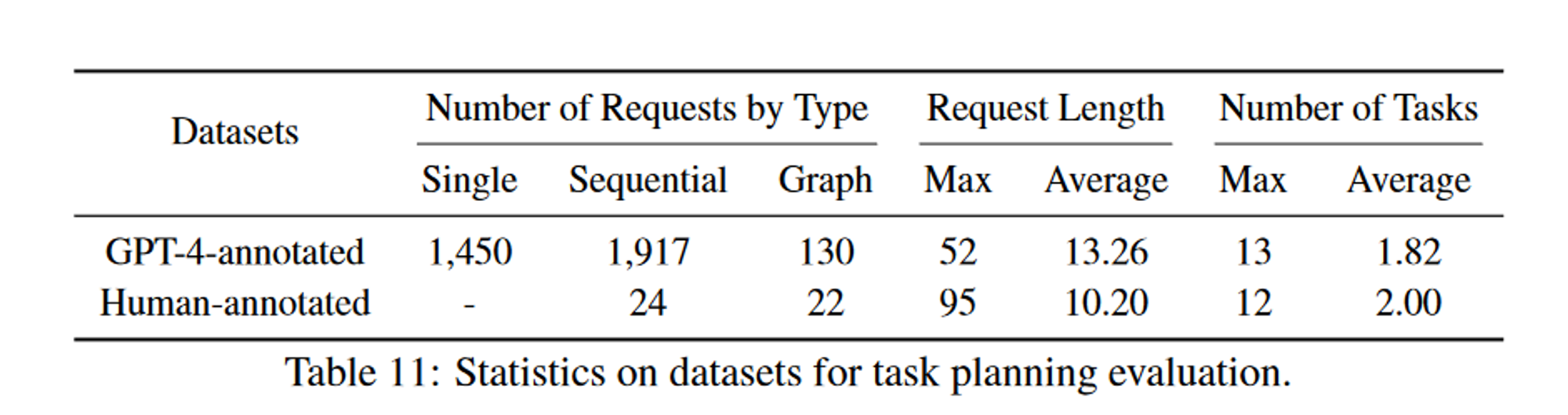
机器学习分类问题详解与实战
介绍
在机器学习中,分类问题是一类常见的监督学习任务,其目标是根据输入特征将数据样本划分为预先定义的类别之一。分类问题广泛应用于各个领域,如图像识别、自然语言处理、金融风险评估等。本文将详细介绍机器学习分类问题的基本概念、常用算法,并通过Python代码进行实战演练。
分类问题基本概念
在分类问题中,我们通常有一组带有标签的训练数据,每个数据样本都由特征向量和对应的类别标签组成。机器学习算法通过学习训练数据的特征和标签之间的关系,来建立一个分类模型。然后,我们可以使用这个模型对新的、未见过的数据样本进行分类预测。
分类问题的数学表示
- One-hot 编码:将每个类别映射到一个独立的维度上,并在该维度上使用1来表示该样本属于该类别,其余维度为0。
- 概率表示:使用每个类别的概率来表示数据属于该类别的可能性。在深度学习中,这种表示方法更为常用,因为它允许模型输出每个类别的置信度。
在分类任务中,常用的模型包括逻辑回归、支持向量机、决策树等。这些模型都可以将输入特征映射到类别标签上,并通过优化目标函数(如交叉熵损失函数)来逼近真实标签。
常用分类算法
- 逻辑回归(Logistic Regression):一种广义的线性回归模型,用于处理二分类问题。通过逻辑函数(sigmoid函数)将线性回归模型的输出映射到0和1之间,表示样本属于某个类别的概率。
- 支持向量机(Support Vector Machine, SVM):一种基于统计学习理论的分类方法,通过寻找一个最优的超平面来划分不同类别的数据。对于非线性问题,可以通过核函数将原始数据映射到高维空间,从而使其线性可分。
- 决策树(Decision Tree):一种树形结构的分类模型,通过一系列的判断条件将样本划分到不同的类别中。决策树模型直观易懂,易于解释,且能够处理离散和连续特征。
- 随机森林(Random Forest):一种基于决策树的集成学习方法,通过构建多个决策树并将它们的预测结果进行投票来得到最终的分类结果。随机森林具有良好的泛化能力和抗过拟合能力。
- Softmax回归(多项式逻辑回归):当类别标签多于两个时,我们通常使用Softmax回归(也称为多项式逻辑回归)来处理。Softmax回归可以将模型的输出转换为概率分布,使得所有类别的概率之和等于1。这样做的好处是模型输出更加符合直觉,方便进行决策。在Softmax回归中,我们使用Softmax函数将模型的线性输出转换为概率分布。Softmax函数的形式为:
- 其中z是模型的线性输出,zi和zj分别是z的第i个和第j个元素。Softmax函数将z的每个元素转换为0到1之间的概率值,并且所有概率值之和等于1。
损失函数与优化
当处理分类问题时,特别是多分类问题,我们经常使用交叉熵损失函数(Cross-Entropy Loss)作为损失函数。对于二分类问题,交叉熵损失函数可以简化为对数损失函数(Log Loss)或称为二元交叉熵损失(Binary Cross-Entropy Loss)。
交叉熵损失函数(Cross-Entropy Loss)
对于多分类问题,假设有K个类别,真实标签采用one-hot编码形式,模型输出的概率分布为p(即经过Softmax层后得到的概率分布),则交叉熵损失函数的公式为:
其中,
是样本的数量。
是第(i)个样本对应第(j)个类别的真实概率(采用one-hot编码,因此只有一个值为1,其余为0)。
是模型预测的第(i)个样本属于第(j)个类别的概率。
对数损失函数(Log Loss)或二元交叉熵损失(Binary Cross-Entropy Loss)
对于二分类问题,交叉熵损失函数可以简化为:
其中,
- (N) 是样本的数量。
是第(i)个样本的真实标签(通常0表示负类,1表示正类)。
是模型预测的第(i)个样本属于正类的概率。
在二分类问题中,通常还会使用Sigmoid函数将模型的输出映射到(0, 1)之间,表示为正类的概率,然后用上述的二元交叉熵损失函数来计算损失。
注意:在实际编程中,为了数值稳定性,通常会使用和
来避免对0或1取对数的情况,其中
是一个很小的正数(如
)。
实战演练
下面,我们将使用Python的scikit-learn库来实现一个简单的分类任务。我们将使用鸢尾花(Iris)数据集,这是一个经典的分类数据集,包含150个样本,每个样本有四个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度)和一个类别标签(山鸢尾、杂色鸢尾、维吉尼亚鸢尾)。
# 导入必要的库和数据集
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建随机森林分类器实例
clf = RandomForestClassifier(n_estimators=100, random_state=42)
# 训练模型
clf.fit(X_train, y_train)
# 使用模型对测试集进行预测
y_pred = clf.predict(X_test)
# 计算预测准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"模型准确率:{accuracy:.2f}")在随机森林分类器的训练过程中,我们并不直接计算损失函数(如交叉熵损失或对数损失)来优化模型参数,因为随机森林是一种基于集成学习的算法,它通过构建多个决策树并进行投票来得到最终的分类结果。每个决策树在训练过程中会基于某种分裂准则(如基尼不纯度或信息增益)来构建,而不是通过最小化损失函数。
然而,当我们评估随机森林分类器的性能时,我们通常会使用准确率、精确率、召回率、F1分数等指标,或者使用交叉验证来评估模型在未见过的数据上的性能。如果我们想要观察模型在训练过程中的某种“损失”,我们可以计算预测概率和真实标签之间的某种度量,但这并不是随机森林训练过程的一部分。
总结
- 多分类问题的关键在于将输入数据映射到正确的类别标签上,这通常通过训练一个能够输出类别概率的模型来实现。
- Softmax 函数在模型输出层使用,用于将模型的原始输出转换为概率分布。
- 对数损失函数和交叉熵损失函数用于衡量模型预测与真实标签之间的差异,并指导模型参数的优化。
在深度学习中,通过选择合适的模型结构、激活函数和损失函数,可以有效地解决多分类问题。同时,使用优化算法(如梯度下降)来最小化损失函数,从而得到最优的模型参数。