目录
写在开头
一、数组的类型与维度
数组的类型
数组的维度
二、数组的创建
递增数组
同值数组
随机数数组
三、数组的索引
访问/修改单个元素
花式索引
数组的切片
四、数组的变形
数组的转置
数组的翻转
数组的形状改变
数组的拼接
五、数组的运算
数组与常数的运算
数组与数组的运算
六、数组的函数
线性代数中的矩阵乘法
数学函数
聚合函数
七、布尔型数组
布尔型数组的生成
布尔型数组的常用函数
八、从NumPy数组到PyTorch张量
写在最后
写在开头
近期好久不写博客了,主要是心态略有浮躁,同时对于自己的网络安全专业和未来方向也略显怀疑,可能还会迷茫一段时间,但我已经决定尽可能让自己忙碌起来,心态尽量平和,少受互联网信息的影响,避免过多思考人生与未来。至于这个新开的深度学习专栏的来由,主要是本人近期要开始研究写论文的东西,要选取一些深度学习模型对某种网络攻击类型进行检测,而我本人又对于深度学习的领域仅限于了解一些基础原理,实践能力(当调参侠)基本没有,因此我也从头开始慢慢学习,用博客做个记录。不过我相信慢就是快,一步一步脚踏实地慢慢来,也终将会有所进步。
此处还特别感谢B站爆肝杰哥的视频,详解了配置pytorch环境的每一步。这里放上其视频链接(本文并不涉及到pytorch的内容,后续博客可能会用到):
Python深度学习:安装Anaconda、PyTorch(GPU版)库与PyCharm_哔哩哔哩_bilibili
本文使用的NumPy库的版本为1.21,不过相近版本的语法都大差不差,基本可以通用。在进入深度学习具体算法的学习之前我们先介绍NumPy数组库,这是因为NumPy包为Python提供了数组变量的类型,弥补了Python本身数据类型的不足。虽然Python中的列表数据类型也可以实现数组的功能,但对于列表,其每个元素的数据类型是可以不同的,因此列表在存储元素的值的同时也要存储该元素的数据类型,这在一定程度上浪费了内存。而NumPy数组中的元素仅可容纳一种数据类型,存储时可以节约内存,加快运算速度,更方便深度学习的相关处理。下面我们做一个简单的引入:
import numpy as np
arr1 = np.array([10, 20, 30]) # 创建整数型数组
arr2 = np.array([1, 2, 3.]) # 创建浮点型数组,内涵浮点数,即为浮点型数组
list1 = ["hello", 100, 3.14] # 创建列表,元素的数据类型可以不同
print(arr1)
print(arr2)
print(list1)
可看到NumPy数组与Python列表的不同:
1. Numpy数组的元素数据类型一致(可分为整数型数组和浮点型数组),而列表可以不一致。
2. Numpy数组用print输出后元素之间是没有逗号','的,而列表的元素之间有逗号','作为分隔。
一、数组的类型与维度
数组的类型
Numpy数组就两种类型,整数型/浮点型。其中可以用.astype()方法相互转换,示例如下:
arr1 = np.array([10, 20, 30]) # 创建整数型数组
arr2 = arr1.astype(float) # 整数型转浮点型
arr3 = arr2.astype(int) # 浮点型转整数型
print(arr1)
print(arr2)
print(arr3)
另外通常情况下,整数型数组在运算过程中很容易升级为浮点型数组,只要与浮点数(组)做运算即可:
int_arr = np.array([10, 20, 30]) # 创建整数型数组
float_arr = np.array([1.0, 2, 3]) # 创建浮点型数组
print(int_arr + 0.0) # 整数型数组与浮点数进行运算
print(int_arr * 1.0)
print(int_arr / 1) # 除以整数也会升级为浮点型数组
print(int_arr + float_arr)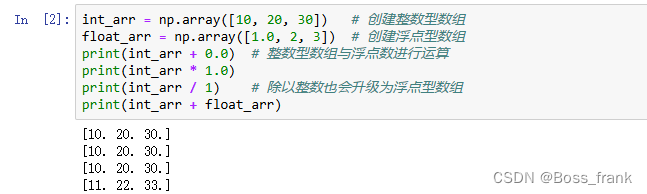
这里特别注意整数型数组遇到除法(即使是➗整数),都会升级为浮点数组
数组的维度
基本上不会遇到三维以上的,数组的中括号层数反应了该数组的维度。这里列个表描述一维到三维数组的表示:
| 数组维数 | 形状表示 | 举例说明 |
| 一维 | x 或 (x,) | 一维数组[1 2 3]的形状是3 或 (3,) |
| 二维 | (x, y) | 二维数组[[1 2 3]]的形状是(1, 3) |
| 三维 | (x, y, z) | 三维数组[[[1 2 3]]]的形状是(1, 1, 3) |
可以使用.shape属性(注意没有括号,不是方法!)查看数组的形状,举例如下

数组之间的相互转化,使用.reshape()方法即可,参数填写想要转换的维数,例如想把(2,3)的数组转化为(3, 2)的数组:
arr1 = np.array([[1, 2, 3], [4, 5, 6]])
print("转换前:\n",arr1)
arr2 = arr1.reshape((3, 2))
print("转化后:\n", arr2)
特别注意的是,reshape()方法有个方便之处,就是给定了每个维度之后,它可以自动算出最后一个维度是多少,最后的这个维度可以填写-1,举例如下:
# 将2*15的二维数组(矩阵)转换为5*6
arr1 = np.arange(30).reshape(2,15) # 生成2*15的整数递增数组
print("转换前:\n",arr1)
arr2 = arr1.reshape(5, -1) # 填写-1时,reshape会自动计算出此处应该是6
print("转化后:\n", arr2)
二、数组的创建
递增数组
直接用np.array()函数可以将Python列表转化为Numpy数组,这个方法我们已经实现过。另外还可以用np.arange()函数创建递增数组格式如下:
arr = np.arange([起始位置x], 终止位置y, [步长s] )
这个和python中的range函数类似,生成[x, y)范围内的数组。print()

同值数组
创建同值数组可以用np.zeros()创建全为0.0的数组,用np.ones()创建全为1.0的数组。
arr1 = np.ones(3)
print(arr1)
arr2 = 3.14 * np.ones((2,4)) # 创建全为3.14的2*4的矩阵
print(arr2)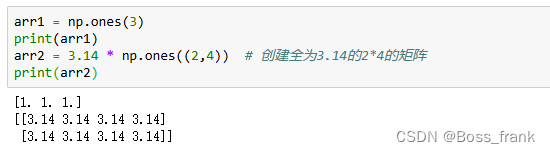
随机数数组
创建随机数组成的数组,需要使用np.random系列的函数,下面举例说明:
首先是0-1均匀分布,方法为np.random.random(形状),举例如下:
# 创建0-1范围均匀分布的矩阵
arr1 = np.random.random(5)
print(arr1)
# 创建90-100范围均匀分布
arr2 = (100-90)*np.random.random((2, 3)) + 90
print(arr2)
如果想生成整数型随机数组,则通过np.random.randint(min,max, shape)实现:
# 创建[1, 10)范围内的整数随机数组,矩阵形状为2*3
arr3 = np.random.randint(1, 10, (2,3))
print(arr3)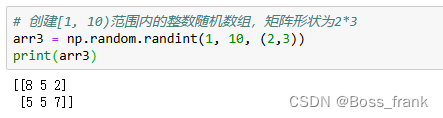
另外,服从正太分布的随机数组的创建方法是np.random.normal(μ, σ, shape):
# 创建均值为80,标准差为5的正太分布随机数组,矩阵形状为3*3
arr4 = np.random.normal(80, 5, (3,3))
print(arr4)
特别地,如果只需要标准正太分布,则可直接使用np.random.randn(shape)即可,只需要传入形状参数。
三、数组的索引
访问/修改单个元素
这个和Python列表一致,正索引从0开始,倒索引从-1开始,就懒得具体描述了。注意对单一元素修改时,不会改变原本矩阵的类型(整数型/浮点型)即可。
arr = np.arange(1, 10).reshape((3,-1))
print(arr)
arr[1,1] = 100.123 # 修改整形数组中的某个元素,数组依然为整形,该元素的浮点会被截断。
print(arr)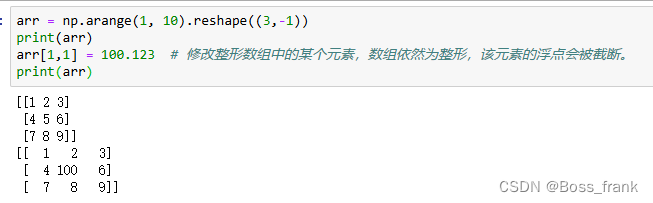
花式索引
用两层中括号可以进行花式索引,同时取出矩阵中的多个元素,输出仍然是个向量,举例如下:
arr = np.arange(1, 17).reshape((4,4))
print(arr)
# 花式索引,取出并修改副对角线的元素
print(arr[[0,1,2,3],[3,2,1,0]])
利用这种方法,可以同时修改矩阵中的多个元素:
arr = np.arange(1, 17).reshape((4,4))
print(arr)
# 花式索引,取出并修改副对角线的元素
arr[[3,2,1,0],[0,1,2,3]] = (100,200,300,400)
print("修改后:\n", arr)
数组的切片
这快其实完全可以类比Python中列表的切片,就简单举个例子略过好了:
# 生成10*10的矩阵
arr = np.arange(1, 101).reshape((10,-1))
print(arr)
# 取出第4-5行,4-5列
print("取出最中间的2*2:\n", arr[4:6, 4:6])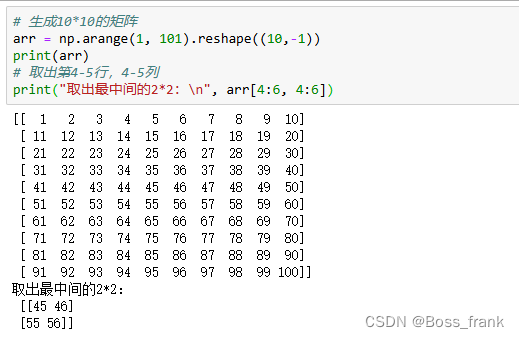
这里还需要特别注意:数组的切片仅仅是视图,数组的赋值也仅仅是绑定,并没有产生新的数组!
# 生成10*10的矩阵
arr = np.arange(1, 101).reshape((10,-1))
print(arr)
# 取出第4-5行,4-5列
arr2 = arr[4:6, 4:6]
arr3 = arr
arr2[:,:] = 999
print(arr)
print(arr2)
print(arr3)
由上图可知,改了arr2后,arr和arr2也会改变,这是因为不论是切片还是赋值,其实都不会创建新的数组,本质上都是相同的内存!要想创建新的变量,需要用到.copy方法才可(实际用到的很少,此处略)。
四、数组的变形
数组的转置
使用.T即可实现转置,注意转置操作仅对矩阵有效,如果是向量(一维数组)需要升级为矩阵(二维数组)
arr1 = np.arange(1, 5)
print("初始向量:\n", arr1)
# 升级为矩阵
arr2 = arr1.reshape((1,-1))
print("矩阵:\n", arr2)
print("转置后的结果\n", arr2.T)
数组的翻转
一共两个函数,分别是上下(up-down)翻转np.flipud()和左右(left-right)翻转np.fliplr()。注意对于向量(一维数组),只能进行上下翻转。这是因为在数学中,向量是以列向量的形式存在。下面举例说明即可:
# 向量的翻转
vec = np.arange(10)
print("初始向量:\n", vec)
vec_ud = np.flipud(vec)
print("向量翻转后:\n", vec_ud)
矩阵的翻转如下:
# 矩阵的翻转
mat = np.arange(25).reshape((5, -1))
print("初始矩阵:\n", mat)
mat_lr = np.fliplr(mat)
print("左右翻转:\n", mat_lr)
mat_ud = np.flipud(mat)
print("上下翻转:\n", mat_ud)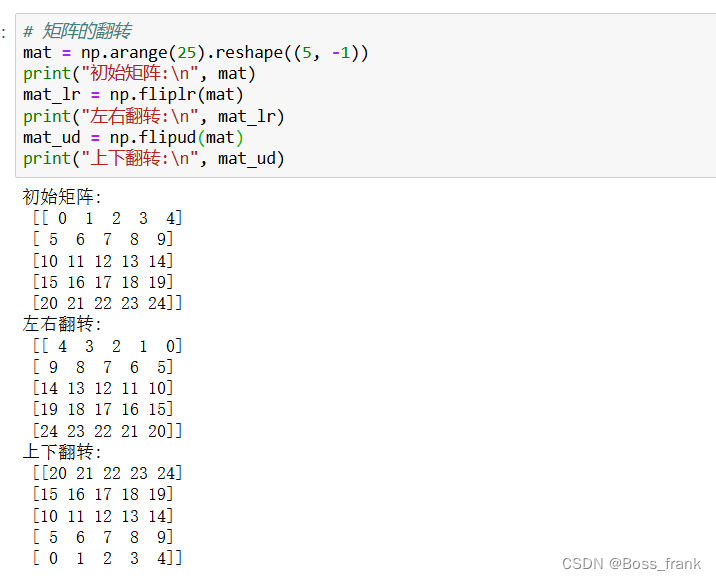
数组的形状改变
使用.reshape()方法即可,前面用到多次了,这里不再举例。
数组的拼接
使用函数np.concatenate([arr1, arr2])即可实现拼接,如果是向量(一维),直接拼接即可。如果是矩阵,默认情况按照axis=0进行拼接(要求列的维度相同),也可以指定按照另一个维度进行拼接,注意对应维度元素个数相等。向量不能和矩阵进行拼接,需要先升级为矩阵。
# 向量的拼接
vec1 = np.array([1,2,3])
vec2 = np.array([7,8,9])
vec3 = np.concatenate([vec1, vec2])
print(vec3)
矩阵拼接要注意对齐相应维数:
# 矩阵的拼接
mat1 = np.array([[1,2,3], [4,5,6]])
mat2 = np.array([[7,8,9], [10,11,12]])
mat3 = np.concatenate([mat1, mat2]) #默认情况,axis=0
mat4 = np.concatenate([mat1, mat2], axis=1) #非默认情况, 指定axis=1
print("axis=0拼接:\n", mat3)
print("axis=1拼接:\n", mat4)
五、数组的运算
数组与常数的运算
这个其实没啥好说的,就是Python中的那些常见运算符,加减乘除幂余取整啥的,常见运算符如下:
+ = * / ** // %
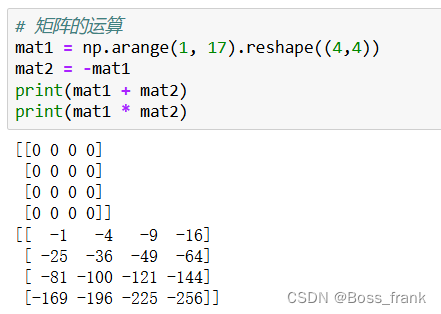
这些运算就是对矩阵中的元素逐个运算,特别注意除法会生成浮点型数组即可。随便举两个例子

数组与数组的运算
这里也没太多可讲的,如果数组的维度相同,则数组间的运算就是对应元素的运算(并不是线性代数中的运算方式)。
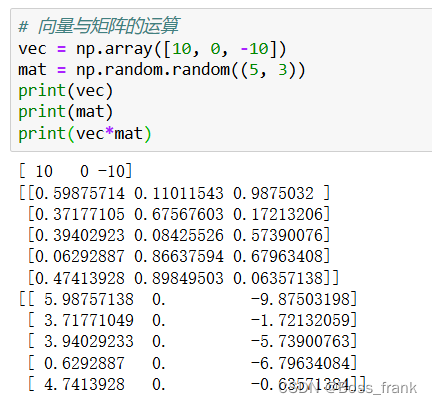
如果进行运算的数组的维数不同,则会出现某一方被广播的情况,例如:
1. 向量与矩阵运算,则向量自动升级为行矩阵。即如果是 (y,) 与 (x,y)运算,则(x,)会先升级为(1,y),然后再运算
2. 如果某矩阵是行矩阵或列矩阵,则该矩阵被广播,以适配另一个矩阵的形状。
与这个例子类似,列矩阵也可以被广播:

行矩阵和列矩阵也可以同时被广播,即(1,y)的行矩阵与(x,1)的列矩阵运算,相当于先把各自广播为(x, y),再进行运算:

六、数组的函数
线性代数中的矩阵乘法
就是函数np.dot(arr1,arr2)。当arr1和arr2均为向量时,相当于是向量点积,其他情况都可视为线性代数中的矩阵乘法:

数学函数
有一大堆,这里列一下好了
| 函数 | 说明 |
| np.abs() | 绝对值 |
| np.sin() | 正弦 |
| np.cos() | 余弦 |
| np.tan() | 正切 |
| np.exp() | 指数e*x |
| np.log() | 对数ln(x) |
举例说明一下对数函数吧,默认是以e为底,以其他为底的话需要用换底公式:

聚合函数
就是按照对应维度的方向求最大最小值,求和、平均值、标准差啥的。向量也可以,但向量没有axis参数,矩阵需要哪个用axis参数指明是哪个维度(当axis=0,最终结果的个数与每一行的元素个数相同。反之axis=1,最终结果的个数与每一列的元素个数相同)。列个表格:
| 函数 | 说明 |
| np.max(arr, axis=0), np.min(arr, axis=1) | 按维度求最大或最小值 |
| np.sum(arr, axis=0) | 按维度求和 |
| np.mean(arr, axis=0), np.std(arr, axis=1) | 按维度最均值或标准差 |
# 聚合函数
arr = np.arange(1, 11).reshape((2, 5))
print(arr)
print("按照维度0求均值: ", np.mean(arr, axis=0))
print("按照维度1求均值: ", np.mean(arr, axis=1))
print("整体求均值: ", np.mean(arr))
特别注意:考虑到大型数组难免有缺失值,以上聚合函数碰到缺失值时会报错,因此出现了聚合函数的安全版本,即计算时忽略缺失值:np.nansum( )、 np.nanprod( ) 、np.nanmean( )、np.nanstd( )、np.nanmax( )、np.nanmin( )。
七、布尔型数组
布尔型数组的生成
顾名思义,就是每个元素都是布尔类型的数组,可以通过一些比较运算符产生(>, <, ==, !=, >=, <=)。这些于是奶奶是还可以多个条件同时使用(用与,或,非对应&, |, ~)下面举例说明:
# 布尔类型的产生
arr = np.arange(25).reshape(5,-1)
print(arr)
# 将值在(10, 18)范围内的位置置为True
print((arr>10)&(arr<18))
print("满足条件的个数为:", np.sum((arr>10)&(arr<18)))
布尔型数组的常用函数
使用np.sum()函数可以统计布尔数组里True的个数,如上。另外还有两个常用函数,如下:
| 函数 | 说明 |
| np.sum(arr) | 统计布尔数组arr里True的个数 |
| np.any(arr) | arr中有一个是True,则为True,否则为False |
| np.all(arr) | arr中所有的都是True, 才为True,否则为False |
| np.where(arr) | 返回arr中是True的位置 |
这里可以举个例子,假设某次英语六级考试,10000人参加考试,所有人均分是425,标准差为70,进行一次模拟,判断是否所有的考生分数都>200,并找出高分的位置:
# 模拟六级成绩样本
arr = np.random.normal(425, 70, 10000)
# 判断是否所有人都高于200分
print(np.all(arr>200))
# 寻找高于650分的位置
print(np.where(arr>650))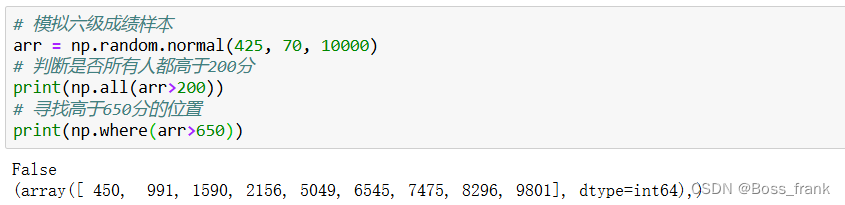
八、从NumPy数组到PyTorch张量
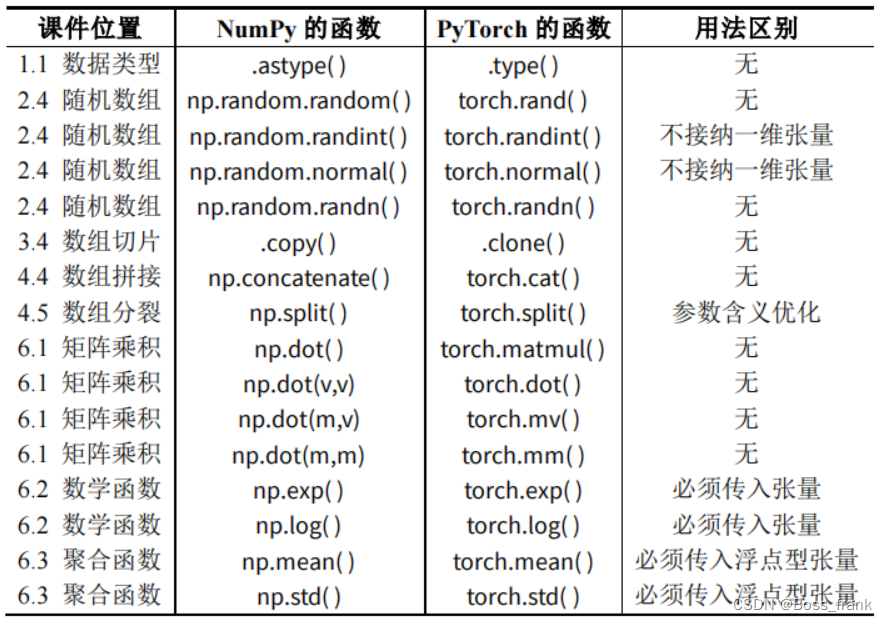
PyTorch作为当前最常用的深度学习库,融合了NumPy数组的语法,作为处理张量的基本语法,且运算可用GPU加速,具有很大速度优势。NumPy数组和PyTorch张量有一定的对应关系:
1.np 对应 torch ;2.数组 array 对应张量 tensor ;3.NumPy 的 n 维数组对应着 PyTorch 的 n 阶张量即NumPy数组和PyTorch张量可用相互转化:ts = torch.tensor(arr) 或 arr = np.array(ts)
NumPy数组和PyTorch张量相关处理的不同点,基本上将np改为torch,array改为tensor,即可对应Pytorch的处理方法。不过也有少量不同,此处根据B站爆肝杰哥的总结,列举不同点(表格源于B站:爆肝杰哥)。
写在最后
这一章节是PyTorch深度学习的基础,内容还挺多的。后续我可能还会更新一些DNN,CNN,RNN,GNN相关的博客,由于我的研究课题是要选取一些深度学习模型对某种网络攻击类型进行检测,可能会用到图神经网络相关的内容,后续学习的过程也会重点总结一下。
今年感觉状态稀碎,不过慢慢来,相信慢就是快!不要太过在意短期的得失。如果各位读者有什么问题也欢迎评论区指出,也可以私信与我讨论(也可以是技术无关的问题),我一定知无不言。