背景介绍
红杉资本2024 AI AGENT大会上吴恩达再次介绍了AI四大设计模式即:
- 反思(Reflection);
- 工具使用(Tool use);
- 规划(Planning);
- 多智能体协作(Multi-agent collaboration);
无独有偶,由于我于2023年年初就开始打造自己的AI AGENT,那时走的比较早特别是我和我的Studio以及相关的同仁们在做RAG时那时还是2023年的4月,那时还没有RAG这三个字。
其实,上述这4种设计模式看着云里雾里。实际,吴恩达是说到点子上了。真正拿AI AGENT去做商业落地的,势必会碰到上述4种模式充斥着你的AI-产品和项目实施过程中。
再说白点,上述4种模式是被“业务”需求逼出来的,不是什么技术名词或者“太学术”而是切切实实的在实际AI落地项目中正被广泛使用着。

特别是多智能体协作,我其实与2023年12月底时已经在产品中使用了并运用在了几个相关的“售前、售后”类业务中。至于其它3种设计模式我会在今后的篇章中逐一展开和讨论。
下面我们先来看多智能体协作设计模式是如何在我们的场景中使用和真正体现的。在我们应用在实际项目中时那时市面上还没有“多智能体”这一说,但已经有“AI Agent-Cooperation”的概念了如:AI小镇就是类似这么一个东西。
可能很多人还不知道有一个著名的:可由多个AI Agent虚拟数字员工组成的一个DevOps团体的项目,在这个产品里有:专司打包的AI、专司初始化数据的AI、专司部署的AI,每个AGENT各司其职,根据一个需求协作完成一次生产代码的发布。
所以我们在那时受启发也成功落地了我们的“多智能体协作”产品。
在上一篇博客《深度解读AI助力企业渡过经济寒冬以及如何落地AI的路径-CSDN博客》中我曾提到了现阶段企业要落地AI需要把焦点着重放在“实际应用、减少成本、提高生产力上,要准、快、省”。其实这个“多智能体”就是出于这个目的诞生的。
从设计模式上我们画成架构图它是长成这样的(我们当时画这个图其实诞生于2023年12月底,比后面市面上出现的AI Agent设计模式之多智能体协作早了4个多月时间)

多智能体协作的介绍
传统的数字化工作流已经为企业带来了效率的飞跃,而多智能体协作(Multiagent Collaboration)的崭新设计模式带给了我们一种全新的工作流范式。下面是对多智能体协作的一个简单介绍:
任务定义
无论是开发一个复杂的五子棋游戏,还是实现其他复杂任务,多智能体协作都能以其独特的方式提升任务执行的效率和准确性。这种模式下,不同的智能体可以根据其特长和能力,分担任务的不同部分,例如设计、编码、测试和文档编写等。
智能体分工
每个智能体都像是一个精密调校的工作机器,各司其职,共同协作。比如,有些智能体擅长解决复杂的算法问题,而另一些则更擅长在设计美学和用户体验之间找到平衡点。
协作执行
在多智能体协作模式下,各个智能体不仅仅是独自工作。它们之间能够实时交流和分享信息,通过反馈机制不断优化任务执行过程。这种方式不仅仅是提高了任务完成的速度,更是提升了整体准确性。
结果整合
最终,所有智能体完成的部分将被整合到一起,形成一个无懈可击的产品或服务。比如,我们可以看到一个功能完善、兼顾用户体验和技术实现的五子棋游戏应运而生。
优点
多智能体协作模式带来的好处不言而喻。通过有效的任务分工,它极大地提高了工作效率和准确性。每个智能体都在其专业领域发挥着最大的作用,从而加速了任务的处理速度。
分析
有了这么些优点但实际实施过程中是相当的复杂和艰难的,尤其是当你遇有一个真实的业务场景并且面临着真实的企业业务用户在使用时这么样的一个系统可不是几句话可以定义和讲得清的。让我们先来看一下我们的业务
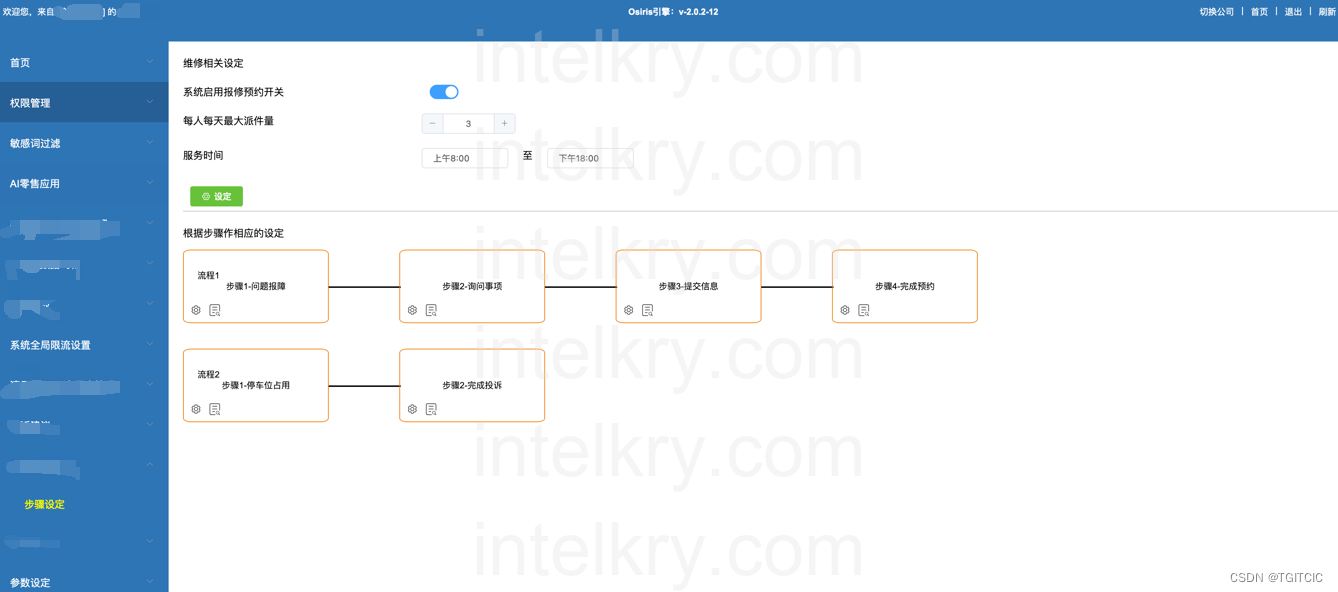
我们就拿我们第一条流程:上门维修予约派单流程来解说这个“多智能体协同”。根据我们的架构图我们已经可以得知,我们定义了4个AI Agent(这是我们开发的一个低代码的、可配置的多AI AGENT协同工作流),你可以认为这4个AI Agent就是4个“数字座席员工”。
平时里这些“员工”要做的事其实就是:
- 接报修电话;
- 问清客户修什么、是不是我的服务对象、客户的信息;
- 有时在这过程中还会有一些客户扯东、扯西,客服需要和他们多扯扯;
- 客户有时还要把自己的上门信息改来改去有时一个细小的差别没有问清客服人员还要陷入比较频繁的信息登记、改动、来回校对信息等繁杂的工作与事务;
- 当这些“基本”信息都收集到手后一般我们会打开系统中的“予约派工”子系统查询当前有无维修师傅可用,如果没有可用的维修师傅比如说一些“大物业”园区内的维修的水电工几乎是处于“连轴转”过程中,此时还要调用“呼叫系统呼叫外部第三方维修服务”来满足自身维修业务中的“派单”,总之这个环节是要费不少功夫;
- 然后把维修单发给客户,要求确认维修事宜、上门时间并告知上门的维修师傅的联系方式,在这一环节中客户还经常充满着:不要了、我突然想起来这个时间我没空。。。等等等诸如此类的事宜;
以上几个环节,每一个环节的时间加一起*客户人数,我们会发觉一个住宅小区的物业客服每天70%以上的时间直接会被蒸发在“报修登记/登录”这一件重复且无太高技术含量的事宜上。如果是一些“园区物业”或者是一些人多一些的小区,那么这一业务条线的客服人员光天天每小时接这种事可以忙到“连上WC的时间都没有”。
这个场景正是AI实展其身手的绝佳之处。
多智能体协作在实际项目实施过程中需要面临的挑战
看着挺激动人心,但是实际实施真心难度超大。
多智能体间的合作关系的考虑
所谓多智能体这并不是一个高大上的名词,它在业务流程环节多则可以定义4个真实的业务角色,少则也需要2个角色,说白了,这一条流程上至少得要有2个员工(如果让一个人干,这个人一天接的任务数不会超过10条就会崩溃)。
那么这两个员分工是很明确的。我们把一个人定义为“信息收集”另一个叫“任务分派”。
如果我们拿同一个AI对话场景来说我们知道有“上下文对话”,但是这个可是跨智能体间的“对话”啊,即第一个AI把自己的活交给下一个AI继续做下去。再说了白一点就是:当AI根据一个“肉人”的prompt产生出答案来把这个答案再交给AI作为下一个AI的输入,然后再下一个,再下一个直到整个流程结束。
这就需要我们自己动手去实现了一个“跨AI Agent”的上下文管理机制,各位可想而知光这一个课题我们做了些什么事。因为如果我们用同一个AI它的completion接口是自带上下文管理机制的也知道如何响应这个上下文。
而现在是多个AI AGENT即多个API Request间我们自己需要持久住这个上下文并且实现AI LLM那些原本有的上下文管理全功能还要能分清系统角色、用户历史会话、当前会话、长度。。。oh my god。
这一块真心把我们当时做吐血了。

用户敏感信息的考虑
这个点我在之前这个系列的几篇博客中都提到过,这条是红线,必须做好。那么问题来了,个人信息在给LLM前肯定全部要*(mask)掉的。当mask掉了后呢、再要把它在脱离LLM(LLM回答回来后)从本地系统以传统软件编程的方式还原回去。
其实这倒也不是太大的问题,问题在于:*掉后的信息是没事的,但是当碰到在客服工作流场景中流程流往下一节点时在交待上一节点的上下文中如果遇到了一堆的*掉的内容,LLM的判断、推理会变被“打得乱七八糟”。
但是“网络安全法”和“个人信息保护法”以及AIGC临时管理办法这几条“红线”是摆在那的,绝对不能逾越,那么此时怎么办?于是我们就想办法。。。想什么办法呢?
虚拟信息!
或者我再说了直白一些,给到LLM时首先在LLM每一个AI AGENT的角色上不断的调优其角色定义使之摆脱依赖于“具体”信息而仅凭“抽象”信息也可以对业务推理、流程决策准确,同时需要给每一次对话中的敏感个人信息做“脱敏后”虚拟占位处理。
其实很多人这边己经知道该如何干了,无非就是一个永远不会重复的分布式ID的问题,但是这个分布式ID还要自带一堆个人属性占位栏以便于LLM在回答时可以辩识出来当时“虚拟”给到LLM的哪个栏位是以下这些信息:

我还只列出来一小段实际有几十个字段,光这一块我们为了从长远的将来说简化我们的编程复杂程度,于是把它干脆做了一个“低代码”化的个人信息虚拟产生器,这个产生品可以在LLM把虚拟的信息如:
客户实际姓名:王小二虚拟后送给LLM为:
客户姓名:dfeaelmafh1018391在LLM返回后在服务器本地要把:dfeaelmafh1018391还原回王小二。

自动表单收集信息机制的考虑
之前几篇博客里我一直强调:AI光“炫”是没有用的,如果只是“炫”它只能够给人以“秀”而不能实际帮助我们的广大企业解决实际运营环节中的“尽最大可能减少无意义的、重复的劳动。从而彻底的提高企业的生产力”。
在设计这个多智能体协同时我们就遵守了这么一条原则:如果不可以100%的提高现有“人肉”运营环节中的效率,那么我们说它是一个智能体就是属于“吹牛”。
实际它带来的效率达到了300%+。
比如说我们把它实现成了:即可以满足用户手工填写式的也可以是场景会话式的“基本信息”收集工作。
对于传统的用户来说习惯于“表单”方式的填写。
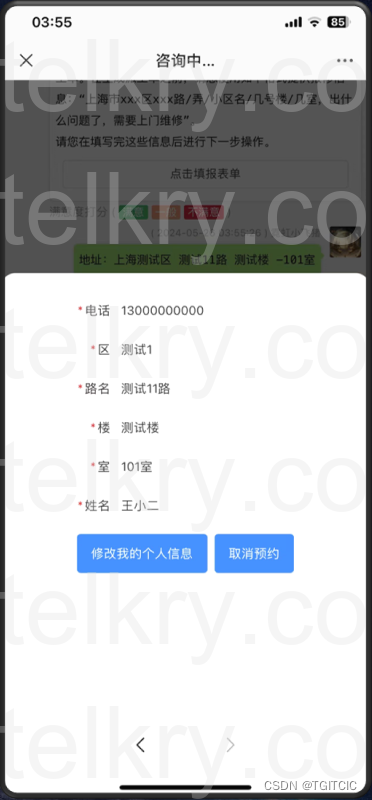
而对于一新较年青的用户特别是移动用户使用习惯,我们的智能体是直接可以在聊天过程中通过历史信息:
- 抓取用户的当前意图(传统数字化的点击动作);
- 抓取用户当前聊天中的只言片语来代填“表单的填写”动作(AI自动生成表单数据);


说到这各位就知道了,这里面其实诞生出两个子系统:
- 实体识别
- 语义识别

没错。。。界面看着其实一步操作、一句简单的会话就搞定了平时人工电话来来回回2、30分钟扯来扯去的事,其背后其实是需要使用到这些前沿技术的,这种技术的使用使得2023年前的数字化技术、企业级开发显得一下子“远古”了起来。这就是我们说的AI原生应用的特点即:一切需求、设计都围绕着AI来实现,没有了AI它就运作不起来。
我们真心是:太难了!
自动派单
到了这边,好家伙。。。其实我不用多说有经验的同学们就知道了,无论有没有AI这边上手需要对接企业派工或者是Ticket系统。
当然,在传统的工作流领域中我们的ticket系统为:发送相应的实时通知然后人工去手点或者倒过来操作步骤:先查看当前有无“空余的可以提供服务 的‘槽位’”,如果没有那么需要根据一个规则顺延如果有那么需要怎么办?
在这如果有经历过一个中等规模即“100个流程用户”规模的工作流系统的开发者们都知道,这种工作流不仅仅是一个简单的Workflow而叫BPMS,什么叫BPM。。。它里面是有Decision的。。。没错,即规则。
所以我们的应用由于使用的是AI NATIVE(AI原生应用)开发的,因此我们用AI重写了整个规则引擎。

这个就不展开了直接看效果。注意下图中“预约安排事宜”栏位
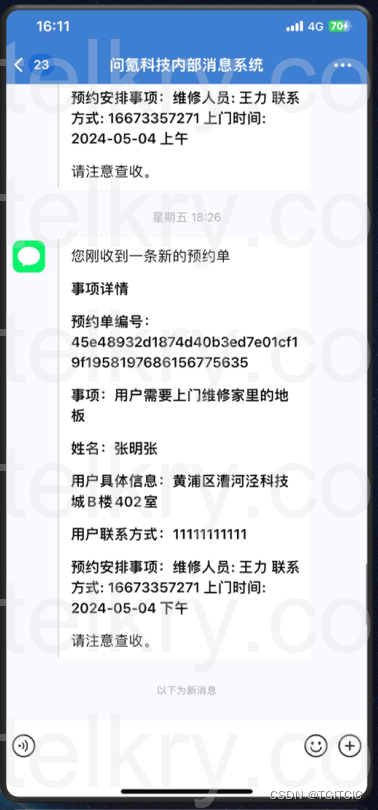
它其实是根据这么一些信息:
- 上门服务时间;
- 当前维修人员信息;
- 当前维修人员手上派单;
- 规则引擎中维修人员在什么样的情况下可以“被分派”规则;
动态再由LLM产生的。
而一旦LLM产生了这个信息,它直接解决了在传统数字化工作流甚至是BPMS场景中的“人肉”那一部分工作即:
- 打开维修人员系统;
- 在相应的系统中选择搜索条件;
- 查到相应的维修员工,给他“派件”;
这一步从原来的20-30分钟缩至:3秒钟。
因此内置AI原生的规则引擎和完善的AI Ticket模块很重要。
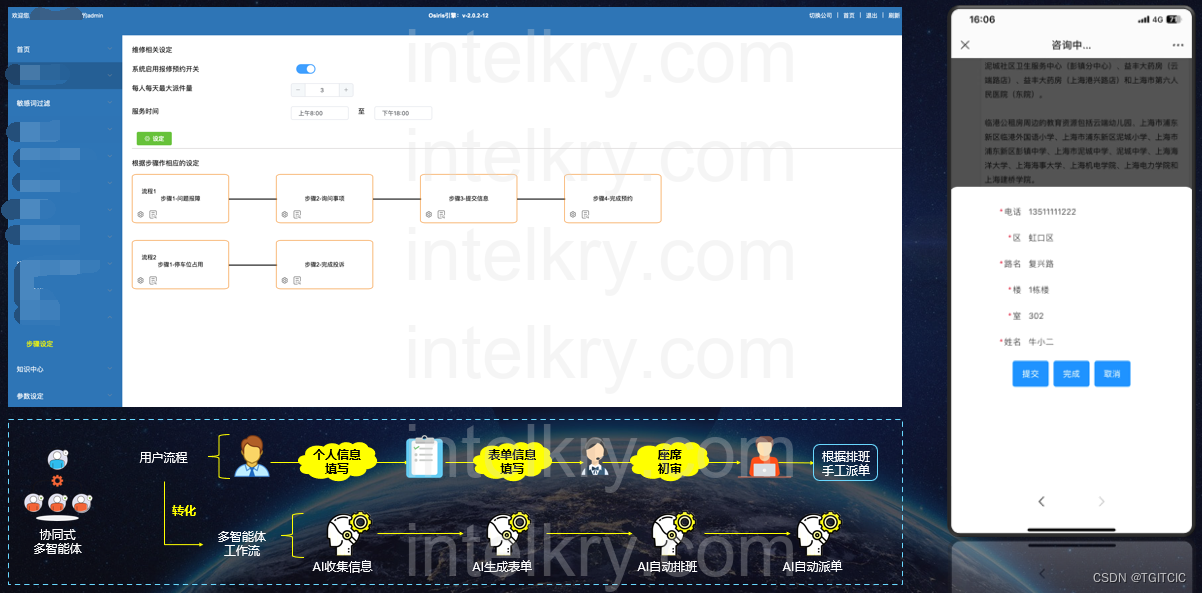
整体预约事宜的总结
我们注意看上面截图中这一部分

知道为什么我要把这一部分特别拿出来说吗?
那是因为在传统的数字化工作流场景中,我们最后在派单时有一个“派单事宜”,这个是“人肉”填上的。这是因为人的大脑是有强大的上下文记忆的,它可以总结、提练!
那么当一个用户经过 了7轮-8轮甚至扯来扯去的一些用户15轮-20轮会话最终:好吧,我确认,上门来修吧”时,那么现在没有“人肉”参与时这个派工单的填写过程了,因此在写“派单事宜”时该怎么写?
答案还是:利用LLM Agent,利用我们在“自定义跨AI Agent”的上下文系统内机制来“总结”这个“派单事宜”。
总结
回过头来我们再来看这个架构图(AI设计模式中的-多智体协同的图和我们这个图高度相似)。我们就可以理解什么叫“多智能体”以及“协同”二字了。
我记得我在2016年和2017年写过关于BPM系统和规则引擎相关的内容。我在那几篇博文中讲到过一种设计良好的数字化系统以及做这个系统的团队和运营这个系统间的配合应该是:
- 对于运营人员来说,流程修改方便,如果缺少运营的工具就向这个系统的制作人提出;
- 作为这个系统的制作人呢?只因该提供运营人员所缺少的工具和相应的“因子”(元素、积木)而不因该去触碰运营人员才应该涉及的“业务逻辑”;
- 而如何可以让一个技术团队真正做到这种“技术回归本质”的运作那么就要靠“工作流+规则引擎”;
其实,尽管现在到了AI时代这一概念依然还在盛行,只不过操作这个系统的人变成了“虚拟数据员工-AI AGENT”,而如何不断的扩展和把这些“员工”的动作、思维串联起来那么需要规则引擎。同时呢又因为现在处于了AI时代,因此原先的规则引擎由于有了AI的赋能显得越加强大了,这是因为它不仅仅能识别+-*/和左右树还能根据自然语言去识别了,因此才出现了这样的“超级智能体”。
这样的多智能体协同又称为“超级智能体”它不仅仅可以用在工作流场景,对于一些零售行为中的售后退单、促销规则、OA流、保险里的特别是一些如:车险、商业医保的“初筛”环节是完全可以代替人工并百分之几百的提高效率的。
比如说我们落地了几个这样的AI流程在许多企业内的生产线上正运作着我们的产品,经过实际的反馈通过一段时间的微调,这样的一个AI流程可以24小时不间断的工作,每一个环节的运算和流转不会超过5秒即可完成原先“人肉+数字化系统”才可以完成的一件事,它的生产力是惊人的、高效的!难怪人们也称这种系统为“超级智能体”。
好了,结束今天的博客。
在后面的博客里我会用我们实际落地的案例对于其它几个AI设计模式继续做逐一展开和深入介绍。同时也由此希望更多的企业去落地AI,只有越多的人群使用AI才能持续地发现AI原生应用的缺陷、发现了缺陷我们才能进一步去完善、去填洞这些缺陷。
当AI落地越多那么越来越多的企业和人群才能从中受益从而起到它对产业级的推动使之可以更好的赋能我们的企业和建设好我们的祖国。