目录
1. 项目相关背景
2. 搜索引擎的相关宏原理
3. 搜索引擎的技术栈和项目环境
4. 正排索引, 倒排索引, 搜索引擎具体原理
5. 编写数据去标签化和数据清洗的模块parser(解析器).
1.项目相关背景
百度, 搜狗, 360等都有搜索引擎, 但是都是全网的搜索;
boost是进行站内搜索, 数据更少并且垂直.
观察通过不同的搜索引擎进行查找的时候会出现不同的关键字, 一般包括title, content, 网址, 时间等.


2. 搜索引擎的相关宏原理
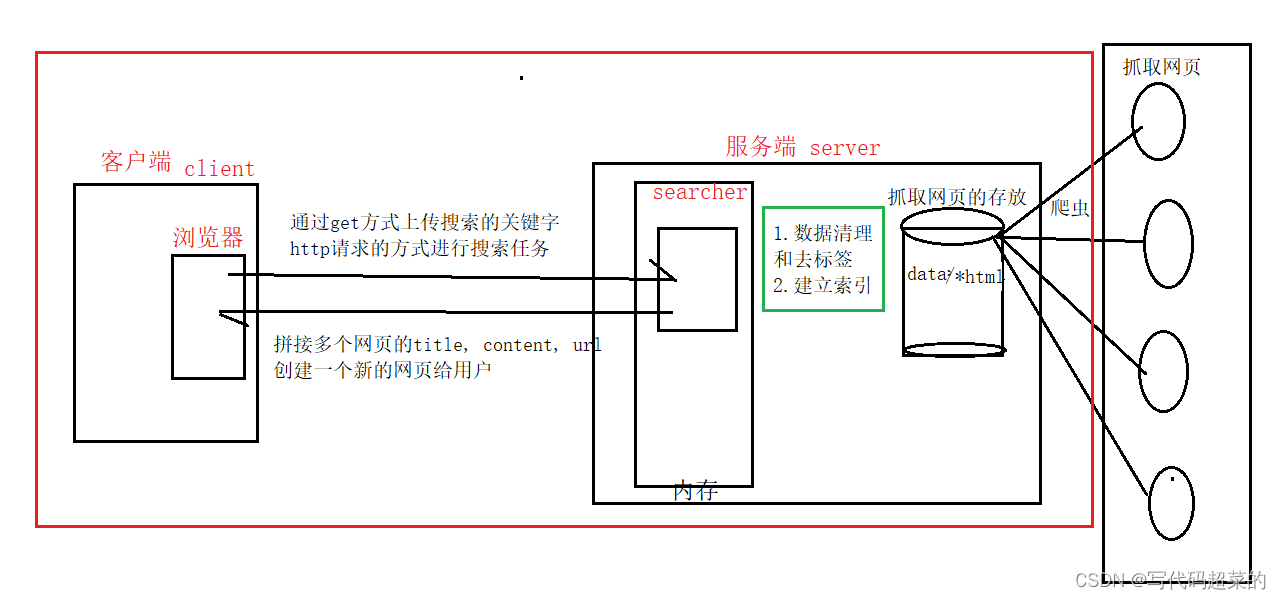
实现用户通过客户端的浏览器输入关键字, 通过get方式, 然后http发送请求给服务端内存中的searcher, searcher再通过已经抓取好网页并且存放在data/*html目录下进行数据清理和去标签建立索引的步骤, 将查找到的多个网页的title, content, url进行拼接, 最后返回给用户一个新的网页.
在后面实现的部分主要是完成对客户端和服务端的流程, 爬虫网页数据就不做了.
3. 搜索引擎的技术栈和项目环境
技术栈:
c/c++, c++11, STL, 标准库boost, Jesoncpp, cppjieba, cpp-httplib, html5, css, js, jQuery, Ajax.
项目环境:
Centos 7云服务器, vim/g++/Makefile, vscode.
4. 正排索引, 倒排索引, 搜索引擎具体原理
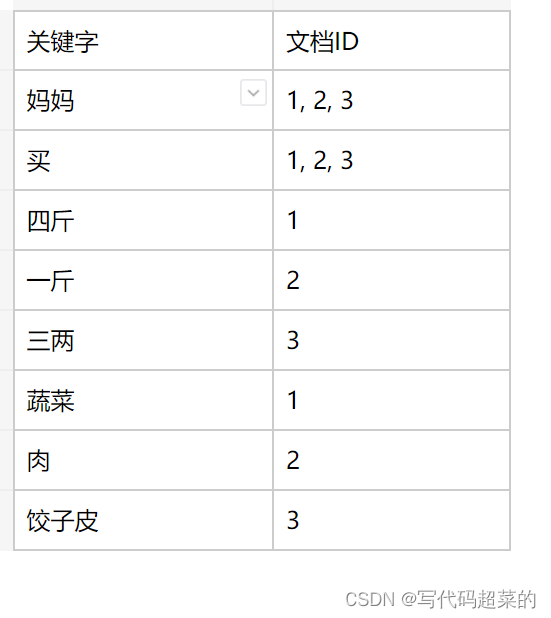
正排索引: 由文档ID找到文档内容;
倒排索引: 根据文档的内容, 分词, 整理不重复的各个关键字, 对应到相应的文档ID.
举个栗子:
妈妈买了四斤蔬菜; 妈妈买了一斤肉; 妈妈买了三两饺子皮.
正排索引:
倒排索引:

5. 编写数据去标签化和数据清洗的模块parser(解析器)
5.1 官网下载标准库
首先到boost官网去下载好标准库; 网址: https://www.boost.org/
然后使用Xshell将下载好的标准库rz, 然后解包, 将标准库留下.
这里我是创建了一个boost_searcher目录来存放所有需要的文件数据.
其中boost_1_85_0就是boost下载好的标准库.
data目录下的input(从boost_1_85_0里面的doc目录下的html目录的全部数据拿出来的)存放原始html的数据, raw_html是处理过的文件数据.
parser.cc就是用来实现去标签化和数据清洗的函数.

5.2 去标签
一般html文件里面都是出现大量成对的标签, 我们只需要内容, 所以标签对我们没有作用要去除.
去除标签之后的每个文档如何区分捏?
使用\3进行标记区分文档. 读取的时候使用getline(ifstream, line); line就是\3.
5.3 编写parser代码
1. 在boost_searcher里创建一个parser.cc的文件;
2. 先实现大体的框架; 首先EnumFile递归原html的所有文档, 将它们放到file_list数组里面;
3. ParserHtml从file_list里面将文件读取出来并且解析出来title, content, url;
4. SaveHtml 是将解析好的数据文件写入到output里面.
#include <iostream>
#include <vector>
#include <string>
#include <boost/filesystem.hpp>
#include <utility>
#include <fstream>
#include "util.hpp"
using namespace std;
// 原来没处理过的html数据的文件目录.
const string src_path = "data/input";
// 将数据清洗以及去标签过的数据放到这个目录文件中
const string output = "data/raw_html/raw.txt";
typedef struct DocInfo
{
string title;
string content;
string url;
}DocInfo_t;
//这里规定一下:
//const &: 输入;
//*: 输出;
//&: 输入输出;
bool EnumFile(const string& src_file, vector<string>* file_list);
bool ParserHtml(const vector<string>& file_list, vector<DocInfo>* results);
bool SaveHtml(const vector<DocInfo_t>& result,const string& output);
int main()
{
//1. 递归将所有的html文件带路径的保存到file_list, 方便对文件进行一个个查询.
vector<string> file_list;
if(!EnumFile(src_path, &file_list))
{
cerr << "Enum File error!" << endl;
return 1;
}
//2.按照file_list读取每个文件的内容.并且进行解析;
vector<DocInfo_t> results;
if(!ParserHtml(file_list, &results))
{
cerr << "Parser Html error!" << endl;
return 2;
}
//3.将各个文件进行解析好的文件内容, 写入到output, \3为每个文档的分割符;
if(!SaveHtml(results, output))
{
cerr << "Save Html error!" << endl;
return 3;
}
return 0;
}EnumFile模块:
1.首先使用到标准库里面的接口boost::filesystem以及path来查看是否src_file的资源路径是否存在.
2. 使用ecursive_directory_iterator对src_file资源进行遍历, 再进一步筛选是否为普通文件以及.html后缀的文件. 如果是的话就将其放到数组file_list里面.
bool EnumFile(const string& src_path, vector<string>* file_list)
{
// 这里是标准库<boost/filesystem.hpp>提供的接口和结构体;
namespace fs = boost::filesystem;
fs::path root_path(src_path);
// 实现判断原资源数据路径是否存在.
if(!fs::exists(root_path))
{
cerr << src_path << "no exists" << endl;
return false;
}
//进行html文档的遍历, 如果为空就是遍历完成了.
fs::recursive_directory_iterator end;
for(fs::recursive_directory_iterator iter(root_path); iter != end; iter++)
{
//判断是否为普通文件, 因为html都是普通文件.
if(!fs::is_regular_file(*iter))
{
continue;
}
//判断是否为html后缀的文件.
if(iter->path().extension() != ".html")
{
continue;
}
cout << "debug: " << iter->path().string() << endl;
//当前路径一定是合法的html为后缀的文件
file_list->push_back(iter->path().string());
}
return true;
}1. ParserHtml: 将处理好的源html数据存放在file里的, 对其进行遍历, 然后对文件中的title, content, url进行解析, 最后存放到result数组里面.
2. 然后使用ParserTitle进行将title解析; 因为title的内容都是放在<title> </title>里面;
我们只要找到<title> 和 </title> 然后将中间的内容切分即可.
3. ParserContent进行去标签获取内容, 采用状态机的方法, 枚举LABLE和CONTENT, 这里需要注意一般html里面开头也是标签, 所以初始化status是LABLE, 对file进行遍历, 如果遇到>那么就代表是标签的结束, status就是CONTENT, 如果遇到<那么就代表是标签的开始, status就是LABLE. 如果遇到\n, 我们需要使用\n做分隔符, 所以要把原来的变成空串, 最后将拼接好的字符串放到content.
4. ParserUrl进行url的解析, 那么我们boost官网查询和我们存放在自己的路径是不同的.
上面是url_head, 下面的url_tail只shangchu需要将data/input删除即可.




static bool ParserTitle(const string& file, string* title)
{
size_t begin = file.find("<title>");
if(begin == string::npos)
return false;
size_t end = file.find("</title");
if(end == string::npos)
return false;
begin += string("<title>").size();
if(begin > end)
return false;
*title = file.substr(begin, end - begin);
return true;
}
static bool ParserContent(const string& file, string* content)
{
//去除html里面的标签;状态机
enum status
{
LABLE,
CONTENT
};
//默认一般html的开头都是标签.
enum status s = LABLE;
for(char c : file)
{
switch(s)
{
case LABLE:
if(c == '>')
s = CONTENT;
case CONTENT:
if(c == '<')
s = LABLE;
else
{
//原本文件的\n去除, 因为要用\n来做文本分割符;
if(c == '\n')
c = ' ';
content->push_back(c);
}
break;
default:
break;
}
}
return true;
}
static bool ParserUrl(const string& file_path, string* url)
{
//这个是网址拼接.
string url_head = "https://www.boost.org/doc/libs/1_85_0/doc/html/accumulators.html";
string url_tail = file_path.substr(src_path.size());
*url = url_head + url_tail;
return true;
}
static void ShowDoc(const DocInfo& doc)
{
cout << "title: " << doc.title << endl;
cout << "content: " << doc.content << endl;
cout << "url: " << doc.url << endl;
}
//将获取的html资源file_list解析处理后放到result;
bool ParserHtml(const vector<string>& file_list, vector<DocInfo_t>* results)
{
for(const string& file : file_list)
{
string result;
//读取每个文件的内容;
if(!ns_util::FileUtil::ReadFile(file, &result))
{
continue;
}
DocInfo_t doc;
//解析文件, 读取title;
if(!ParserTitle(result, &doc.title))
{
continue;
}
//解析文件, 读取content;
if(!ParserContent(result, &doc.content))
{
continue;
}
//解析文件, 读取url;
if(!ParserUrl(result, &doc.url))
{
continue;
}
results->push_back(move(doc)); //提高效率减少拷贝.
//for test
ShowDoc(doc);
break;
}
return true;
}util.hpp: FileUtil是将每条源html的资源进行输出;
#pragma once
#include <iostream>
#include <vector>
#include <string>
#include <fstream>
using namespace std;
namespace ns_util
{
class FileUtil
{
public:
//读取文件file_path里面的内容并且放到out;
static bool ReadFile(const string& file_path, string* out)
{
ifstream in(file_path, ios::in);
//如果没有打开文件成功
if(!in.is_open())
{
cerr << "open file" << file_path << "error" << endl;
return false;
}
string line;
while(!getline(in, line))
{
*out += line;
}
in.close();
return true;
}
};
};SaveHtml:将解析好的数据进行文档分割和内容分割. 将解析好的数据以这种方式写入到output.
//将解析的数据读写到output每个文档\n分割, 每个文档的title, content, url以\3分割.
bool SaveHtml(const vector<DocInfo_t>& result,const string& output)
{
#define SEP '\3'
//采用二进制方式写入;
ofstream out(output, ios::out | ios::binary);
if(!out.is_open())
{
cerr << "open " << output << "failed!" << endl;
return false;
}
for(auto& item : result)
{
string out_string;
out_string = item.title;
out_string += SEP;
out_string += item.content;
out_string += SEP;
out_string += item.url;
out_string += '\n';
out.write(out_string.c_str(), out_string.size());
}
out.close();
return true;
}后言: 好久没更新博客了, xdm求个三联, 多多更新超多计算机网络, Linux, c++, c, 算法内容.