Ollama:一个在本地部署、运行大型语言模型的工具
- Ollama部署、运行大型语言模型
- 概述
- 安装
- 配置
- Ollama命令
- 模型库
- 使用示例
- 自定义模型
- 从GGUF导入
- 自定义提示
- 从PyTorch或Safetensors导入
- 开启服务
- REST API
- 卸载Ollama
- One-API
- 概述
- One-API管理本地模型
- Open WebUI
- 概述
- Docker部署
- Open WebUI配置
Ollama部署、运行大型语言模型
概述
Ollama是一个专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计的工具。
官方网站:https://ollama.com/
Github:https://github.com/ollama/ollama
安装
Ollama支持macOS、Linux和Windows多个平台运行
macOS:下载Ollama
Windows:下载Ollama
Docker:可在Docker Hub上找到Ollama Docker镜像
Linux:因为使用服务器,这里便以Linux操作系统使用为例记录说明
其中Linux通过命令直接安装如下:
root@master:~/work# curl -fsSL https://ollama.com/install.sh | sh
>>> Downloading ollama...
######################################################################## 100.0%##O#-#
>>> Installing ollama to /usr/local/bin...
>>> Creating ollama user...
>>> Adding ollama user to render group...
>>> Adding ollama user to video group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
>>> Enabling and starting ollama service...
Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service.
>>> NVIDIA GPU installed.
查看ollama的状态
root@master:~/work# systemctl status ollama
● ollama.service - Ollama Service
Loaded: loaded (/etc/systemd/system/ollama.service; enabled; vendor preset: enabled)
Active: active (running) since Thu 2024-05-16 07:48:52 UTC; 19s ago
Main PID: 1463063 (ollama)
Tasks: 19 (limit: 120679)
Memory: 488.7M
CPU: 6.848s
CGroup: /system.slice/ollama.service
└─1463063 /usr/local/bin/ollama serve
May 16 07:48:52 master ollama[1463063]: Couldn't find '/usr/share/ollama/.ollama/id_ed25519'. Generating new private key.
May 16 07:48:52 master ollama[1463063]: Your new public key is:
May 16 07:48:52 master ollama[1463063]: ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIKkP+MSQgroycM4iPUhDAUW02qwhEIB4vtANecwzN3En
安装成功后执行ollama -v命令,查看版本信息,如果可以显示则代表已经安装好
root@master:~# ollama -v
ollama version is 0.1.38
配置
编辑
vim /etc/systemd/system/ollama.service文件来对ollama进行配置
1.更改HOST
由于Ollama的默认参数配置,启动时设置了仅本地访问,因此需要对HOST进行配置,开启监听任何来源IP
[Service]
# 配置远程访问
Environment="OLLAMA_HOST=0.0.0.0"
2.更改模型存储路径
默认情况下,不同操作系统大模型存储的路径如下:
macOS: ~/.ollama/models
Linux: /usr/share/ollama/.ollama/models
Windows: C:\Users.ollama\models
官方提供设置环境变量OLLAMA_MODELS来更改模型文件的存储路径
[Service]
# 配置OLLAMA的模型存放路径
Environment="OLLAMA_MODELS=/data/ollama/models"
注意:
由于当时使用root账号,同时目录权限也属于root,配置好后导致服务无法正常启动
此时,可以查看Ollama的运行日志,特别是在遇到问题需要调试时,可以使用以下命令:
journalctl -u ollama
解决问题:
因为指定的目录ollama用户及用户组没有相应权限,导致服务不能启动。通过授权给相应的目录权限解决问题。
chown ollama:ollama ollama/models
3.更改运行GPU
配置环境变量CUDA_VISIBLE_DEVICES来指定运行Ollama的GPU,默认不需要改动,适用于多卡环境。
Environment="CUDA_VISIBLE_DEVICES=0,1"
4.应用配置
重载systemd并重启Ollama
systemctl daemon-reload
systemctl restart ollama
5.访问测试
浏览器访问http://IP:11434/,出现Ollama is running代表成功。

Ollama命令
Shell窗口输入ollama,打印ollama相关命令说明
root@master:~/work# ollama
Usage:
ollama [flags]
ollama [command]
Available Commands:
serve Start ollama
create Create a model from a Modelfile
show Show information for a model
run Run a model
pull Pull a model from a registry
push Push a model to a registry
list List models
ps List running models
cp Copy a model
rm Remove a model
help Help about any command
Flags:
-h, --help help for ollama
-v, --version Show version information
Use "ollama [command] --help" for more information about a command.
ollama的操作命令跟docker操作命令非常相似
ollama serve # 启动ollama
ollama create # 从模型文件创建模型
ollama show # 显示模型信息
ollama run # 运行模型
ollama pull # 从注册仓库中拉取模型
ollama push # 将模型推送到注册仓库
ollama list # 列出已下载模型
ollama cp # 复制模型
ollama rm # 删除模型
ollama help # 获取有关任何命令的帮助信息
模型库
Ollama的Library,类似Docker的Docker Hub,在这里可以查找受Ollama支持的大模型。

以下是一些可以下载的示例模型:
注意:Ollama支持8 GB的RAM可用于运行7B型号,16 GB可用于运行13B型号,32 GB可用于运行33B型号。当然这些模型是经过量化过的。

使用示例
下载llama3-8b模型
root@master:~# ollama pull llama3:8b
pulling manifest
pulling 00e1317cbf74... 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 4.7 GB
pulling 4fa551d4f938... 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 12 KB
pulling 8ab4849b038c... 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 254 B
pulling 577073ffcc6c... 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 110 B
pulling ad1518640c43... 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 483 B
verifying sha256 digest
writing manifest
removing any unused layers
success
下载成功查看模型
root@master:~# ollama list
NAME ID SIZE MODIFIED
llama3:8b a6990ed6be41 4.7 GB 3 minutes ago
运行模型并进行对话
root@master:~# ollama run llama3:8b
>>> hi
Hi! How's your day going so far? I'm here to chat and help with any questions or topics you'd like to discuss. What's on your mind?
>>> Send a message (/? for help)
自定义模型
所谓自定义模型就是不适用Ollama官方模型库中的模型,理论可以使用其他各类经过转换处理的模型
从GGUF导入
Ollama支持在Modelfile文件中导入GGUF模型
创建一个名为 Modelfile的文件,其中包含一条FROM指令,其中包含要导入的模型的本地文件路径。
FROM ./Llama3-FP16.gguf
在Ollama中创建模型
ollama create llama3 -f Modelfile
运行模型
ollama run llama3
完整执行日志如下:
root@master:~/work# touch Modelfile
root@master:~/work# mv /root/work/jupyterlab/models/Llama3-FP16.gguf ./
root@master:~/work# ollama create llama3 -f Modelfile
transferring model data
using existing layer sha256:547c95542e3fa5cc232295ea3cbd49fc14b4f4489ca9b465617076c1f55d4526
creating new layer sha256:81834e074ec2a24086bdbf16c3ba70eb185f5883cde6495e95f5141e4d325456
writing manifest
success
root@master:~/work# ollama run llama3
>>> Send a message (/? for help)
自定义提示
Ollama库中的模型可以通过提示进行自定义。
FROM llama3
# 设置温度参数
PARAMETER temperature 1
# 设置SYSTEM 消息
SYSTEM """
作为AI智能助手,你将竭尽所能为员工提供严谨和有帮助的答复。
"""
更多参数说明参考:Modelfile文档
从PyTorch或Safetensors导入
所谓从从PyTorch或Safetensors导入Ollama,其实就是使用
llama.cpp项目,对PyTorch或Safetensors类型的模型进
行转换、量化处理成GGUF格式的模型,然后再用Ollama加载使用 。
上述从GGUF导入使用的模型:Llama3-FP16.gguf便是经过llama.cpp项目处理得到的。
llama.cpp的使用参考:使用llama.cpp实现LLM大模型的格式转换、量化、推理、部署
官方文档参考:导入模型指南
开启服务
运行模型后,执行
ollama serve命令启动Ollama服务,然后就可以通过API形式进行模型调用
ollama serve会自动启动一个http服务,可以通过http请求模型服务
首次启动会自动生成ssh私钥文件,同时打印公钥内容。
root@master:/usr/local/docker# ollama serve
Couldn't find '/root/.ollama/id_ed25519'. Generating new private key.
Your new public key is:
ssh-ed25519 AAAAC3NzaC1lZDI1NTE5ssssssxxxxxxxxxxjx3diFB3a5deoGLnT7gHXxjA6R
2024/05/16 09:27:27 routes.go:1008: INFO server config env="map[OLLAMA_DEBUG:false OLLAMA_LLM_LIBRARY: OLLAMA_MAX_LOADED_MODELS:1 OLLAMA_MAX_QUEUE:512 OLLAMA_MAX_VRAM:0 OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:1 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:*] OLLAMA_RUNNERS_DIR: OLLAMA_TMPDIR:]"
time=2024-05-16T09:27:27.635Z level=INFO source=images.go:704 msg="total blobs: 0"
time=2024-05-16T09:27:27.635Z level=INFO source=images.go:711 msg="total unused blobs removed: 0"
time=2024-05-16T09:27:27.635Z level=INFO source=routes.go:1054 msg="Listening on 127.0.0.1:11434 (version 0.1.38)"
time=2024-05-16T09:27:27.635Z level=INFO source=payload.go:30 msg="extracting embedded files" dir=/tmp/ollama4098813456/runners
time=2024-05-16T09:27:31.242Z level=INFO source=payload.go:44 msg="Dynamic LLM libraries [cpu cpu_avx cpu_avx2 cuda_v11 rocm_v60002]"
time=2024-05-16T09:27:31.401Z level=INFO source=types.go:71 msg="inference compute" id=GPU-4c974b93-cf0c-486e-9e6c-8f91bc02743c library=cuda compute=7.0 driver=12.2 name="Tesla V100S-PCIE-32GB" total="31.7 GiB" available="16.5 GiB"

REST API
更多、具体API,请参阅 API文档
1.生成回复
curl http://IP:11434/api/chat -d '{
"model": "llama3:8b",
"messages": [
{ "role": "user", "content": "你好啊" }
]
}'
请求参数示例:
{
"model": "llama3",
"prompt": "你好啊",
"stream": false
}
2.与模型聊天
curl http://IP:11434/api/chat -d '{
"model": "llama3",
"messages": [
{ "role": "user", "content": "你好啊" }
]
}'
请求参数示例:
{
"model": "llama3",
"messages": [
{
"role": "system",
"content": "你是一个乐于助人的AI助手。"
},
{
"role": "user",
"content": "你好啊"
}
],
"stream": false
}
卸载Ollama
停止并禁用服务
systemctl stop ollama
systemctl disable ollama
删除服务文件和Ollama二进制文件
rm /etc/systemd/system/ollama.service
rm $(which ollama)
清理Ollama用户和组
rm -r /usr/share/ollama
userdel ollama
groupdel ollama
One-API
概述
One-API是一个OpenAI接口管理 & 分发系统,支持各类大模型。这里使用Docker快速进行部署。
GitHub:https://github.com/songquanpeng/one-api
拉取镜像
docker pull justsong/one-api
创建挂载目录
mkdir -p /usr/local/docker/oneapi
启动容器
docker run --name one-api -d --restart always -p 3001:3000 -e TZ=Asia/Shanghai -v /usr/local/docker/oneapi:/data justsong/one-api
访问IP:3001
初始账号用户名为 root,密码为 123456

One-API管理本地模型
在创建渠道时选择Ollama,然后手工填上自己要使用的模型,密钥任意,最重要的是后面在代理中写上自己ollama服务的地址即可

测试成功后,在各类OpenAI套壳软件中,通过配置类似于OpenAI的密钥、API地址等参数,就可以象使用OpenAI一样。

Open WebUI
概述
Open WebUI 是一个可扩展、功能丰富且用户友好的自托管 WebUI,旨在完全离线操作。它支持各种 LLM 运行程序,包括 Ollama 和 OpenAI 兼容的 API。
GitHub:https://github.com/open-webui/open-webui
Open WebUI:https://docs.openwebui.com/
Open WebUI社区: https://openwebui.com/
Docker部署
使用Docker快速安装部署Open WebUI,需要注意:确保在Docker命令中包含
-v open-webui:/app/backend/data。因为它确保数据库正确安装并防止任何数据丢失。
使用Docker进行Open WebUI安装部署,根据场景不同,可分为以下几类:
1.默认配置安装,如果计算机上有Ollama,请使用以下命令:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
docker run -d -p 3000:8080 -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
2.Ollama位于不同的服务器上,连接到另一台服务器上的 Ollama,请将OLLAMA_BASE_URL更改为服务器的URL:
docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=https://example.com -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
3.要运行支持Nvidia GPU的Open WebUI,请使用以下命令:
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda
4.安装带有捆绑Ollama支持的Open WebUI
使用GPU支持:通过运行以下命令来利用GPU资源:
docker run -d -p 3000:8080 --gpus=all -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollama
仅适用于CPU:如果不使用GPU,请改用以下命令:
docker run -d -p 3000:8080 -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollama
Open WebUI配置
访问http://IP:3000,创建一个账号(管理员)

进入Open WebUI后,界面如下。在Settings中进行相关设置。
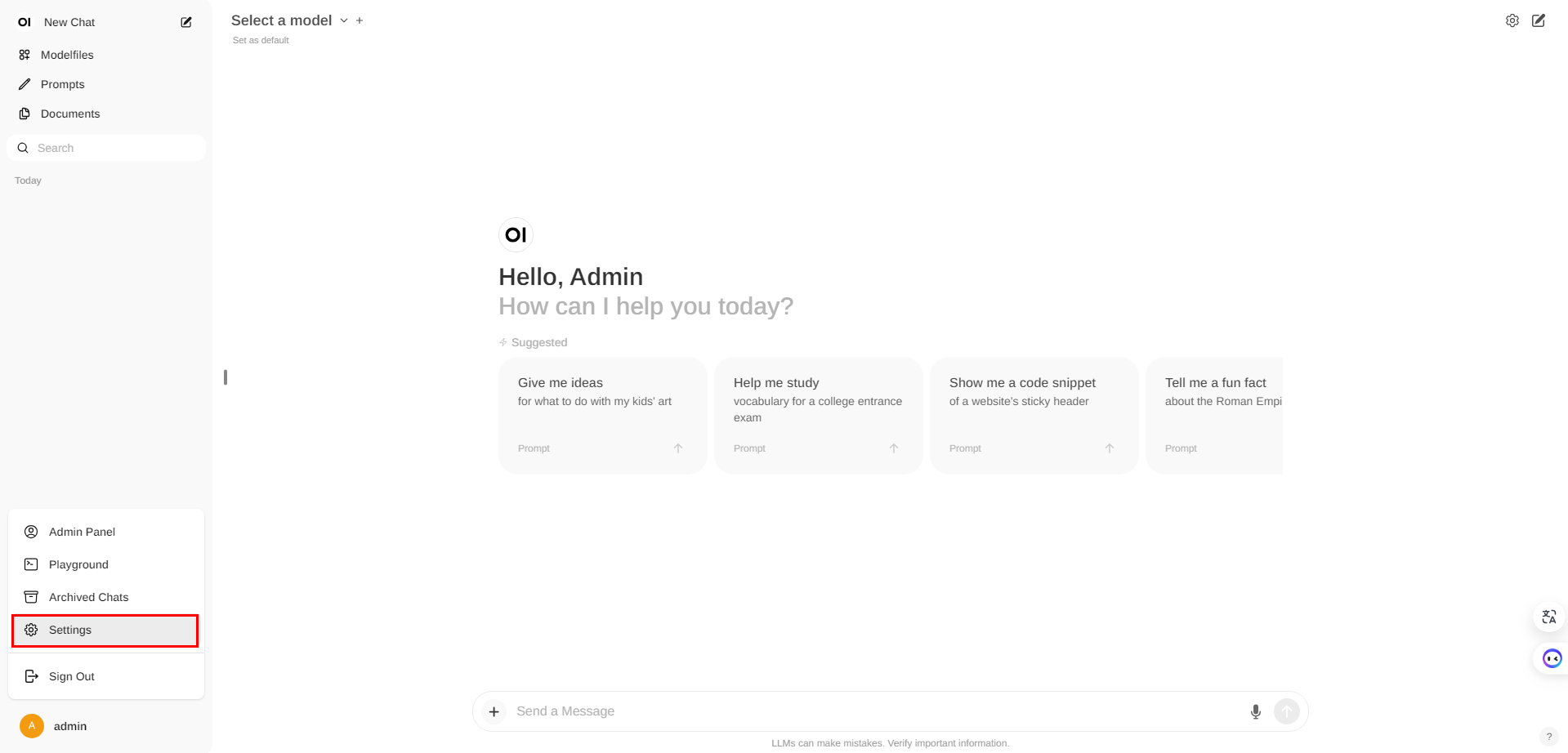
设置语言
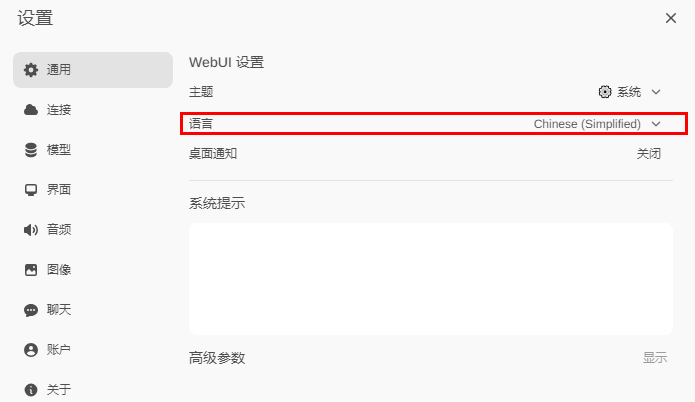
设置Ollama的访问地址

选择模型,开始聊天。