欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
文章目录
- 一项目简介
- 二、功能
- 三、系统
- 四. 总结
一项目简介
一、项目背景与意义
在当今数字化时代,用户生成内容(UGC)如在线评论、社交媒体帖子和博客文章等呈现爆炸性增长。这些评论中包含了大量的情感信息,对于企业和个人来说,理解和分析这些情感倾向对于改进产品、服务或营销策略至关重要。因此,开发一个基于Python的情感分析可视化项目,可以帮助用户快速、直观地了解大量评论中的情感倾向,具有重要的实际应用价值。
二、项目目标
本项目旨在利用Python编程语言和相关库,对收集到的评论进行情感分析,并将分析结果以可视化的形式呈现给用户。具体目标包括:
收集并预处理评论数据,包括去除噪声、分词、去除停用词等步骤。
构建情感分析模型,对预处理后的评论进行情感倾向判断,并给出相应的情感分数或标签(如正面、负面、中性)。
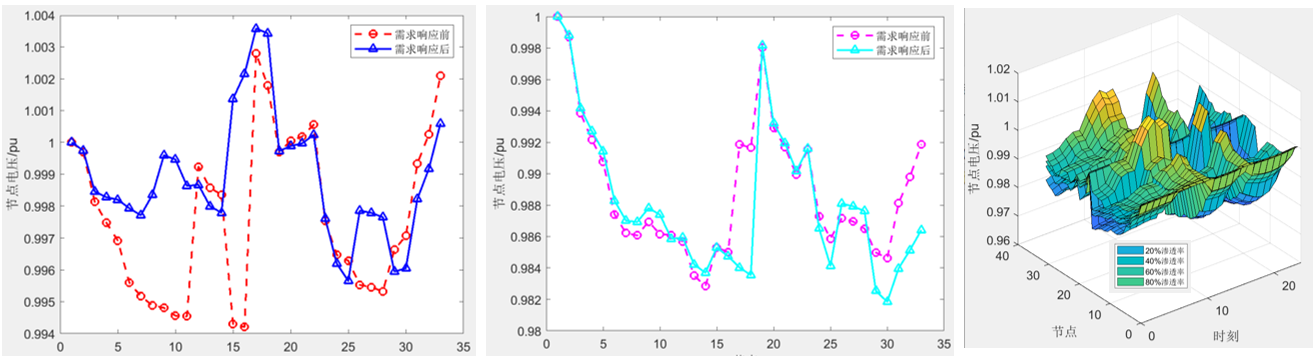
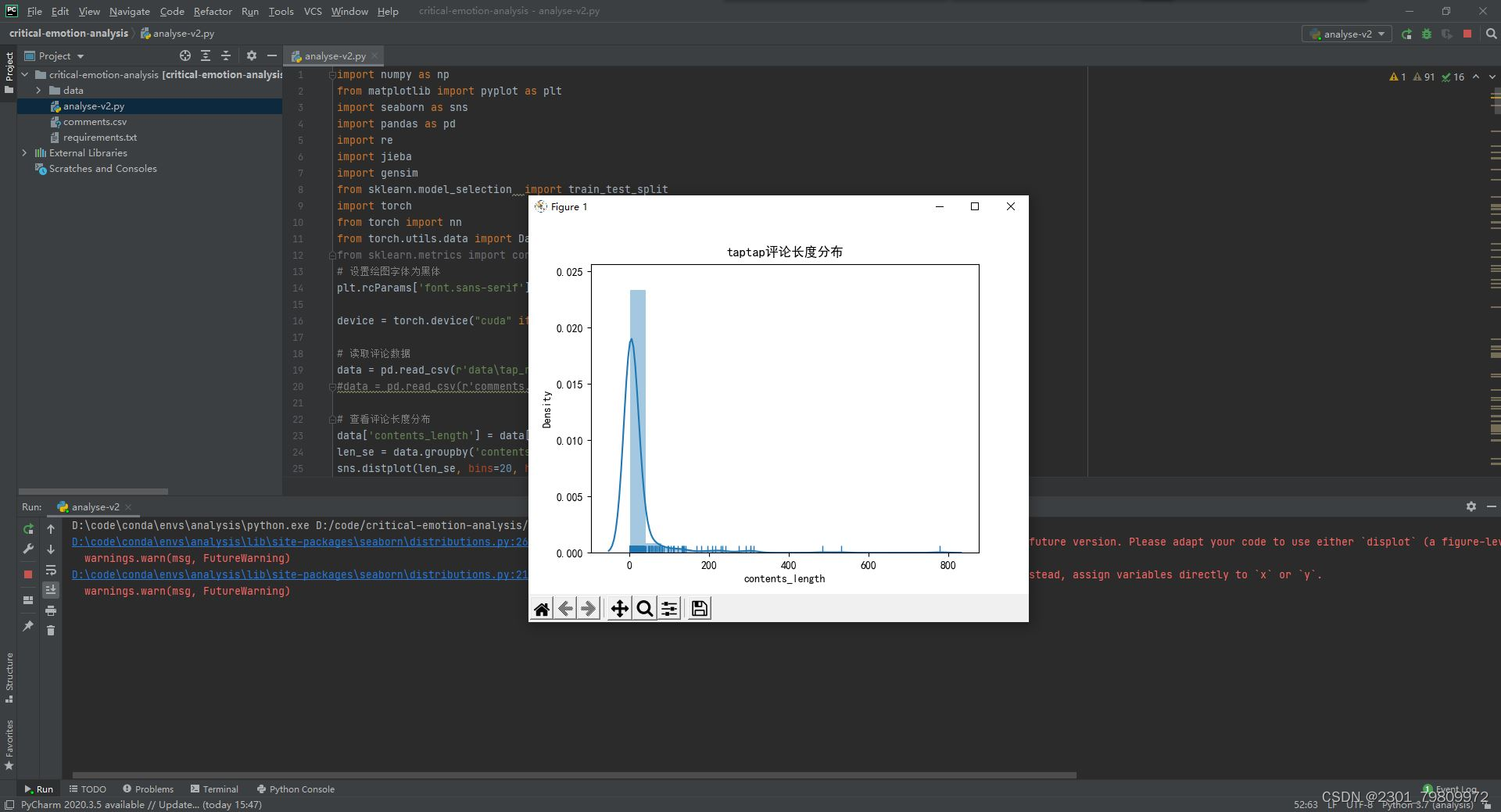
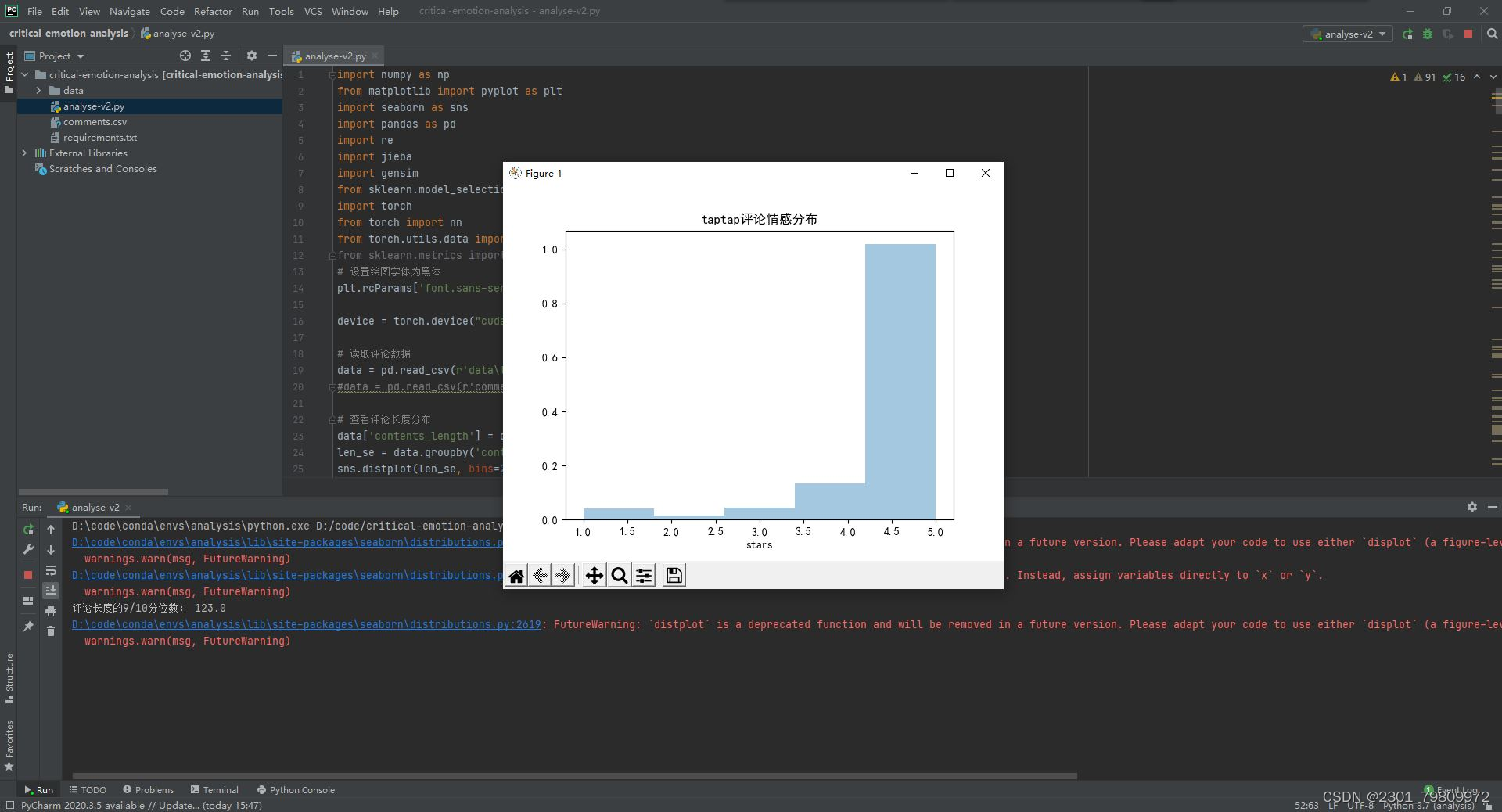
将情感分析结果以可视化的形式展示,包括柱状图、饼图、词云等,以便用户直观地了解情感分布和关键词。
提供用户交互功能,允许用户自定义查询条件,如时间范围、评论来源等,以获取更精细的情感分析结果。
三、项目内容与方法
数据收集与预处理:
从社交媒体、电商平台等渠道收集评论数据。
对数据进行预处理,包括去除HTML标签、特殊字符、URL等噪声。
使用分词工具对评论进行分词,并去除停用词。
情感分析模型构建:
选择适合情感分析的机器学习或深度学习模型,如朴素贝叶斯、支持向量机(SVM)、循环神经网络(RNN)等。
使用标注好的情感数据集对模型进行训练,并调整模型参数以优化性能。
对预处理后的评论进行情感倾向判断,并给出情感分数或标签。
可视化展示:
使用Python的可视化库(如Matplotlib、Seaborn、Wordcloud等)对情感分析结果进行可视化展示。
绘制柱状图展示不同情感倾向的评论数量分布。
绘制饼图展示正面、负面和中性评论的比例。
使用词云展示评论中的关键词及其情感倾向。
用户交互功能:
开发一个简单的Web界面或命令行工具,允许用户输入查询条件。
根据用户输入的查询条件,对评论数据进行筛选和重新分析。
更新可视化结果,以反映用户自定义查询条件下的情感分布情况。
四、技术栈
Python:作为主要编程语言,用于数据处理、模型构建和可视化展示。
Pandas:用于数据处理和清洗。
NLTK或jieba(针对中文):用于文本分词和去除停用词。
Scikit-learn、TensorFlow或PyTorch:用于构建情感分析模型。
Matplotlib、Seaborn、Wordcloud等:用于可视化展示。
Flask或Django(可选):用于开发Web界面(如果需要)。
五、预期成果与贡献
通过本项目的实施,预期将取得以下成果和贡献:
构建一个基于Python的情感分析可视化系统,实现对大量评论数据的快速情感分析。
提供直观的可视化结果,帮助用户快速了解评论中的情感分布和关键词。
允许用户自定义查询条件,获取更精细的情感分析结果,满足不同需求。
为企业或个人提供有价值的情感分析服务,帮助他们更好地了解用户需求和反馈。
二、功能
基于Python对评论进行情感分析可视化
三、系统
四. 总结
本项目利用Python和相关库构建了一个情感分析可视化系统,实现对评论数据的情感倾向判断和可视化展示。通过本项目的实施,我们可以更深入地了解用户的情感需求,为企业和个人提供有价值的决策支持。未来,我们可以进一步优化模型性能、扩展数据源和可视化形式,以满足更广泛的应用场景和需求。