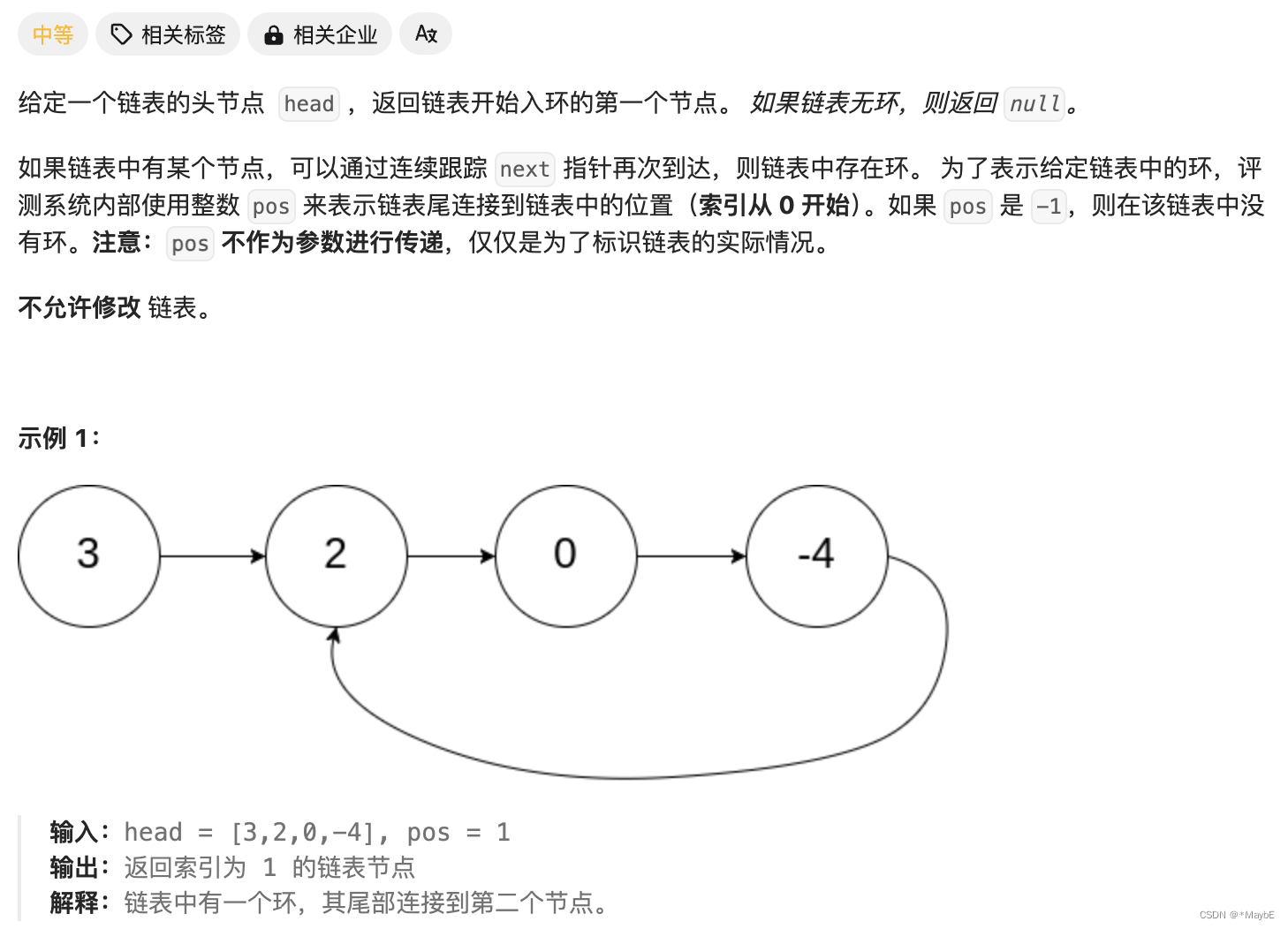
目录
- 💡引言
- ✈️✈️一,开源大模型的优势与劣势
- ✈️✈️1.1 优势:
- ✈️✈️1.2 挑战和劣势:
- 🚀🚀2. 闭源大模型的优势与劣势
- 🚀🚀2.1 优势:
- 🚀🚀2.2 局限和挑战:
- ✏️✏️3. 结论
💡引言
人工智能技术的飞速发展使得大模型成为了当前科技领域的热点之一。在这一领域,开源大模型和闭源大模型作为两种不同的发展路径备受关注。开源大模型强调共享和透明,而闭源大模型则更注重商业价值和知识保护。如何平衡技术发展和社会责任已成为一个亟待解决的问题。

✈️✈️一,开源大模型的优势与劣势
开源大模型以其开放、透明的特性吸引了大量研究者和开发者的参与。
✈️✈️1.1 优势:
共享知识:开源大模型为研究者和开发者提供了一个共享平台,促进了知识交流和合作。
透明度:开源大模型的代码和算法对所有人都是可见的,这有助于提高模型的质量和可靠性。
创新激励:开源大模型为其他研究者提供了灵感和启示,推动了技术的进步和创新。
from transformers import BertTokenizer, BertModel
import torch
# 加载预训练的模型和tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 输入文本
text = "Replace me by any text you'd like."
# 分词并添加特殊标记
inputs = tokenizer(text, return_tensors="pt")
# 前向传播
outputs = model(**inputs)
# 获取最后一层的隐藏状态
last_hidden_states = outputs.last_hidden_state
✈️✈️1.2 挑战和劣势:
安全风险:开源大模型可能面临安全漏洞和攻击的风险,特别是在处理敏感数据时。
数据隐私:开源大模型可能无法有效保护用户的数据隐私,这可能导致个人信息泄露和滥用的问题。
🚀🚀2. 闭源大模型的优势与劣势
相比之下,闭源大模型更加注重商业利益和知识保护。

🚀🚀2.1 优势:
商业价值:闭源大模型在商业应用中具有巨大的商业潜力,可以为企业带来可观的利润和竞争优势。
知识保护:闭源大模型可以有效保护企业的核心技术和商业利益,防止知识被不法分子利用或复制。
🚀🚀2.2 局限和挑战:
缺乏透明度:闭源大模型的代码和算法对外部人员不可见,这可能导致模型的质量和可靠性无法得到充分评估。
社会责任:闭源大模型可能面临社会舆论的质疑,特别是在涉及重要决策或公共利益的应用中。
技术发展与社会责任的平衡 在如何看待开源大模型和闭源大模型时,我们需要找到技术发展和社会责任之间的平衡点。一方面,我们应该鼓励开源大模型的发展,促进知识共享和技术创新;另一方面,我们也要重视闭源大模型的商业价值和知识保护,确保企业能够合法权益受到保护。
在这一平衡中,我们还需要考虑到数据隐私、安全风险、社会责任等因素。特别是在处理敏感数据和涉及重要决策的场景中,我们应该更加谨慎地评估开源和闭源模型的优劣势,并采取相应的措施保护用户的权益和社会的公共利益。
✏️✏️3. 结论
开源大模型和闭源大模型各有优劣势,选择哪种模型取决于具体的应用场景和需求。在技术发展和社会责任之间,我们应该寻求一个平衡点,既促进技术的进步和共享,又保护个人隐私和商业利益。只有在这样的平衡下,人工智能技术才能更好地造福人类社会,为我们创造更美好的未来。