PgSQL内核机制 - 算子执行统计元组个数
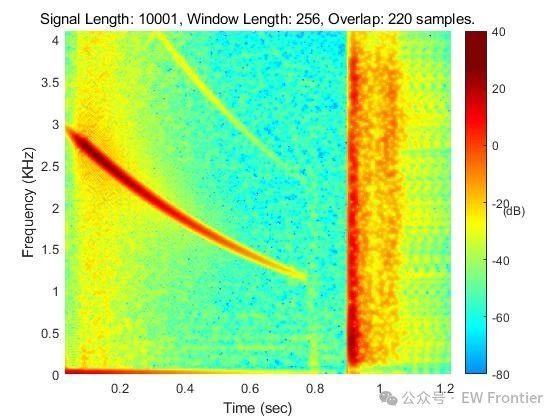
我们在执行explain analyze观察执行计划执行情况时,时常通过每个算子实际执行结果来分析SQL的执行,其中有一项“rows = XXX”表示执行的行数(这里姑且先认为是执行的真实行数)。但有些场景下,比如MergeJoin,如下:
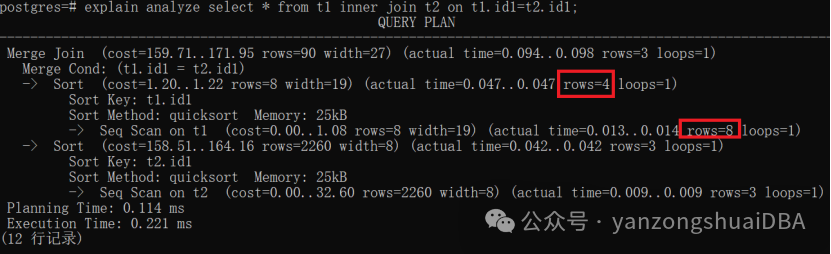
可以看到内表t1的SeqScan算子扫描出8行记录,而排序Sort算子仅4个,难道不是应该8个元组都进行排序吗?
那我们得重新理解下rows这个字段的意义了。
1、merge join的操作
具体状态机可以参考:PostgreSQL/GreenPlum Merge Inner Join解密
我们以文章开头的例子继续进行说明:
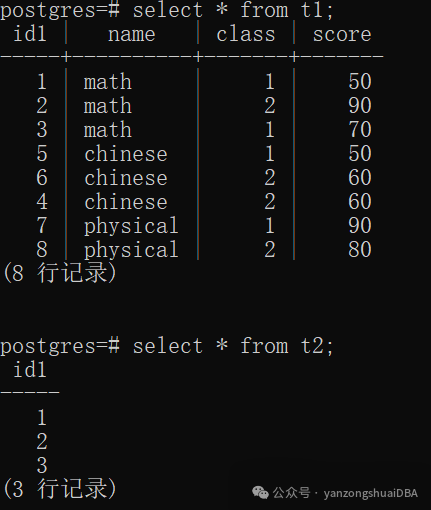
1)先取外表t2的1;然后取内表1进行join条件判断
2)两者相等,标记内表位置1
3)取内表下一个值2,并保存到mj_InnerTupleSlot中,外表值1和内表2进行比较:1 < 2
4)取外表下一个值2,和标记位置1进行比较,2 > 1,则继续和内表当前保存的mj_InnerTupleSlot值进行比较
5)两者相等,标记内表位置2
6)取内表下一个值3,并将其保存到mj_InnerTupleSlot;外表2和内表3比较:2 < 3
7)取外表下一个值3,和内表标记位置2比较:3 > 2,继续和内表保存值mj_InnerTupleSlot比较:3 = 3
8)继续取内表下一个值4。外表3和内表4比较:3 < 4
9)外表值取完,终止join
可以从流程中看到,从内表只取出了4个值。这个正好和rows字段值匹配。也就是从子节点拿多少数据,rows输出多大值。
我们从代码中查看下是否是这样。
2、rows统计
结构体Instrumentation中的tuplecount输出到explain analyze中进行展示:如下图所示
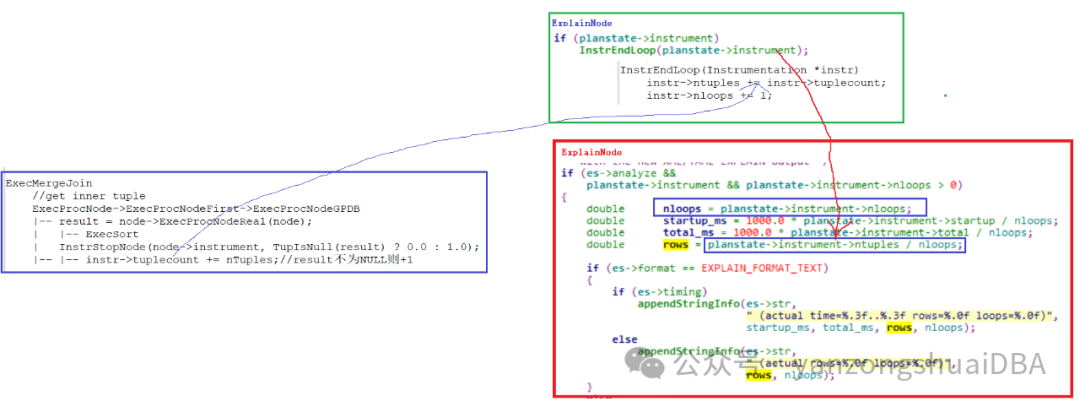
ExecMergeJoin每次从内表即Sort节点取一个数据,都会统计到Instr->tuplecount中。ExplainNode最终输出结果时,将Instr->tuplecount统计到instr->ntuples中。最终的rows值为ntuples/nloops,从执行计划中可以看到该算子仅进行了一次循环执行,即nloops为1。所以,可以这么理解:从Sort节点取出多少值,就会统计到rows中进行展示。
Rows的意义:子节点向父节点输出元组的个数,并不是子节点拥有的元组个数!