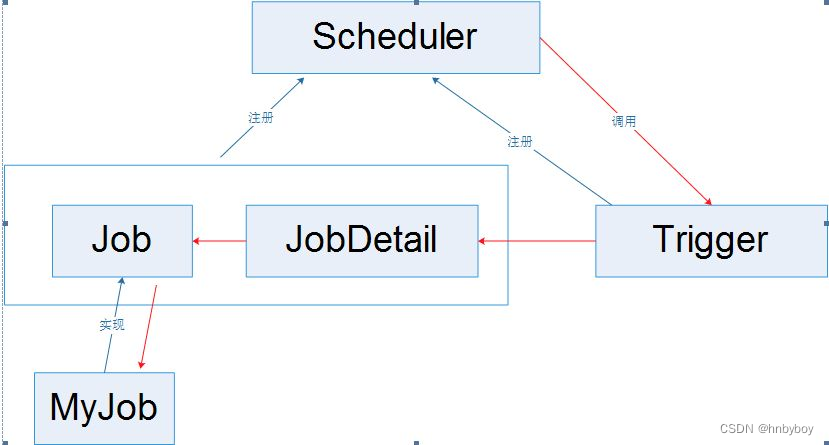
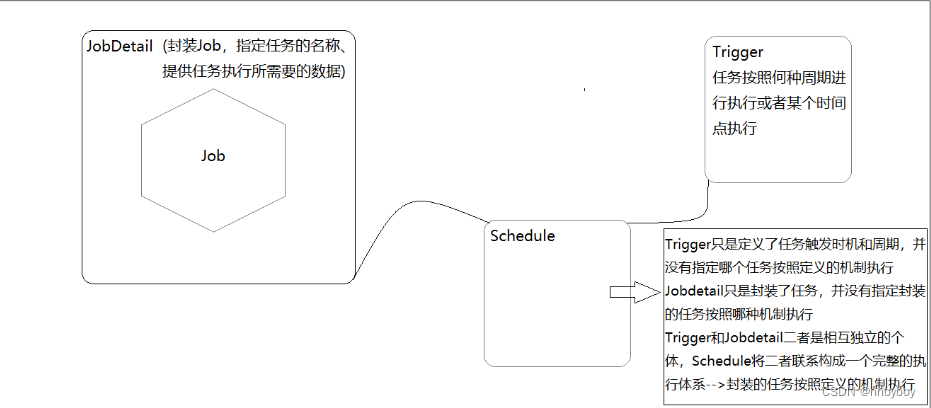
Quartz 设计有四个核心类,分别是Scheduler(调度器)、Job(任务) 、Trigger(触发器)、JobDetail(任务详情),他们是使用Quartz的关键。
job - 任务 - 你要做什么事?
JobDetail - - 数据 - 你要做什么事,需要什么数据?
Trigger - 触发器 - 你什么时候去做
Scheduler - 任务调度 - 你什么时候需要去做什么事?
调度器作为作业的总指挥,触发器作为作业的操作者,作业为应用的功能模块,其关系如下图所示:
Job接口
定时任务的接口,具体定时任务需要实现该接口
定义需要执行的任务,该类是一个接口,只定义了一个方法execute(JobExecutionContext context),在实现类的execute方法中编写所需要定时执行的Job(任务),JobExcutionContext类提供了调度应用的一些信息。Job运行时的信息保存在JobDataMap实例中。
public class MyJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
System.out.println("开始执行定时任务...");
}
}
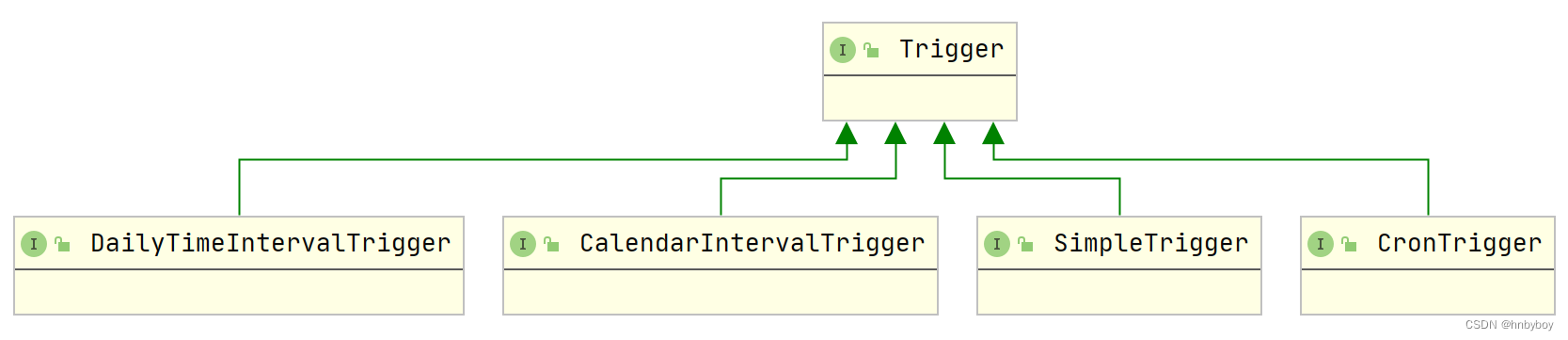
Trigger接口
负责设置调度策略,该类是一个接口,描述触发job执行的时间触发规则
有以下这些子类,其中经常用到的是cronTigger
公共属性
triggerKey:表示Trigger身份的属性
jobKey:Trigger触发时被执行的Job的身份
startTime:Trigger第一次触发的时间
endTime:Trigger失效的时间点
优先级(priority):如果Trigger很多,或者Quartz线程池的工作线程太少,Quartz可能没有足够的资源同时触发所有的Trigger,这种情况下,如果希望某些Trigger优先被触发,就需要给它设置优先级,Trigger默认的优先级为5,优先级priority属性的值可以是任意整数,正数、负数都可以。(只有同时触发的Trigger之间才会比较优先级)
SimpleTrigger
指定从某一个时间开始,以一定时间间隔(单位:毫秒)执行的任务
关键属性:
repeatInterval:重复间隔
repeatCount:重复次数,实际执行次数是repeatCount+1(因为在startTime的时候一定会执行一次)
TriggerBuilder.newTrigger()
//设置Trigger的name以及group
.withIdentity("my_job_tigger", "my_job_tigger_group")
//trigger 开始生效时间
.startAt(new Date(System.currentTimeMillis() + 5000))
//调度策略
.withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(5).withRepeatCount(10))
//trigger开始失效时间
.endAt(new Date(System.currentTimeMillis() + 15000))
//任务名词
.forJob("自定义JOB")
.build();
DailyTimeIntervalTrigger
指定每天的某个时间段内,以一定的时间间隔执行任务,并且它可以支持指定星期
关键属性
startTimeOfDay:每天开始时间
endTimeOfDay:每天结束时间
daysOfWeek:需要执行的星期
TriggerBuilder.newTrigger()
//设置Trigger的name以及group
.withIdentity("my_job_tigger", "my_job_tigger_group")
//trigger 开始生效时间
.startNow()
//调度策略
.withSchedule(DailyTimeIntervalScheduleBuilder.dailyTimeIntervalSchedule()
//早上10点开始执行
.startingDailyAt(TimeOfDay.hourAndMinuteOfDay(10, 0))
//晚上8点停止执行
.endingDailyAt(TimeOfDay.hourAndMinuteOfDay(20, 0))
// 周一到周四执行,不写即每天执行
.onDaysOfTheWeek(DateBuilder.MONDAY, DateBuilder.TUESDAY, DateBuilder.WEDNESDAY, DateBuilder.THURSDAY)
//一小时执行一次
.withIntervalInHours(1)
//重复执行10次,总共执行11次
.withRepeatCount(10)
)
//trigger开始失效时间
.endAt(new Date(System.currentTimeMillis() + 15000))
//任务名词
.forJob("calendar_tigger_test")
.build();
CronTrigger
适合于更复杂的任务,它支持类型于Linux Cron的语法(并且更强大)
TriggerBuilder.newTrigger()
//设置Trigger的name以及group
.withIdentity("my_job_tigger", "my_job_tigger_group")
//trigger 开始生效时间
.startNow()
//调度策略 每隔5S执行一次
.withSchedule(CronScheduleBuilder.cronSchedule("*/5 * * * * ?"))
//trigger开始失效时间
.endAt(new Date(System.currentTimeMillis() + 15000))
//任务名词
.forJob("calendar_tigger_test")
.build();
JobDetail
描述Job的实现类及其它相关的静态信息,如:Job名字、描述、关联监听器等信息
Quartz在每次执行Job时,都重新创建一个Job实例,所以它不直接接受一个Job的实例,相反它接收一个Job实现类,以便运行时通过newInstance()的反射机制实例化Job。
因此需要通过一个类来描述Job的实现类及其它相关的静态信息,如Job名字、描述、关联监听器等信息,JobDetail承担了这一角色,JobDetail 用来保存我们作业的详细信息。
一个JobDetail可以有多个Trigger,但是一个Trigger只能对应一个JobDetail
JobBuilder.newJob(MyJob.class).withIdentity("MyJob_1", "JobGroup_1").build();
Scheduler
调度器就相当于一个容器,装载着任务和触发器
Scheduler负责管理Quartz的运行环境,Quartz它是基于多线程架构的,它启动的时候会初始化一套线程,这套线程会用来执行一些预置的作业。
Trigger和JobDetail可以注册到Scheduler中,Scheduler可以将Trigger绑定到某一JobDetail中,这样当Trigger触发时,对应的Job就被执行
Scheduler拥有一个SchedulerContext,它类似于ServletContext,保存着Scheduler上下文信息,Job和Trigger都可以访问SchedulerContext内的信息。Scheduler使用一个线程池作为任务运行的基础设施,任务通过共享线程池中的线程提高运行效率
创建调度器
Scheduler接口有两个实现类,分别为StdScheduler(标准默认调度器)和RemoteScheduler(远程调度器),我们重点介绍下StdScheduler实例,StdScheduler只提供了一个带参构造方法,此构造需要传递QuartzScheduler和SchedulingContext两个实例参数
public StdScheduler(QuartzScheduler sched, SchedulingContext schedCtxt)
然而我们一般不使用构造方法去创建调度器,而是通过调度器工厂来创建,调度器工厂接口SchedulerFactory提供了两种不同类型的工厂实现,分别是DirectSchedulerFactory和StdSchedulerFactory
而DirectSchedulerFactory一般用的比较少,更多的场景下我们使用StdSchedulerFactory工厂来创建
创建方式
StdSchedulerFactory提供三种方式创建调度器实例
通过java.util.Properties属性实例
通过外部属性文件提供
通过有属性文件内容的 java.io.InputStream 文件流提供
public static void main(String[] args) {
try {
StdSchedulerFactory schedulerFactory = new StdSchedulerFactory();
// 第一种方式 通过Properties属性实例创建
Properties props = new Properties();
props.put(StdSchedulerFactory.PROP_THREAD_POOL_CLASS, "org.quartz.simpl.SimpleThreadPool");
props.put("org.quartz.threadPool.threadCount", 5);
schedulerFactory.initialize(props);
// 第二种方式 通过传入文件名
// schedulerFactory.initialize("my.properties");
// 第三种方式 通过传入包含属性内容的文件输入流
// InputStream is = new FileInputStream(new File("my.properties"));
// schedulerFactory.initialize(is);
// 获取调度器实例
Scheduler scheduler = schedulerFactory.getScheduler();
} catch (Exception e) {
e.printStackTrace();
}
}
集群方案
上面的单机方案存在着单点问题,如果定时任务在多个服务器上运行,则会重复触发,为了解决这些问题,就需要使用quartz的集群方案
集群架构
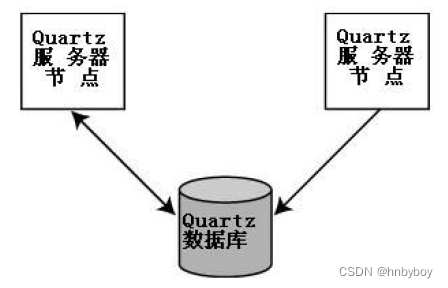
一个Quartz集群中的每个节点是一个独立的Quartz应用,它又管理着其他的节点。
这就意味着你必须对每个节点分别启动或停止,Quartz集群中,独立的Quartz节点并不与另一节点或是管理节点通信,而是通过相同的数据库表来感知到另一Quartz应用的
初始化数据库
docker run -itd --name mysql-quartz -p 3306:3306 -v /opt/scheduleTask/quartz:/opt -e MYSQL_ROOT_PASSWORD=123456 mysql:5.7
docker exec -it mysql-quartz bash
mysql> create database quartz default charset 'utf8';
mysql> use quartz;
mysql> source /opt/tables_mysql.sql
因为Quartz集群依赖于数据库,所以必须首先创建Quartz数据库表,Quartz发布包中包括了所有被支持的数据库平台的SQL脚本
这些SQL脚本存放于<quartz_home>/docs/dbTables 目录下找到对应数据库的SQL文件这里采用的是tables_mysql.sql
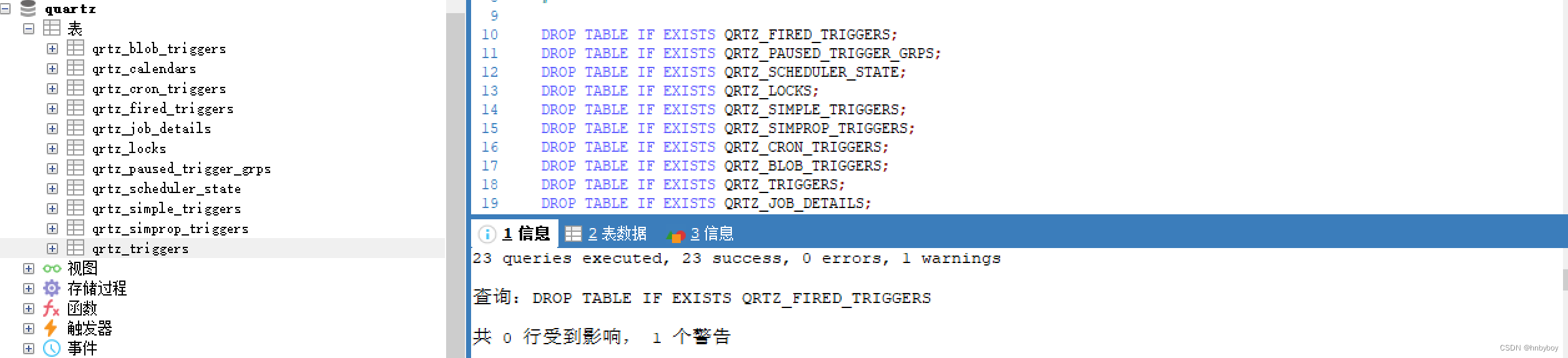
对应表简单含义如下:

引入pom
<!--quartz SpringBoot starter-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<!--druid 数据连接池-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.17</version>
</dependency>
<!--jpa 支持-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<!-- https://mvnrepository.com/artifact/commons-lang/commons-lang -->
<dependency>
<groupId>commons-lang</groupId>
<artifactId>commons-lang</artifactId>
<version>2.6</version>
</dependency>
编辑quartz.properties
org.quartz.scheduler.instanceName=SsmScheduler
# new add
org.quartz.scheduler.instanceId=AUTO
org.quartz.scheduler.wrapJobExecutionInUserTransaction=false
org.quartz.threadPool.class=org.quartz.simpl.SimpleThreadPool
org.quartz.threadPool.threadCount=10
org.quartz.threadPool.threadPriority=5
org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread=true
#============================================================================
# Configure JobStore
#============================================================================
org.quartz.jobStore.class=org.quartz.impl.jdbcjobstore.JobStoreTX
org.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.StdJDBCDelegate
org.quartz.jobStore.useProperties=true
org.quartz.jobStore.tablePrefix=QRTZ_
org.quartz.jobStore.misfireThreshold=60000
org.quartz.jobStore.isClustered=true
org.quartz.jobStore.clusterCheckinInterval=2000
org.quartz.jobStore.dataSource=qzDS
#============================================================================
# Configure Datasources
#============================================================================
#JDBC??
org.quartz.dataSource.qzDS.driver:com.mysql.jdbc.Driver
org.quartz.dataSource.qzDS.URL:jdbc:mysql://192.168.56.101:3306/quartz_job?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8&useSSL=false
org.quartz.dataSource.qzDS.user:root
org.quartz.dataSource.qzDS.password:root
org.quartz.dataSource.qzDS.maxConnection:10
org.quartz.dataSource.qzDS.connectionProvider.class=com.itcast.yongheng.quartzjob.cluster.DruidConnectionProvider
整合SpringBoot
注册Quartz注册工厂
该类是将quartz自己创建的类交给spring进行管理以及自动注入
@Component
public class QuartzJobFactory extends AdaptableJobFactory {
@Autowired
private AutowireCapableBeanFactory capableBeanFactory;
@Override
protected Object createJobInstance(TriggerFiredBundle bundle) throws Exception {
//调用父类的方法
Object jobInstance = super.createJobInstance(bundle);
//进行注入
capableBeanFactory.autowireBean(jobInstance);
return jobInstance;
}
}
注册调度工厂
@Configuration
public class QuartzConfig {
@Autowired
private QuartzJobFactory jobFactory;
@Bean
public SchedulerFactoryBean schedulerFactoryBean() throws IOException {
//获取配置属性
PropertiesFactoryBean propertiesFactoryBean = new PropertiesFactoryBean();
propertiesFactoryBean.setLocation(new ClassPathResource("/quartz.properties"));
//在quartz.properties中的属性被读取并注入后再初始化对象
propertiesFactoryBean.afterPropertiesSet();
//创建SchedulerFactoryBean
SchedulerFactoryBean factory = new SchedulerFactoryBean();
factory.setQuartzProperties(propertiesFactoryBean.getObject());
factory.setJobFactory(jobFactory);//支持在JOB实例中注入其他的业务对象
factory.setApplicationContextSchedulerContextKey("applicationContextKey");
factory.setWaitForJobsToCompleteOnShutdown(true);//这样当spring关闭时,会等待所有已经启动的quartz job结束后spring才能完全shutdown。
factory.setOverwriteExistingJobs(false);//是否覆盖己存在的Job
factory.setStartupDelay(10);//QuartzScheduler 延时启动,应用启动完后 QuartzScheduler 再启动
return factory;
}
/**
* 通过SchedulerFactoryBean获取Scheduler的实例
*
* @return
* @throws IOException
* @throws SchedulerException
*/
@Bean(name = "scheduler")
public Scheduler scheduler() throws IOException, SchedulerException {
Scheduler scheduler = schedulerFactoryBean().getScheduler();
return scheduler;
}
}
配置Quartz数据源
默认 Quartz 的数据连接池是 c3p0,由于性能不太稳定,不推荐使用,因此我们将其改成driud数据连接池
public class DruidConnectionProvider implements ConnectionProvider {
/**
* 常量配置,与quartz.properties文件的key保持一致(去掉前缀),同时提供set方法,Quartz框架自动注入值。
*
* @return
* @throws SQLException
*/
//JDBC驱动
public String driver;
//JDBC连接串
public String URL;
//数据库用户名
public String user;
//数据库用户密码
public String password;
//数据库最大连接数
public int maxConnection;
//数据库SQL查询每次连接返回执行到连接池,以确保它仍然是有效的。
public String validationQuery;
private boolean validateOnCheckout;
private int idleConnectionValidationSeconds;
public String maxCachedStatementsPerConnection;
private String discardIdleConnectionsSeconds;
public static final int DEFAULT_DB_MAX_CONNECTIONS = 10;
public static final int DEFAULT_DB_MAX_CACHED_STATEMENTS_PER_CONNECTION = 120;
//Druid连接池
private DruidDataSource datasource;
@Override
public Connection getConnection() throws SQLException {
return datasource.getConnection();
}
@Override
public void shutdown() throws SQLException {
datasource.close();
}
@Override
public void initialize() throws SQLException {
if (this.URL == null) {
throw new SQLException("DBPool could not be created: DB URL cannot be null");
}
if (this.driver == null) {
throw new SQLException("DBPool driver could not be created: DB driver class name cannot be null!");
}
if (this.maxConnection < 0) {
throw new SQLException("DBPool maxConnectins could not be created: Max connections must be greater than zero!");
}
datasource = new DruidDataSource();
try {
datasource.setDriverClassName(this.driver);
} catch (Exception e) {
try {
throw new SchedulerException("Problem setting driver class name on datasource: " + e.getMessage(), e);
} catch (SchedulerException e1) {
}
}
datasource.setUrl(this.URL);
datasource.setUsername(this.user);
datasource.setPassword(this.password);
datasource.setMaxActive(this.maxConnection);
datasource.setMinIdle(1);
datasource.setMaxWait(0);
datasource.setMaxPoolPreparedStatementPerConnectionSize(DEFAULT_DB_MAX_CONNECTIONS);
if (this.validationQuery != null) {
datasource.setValidationQuery(this.validationQuery);
if (!this.validateOnCheckout) {
datasource.setTestOnReturn(true);
} else {
datasource.setTestOnBorrow(true);
}
datasource.setValidationQueryTimeout(this.idleConnectionValidationSeconds);
}
}
public String getDriver() {
return driver;
}
public void setDriver(String driver) {
this.driver = driver;
}
public String getURL() {
return URL;
}
public void setURL(String URL) {
this.URL = URL;
}
public String getUser() {
return user;
}
public void setUser(String user) {
this.user = user;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public int getMaxConnection() {
return maxConnection;
}
public void setMaxConnection(int maxConnection) {
this.maxConnection = maxConnection;
}
public String getValidationQuery() {
return validationQuery;
}
public void setValidationQuery(String validationQuery) {
this.validationQuery = validationQuery;
}
public boolean isValidateOnCheckout() {
return validateOnCheckout;
}
public void setValidateOnCheckout(boolean validateOnCheckout) {
this.validateOnCheckout = validateOnCheckout;
}
public int getIdleConnectionValidationSeconds() {
return idleConnectionValidationSeconds;
}
public void setIdleConnectionValidationSeconds(int idleConnectionValidationSeconds) {
this.idleConnectionValidationSeconds = idleConnectionValidationSeconds;
}
public DruidDataSource getDatasource() {
return datasource;
}
public void setDatasource(DruidDataSource datasource) {
this.datasource = datasource;
}
public String getDiscardIdleConnectionsSeconds() {
return discardIdleConnectionsSeconds;
}
public void setDiscardIdleConnectionsSeconds(String discardIdleConnectionsSeconds) {
this.discardIdleConnectionsSeconds = discardIdleConnectionsSeconds;
}
}
创建完成之后,还需要在quartz.properties配置文件中设置以下数据源
#数据库连接池,将其设置为druid
org.quartz.dataSource.qzDS.connectionProvider.class=com.itcast.yongheng.quartzjob.cluster.DruidConnectionProvider
任务管理
默认quartz的功能是有限的,我们可以自己实现quartz的任务管理,比如添加、删除、暂停、运行定时任务
管理接口
该接口是定时任务的管理接口,可以对定时任务进行管理
public interface QuartzJobService {
/**
* 添加任务可以传参数
* @param clazzName
* @param jobName
* @param groupName
* @param cronExp
* @param param
*/
void addJob(String clazzName, String jobName, String groupName, String cronExp, Map<String, Object> param);
/**
* 暂停任务
* @param jobName
* @param groupName
*/
void pauseJob(String jobName, String groupName);
/**
* 恢复任务
* @param jobName
* @param groupName
*/
void resumeJob(String jobName, String groupName);
/**
* 立即运行一次定时任务
* @param jobName
* @param groupName
*/
void runOnce(String jobName, String groupName);
/**
* 更新任务
* @param jobName
* @param groupName
* @param cronExp
* @param param
*/
void updateJob(String jobName, String groupName, String cronExp, Map<String, Object> param);
/**
* 删除任务
* @param jobName
* @param groupName
*/
void deleteJob(String jobName, String groupName);
/**
* 启动所有任务
*/
void startAllJobs();
/**
* 暂停所有任务
*/
void pauseAllJobs();
/**
* 恢复所有任务
*/
void resumeAllJobs();
/**
* 关闭所有任务
*/
void shutdownAllJobs();
}
管理实现类
该类是定时任务的具体实现,是实现了quartz的各种操作
@Service
public class QuartzJobServiceImpl implements QuartzJobService {
private static final Logger log = LoggerFactory.getLogger(QuartzJobServiceImpl.class);
@Autowired
private Scheduler scheduler;
@Override
public void addJob(String clazzName, String jobName, String groupName, String cronExp, Map<String, Object> param) {
try {
// 启动调度器,默认初始化的时候已经启动
// scheduler.start();
//构建job信息
Class<? extends Job> jobClass = (Class<? extends Job>) Class.forName(clazzName);
JobDetail jobDetail = JobBuilder.newJob(jobClass).withIdentity(jobName, groupName).build();
//表达式调度构建器(即任务执行的时间)
CronScheduleBuilder scheduleBuilder = CronScheduleBuilder.cronSchedule(cronExp);
//按新的cronExpression表达式构建一个新的trigger
CronTrigger trigger = TriggerBuilder.newTrigger().withIdentity(jobName, groupName).withSchedule(scheduleBuilder).build();
//获得JobDataMap,写入数据
if (param != null) {
trigger.getJobDataMap().putAll(param);
}
scheduler.scheduleJob(jobDetail, trigger);
} catch (Exception e) {
log.error("创建任务失败", e);
}
}
@Override
public void pauseJob(String jobName, String groupName) {
try {
scheduler.pauseJob(JobKey.jobKey(jobName, groupName));
} catch (SchedulerException e) {
log.error("暂停任务失败", e);
}
}
@Override
public void resumeJob(String jobName, String groupName) {
try {
scheduler.resumeJob(JobKey.jobKey(jobName, groupName));
} catch (SchedulerException e) {
log.error("恢复任务失败", e);
}
}
@Override
public void runOnce(String jobName, String groupName) {
try {
scheduler.triggerJob(JobKey.jobKey(jobName, groupName));
} catch (SchedulerException e) {
log.error("立即运行一次定时任务失败", e);
}
}
@Override
public void updateJob(String jobName, String groupName, String cronExp, Map<String, Object> param) {
try {
TriggerKey triggerKey = TriggerKey.triggerKey(jobName, groupName);
CronTrigger trigger = (CronTrigger) scheduler.getTrigger(triggerKey);
if (cronExp != null) {
// 表达式调度构建器
CronScheduleBuilder scheduleBuilder = CronScheduleBuilder.cronSchedule(cronExp);
// 按新的cronExpression表达式重新构建trigger
trigger = trigger.getTriggerBuilder().withIdentity(triggerKey).withSchedule(scheduleBuilder).build();
}
//修改map
if (param != null) {
trigger.getJobDataMap().putAll(param);
}
// 按新的trigger重新设置job执行
scheduler.rescheduleJob(triggerKey, trigger);
} catch (Exception e) {
log.error("更新任务失败", e);
}
}
@Override
public void deleteJob(String jobName, String groupName) {
try {
//暂停、移除、删除
scheduler.pauseTrigger(TriggerKey.triggerKey(jobName, groupName));
scheduler.unscheduleJob(TriggerKey.triggerKey(jobName, groupName));
scheduler.deleteJob(JobKey.jobKey(jobName, groupName));
} catch (Exception e) {
log.error("删除任务失败", e);
}
}
@Override
public void startAllJobs() {
try {
scheduler.start();
} catch (Exception e) {
log.error("开启所有的任务失败", e);
}
}
@Override
public void pauseAllJobs() {
try {
scheduler.pauseAll();
} catch (Exception e) {
log.error("暂停所有任务失败", e);
}
}
@Override
public void resumeAllJobs() {
try {
scheduler.resumeAll();
} catch (Exception e) {
log.error("恢复所有任务失败", e);
}
}
@Override
public void shutdownAllJobs() {
try {
if (!scheduler.isShutdown()) {
// 需谨慎操作关闭scheduler容器
// scheduler生命周期结束,无法再 start() 启动scheduler
scheduler.shutdown(true);
}
} catch (Exception e) {
log.error("关闭所有的任务失败", e);
}
}
}
API接口
通过实现该接口可以通过外部API对定时任务进行管理
@RestController
@RequestMapping("/quartz")
public class QuartzController {
private static final Logger log = LoggerFactory.getLogger(QuartzController.class);
@Autowired
private QuartzJobService quartzJobService;
/**
* 添加新任务
*
* @param configDTO
* @return
*/
@RequestMapping("/addJob")
public Object addJob(@RequestBody QuartzConfigDTO configDTO) {
quartzJobService.addJob(configDTO.getJobClass(), configDTO.getJobName(), configDTO.getGroupName(), configDTO.getCronExpression(), configDTO.getParam());
return HttpStatus.OK;
}
/**
* 暂停任务
*
* @param configDTO
* @return
*/
@RequestMapping("/pauseJob")
public Object pauseJob(@RequestBody QuartzConfigDTO configDTO) {
quartzJobService.pauseJob(configDTO.getJobName(), configDTO.getGroupName());
return HttpStatus.OK;
}
/**
* 恢复任务
*
* @param configDTO
* @return
*/
@RequestMapping("/resumeJob")
public Object resumeJob(@RequestBody QuartzConfigDTO configDTO) {
quartzJobService.resumeJob(configDTO.getJobName(), configDTO.getGroupName());
return HttpStatus.OK;
}
/**
* 立即运行一次定时任务
*
* @param configDTO
* @return
*/
@RequestMapping("/runOnce")
public Object runOnce(@RequestBody QuartzConfigDTO configDTO) {
quartzJobService.runOnce(configDTO.getJobName(), configDTO.getGroupName());
return HttpStatus.OK;
}
/**
* 更新任务
*
* @param configDTO
* @return
*/
@RequestMapping("/updateJob")
public Object updateJob(@RequestBody QuartzConfigDTO configDTO) {
quartzJobService.updateJob(configDTO.getJobName(), configDTO.getGroupName(), configDTO.getCronExpression(), configDTO.getParam());
return HttpStatus.OK;
}
/**
* 删除任务
*
* @param configDTO
* @return
*/
@RequestMapping("/deleteJob")
public Object deleteJob(@RequestBody QuartzConfigDTO configDTO) {
quartzJobService.deleteJob(configDTO.getJobName(), configDTO.getGroupName());
return HttpStatus.OK;
}
/**
* 启动所有任务
*
* @return
*/
@RequestMapping("/startAllJobs")
public Object startAllJobs() {
quartzJobService.startAllJobs();
return HttpStatus.OK;
}
/**
* 暂停所有任务
*
* @return
*/
@RequestMapping("/pauseAllJobs")
public Object pauseAllJobs() {
quartzJobService.pauseAllJobs();
return HttpStatus.OK;
}
/**
* 恢复所有任务
*
* @return
*/
@RequestMapping("/resumeAllJobs")
public Object resumeAllJobs() {
quartzJobService.resumeAllJobs();
return HttpStatus.OK;
}
/**
* 关闭所有任务
*
* @return
*/
@RequestMapping("/shutdownAllJobs")
public Object shutdownAllJobs() {
quartzJobService.shutdownAllJobs();
return HttpStatus.OK;
}
}
添加定时任务
调用服务接口,添加自己的定时任务
127.0.0.1:8084/quartz/addJob
接口参数如下:
{
"jobName":"myJob",
"groupName":"default",
"jobClass":"com.itcast.yongheng.quartzjob.jobs.QuartzDemo1",
"cronExpression":"0/5 * * * * ?",
"param":{
"hello":"world"
}
}
ElasticJob
ElasticJob 诞生于 2015 年,当时业界虽然有 QuartZ 等出类拔萃的定时任务框架,但缺乏分布式方面的探索
分布式调度云平台产品的缺失,使得 ElasticJob 从出现便备受关注,它有效的弥补了作业在分布式领域的短板,并且提供了一站式的自动化运维管控端。
Quartz 很难满足我们这种大批量、任务执行周期长的任务调度!
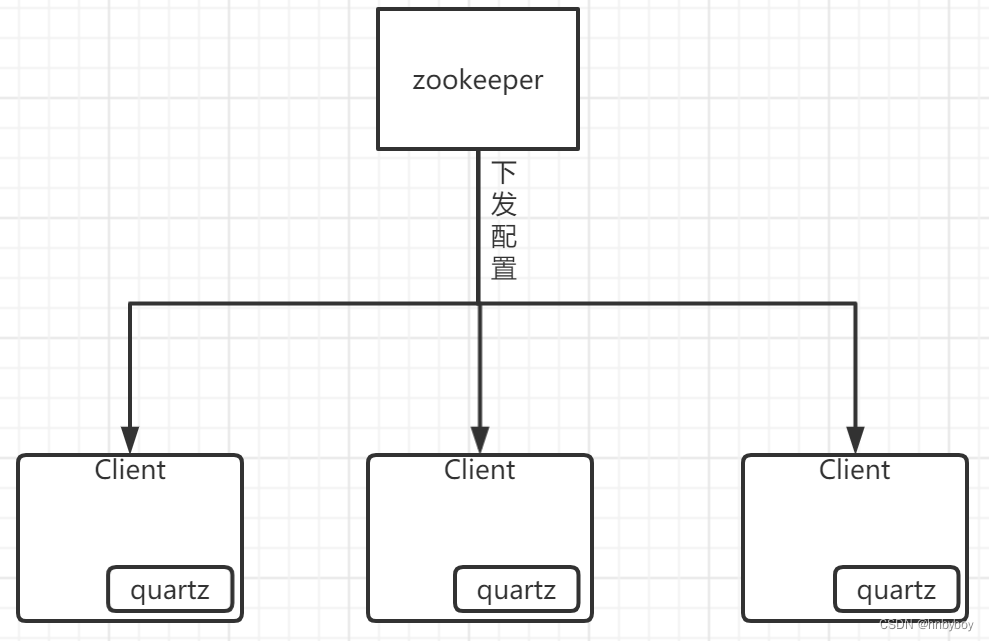
ElasticJob 在技术选型时,选择站在了巨人的肩膀上而不是重复制造轮子的理念,将定时任务事实标准的 QuartZ 与 分布式协调的利器 ZooKeeper 完美结合,快速而稳定的搭建了全新概念的分布式调度框架。
基本介绍
Elastic-Job提供了一种轻量级,无中心化解决方案。
官网:https://shardingsphere.apache.org/elasticjob/current/cn/overview/
没有统一的调度中心,集群的每个节点都是对等的, 节点之间通过注册中心进行分布式协调。E-Job 存在主节点的概念,但是主节点没有调度 的功能,而是用于处理一些集中式任务,如分片,清理运行时信息等。
Elastic-Job 最开始只有一个 elastic-job-core 的项目,在 2.X 版本以后主要分为 Elastic-Job-Lite 和 Elastic-Job-Cloud 两个子项目
Elastic-Job-Lite 定位为轻量级无中心化解决方案,使用 jar 包的形式提供分布式任务的协调服务。而 Elastic-Job-Cloud 使用 Mesos + Docker 的解决方案,额外提供资源治理、应用分发以及进程隔离等服务,跟 Lite 的区别只是部署方式不同,他们使用相同的 API,只要开发一次
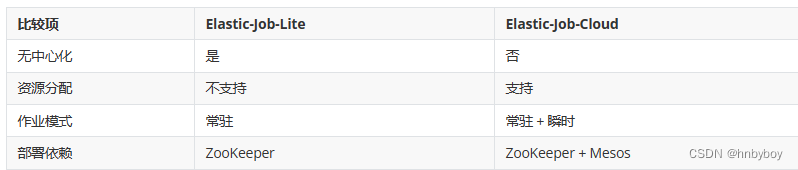
整体架构图
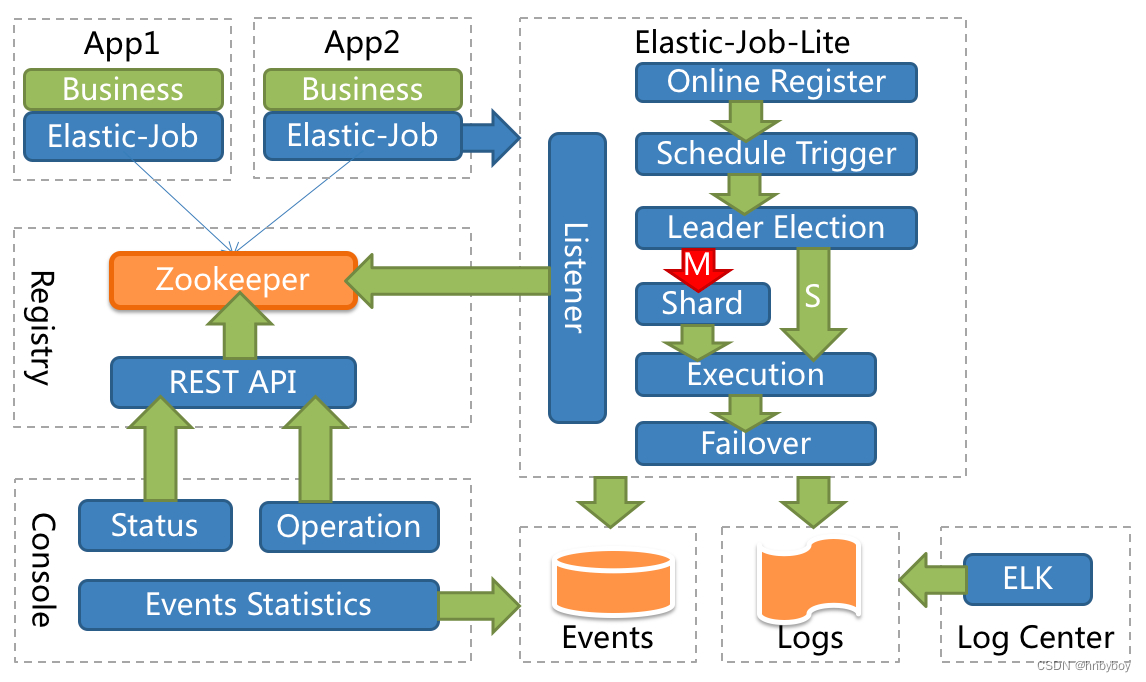
App
应用程序,内部包含任务执行业务逻辑和Elastic-Job-Lite组件,其中执行任务需要实现ElasticJob接口完成,与Elastic-Job-Lite组件的集成,并进行任务的相关配置。应用程序可启动多个实例,也就出现了多个任务执行实例
Elastic-Job-Lite
Elastic-Job-Lite定位为轻量级无中心化解决方案,使用jar包的形式提供分布式任务的协调服务,此组件负责任务的调度,并产生日志及任务调度记录。
无中心化,是指没有调度中心这一概念,每个运行在集群中的作业服务器都是对等的,各个作业节点是自治的、平等的、节点之间通过注册中心进行分布式协调
Registry
以Zookeeper作为Elastic-Job的注册中心组件,存储了执行任务的相关信息,同时Elastic-Job利用该组件进行执行任务实例的选举
Console
Elastic-Job提供了运维平台,它通过读取Zookeeper数据展现任务执行状态,或更新Zookeeper数据修改全局配置,通过Elastic-Job-Lite组件产生的数据来查看任务执行历史记录。
elastic-job、zk 和 quartz 关系如下
弹性调度
弹性调度是 ElasticJob 最重要的功能,能够让任务通过分片进行水平扩展的任务处理。
任务分片
任务的分片执行是指一个批量任务如果由一台服务执行速度会比较慢,那么对任务进行分片交给多台服务器进行执行,这样执行的效率就会得到提高。
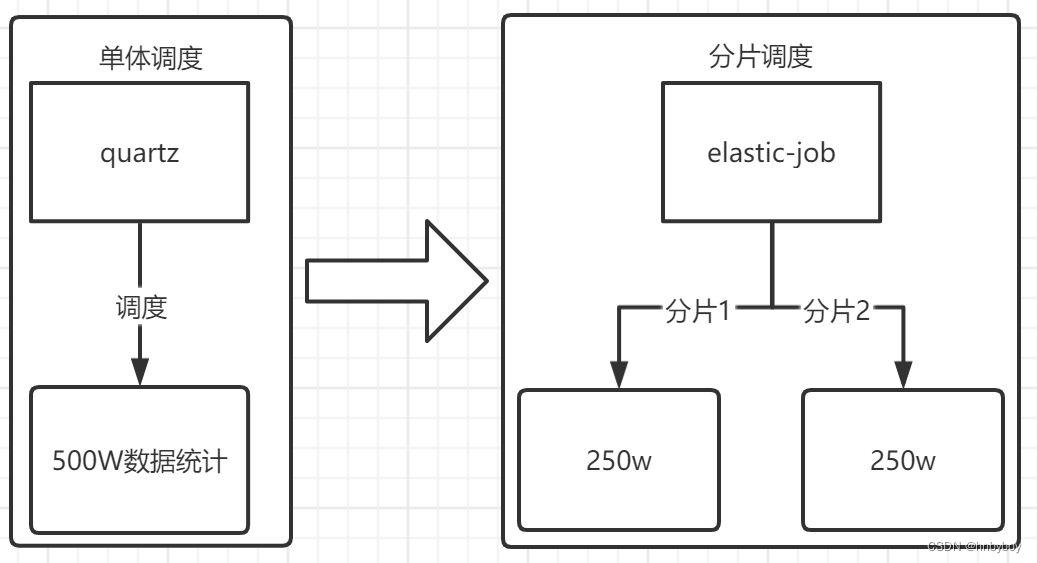
ElasticJob 中任务分片项的概念,使得任务可以在分布式的环境下运行,每台任务服务器只运行分配给该服务器的分片,随着服务器的增加或宕机,ElasticJob 会近乎实时的感知服务器数量的变更,从而重新为分布式的任务服务器分配更加合理的任务分片项,使得任务可以随着资源的增加而提升效率。
任务的分布式执行,需要将一个任务拆分为多个独立的任务项,然后由分布式的服务器分别执行某一个或几个分片项。
举例说明,如果作业分为 4 片,用两台服务器执行,则每个服务器分到 2 片,分别负责作业的 50% 的负载,如下图所示。
个性化分片参数
ElasticJob 可以设置分片项和自定义分片参数,个性化参数可以和分片项匹配对应关系,用于将分片项的数字转换为更加可读的业务代码
例如按照地区进行统计数据,北京=1,上海=2,广州=3,如果仅仅按照1、2、3进行分片,对开发者来说很不友好,需要了解具体数字所代表的含义,而使用个性化参数可以让代码的可读性更高,如果使用以下配置
shardingItemParameters: 0=Beijing,1=Shanghai,2=Guangzhou
那么在代码中可以更清晰的理解具体分片键的含义,或者使用枚举类型来让业务代码的可读性更高
分片策略
框架默认提供了三种分片策略,所有的分片策略都是接口JobShardingStrategy的实现

AverageAllocationJobShardingStrategy
策略说明
基于平均分配算法的分片策略,也是默认的分片策略,如果分片不能整除,则不能整除的多余分片将依次追加到序号小的服务器
如果有3台服务器,分成9片,则每台服务器分到的分片是:1=[0,1,2], 2=[3,4,5], 3=[6,7,8]
如果有3台服务器,分成8片,则每台服务器分到的分片是:1=[0,1,6], 2=[2,3,7], 3=[4,5]
如果有3台服务器,分成10片,则每台服务器分到的分片是:1=[0,1,2,9], 2=[3,4,5], 3=[6,7,8]
OdevitySortByNameJobShardingStrategy
策略说明
根据作业名的哈希值奇偶数决定IP升降序算法的分片策略,用于不同的作业平均分配负载至不同的服务器。
作业名的哈希值为奇数则IP升序。
作业名的哈希值为偶数则IP降序。
特点
AverageAllocationJobShardingStrategy的缺点是,一旦分片数小于作业服务器数,作业将永远分配至IP地址靠前的服务器,导致IP地址靠后的服务器空闲。而OdevitySortByNameJobShardingStrategy则可以根据作业名称重新分配服务器负载。
如果有3台服务器,分成2片,作业名称的哈希值为奇数,则每台服务器分到的分片是:1=[0], 2=[1], 3=[]
如果有3台服务器,分成2片,作业名称的哈希值为偶数,则每台服务器分到的分片是:3=[0], 2=[1], 1=[]
RotateServerByNameJobShardingStrategy
策略说明
根据作业名的哈希值对服务器列表进行轮转的分片策略
动态调度
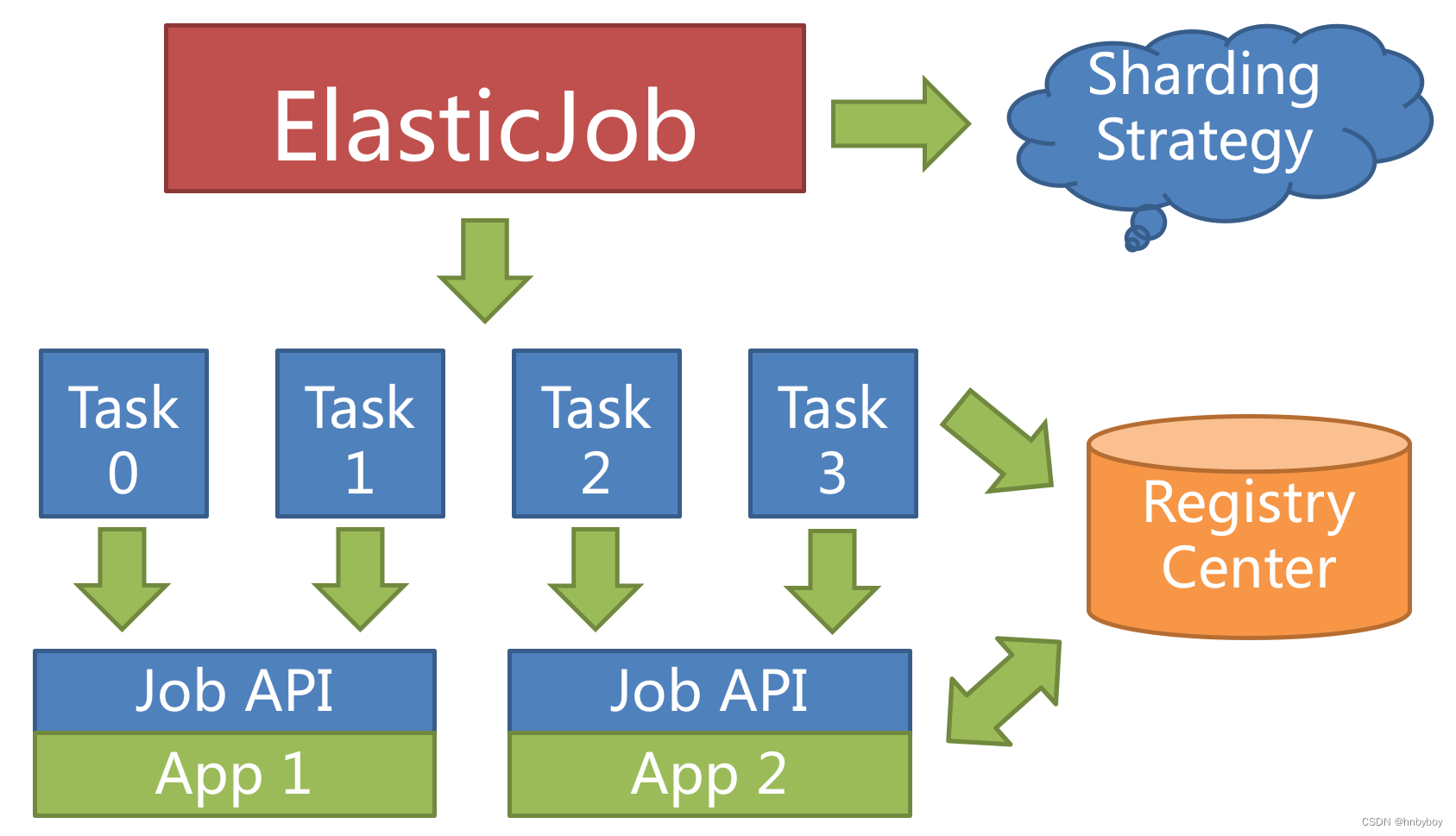
ElasticJob 可以根据节点的数量动态进行任务的分派,可以提高业务的执行效率以及提高吞吐量
当新增加作业服务器时,ElasticJob 会通过注册中心的临时节点的变化感知到新服务器的存在,并在下次任务调度的时候重新分片,新的服务器会承载一部分作业分片,如下图所示。
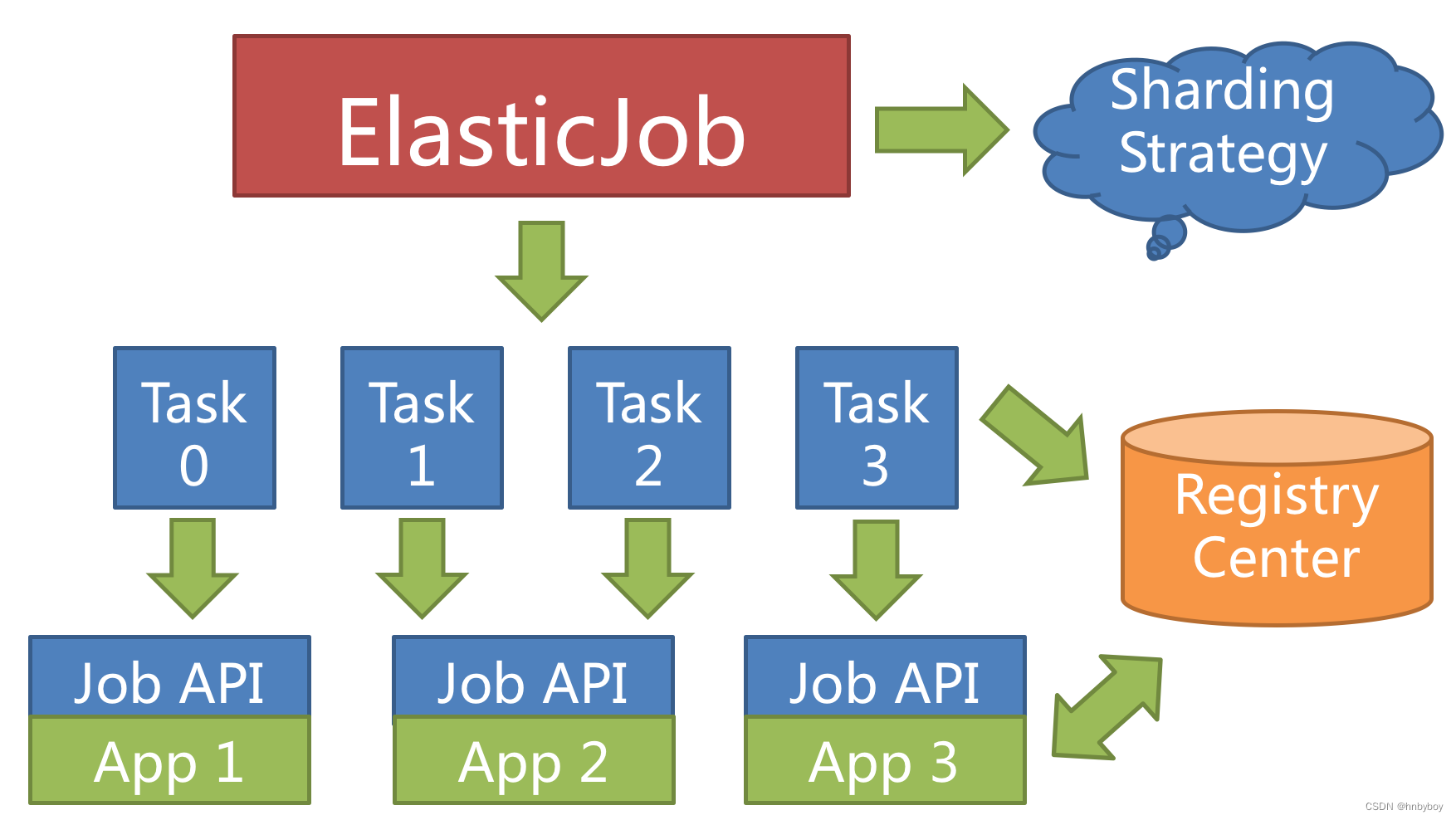
如果将分片项设置为大于服务器的数量,最好是大于服务器倍数的数量,作业将会合理的利用分布式资源,动态的分配分片项。
例如三台服务器,分成 10 片,则分片项分配结果为服务器 A = 0,1,2;服务器 B = 3,4,5;服务器 C = 6,7,8,9
如果服务器 C 崩溃,则分片项分配结果为服务器 A = 0,1,2,3,4; 服务器 B = 5,6,7,8,9。 在不丢失分片项的情况下,最大限度的利用现有资源提高吞吐量。
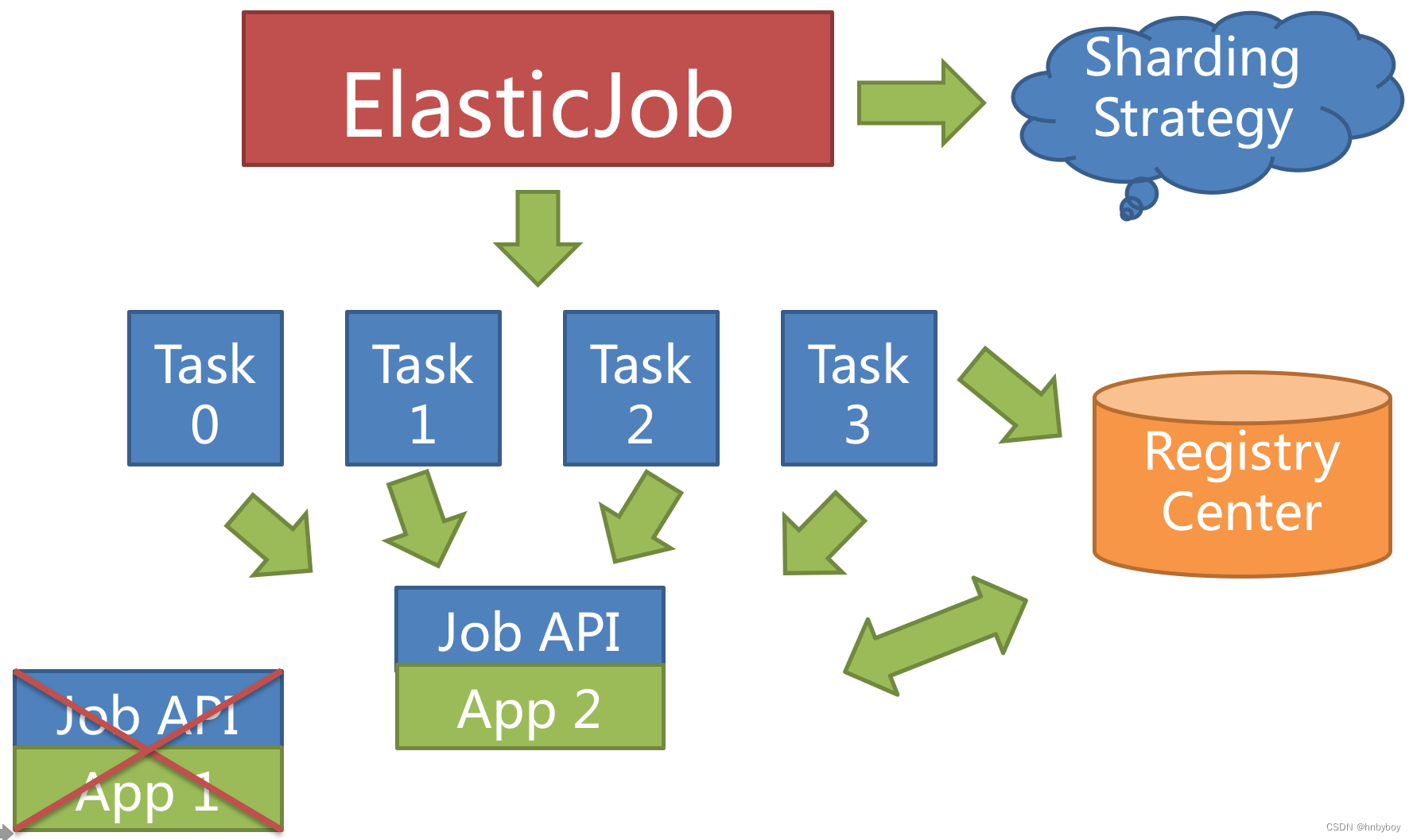
高可用
当定时任务服务器宕机时,注册中心同样会通过临时节点感知,并将在下次运行时将分片转移至仍存活的服务器,以达到作业高可用的效果
本次由于服务器宕机而未执行完的作业,则可以通过失效转移的方式继续执行。如下图所示。
作业类型
elastic-job提供了三种类型的作业类型,分别是Simple,Dataflow,ScriptJob
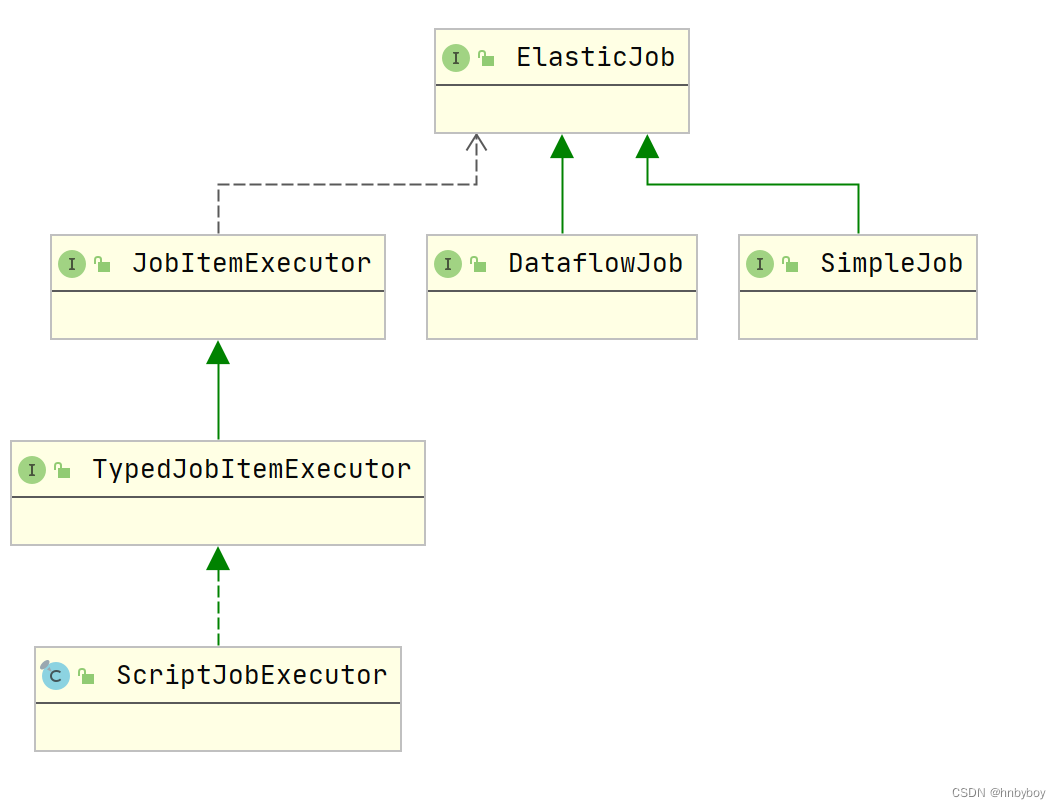
Simple
SimpleJob需要实现SimpleJob接口,意为简单实现,未经过任何封装,与quartz原生接口相似,比如示例代码中所使用的job
Dataflow
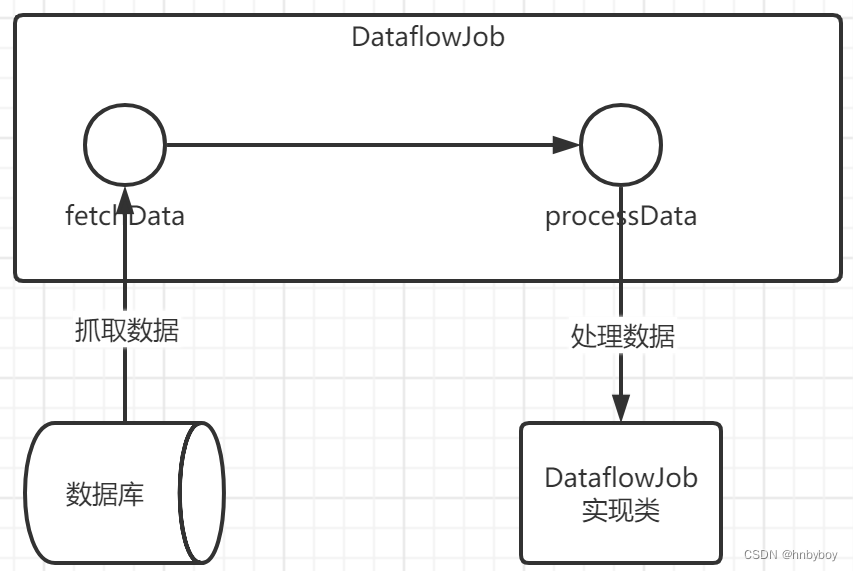
Dataflow类型用于处理数据流,需实现DataflowJob接口,适用于不间歇的数据处理。
该接口提供2个方法可供覆盖,分别用于抓取(fetchData)和处理(processData)数据
注意事项:
1.可通过DataflowJobConfiguration配置是否流式处理。
2.流式处理数据只有fetchData方法的返回值为null或集合长度为空时,作业才停止抓取,否则作业将一直运行下去; 非流式处理数据则只会在每次作业执行过程中执行一次fetchData方法和processData方法,随即完成本次作业。
3.如果采用流式作业处理方式,建议processData处理数据后更新其状态,避免fetchData再次抓取到,从而使得作业永不停止。
案例:这里模拟定时处理订单状态,拉取订单然后进行处理订单。
public class MyDataFlowJob implements DataflowJob<Order> {
Logger log = LoggerFactory.getLogger(MyDataFlowJob.class);
//模拟100个未处理订单
private static List<Order> orders = new ArrayList<>();
{
for (int i = 0; i < 100; i++) {
Order order = new Order();
order.setOrderId(i);
order.setStatus(0);
orders.add(order);
}
}
@Override
public List<Order> fetchData(ShardingContext shardingContext) {
//订单号%分片总数==当前分片项
List<Order> orderList = orders.stream().filter(o -> o.getStatus() == 0)
.filter(o -> o.getOrderId() % shardingContext.getShardingTotalCount() == shardingContext.getShardingItem())
.collect(Collectors.toList());
List<Order> subList = null;
if (orderList != null && orderList.size() > 0) {
int endIndex = 10;
if (orderList.size() < 10) {
endIndex = orderList.size() - 1;
}
subList = orderList.subList(0, endIndex);
}
//由于抓取数据过快,为更好看出效果,此处休眠一会儿
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("分片项:{},我抓取的数据:{}", shardingContext.getShardingItem(), subList);
return subList;
}
@Override
public void processData(ShardingContext shardingContext, List<Order> list) {
list.forEach(o -> o.setStatus(1));
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("分片项:{},处理中.....", shardingContext.getShardingItem());
}
}
事件跟踪
在elastic-job中,有一块很重要的功能,与作业的执行密切相关但是又不能影响作业的执行,这就是事件跟踪,定时任务执行一个事件,需要记录定时任务执行时间,状态等等信息,这些都可以通过事件跟踪来完成
控制台
Elastic-job控制台能够对elasticjob的作业做运维工作,比如暂停定时任务,修改定时任务执行时间,分片策略等等
elastic-job控制台和Elastic Job并无直接关系,是通过读取Elastic Job的注册中心数据展现作业状态,或更新注册中心数据修改全局配置。
控制台只能控制作业本身是否运行,但不能控制作业进程的启停,因为控制台和作业本身服务器是完全分布式的,控制台并不能控制作业服务器。
支持功能:
查看作业以及服务器状态
快捷的修改以及删除作业设置
启用和禁用作业
跨注册中心查看作业
查看作业运行轨迹和运行状态
安装部署
下载ElasticJob-UI
访问https://shardingsphere.apache.org/elasticjob/current/cn/downloads/地址,找到ElasticJob-UI 的tar包下载即可,注意下载ElasticJob-Lite-UI的tar包
启动服务
解压后,找到bin目录下的启动类,启动即可
访问测试
ElasticJob-UI 默认启动端口是8088,可以在application.properties配置文件进行修改,启动后出现如下访问界面,用户名密码都是root
配置注册中心
ElasticJob-UI因为设计的时候就是和Elastic Job服务相分离的,通过zk来查看和控制作业的状态,所以使用elastic-job第一步就是配置注册中心,如下图添加注册中心
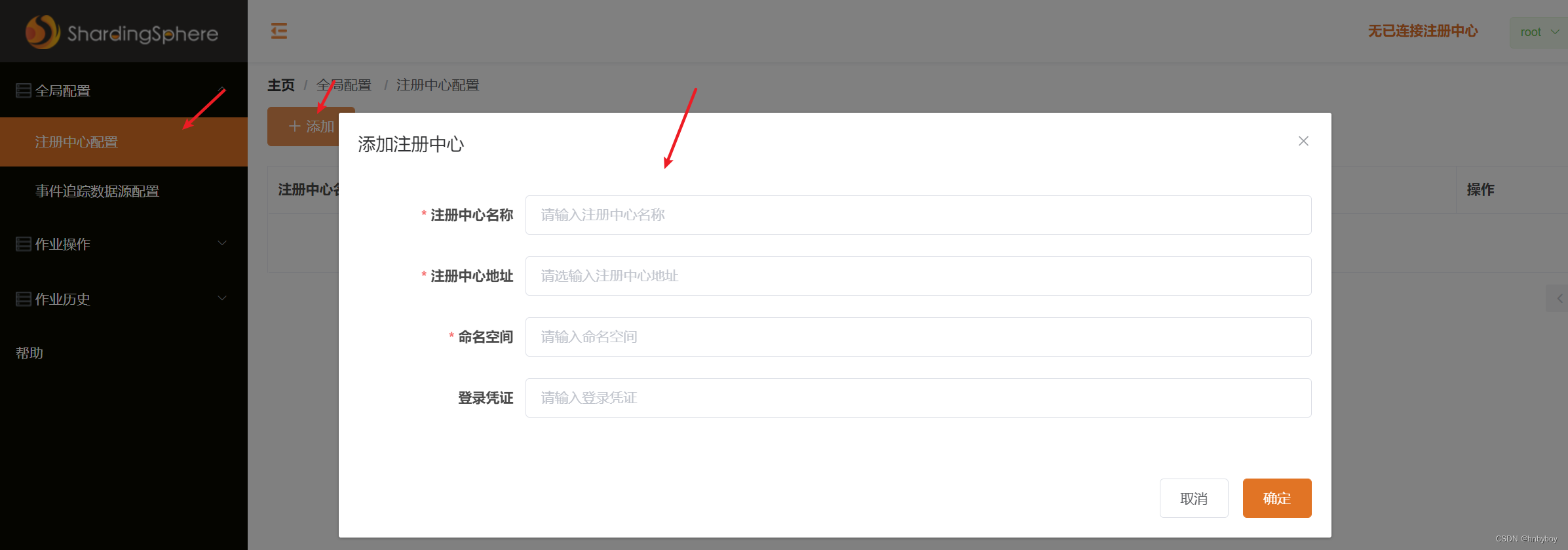
配置项说明
注册中心名称:可以随意命名,注册中心的名称
注册中心地址:也就是zookeeper地址,我们的地址时localhost:2181
命名空间地址:这个一般是我们在elastic-job配置的命名空间的地址我们配置的是elasticjob-lite-springboot
登录凭证:zk的登录凭证,默认没有配置可以忽略
作业操作
可以在作业操作栏目对作业进行操作,比如暂停以及触发任务,和修改任务的执行计划等等
xxl-job
https://gitee.com/xuxueli0323/xxl-job
https://gitee.com/xuxueli0323/xxl-tool
https://gitee.com/xuxueli0323/xxl-sso
XXL-JOB是一个轻量级分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展,其中“XXL”是主要作者,大众点评许雪里名字的缩写
默认支持6000个定时任务,如果生产环境的任务数量在这个范围内,可以选择使用 XXL-JOB。
,XXL-JOB的集群并不是分片集群,不管部署多少台,同一时间执行调度任务的只会有一台。
和ElasticJob的区别:
相同点:E-Job和xxl-job都有普遍的用户基础和完整的技术文档,都能满足定时任务的基本功能需求
不同点:
xxl-Job 侧重的业务实现的简单和管理的方便,学习成本简单,失败策略和路由策略丰富,推荐使用在“用户基数相对少,服务器数量在一定范围内”的情景下使用
E-Job 关注的是数据,增长了弹性扩容和数据分片的思路,以便于更大限度的利用分布式服务器的资源,可是学习成本相对高些,推荐在“数据量庞大,且部署服务器数量较多”时使用算法
xxl-Job采用了中心化思想的架构,而E-Job采用了无中心的架构
功能:
简单灵活:丰富的任务管理功能,高性能,高可用,易于监控运维
整体架构设计
将调度行为抽象形成“调度中心”公共平台,而平台自身并不承担业务逻辑,“调度中心”负责发起调度请求;
将任务抽象成分散的JobHandler,交由“执行器”统一管理,“执行器”负责接收调度请求并执行对应的JobHandler中业务逻辑,因此,“调度”和“任务”两部分可以相互解耦,提高系统整体稳定性和扩展性;
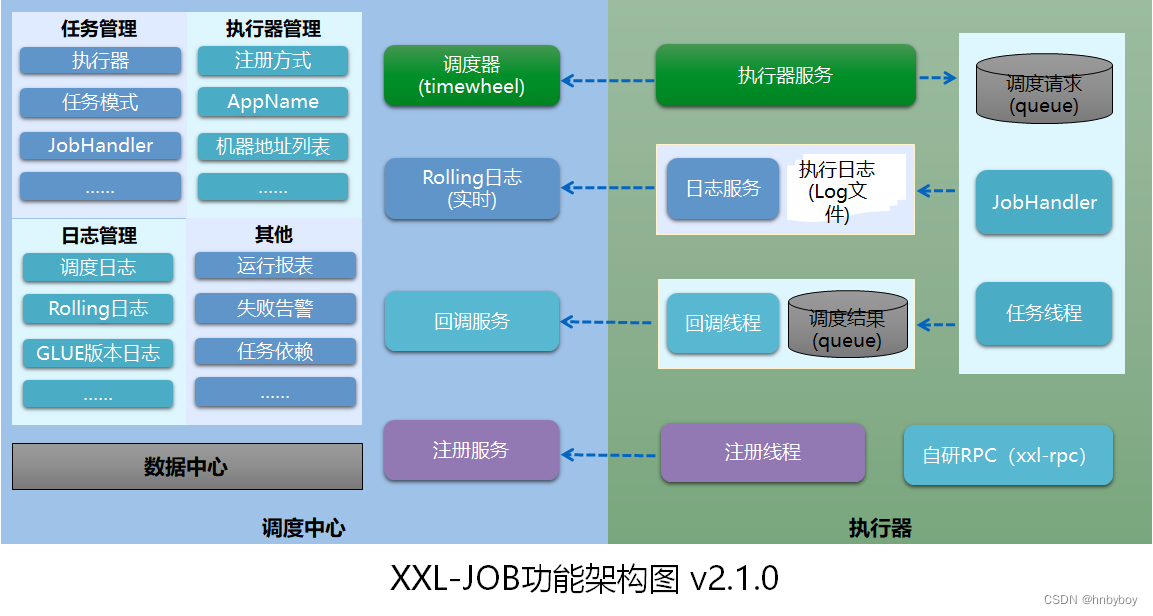
调度模块(调度中心)
负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码
调度系统与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块; 支持可视化、简单且动态的管理调度信息,包括任务新建,更新,删除,任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器Failover
功能:
任务管理:对调度的任务进行触发时间等配置
日志管理:查看调度的日志情况
执行器管理:管理接入的业务模块
其它,比如用户权限配置和运行统计报表等功能
执行模块(执行器)
负责接收调度请求并执行任务逻辑。
任务模块专注于任务的执行等操作,开发和维护更加简单和高效; 接收“调度中心”的执行请求、终止请求和日志请求等
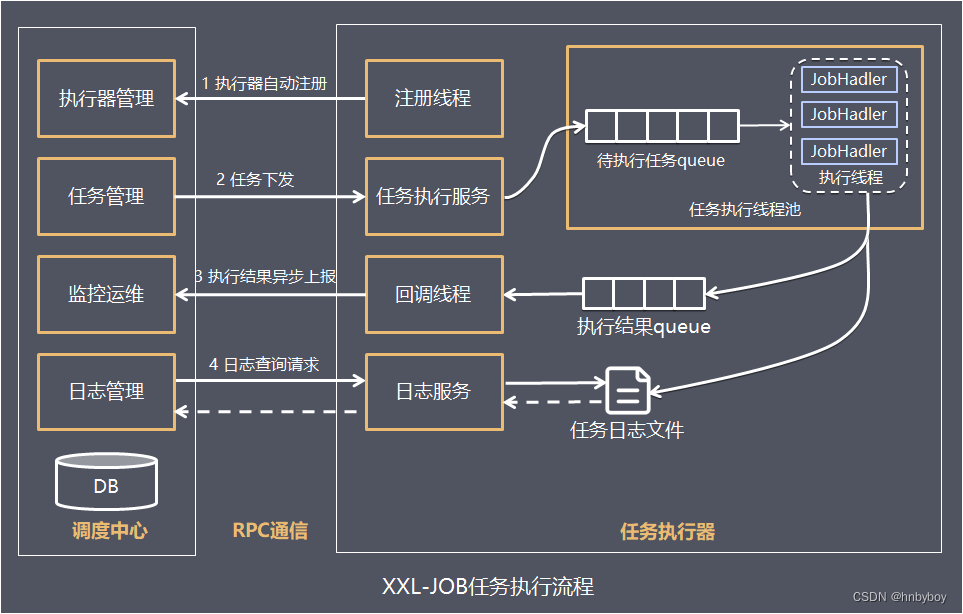
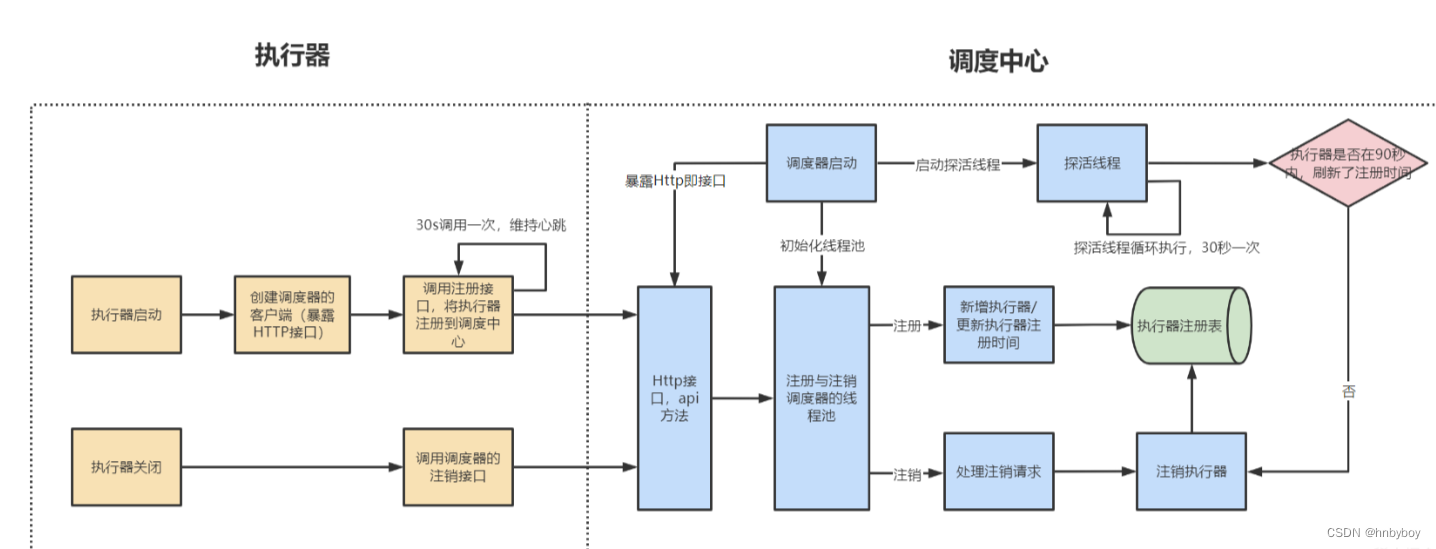
工作原理
任务执行器根据配置的调度中心的地址,自动注册到调度中心
达到任务触发条件,调度中心下发任务
执行器基于线程池执行任务,并把执行结果放入内存队列中、把执行日志写入日志文件中
执行器的回调线程消费内存队列中的执行结果,主动上报给调度中心
当用户在调度中心查看任务日志,调度中心请求任务执行器,任务执行器读取任务日志文件并返回日志详情
部署调度中心
初始化数据库
https://gitee.com/xuxueli0323/xxl-job 地址下载项目源码并解压, SQL脚本位置在
/xxl-job/doc/db/tables_xxl_job.sql

xxl_job的数据库里有如下几个表:
xxl_job_group:执行器信息表,用于维护任务执行器的信息
xxl_job_info:调度扩展信息表,主要是用于保存xxl-job的调度任务的扩展信息,比如说像任务分组、任务名、机器的地址等等
xxl_job_lock:任务调度锁表
xxl_job_log:日志表,主要是用在保存xxl-job任务调度历史信息,像调度结果、执行结果、调度入参等等
xxl_job_log_report:日志报表,会存储xxl-job任务调度的日志报表,会在调度中心里的报表功能里使用到
xxl_job_logglue:任务的GLUE日志,用于保存GLUE日志的更新历史变化,支持GLUE版本的回溯功能
xxl_job_registry:执行器的注册表,用在维护在线的执行器与调度中心的地址信息
xxl_job_user:系统的用户表
创建用户并授权:
mysql> source /opt/tables_xxl_job.sql;
mysql> CREATE USER 'xxl'@'%' IDENTIFIED BY 'xxl';
mysql> GRANT ALL ON xxl_job.* TO 'xxl'@'%' IDENTIFIED BY 'xxl' WITH GRANT OPTION;
源码结构
解压源码,按照maven格式将源码导入IDE, 使用maven进行编译即可
xxl-job-admin:调度中心
xxl-job-core:公共依赖
xxl-job-executor-samples:执行器Sample示例(选择合适的版本执行器,可直接使用,也可以参考其并将现有项目改造成执行器)
:xxl-job-executor-sample-springboot:Springboot版本,通过Springboot管理执行器,推荐这种方式;
:xxl-job-executor-sample-frameless:无框架版本;
配置调度中心:
调度中心项目是xxl-job-admin,作用是统计管理调度平台上面的任务,负责触发以及执行调度任务,并且提供任务管理
修改application.properties
调度中心配置内容说明,可以按需进行修改
server.port=8080
#项目访问路径
server.servlet.context-path=/xxl-job-admin
spring.datasource.url=jdbc:mysql://192.168.10.30:3306/xxl_job?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
spring.datasource.username=xxl
spring.datasource.password=xxl
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
### 报警邮箱
spring.mail.host=smtp.qq.com
spring.mail.port=25
spring.mail.username=xxx@qq.com
spring.mail.password=xxx
spring.mail.properties.mail.smtp.auth=true
spring.mail.properties.mail.smtp.starttls.enable=true
spring.mail.properties.mail.smtp.starttls.required=true
spring.mail.properties.mail.smtp.socketFactory.class=javax.net.ssl.SSLSocketFactory
### 调度中心通讯TOKEN [选填]:非空时启用;
xxl.job.accessToken=
### 调度中心国际化配置 [必填]: 默认为 "zh_CN"/中文简体, 可选范围为 "zh_CN"/中文简体, "zh_TC"/中文繁体 and "en"/英文;
xxl.job.i18n=zh_CN
## 调度线程池最大线程配置【必填】
xxl.job.triggerpool.fast.max=200
xxl.job.triggerpool.slow.max=100
### 调度中心日志表数据保存天数 [必填]:过期日志自动清理;限制大于等于7时生效,否则, 如-1,关闭自动清理功能;
xxl.job.logretentiondays=30
部署项目
可以在本地直接运行xxl-job服务,或者打包后在服务器上面运行
启动服务
运行项目后访问 http://192.168.10.30:8080/xxl-job-admin ,该地址执行器将会使用到,作为回调地,默认登录账号 admin/123456, 登录后运行界面
Docker部署:
创建docker-comopose.yml
version: '3'
services:
xxl-job-admin:
image: xuxueli/xxl-job-admin:2.3.0
restart: always
container_name: xxl-job-admin
environment:
PARAMS: '--spring.datasource.url=jdbc:mysql://192.168.10.30:3306/xxl_job?Unicode=true&characterEncoding=UTF-8 --spring.datasource.username=root --spring.datasource.password=root'
ports:
- 8080:8080
volumes:
- ./data/applogs:/data/applogs
启动服务
docker-compose up -d
集群部署:
XXL-JOB的集群部署非常简单,只需要注意两点:
集群节点都连接的是同一个数据库。
多台机器部署时,需要统一系统时间,如果是单个机器部署,则不用管这条。
现在是在同一台机器中,并且在上面打的包中,指定了数据库的url地址,所以只需要正常启动,就满足上述的条件了。
找到刚刚打的包,xxl-job-admin,这是一个springboot的功能,所以通过java -jar直接启动就好了,这里先启动两台。
java -jar xxl-job-admin-2.3.1.jar --server.port=8080
java -jar xxl-job-admin-2.3.1.jar --server.port=8081
操作到这里,一个基本的调度中心集群就搭建好了。
需要注意的是,XXL-JOB的集群并不是分片集群,不管部署多少台,同一时间执行调度任务的只会有一台。
集群部署纯粹只是为了处理单点故障问题。
为什么会这么设计呢?
如果是分片集群,在同一时间,不同的调度中心在执行同一个调度任务,会导致的重复调度问题,一般解决这种问题,可以通过分布式锁来处理,同一时间只让一个线程去处理任务。
在加上XXL-JOB的架构理念中,将调度器与执行器分离了,使用异步调用的方式来处理,从而大大降低了调度器的性能压力。
于是,就直接使用数据库的独占锁做分布式锁处理了,处理方式简单。
反向代理
上面我们已经获得了一个集群,但是对于生产环境来说,简单粗暴的通过调度中心所在服务器的ip访问并不是一个友好的方式,可想象的是,一旦ip发生了变化,我们所有的调度器所在服务的配置文件都需要修改。
更好的方式是通过反向代理的方式来暴露调度中心,以Windows环境为例,用以下步骤来做配置:
第一步:修改hosts文件
如果是生产环境,忽略这一步,直接使用生产环境的域名即可。本地配置hosts文件,主要是想把127.0.0.1映射到某个域名上。
127.0.0.1 wsl.xxljob.cn
wsl.xxljob.cn 可以配置成任意自己喜欢的域名。
第二步:配置Nginx
一般来说,我们不会直接在nginx的配置文件中做配置,而是单独创建一个由某个服务独有的配置文件,方便管理。
这里我们在conf目录中创建xxl-job.conf并做以下配置:
# 负载均衡
upstream local.xxljob.cn {
server 127.0.0.1:8080;
server 127.0.0.1:8081;
}
server {
listen 80; # nginx端口
server_name wsl.xxljob.cn; # hosts中配置的域名
error_page 404 /404.html;
error_page 500 502 503 504 /50x.html;
# 需要转发的uri路径
location ~* /xxl-job-admin {
proxy_pass http://local.xxljob.cn; # 映射上面的upstream
proxy_pass_header Date;
proxy_pass_header Server;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
# 日志配置
log_format xxl-job '$remote_addr - $upstream_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log logs/access.log xxl-job;
error_log logs/error.log;
配置好后,打开同级目录下nginx.conf文件,将上面的文件依赖到nginx配置中。
http {
resolver 8.8.8.8;
include mime.types;
default_type application/octet-stream;
include xxl-job.conf;
# ......此处省略其他配置
}
然后启动nginx,通过域名访问http://wsl.xxljob.cn/xxl-job-admin/,默认登录账号 “admin/123456”, 登录后运行界面如下图所示。
第三步:反向代理验证
在上面的nginx配置中,加入了一个日志格式化配置:- $upstream_addr,有这个配置后,我们就可以在access_log中查看负载均衡的请求详情了。
刷新几次页面,然后打开nginx目录下的log文件,看到8080和8081交替执行,表达负载均衡配置成功。
部署执行器
引入依赖
在项目pom文件中引入了 “xxl-job-core” 的maven依赖;
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
<version>2.3.0</version>
</dependency>
执行器配置文件
如调度中心集群部署存在多个地址则用逗号分隔
### 调度中心部署根地址 [选填]:如调度中心集群部署存在多个地址则用逗号分隔。执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调";为空则关闭自动注册;
xxl.job.admin.addresses=http://192.168.10.30:8080/xxl-job-admin
### 执行器通讯TOKEN [选填]:非空时启用;
xxl.job.accessToken=
### 执行器AppName [选填]:执行器心跳注册分组依据;为空则关闭自动注册
xxl.job.executor.appname=xxl-job-executor-task
### 执行器注册 [选填]:优先使用该配置作为注册地址,为空时使用内嵌服务 ”IP:PORT“ 作为注册地址。从而更灵活的支持容器类型执行器动态IP和动态映射端口问题。
xxl.job.executor.address=
### 执行器IP [选填]:默认为空表示自动获取IP,多网卡时可手动设置指定IP,该IP不会绑定Host仅作为通讯实用;地址信息用于 "执行器注册" 和 "调度中心请求并触发任务";
xxl.job.executor.ip=
### 执行器端口号 [选填]:小于等于0则自动获取;默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口;
xxl.job.executor.port=9999
### 执行器运行日志文件存储磁盘路径 [选填] :需要对该路径拥有读写权限;为空则使用默认路径;
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
### 执行器日志文件保存天数 [选填] : 过期日志自动清理, 限制值大于等于3时生效; 否则, 如-1, 关闭自动清理功能;
xxl.job.executor.logretentiondays=30
我们可以把这个配置文件直接复制到项目中,需要注意修改下面几个位置:
# 调度中心地址修改为集群的地址
xxl.job.admin.addresses=http://ls.xxljob.cn/xxl-job-admin
# 因为调度中心配置的是default_token,此处我们保持一致
xxl.job.accessToken=default_token
# 指定执行器名称,每个服务都应该有不同的执行器名称,同一个服务的不同集群节点的执行器名称应该相同
xxl.job.executor.appname=my-simple-executor
配置执行器
@Configuration
public class XxlJobConfig {
private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
}
/**
* 针对多网卡、容器内部署等情况,可借助 "spring-cloud-commons" 提供的 "InetUtils" 组件灵活定制注册IP;
*
* 1、引入依赖:
* <dependency>
* <groupId>org.springframework.cloud</groupId>
* <artifactId>spring-cloud-commons</artifactId>
* <version>${version}</version>
* </dependency>
*
* 2、配置文件,或者容器启动变量
* spring.cloud.inetutils.preferred-networks: 'xxx.xxx.xxx.'
*
* 3、获取IP
* String ip_ = inetUtils.findFirstNonLoopbackHostInfo().getIpAddress();
*/
任务实例:
import com.wsl.paybase.common.config.XxlJobConfig;
import com.xxl.job.core.handler.annotation.XxlJob;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
@Component
public class MyJob {
private final Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
@XxlJob("mySimpleJob")
public void mySimpleJob() {
logger.info("执行自定义任务");
}
}
启动执行器
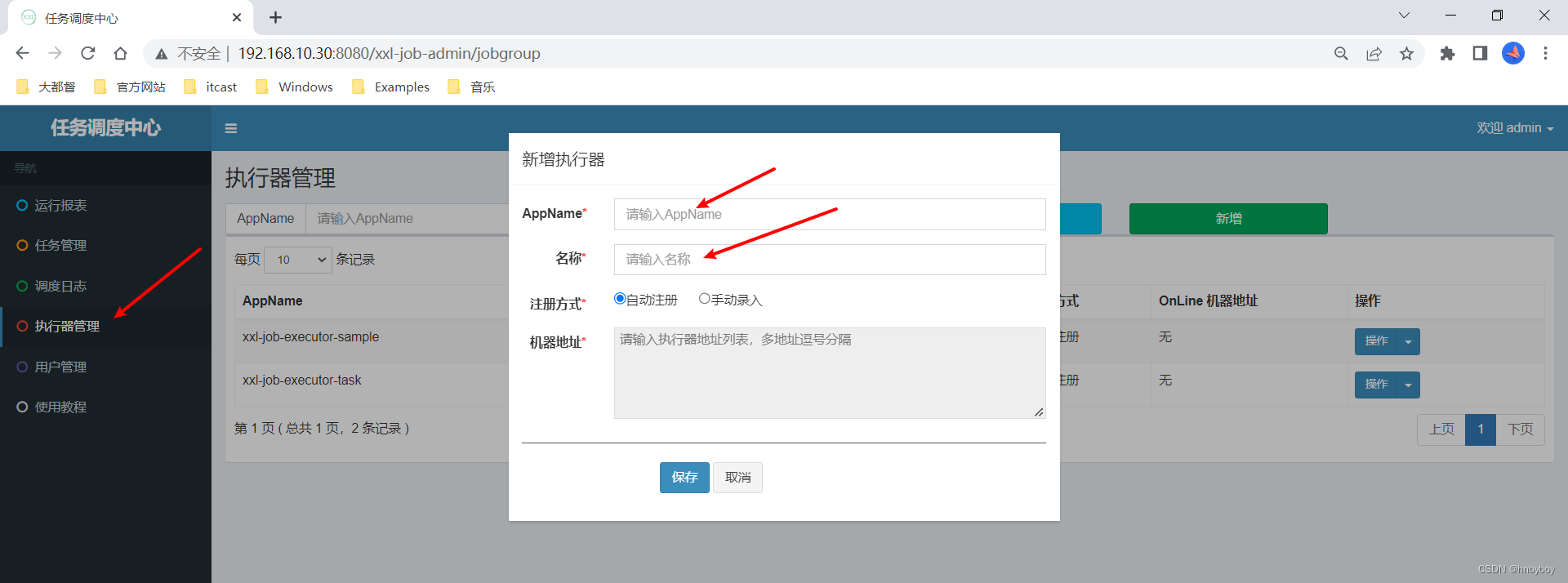
本地执行器服务启动后,需要在调度中心配置执行器
注意AppName就是执行器项目配置的配置项,名称可以随意,机器地址采用自动注册就可以
执行器的注册与注销的流程
作业详情:
xxl-job支持很多种任务模式,下面我们挑几个常用的介绍下
BEAN模式
Bean模式任务,支持基于方法的开发方式,每个任务对应一个方法。
原理:
每个Bean模式任务都是一个Spring的Bean类实例,它被维护在“执行器”项目的Spring容器中。
任务类需要加“@JobHandler(value=”名称”)”注解,因为“执行器”会根据该注解识别Spring容器中的任务。任务类需要继承统一接口“IJobHandler”,任务逻辑在execute方法中开发,因为“执行器”在接收到调度中心的调度请求时,将会调用“IJobHandler”的execute方法,执行任务逻辑。
编写执行器:
为Job方法添加注解 “@XxlJob(value=“自定义jobhandler名称”, init = “JobHandler初始化方法”, destroy = “JobHandler销毁方法”)”,注解value值对应的是调度中心新建任务的JobHandler属性的值。
@Component
public class XxlJobBeanMethodTask {
private static final Logger logger = LoggerFactory.getLogger(XxlJobBeanMethodTask.class);
@XxlJob("methodTask")
public void methodTask() throws Exception {
logger.info("methodTask定时任务启动,总分片:{},当前分片:{},参数:{}",XxlJobHelper.getShardIndex(),XxlJobHelper.getShardIndex(),XxlJobHelper.getJobParam());
XxlJobHelper.log("XXL-METHODTASK, methodTask定时任务启动");
//执行成功标志,默认就是执行成功
XxlJobHelper.handleSuccess();
}
}
新建调度任务
在任务管理,选择对应的执行器新建任务
新增完成后,可以在列表点击执行一次或者点击启动启动定时任务
GLUE模式(Java)
任务以源代码方式维护在调度中心,支持通过Web IDE在线更新,实时编译和生效,因此不需要指定JobHandler
原理
每个 “GLUE模式(Java)” 任务的代码,实际上是“一个继承自“IJobHandler”的实现类的类代码”,“执行器”接收到“调度中心”的调度请求时,会通过Groovy类加载器加载此代码,实例化成Java对象,同时注入此代码中声明的Spring服务(请确保Glue代码中的服务和类引用在“执行器”项目中存在),然后调用该对象的execute方法,执行任务逻辑。
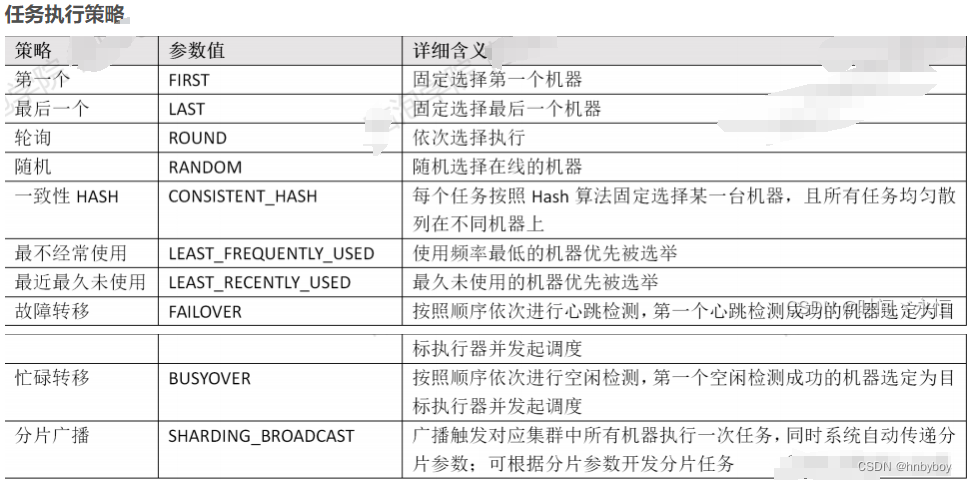
路由策略
路由策略属于XXLJob的高级功能,可以控制执行器执行的策略
最后一个
当选择该策略时,会选择执行器注册地址的最后一台机器执行,如果最后一台机器出现故障,则调度任务失败,测试方式如上
轮询
当选择该策略时,会按照执行器注册地址轮询分配任务,如果其中一台机器出现故障,调度任务失败,任务不会转移
随机
当选择该策略时,会按照执行器注册地址随机分配任务,如果其中一台机器出现故障,调度任务失败,任务不会转移
一致性HASH
当选择该策略时,每个任务按照Hash算法固定选择某一台机器,如果那台机器出现故障,调度任务失败,任务不会转移。
最不经常使用
当选择该策略时,会优先选择使用频率最低的那台机器,如果其中一台机器出现故障,调度任务失败,任务不会转移(实践表明效果和轮询策略一致)
最近最久未使用
当选择该策略时,会优先选择最久未使用的机器,如果其中一台机器出现故障,调度任务失败,任务不会转移(实践表明效果和轮询策略一致)
故障转移
当选择该策略时,按照顺序依次进行心跳检测,如果其中一台机器出现故障,则会转移到下一个执行器,若心跳检测成功,会选定为目标执行器并发起调度
忙碌转移
当选择该策略时,按照顺序依次进行空闲检测,如果其中一台机器出现故障,则会转移到下一个执行器,若空闲检测成功,会选定为目标执行器并发起调度
分片广播
当选择该策略时,广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数,可根据分片参数开发分片任务,如果其中一台机器出现故障,则该执行器执行失败,不会影响其他执行器
XXL的分片是根据启动的客户端进行分片,
分片参数是调度中心自动传递的,不用我们手动传递,且集群中的每个index序号是固定的,即使集群中有项目宕机,也不影响其他项目的index序号,当重启宕机项目时,它的序号还是原先的
服务启动后会自动的进行服务分片,分片会根据不同的节点进行调度
阻塞策略
调度过于密集执行器来不及处理时的处理策略
单机串行
调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行
丢弃后续调度
调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败
覆盖之前调度
调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务
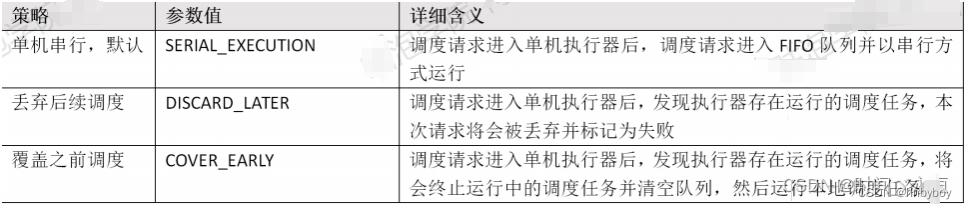
时间轮是一种用于实现定时器、延时调度等功能的算法,广泛的运用于各种中间件中,例如:Netty、Kafka、Dubbo等,在XXL-JOB中,实现方式非常简单,通过一个HashMap来实现的
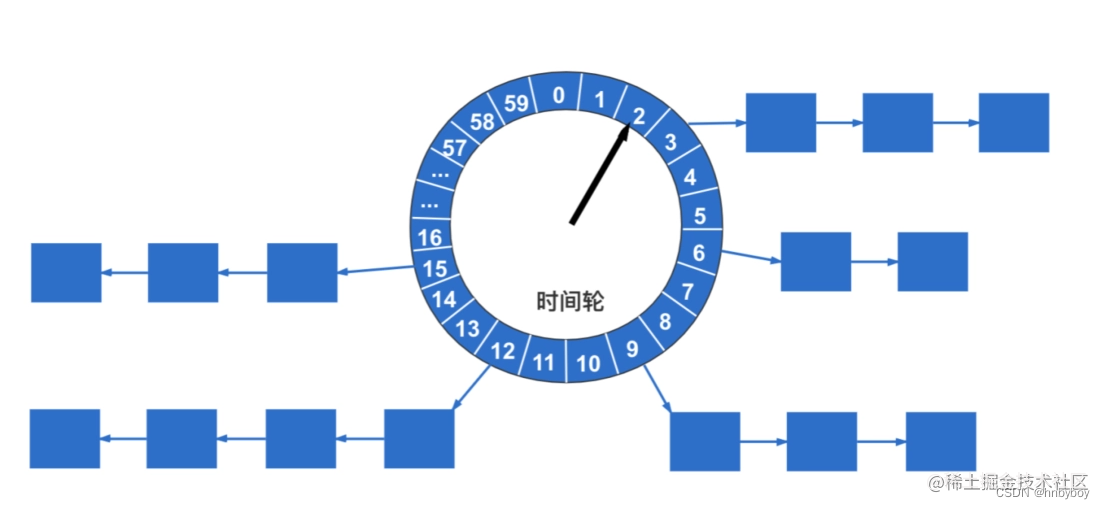
调度中心的调度流程:
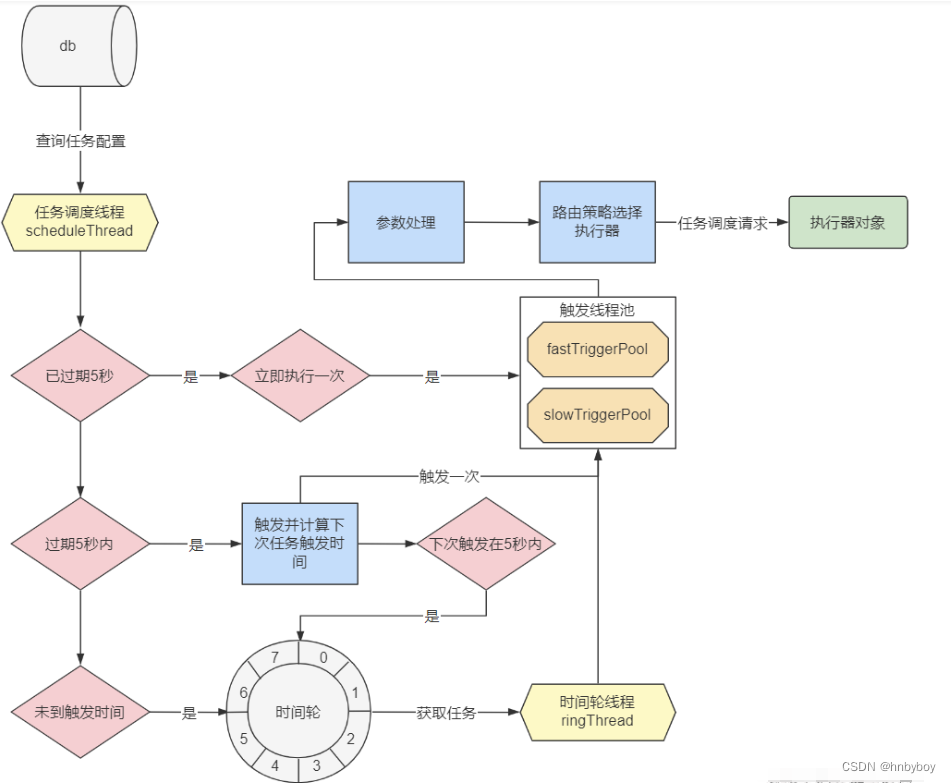
调度中心与执行器流程:
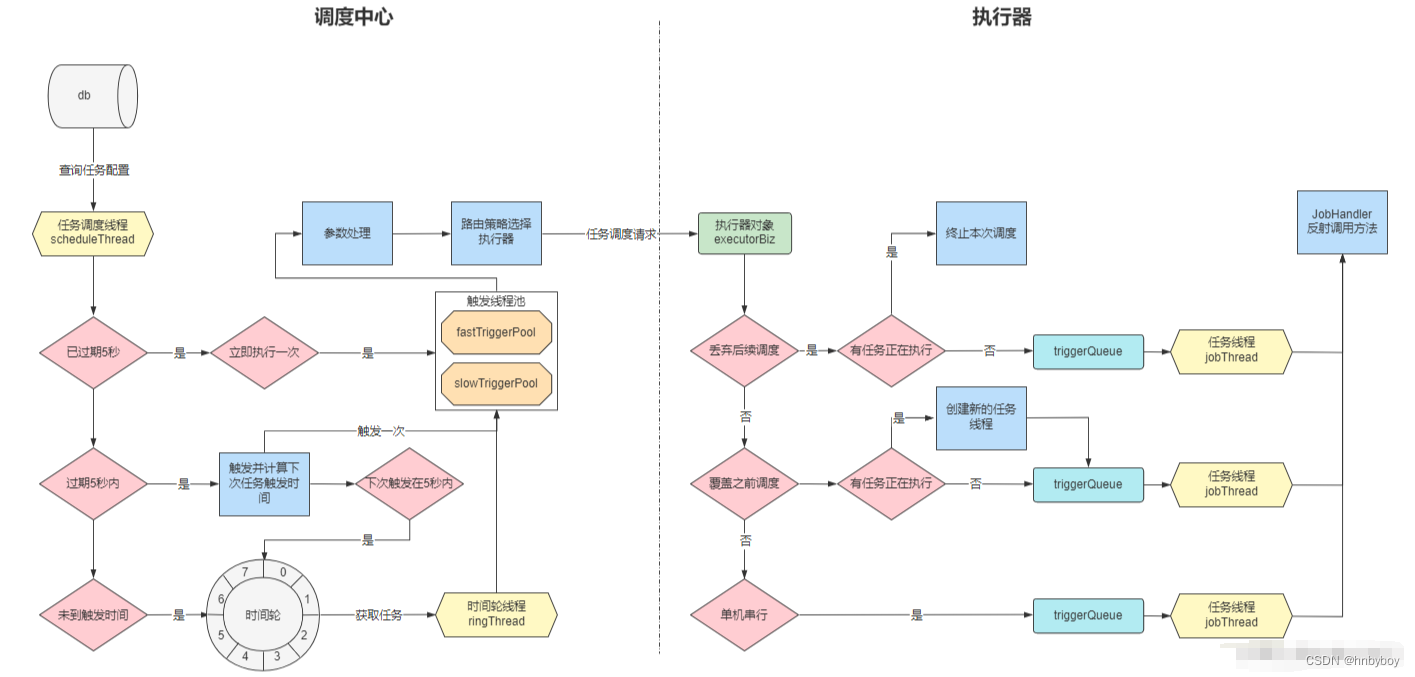
调度流程:
XXL-JOB调度流程的思想是比较容易理解的:
获取任务:调度线程不断的扫描任务表,查询出将要执行的任务。
前置处理:对每一个任务都做一次触发时间的计算,能够立即触发的就立即触发,不能立即触发的就放在时间轮中触发,不能触发的就抛弃掉。
路由策略:在执行器集群中选择一个节点执行定时任务。
触发任务:调度线程不断的从时间轮中获取任务并触发。
异步调度:调度中心将调度与触发做了异步处理,使用触发线程池来做Http调用。
阻塞策略:根据阻塞策略判断当前的调用请求是否执行。
任务执行:执行器为每个任务都分配了一个线程,自己处理自己的任务,任务之间不会互相影响。
任务回调:将执行结果回传到调度中心中,更新任务执行状态。
Job项目:有流程编排
PowerJob项目:
https://www.yuque.com/powerjob/guidence/quick_start
http://www.powerjob.tech/
Cron表达式生成器:
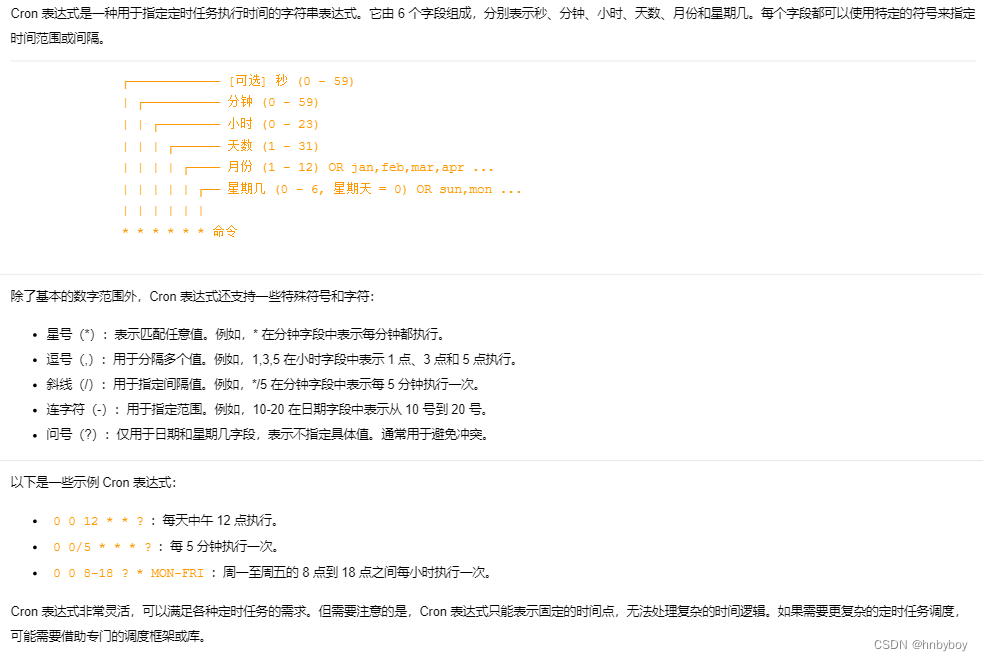
常用cron表达式例子
(1)0/2 * * * * ? 表示每2秒 执行任务
(1)0 0/2 * * * ? 表示每2分钟 执行任务
(1)0 0 2 1 * ? 表示在每月的1日的凌晨2点调整任务
(2)0 15 10 ? * MON-FRI 表示周一到周五每天上午10:15执行作业
(3)0 15 10 ? 6L 2002-2006 表示2002-2006年的每个月的最后一个星期五上午10:15执行作
(4)0 0 10,14,16 * * ? 每天上午10点,下午2点,4点
(5)0 0/30 9-17 * * ? 朝九晚五工作时间内每半小时
(6)0 0 12 ? * WED 表示每个星期三中午12点
(7)0 0 12 * * ? 每天中午12点触发
(8)0 15 10 ? * * 每天上午10:15触发
(9)0 15 10 * * ? 每天上午10:15触发
(10)0 15 10 * * ? 每天上午10:15触发
(11)0 15 10 * * ? 2005 2005年的每天上午10:15触发
(12)0 * 14 * * ? 在每天下午2点到下午2:59期间的每1分钟触发
(13)0 0/5 14 * * ? 在每天下午2点到下午2:55期间的每5分钟触发
(14)0 0/5 14,18 * * ? 在每天下午2点到2:55期间和下午6点到6:55期间的每5分钟触发
(15)0 0-5 14 * * ? 在每天下午2点到下午2:05期间的每1分钟触发
(16)0 10,44 14 ? 3 WED 每年三月的星期三的下午2:10和2:44触发
(17)0 15 10 ? * MON-FRI 周一至周五的上午10:15触发
(18)0 15 10 15 * ? 每月15日上午10:15触发
(19)0 15 10 L * ? 每月最后一日的上午10:15触发
(20)0 15 10 ? * 6L 每月的最后一个星期五上午10:15触发
(21)0 15 10 ? * 6L 2002-2005 2002年至2005年的每月的最后一个星期五上午10:15触发
(22)0 15 10 ? * 6#3 每月的第三个星期五上午10:15触发
参考来源:
https://github.com/ltsopensource/light-task-scheduler
https://gitee.com/xuxueli0323/xxl-job
https://shardingsphere.apache.org/elasticjob/current/cn/overview/
https://www.jb51.net/program/2903277t8.htm#_label8
https://blog.csdn.net/qq_38249409/article/details/127494577
https://blog.csdn.net/qq_38249409/article/details/127494577
https://blog.csdn.net/qq_38249409/category_12171289.html
https://cron.ciding.cc/
https://cron.qqe2.com/
http://www.powerjob.tech/



![[vue error] vue3中使用同名简写报错 ‘v-bind‘ directives require an attribute value](https://img-blog.csdnimg.cn/direct/0a18bb69d56c4e75b2bbd6cb39009586.png)