note
文章目录
- note
- 论文
- 1. 论文试图解决什么问题
- 2. 这是否是一个新的问题
- 3. 这篇文章要验证一个什么科学假设
- 4. 有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
- 5. 论文中提到的解决方案之关键是什么?
- 6. 论文中的实验是如何设计的?
- 7. 用于定量评估的数据集是什么?代码有没有开源?
- 8. 论文中的实验及结果有没有很好地支持需要验证的科学假设?
- 9. 这篇论文到底有什么贡献?
- 10. 下一步呢?有什么工作可以持续深入?
- Reference
论文

新加坡-南洋理工大学发的paper,2023年12月
我们还是从十大问题分析这篇论文,但由于是综述,可能没有实验环节详细的部分。
1. 论文试图解决什么问题
- 一篇关于Visual Instruction Tuning 视觉指令微调任务的综述,Visual Instruction Tuning是为了让多模态LLM拥有指令遵循能力
- 文章介绍传统CV局限性(需要针对不同任务训练不同模型,缺乏交互能力),如下图左侧
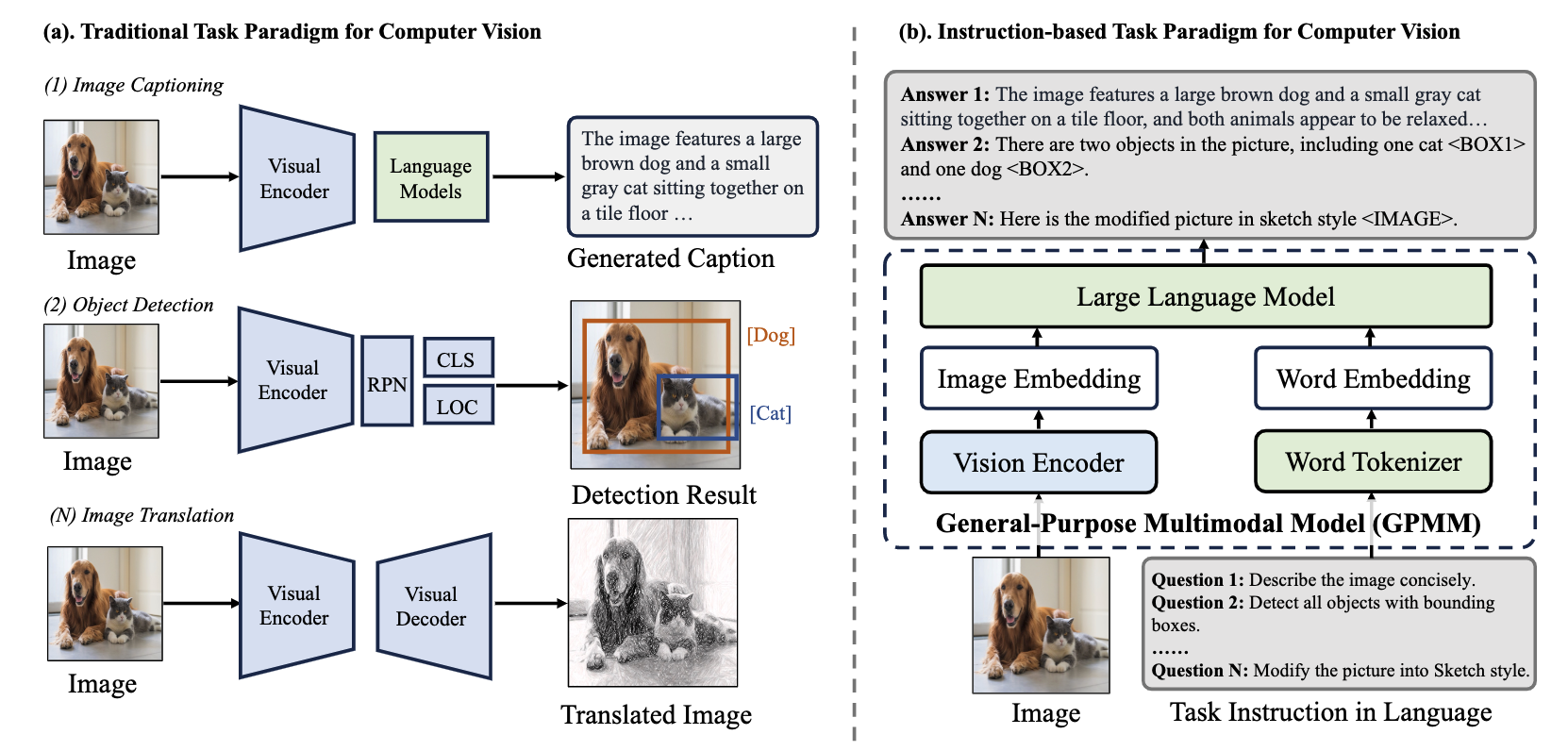
- 文章从三方面介绍Visual Instruction Tuning的发展过程:单语言(英语)到多语言、图片输入从单一到多元(从图片到视频/3D图像等)、任务复杂化(从基本的图片分类到VQA视觉问答、图像生成等难任务)
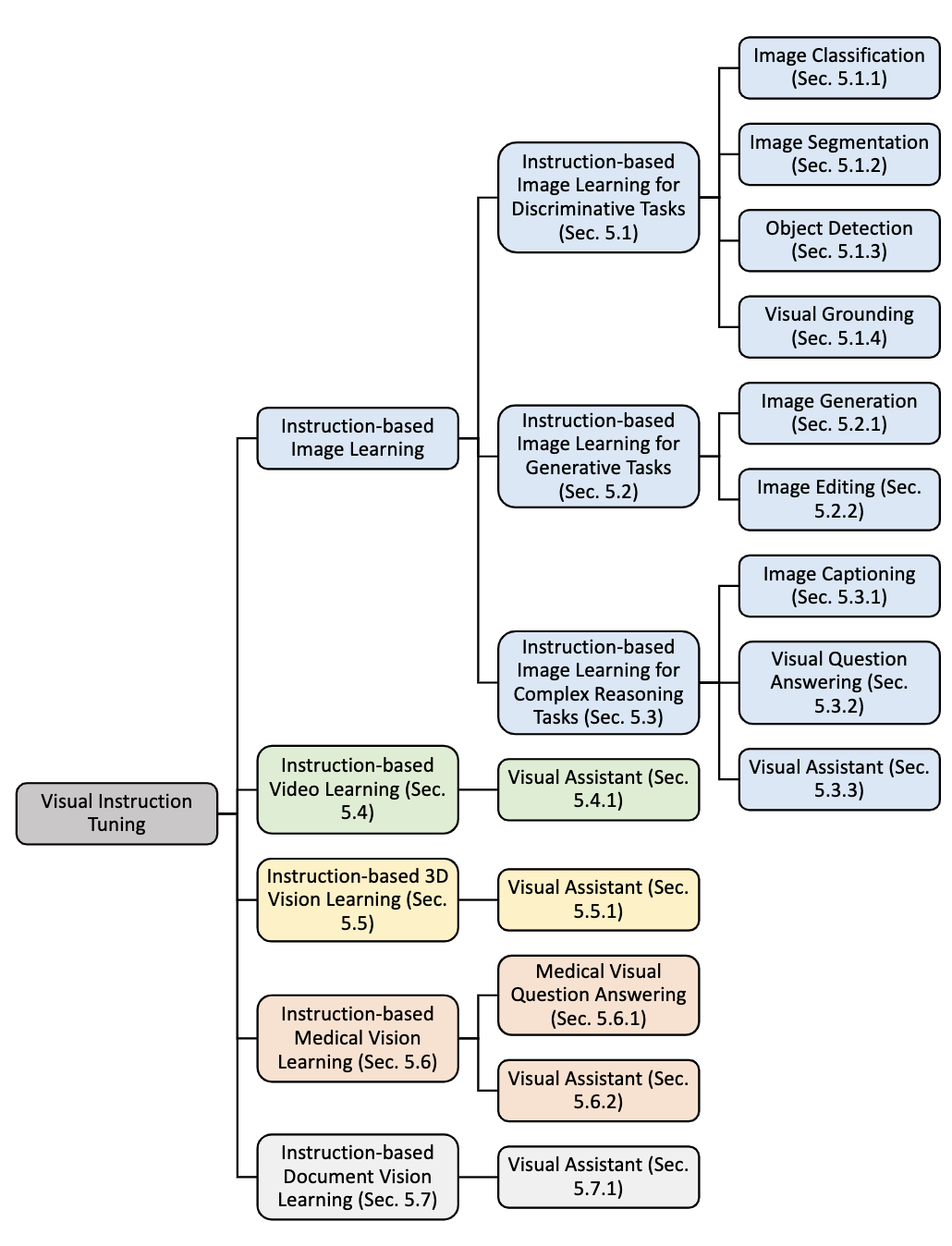
2. 这是否是一个新的问题
去年年底到今年,类似的综述还是不少的。
3. 这篇文章要验证一个什么科学假设
4. 有哪些相关研究?如何归类?谁是这一课题在领域内值得关注的研究员?
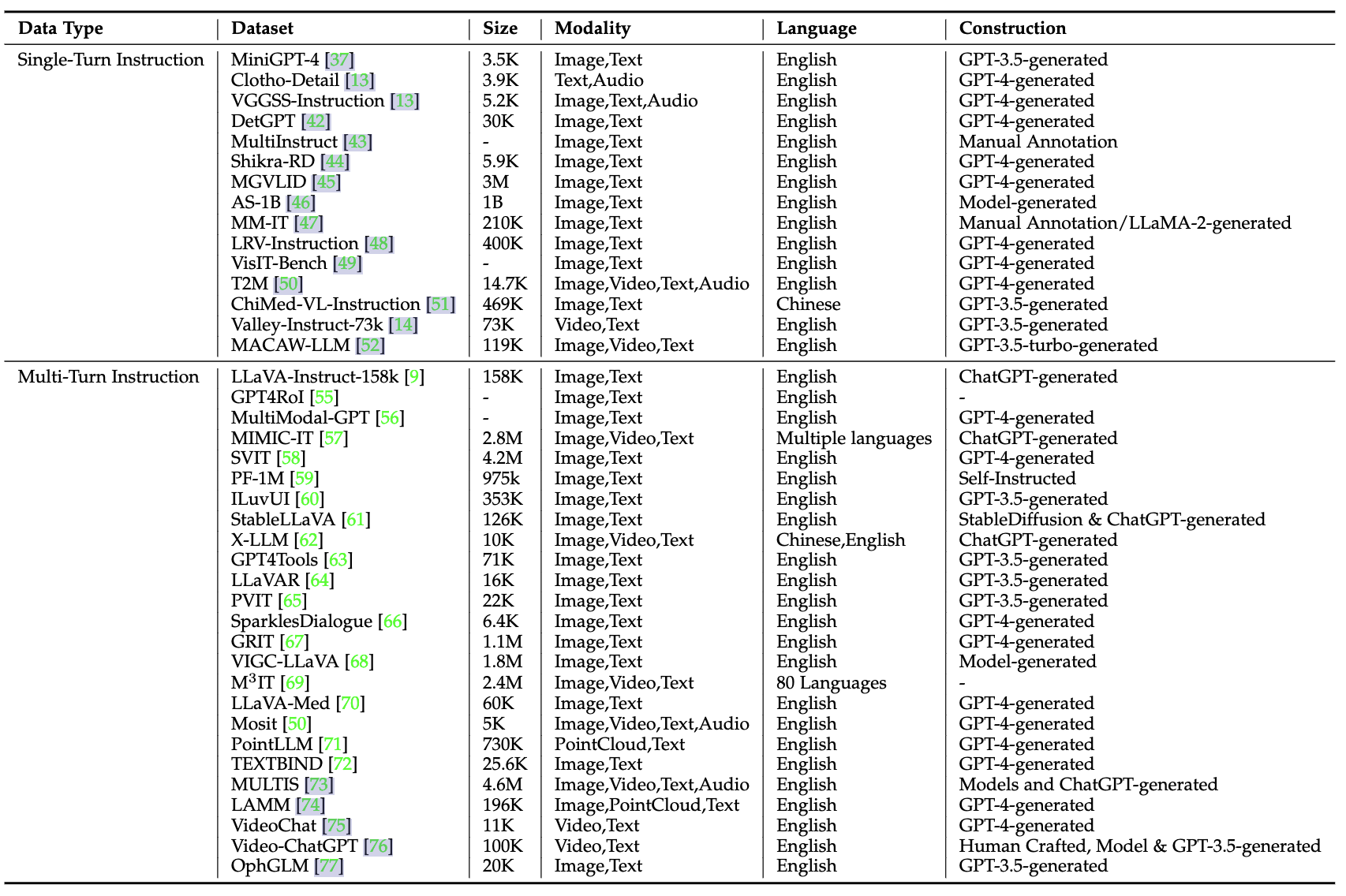
相关的视觉微调 公开数据集如下,大部分是GPT3.5或者GPT4构造的,而且多轮对话的visual SFT数据还不少:
5. 论文中提到的解决方案之关键是什么?
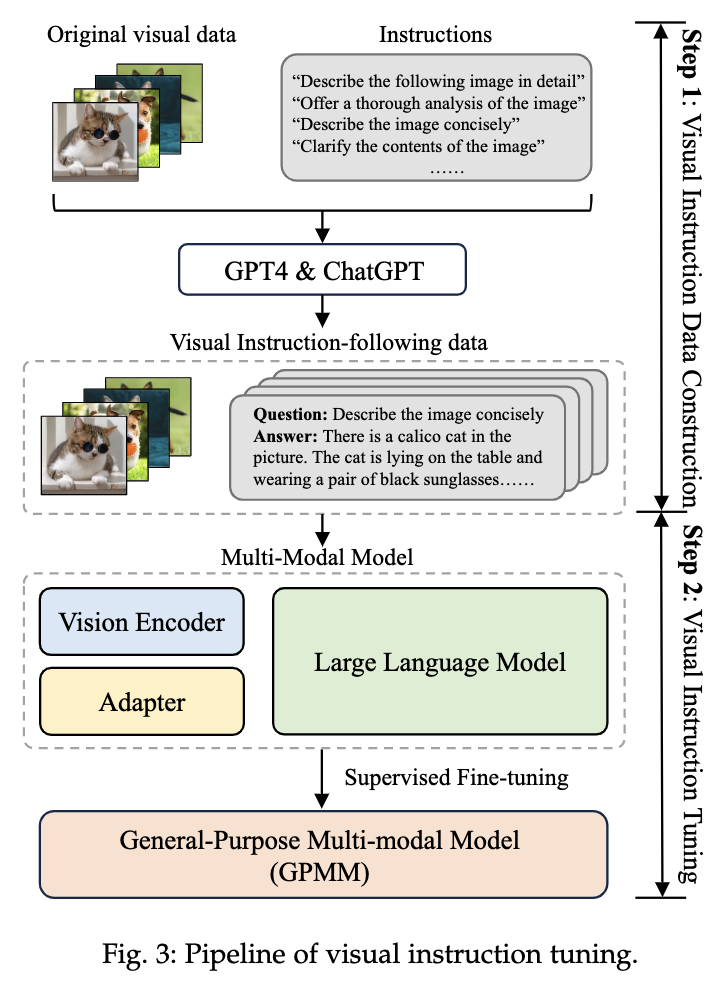
跟进一步,视觉微调的主流过程,基于预训练的LLM,将视觉特征token化冰对齐到语言空间中,利用语言模型得到多模态LLM的输出:
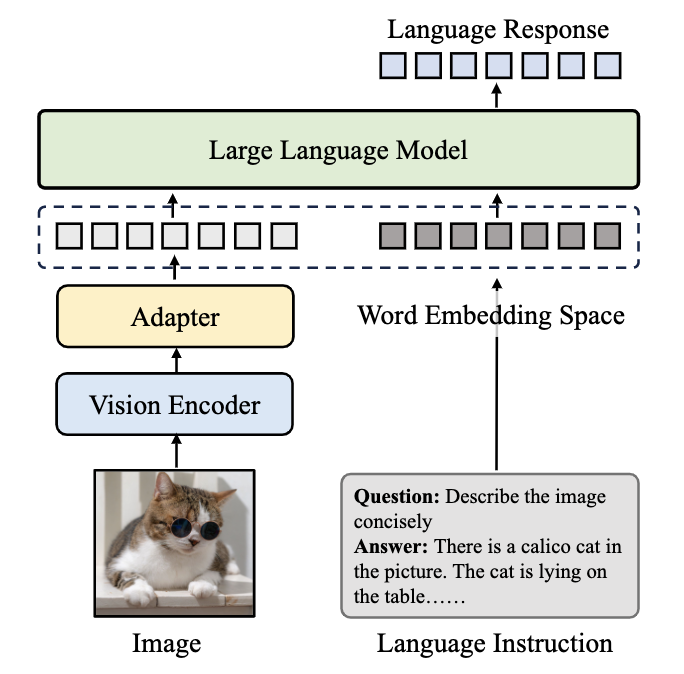
6. 论文中的实验是如何设计的?
是综述,没实验。
7. 用于定量评估的数据集是什么?代码有没有开源?
用于多模态视觉微调的评估数据集:
- VQAv2:Visual Question Answering(视觉问答)数据集,广泛用于评估模型在理解图像内容并回答问题方面的能力。
- GQA:Graphic Question Answering数据集,包含复杂的视觉问答任务,测试模型的视觉推理能力。
- OKVQA:Open-ended Knowledge Visual Question Answering数据集,需要外部知识来回答视觉问题,评估模型结合视觉和知识推理的能力。
- OCR-VQA:Optical Character Recognition Visual Question Answering数据集,测试模型在图像中识别和理解文本的能力。
- A-OKVQA:Augmented OKVQA数据集,扩展了OKVQA,包含更多样的问答对,测试模型在多种情境下的知识推理能力。
- MSCOCO:Microsoft Common Objects in Context数据集,包含丰富的图像标注信息,广泛用于图像识别和分割任务。
- TextCaps:数据集专注于图像字幕生成,测试模型在理解图像内容并生成自然语言描述方面的能力。
- RefCOCO、RefCOCO+、RefCOCOg:ReferIt Game数据集的变体,用于评估模型在图像中定位指定对象的能力。
- Visual Genome:包含图像、区域标注和关系描述的数据集,广泛用于视觉问答和图像理解任务。
- Flickr30K:包含丰富的图像及其描述的数据集,用于评估图像字幕生成和图像理解。
- VizWiz:数据集包含盲人用户拍摄的图像和相关问题,用于评估模型在处理实际场景和用户生成内容方面的能力。
- ScienceQA:针对科学领域的问答数据集,测试模型在结合视觉和科学知识回答问题方面的能力。
8. 论文中的实验及结果有没有很好地支持需要验证的科学假设?
略,综述没实验。
9. 这篇论文到底有什么贡献?
这篇综述对Visual Instruction Tuning进行了任务分类:
(1)Discriminative判别式任务:
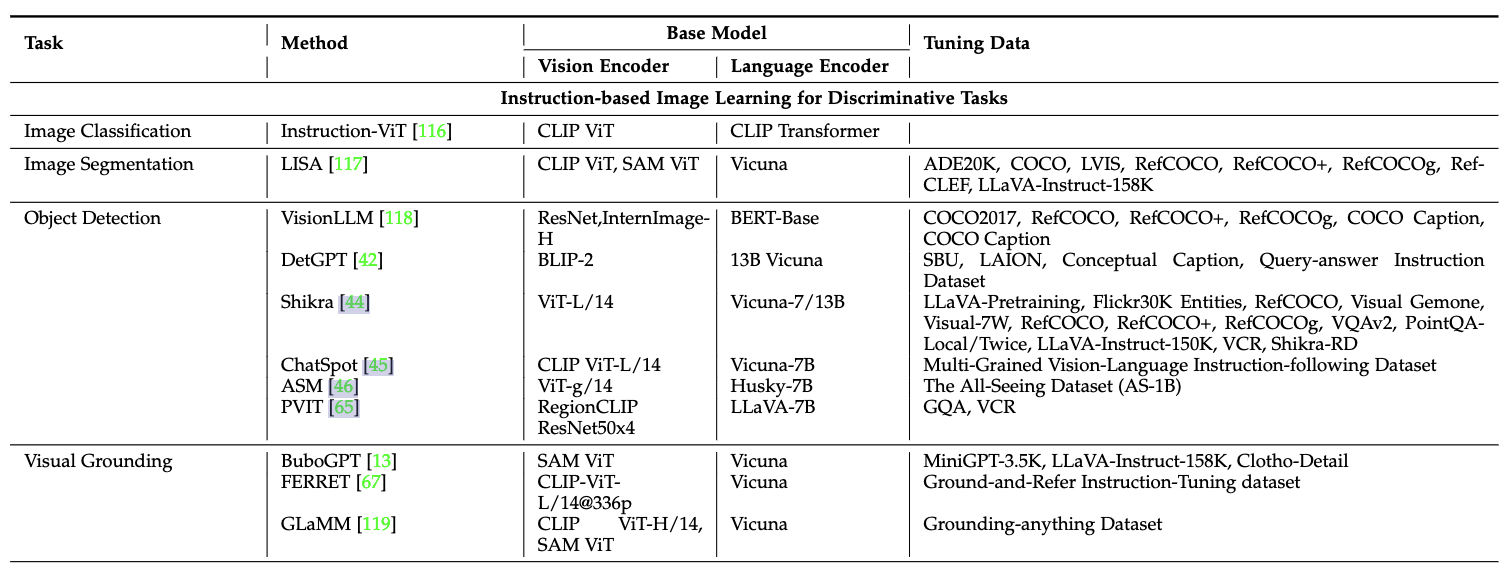
-
图像分类(Image Classification):利用可学习的
[CLS]token表示全局图像特征,计算[CLS] token和提示tokens之间的相似性,如下图
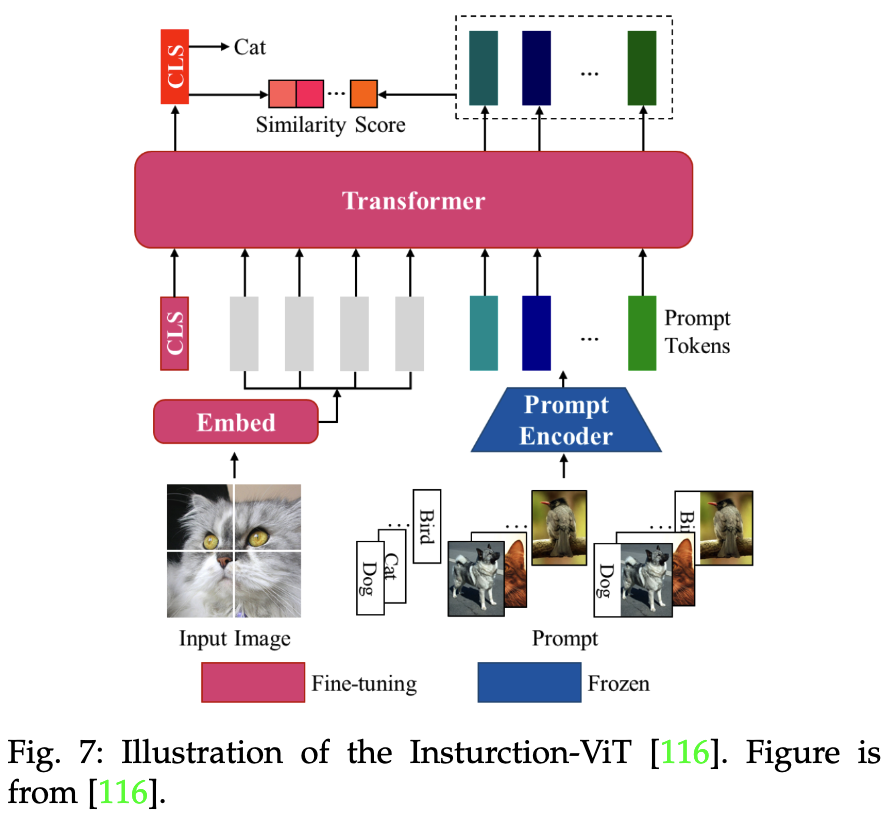
-
语义分割(Image Segmentation):常规的语义分割是像素级别的分类任务,LISA模型是根据复杂的query生成分割掩码,理解query并在图像中找到对应的区域(比如找到下面的维C最多的食物并标记),所以这里模型最终生成一张图。
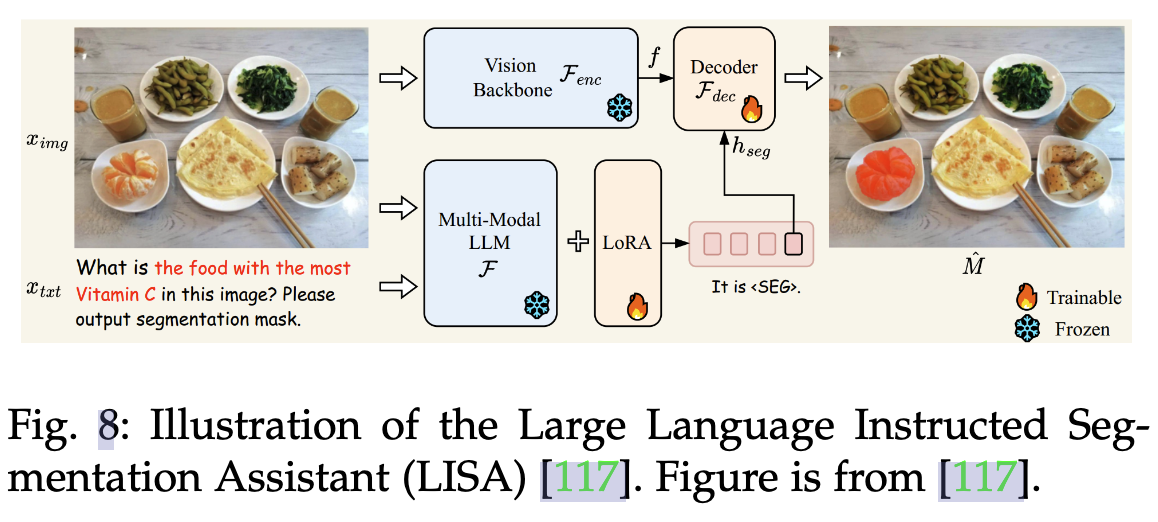
-
目标检测(Object Detection):下图是visionLLM的做法,提出一个指令感知图像分词器(Instruction-Aware Image Tokenizer)有效理解和解析视觉输入,总之是让LLM最终回答出query指向目标的上下左右坐标。VisionLLM 在 COCO 数据集上的目标检测任务中实现了超过 60% 的平均精度(mAP),这与特定于检测的模型相当。
- 视觉定位(Visual Grounding)
(2)生成式任务:
- 图像生成
- 图像编辑

(3)复杂推理任务:
- Image Captioning:图像描述,可以用如MiniGPT-4、Clever Flamingo等模型
- Visual Question Answering:即VQA视觉问答,可以用如MiniGPT-v2、instructBLIP等模型
- Visual Assistant:视觉助手,可以用如LLaVA、Qwen-VL(多任务预训练数据很好)等模型
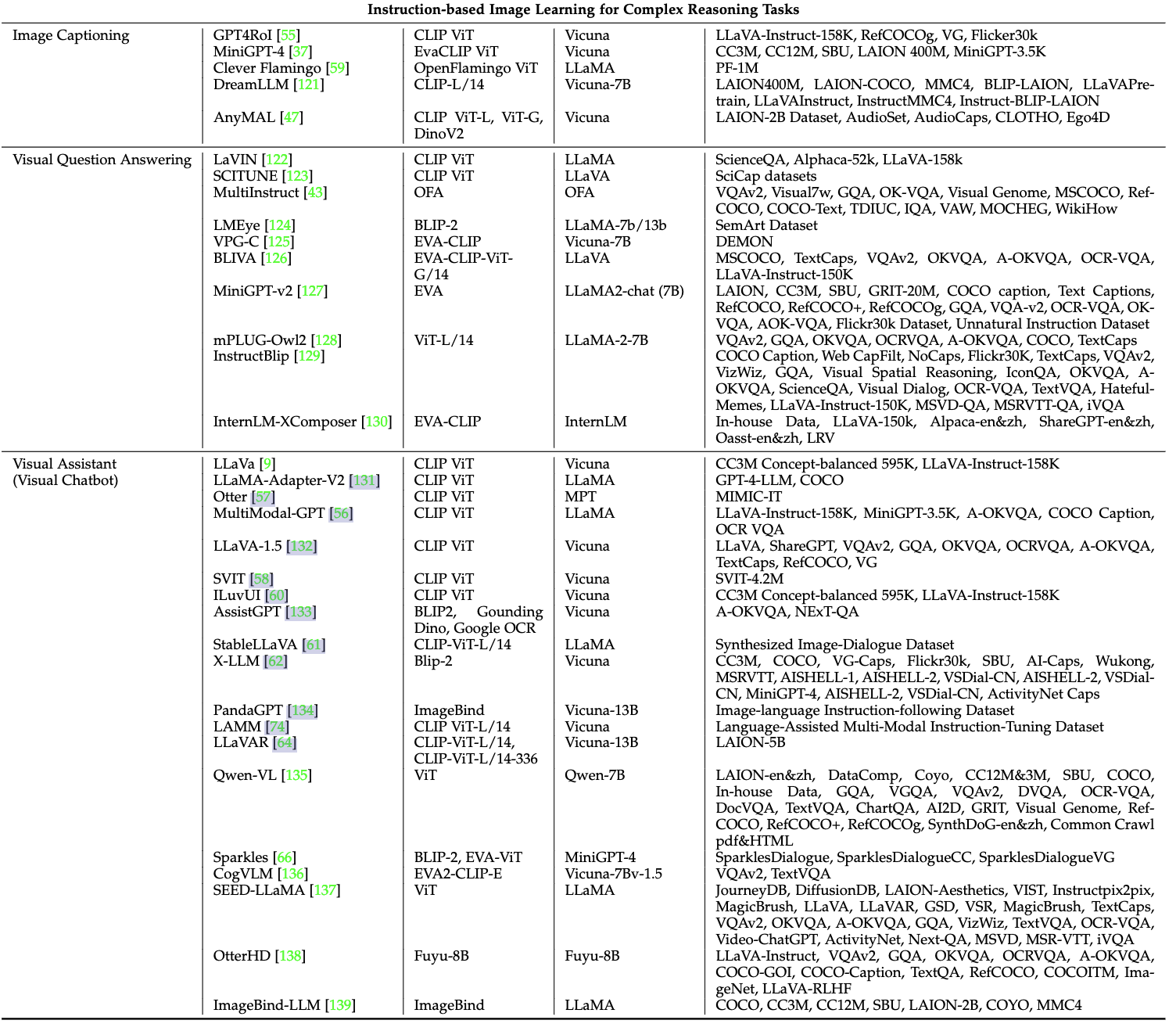
(4)视频学习的微调:视频理解、视频生成、视频字幕生成等
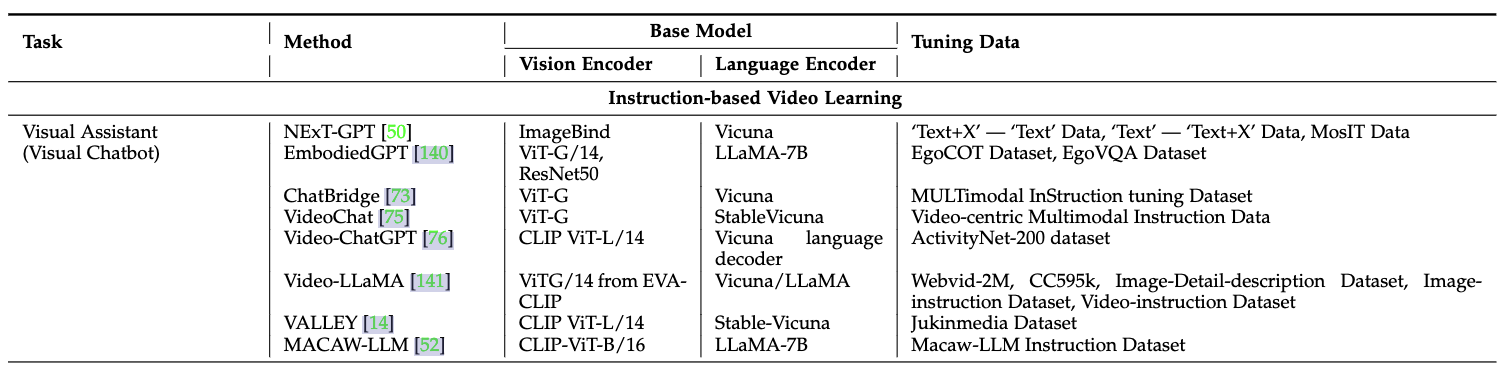
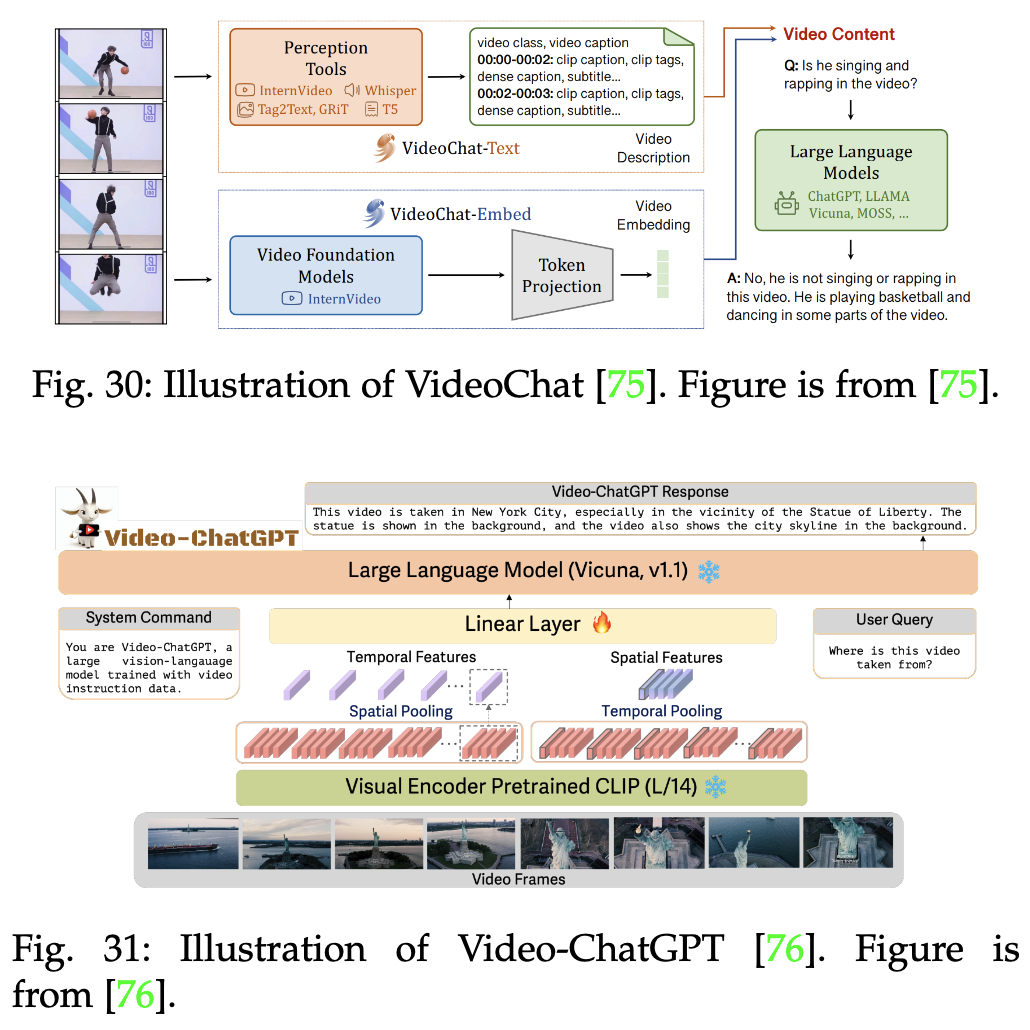
如video-chatgpt模型(如下),视频具有时序特性,Video-ChatGPT使用预训练的视频编码器将视频分割成多个帧,并提取每一帧的视觉特征。这些视觉特征再经过时序编码,生成包含时序信息的特征向量。用户可以对视频进行提问:
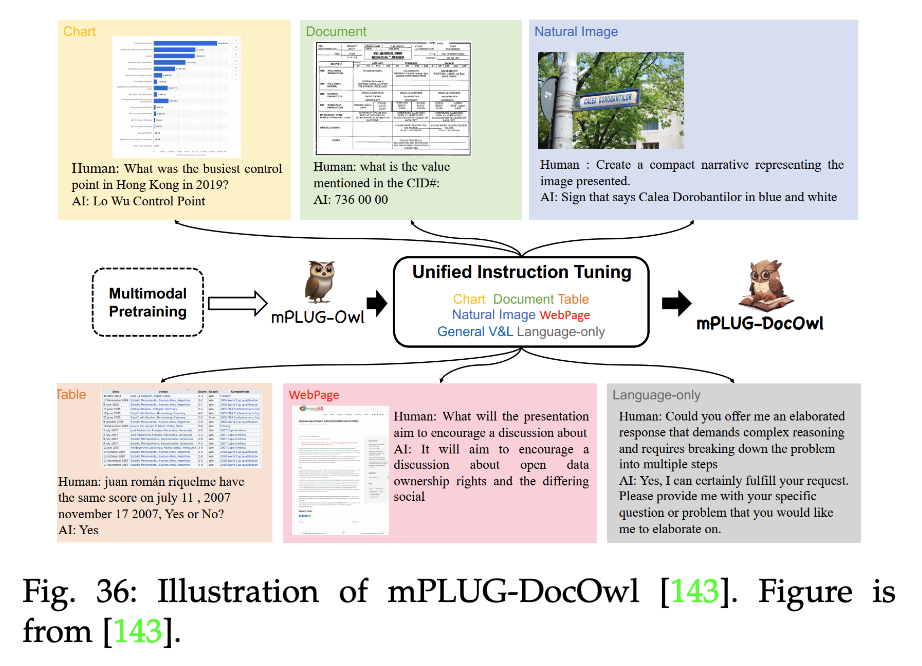
(5)文档学习的视觉微调:

如mPLUG-DocOwl模型:
(6)3D Vision Learning的视觉微调:包括depth estimation, 3D reconstruction(3D重建), object recognition, and scene comprehension(场景理解)等具体任务。
10. 下一步呢?有什么工作可以持续深入?
- 增强模型在视觉和语言之间的对齐能力
- 动态场景理解:比如视频、实时流媒体的多模态输入
- 用于帮助艺术家、设计师进行图像、视频编辑;用于教育领域等
Reference
[1] Visual Instruction Tuning towards General-Purpose Multimodal Model: A Survey



![打卡信奥刷题(19)用Scratch图形化工具信奥B3972 [语言月赛 202405] 二进制 题解](https://img-blog.csdnimg.cn/direct/de86e95a4bcf475aaa1aea664966c6e9.png)