随着电子商务的蓬勃发展,淘宝作为中国最大的在线购物平台之一,吸引了大量的消费者进行购物并留下了大量的客户评价。这些客户评价中包含了丰富的消费者意见和情感信息,对于商家改进产品、提升服务质量以及消费者决策都具有重要的参考价值。
然而,由于客户评价数据庞大且分散在网页中,手动分析和挖掘这些数据是一项艰巨而耗时的任务。因此,基于数据挖掘技术的研究与应用在淘宝客户评价方面变得越来越重要。
数据采集实现
3.1 数据采集主要方法和步骤
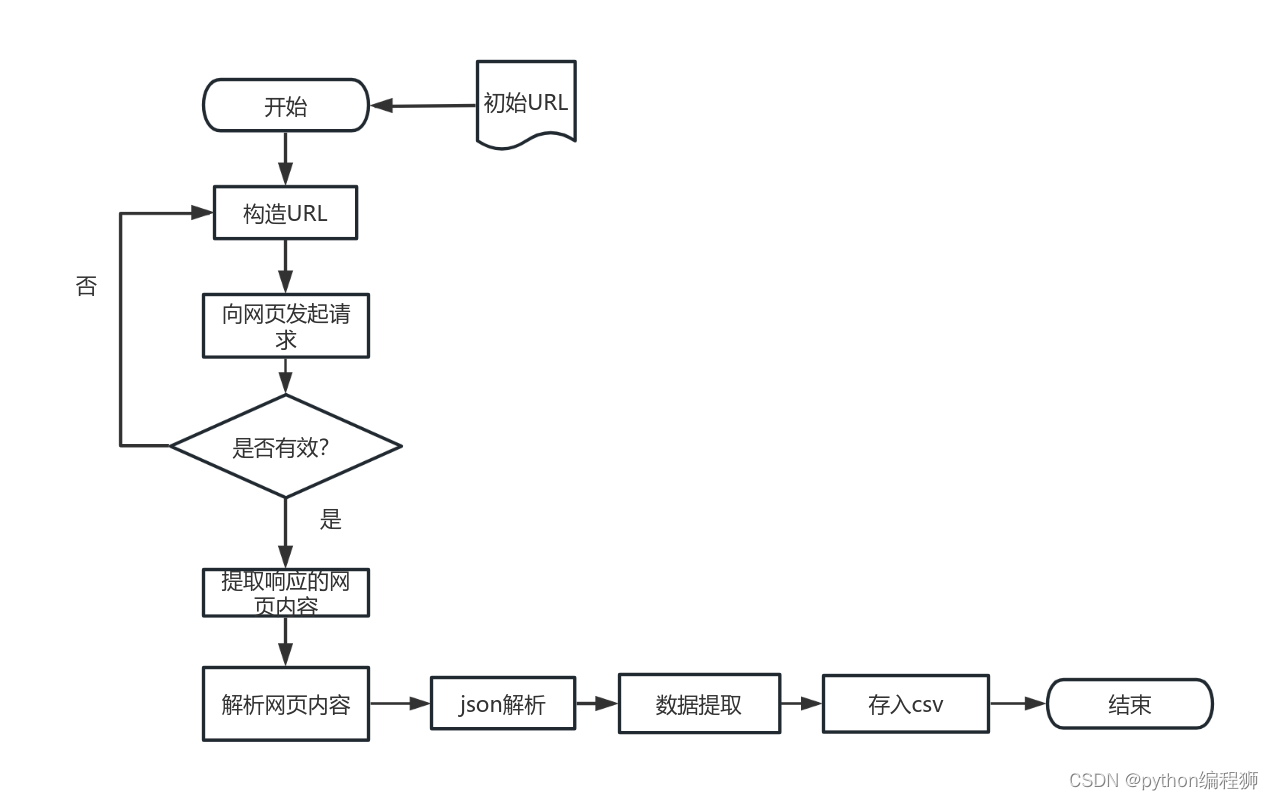
本次研究以采集淘宝登山装评论为例,采集登山装的评论信息,因为淘宝网页版限制采集,每一款商品只能采集3页,共采集100页评论。实现了通过Python的requests库进行网络爬虫,从淘宝网站获取商品评论数据,并将数据保存到CSV文件中的功能。通过逐条提取评论信息,实现了数据采集的自动化处理。具体流程如下:
首先,需要定义请求头信息,包括Cookie、Referer和User-Agent等,以模拟浏览器的请求。接下来,使用requests库的get方法发送HTTP请求,获取淘宝商品评论数据。将响应内容转换为文本格式,并通过解析响应的JSON数据,提取所需的评论信息;对于每条评论,可以进行循环处理。通过评论中的字段获取阅读数、喜欢数、购买时间、评论内容、款式、尺寸和用户名等相关信息。购买时间可以进行处理,转换为天数或月份。最后,整理提取到的信息,整理成一段话或进行进一步的分析和挖掘。这样的处理流程可以帮助你获取淘宝商品评论数据,并提取出核心信息,以便进行后续的研究和分析。在数据处理完成后,将每条评论的信息保存到CSV文件中,使用csv.writer将数据写入到指定的文件中。
数据清洗与预处理实现
4.1 清洗与预处理内容
处理的主要内容包括去除了评论中的空格,并通过分词、过滤停用词和过滤只包含数字/只包含中文字符的词语的方式对评论数据进行了清洗处理。
4.2 清洗与预处理操作
4.2.1 去除空格
去除评论中的空格可以提高文本处理的准确性和效率。空格在文本处理中通常被视为无用字符,对于文本分词、情感分析、关键词提取等任务而言,空格可能会干扰算法的正确性。清洗后的评论数据可以更好地用于文本分析和挖掘。去除空格后的评论数据可以更准确地统计词频、生成词云图、进行情感分析等,从而更好地了解用户的意见、倾向和行为。清洗后的评论数据也有助于提升可视化结果的质量。去除空格后的评论数据能够更好地展示购买时间分布直方图、阅读数和喜欢数的散点图、尺寸占比饼图等可视化结果,使得数据分析更直观和易懂。
4.2.2 过滤评论内容
提取出评论内容中的有意义的关键词,去除掉一些无关紧要的词语,从而更好地理解和分析评论的主要内容。使用jieba和停用词过滤评论内容可以提高文本可读性、降低噪音干扰、提取关键信息和优化搜索引擎等方面的作用,有助于更好地理解和分析评论内容。首先分词处理:将评论内容进行分词处理,使用jieba库的分词函数jieba.cut()对评论文本进行分词,生成分词列表。
然后去除停用词:根据停用词表,将分词列表中的停用词去除,只保留有意义的关键词。可以使用循环遍历分词列表,并判断是否为停用词,若是则从列表中移除。
最好整理过滤后的评论内容:将经过分词和去除停用词处理后的关键词列表重新组合成字符串形式,表示过滤后的评论内容。

数据分析和可视化
首先,对停用词进行处理,整合停用词库文件并计算整合后的停用词数量,然后将整合后的停用词保存到文件中。接着,使用jieba对评论数据进行分词处理,同时过滤停用词、纯数字和纯中文字符的词语。进行词频统计并生成词云图,展示高频词汇,帮助了解评论数据的关键内容。利用SnowNLP进行情感分析,将情感分析结果加入DataFrame中,并绘制柱状图和饼图展示不同情感类别的数量占比。对数据分布进行可视化,绘制购买时间分布直方图、阅读数和喜欢数的散点图,以及登山装尺寸占比的饼图。进行TF-IDF转换和聚类分析,使用TfidfVectorizer将清洗后的评论数据进行TF-IDF转换,然后通过KMeans算法寻找最优的聚类数,并绘制聚类数与silhouette score的折线图。进行LDA主题建模和可视化,利用LatentDirichletAllocation进行LDA主题建模,并使用pyLDAvis进行可视化,在最后打印每个主题的关键词和数量。这一系列处理可以帮助分析评论数据,并从不同角度展示数据特征和情感倾向,为深入理解评论内容提供支持。
5.2 评论词频分析
评论词频分析是一种常用的文本分析技术,通过对大量评论数据进行处理和统计,可以帮助我们了解用户对某个产品或服务的评价和观点。首先,我们需要导入必要的库,并读取保存评论数据的CSV文件。然后,对数据进行清洗,去除不需要的字符和空格。接下来,使用分词工具对每条评论进行分词处理,将其拆分为一个个单词。为了提高分析的准确性,我们还需要去除停用词,这些停用词通常是一些无意义的常用词语。之后,通过统计每个词语的出现次数,得到词频字典。为了更直观地展示词频信息,我们可以创建词云图。词云图根据词频大小,将词语以不同的字体大小呈现,从而突出显示出现频率较高的词语。最后,我们可以使用matplotlib.pyplot库中的函数将词云图显示出来。通过这些步骤,我们可以对评论数据进行全面的词频分析,了解用户对某个产品的关注点、喜好和意见。这种分析方法在市场调研、品牌管理和产品改进等方面具有广泛的应用价值。通过对评论数据的深入分析,企业可以更好地了解用户需求,提升产品质量和服务水平,从而提高竞争力和用户满意度。词频分析词云图如图5.1所示。

图5.1 词频词云图
词频分析结果,可以得出以下结论:
一些表示衣物的关键词如“穿”、“上身”、“衣服”、“尺码”、“面料”和“质量”等出现频率较高,说明用户在评论中比较关注这些方面。
“效果”、“买”和“推荐”等词也出现频率较高,说明用户对购买的产品效果满意并愿意推荐给他人。
用户普遍认为产品“不错”、“好看”、“合适”、“喜欢”和“满意”,这些词频较高,表明用户对产品的整体评价较高。
用户对产品的功能特性也有关注,如“防水”、“保暖”、“防风”等词频较高,说明用户对产品的性能表现有所期待。
一些词频较低的词如“价格”、“物流”、“服务”等,用户对这些方面的评价相对较少,但仍然能够看到一些用户对于价格、物流和服务方面的提及。
根据词频分析结果,大部分用户对该产品的质量、效果、外观以及性能等方面持积极评价,并愿意推荐给他人。
评论情感分析
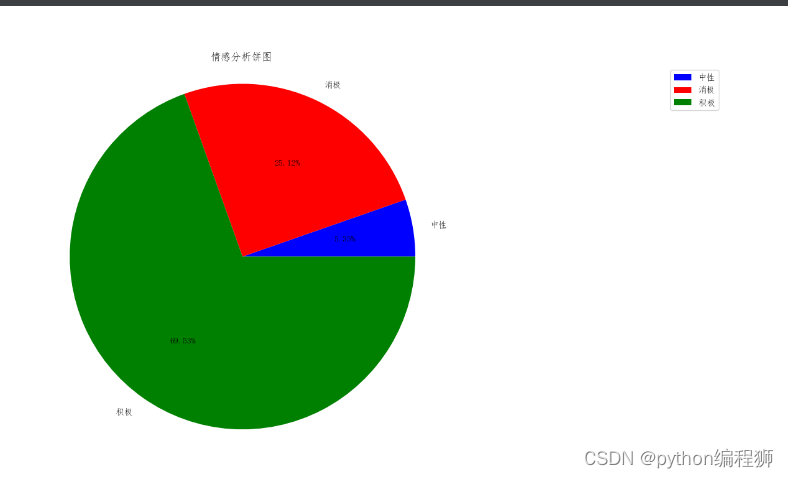
情感分析是通过对文本进行处理和分析,来判断其中所表达的情感倾向。首先使用SnowNLP库对评论数据进行情感分析,获取每条评论的情感分数。根据分数的高低,将评论划分为积极、中性和消极三种情感类别。遍历了DataFrame对象中的每一行评论,利用SnowNLP库计算每条评论的情感分数,并根据分数的范围将其分类为积极、中性或消极。最后,将分类结果存储在名为'情感分析'的新列中。
最后实现了基本的情感分析功能,可以帮助用户了解评论数据中的情感倾向,并进一步分析用户对产品的态度和满意度。通过对不同情感类别的评论数量进行统计和可视化,可以更直观地了解用户对产品的整体评价。
聚类分析
设定了最大的聚类数max_clusters,并初始化了最佳得分best_score和最佳聚类数best_clusters。然后,通过循环遍历不同的聚类数clusters,从2到max_clusters + 1。
在每次循环中,利用KMeans算法进行聚类,其中设置聚类数为当前的clusters值,并利用fit方法拟合数据。然后,根据拟合后的结果,使用labels_属性获取每个样本点所属的聚类标签。
接下来,利用silhouette_score函数计算tfidf_matrix和聚类标签之间的轮廓系数silhouette_avg。如果silhouette_avg的值高于best_score,则将其更新为最新的最佳得分,并将best_clusters设定为当前的聚类数clusters。
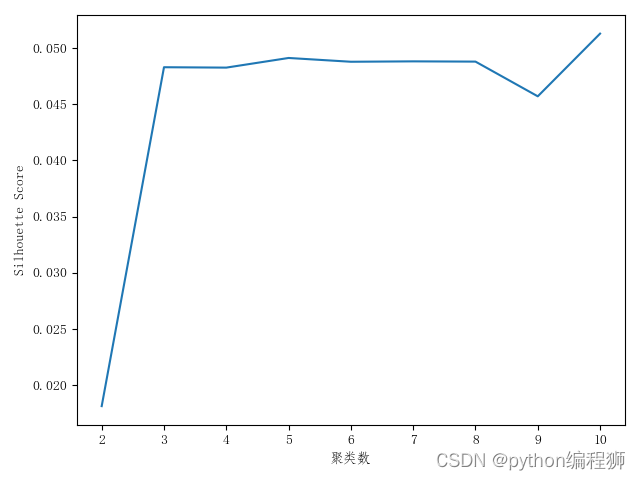
最后,通过绘制折线图,展示聚类数与silhouette score之间的关系。折线图可以帮助我们确定最佳的聚类数,即silhouette score最高的聚类数。
通过这种方式,我们可以利用KMeans算法对给定的数据进行聚类分析,将相似的样本点划分到同一个聚类中。聚类分析有助于发现数据内部的模式和结构,帮助我们理解数据集的特征和组织形式,为进一步的数据分析和应用提供指导。聚类分析如图5.6所示,最优聚类数是4或者9。
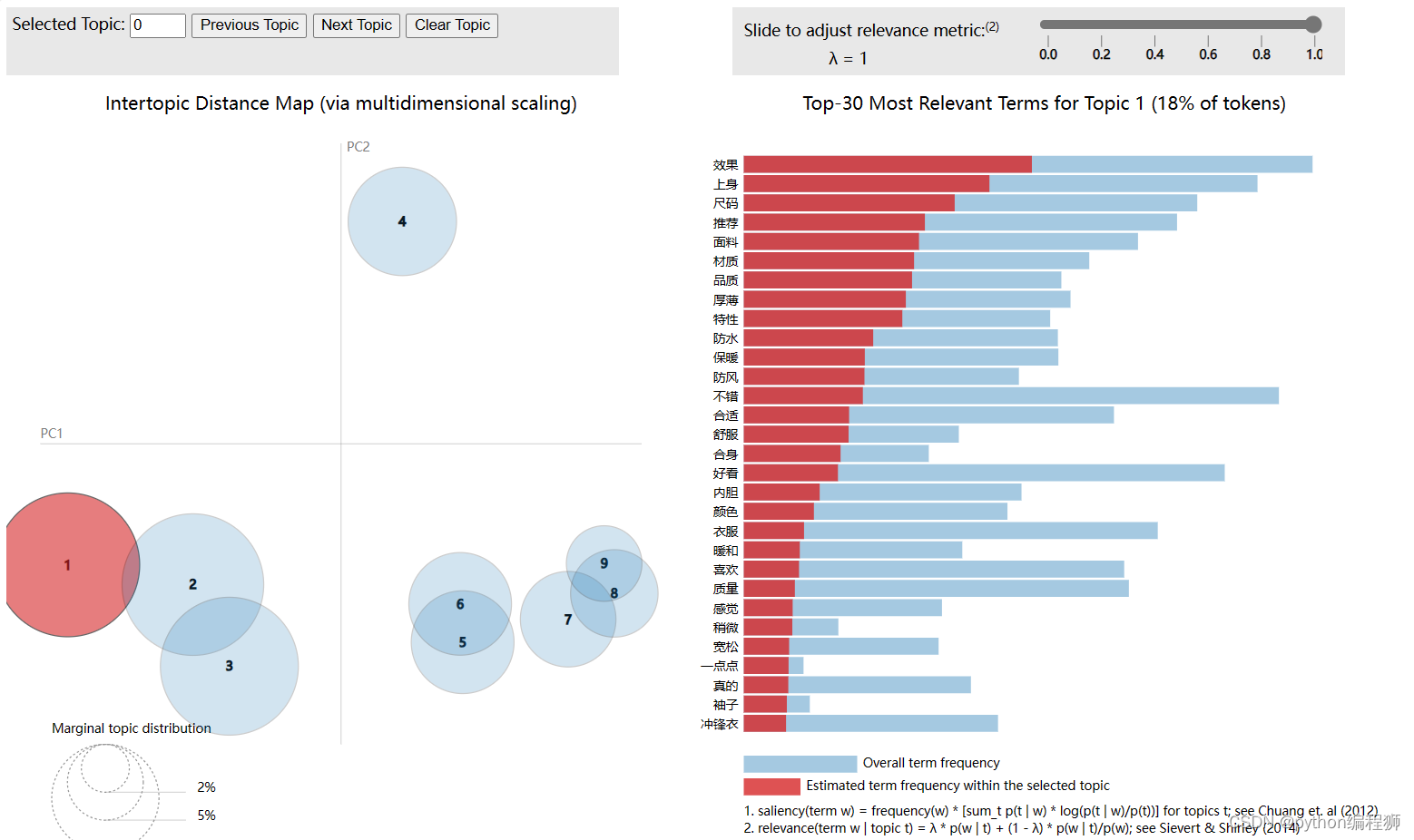
LDA主题建模与可视化
LDA(Latent Dirichlet Allocation)主题建模和可视化是通过使用sklearn库和pyLDAvis库来实现的。首先指定了主题的数量num_topics,即我们希望从数据中提取的主题数目。然后,使用LatentDirichletAllocation类初始化一个LDA对象,并将num_topics作为参数传递进去。接下来,使用fit方法对tfidf_matrix进行拟合,其中tfidf_matrix是通过TfidfVectorizer类将评论数据转换为TF-IDF矩阵得到的。拟合过程会根据LDA模型的设定,对每个文档分配主题,并学习每个主题的词语分布。随后,使用pyLDAvis库的prepare函数,将LDA模型、TF-IDF矩阵和vectorizer作为参数传递进去,生成一个包含主题-关键词分布的可视化对象。最后,通过save_html函数将可视化对象保存为HTML文件,以便于在浏览器中打开查看。
LDA主题建模和可视化的目的是揭示文本数据背后潜在的主题结构。LDA模型通过对文档中词语的频率和共现关系进行建模,将文本数据划分为不同的主题,并计算每个主题与词语之间的关联度。
通过pyLDAvis库生成的可视化结果展示了主题-关键词矩阵和主题之间的相关性。在可视化图表中,可以看到不同主题的词语云图、主题之间的距离和重叠程度等信息,帮助我们更好地理解主题之间的内在联系。
这种LDA主题建模和可视化的方法为文本数据提供了一种深入分析和理解的手段。它可以应用于各种文本领域,如社交媒体分析、舆情监测、主题检索等,帮助我们挖掘文本数据中的有价值信息,并为决策和研究提供支持。LDA主题分析结果如图5.7所示。