本文字数:7875;估计阅读时间:20 分钟
审校:庄晓东(魏庄)

介绍
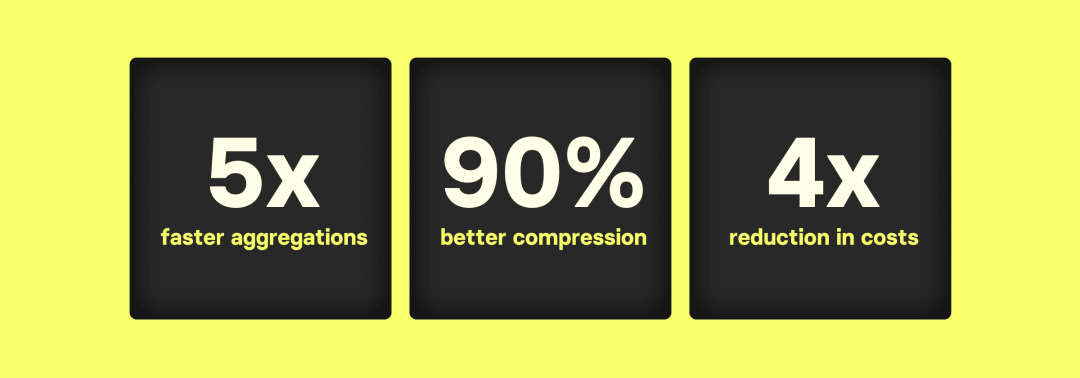
在另一篇博客文章中,我们对 ClickHouse 和 Elasticsearch 在大规模数据分析和可观测性用例中的性能进行了比较,特别是对数十亿行数据表进行的 count(*) 聚合操作。结果显示,ClickHouse 在处理大数据量的聚合查询时,性能显著优于 Elasticsearch。具体表现如下:
ClickHouse 的 count(*) 聚合查询能够高效地利用硬件资源,处理大数据集的延迟至少比 Elasticsearch 低 5 倍。这意味着在相同的延迟下,ClickHouse 所需的硬件更小且成本低 4 倍。
基于这些优势,越来越多的用户从 Elasticsearch 迁移到 ClickHouse,以下是一些客户的反馈:
-
在 PB 级可观测性用例中大幅降低成本:
“从 Elasticsearch 迁移到 ClickHouse,减少了我们可观测性硬件的成本超过 30%。”
——滴滴科技
-
提升数据分析应用的技术限制:
“这释放了新功能的潜力,推动了增长并简化了扩展。”
——Contentsquare
-
在监控平台的可扩展性和查询延迟上大幅改善:
“ClickHouse 帮助我们从每月数百万行扩展到数十亿行。” “切换后,我们看到平均读取延迟提升了 100 倍。”
——The Guild
你可能会问,“为什么 ClickHouse 比 Elasticsearch 更快更高效?”这篇博客将为你提供一个深入的技术解析。
ClickHouse 和 Elasticsearch 中的计数聚合
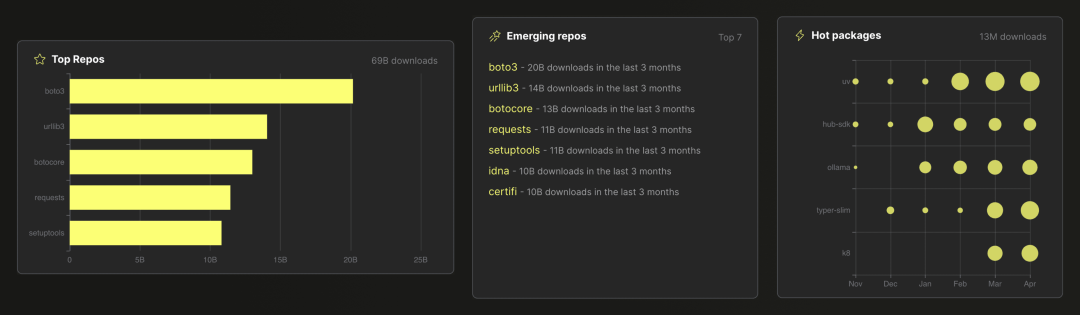
在数据分析场景中,常见的聚合操作是计算和排序数据集中各个值的频率。例如,在这张来自 ClickPy 应用程序的截图中(分析了近 9000 亿行 Python 包下载事件),所有数据可视化在底层都使用了带有 count(*) 聚合操作的 SQL GROUP BY 子句:
同样,在日志记录(或更广泛的可观测性)用例中,聚合操作最常见的应用之一是统计特定日志消息或事件的发生频率(并在频率异常时发出警报)。
在 Elasticsearch 中,类似于 ClickHouse 的 SELECT count(*) FROM ... GROUP BY ... SQL 查询的操作是 terms 聚合,这是 Elasticsearch 的一种桶聚合。
ClickHouse 的 GROUP BY 与 count(*) 和 Elasticsearch 的 terms aggregation 在功能上基本相当,但在实现、性能和结果质量上存在显著差异,具体如下所述。
我们在一篇附带的博客文章中比较了计数聚合的性能。
除了桶聚合,Elasticsearch 还提供了指标聚合。我们将在另一篇博客中对 ClickHouse 和 Elasticsearch 在指标用例上的表现进行比较。
计数聚合的实现方法
并行化
ClickHouse
ClickHouse 从一开始就被设计为能够快速高效地处理和聚合互联网规模的数据。为了实现这一点,ClickHouse 在列值、表块和表分片这三个层次上并行化 SELECT 查询,包括 count(*) 和其他 90 多种聚合函数:

① SIMD 并行化
ClickHouse 利用 CPU 的 SIMD 单元(例如 AVX512)对列中的连续值进行相同的操作。本文详细介绍了其工作原理。
② 多核并行化
在一台拥有 n 个 CPU 核心的机器上,ClickHouse 通过 n 个并行执行通道(或根据用户的 max_threads 设置调整通道数)运行聚合查询:
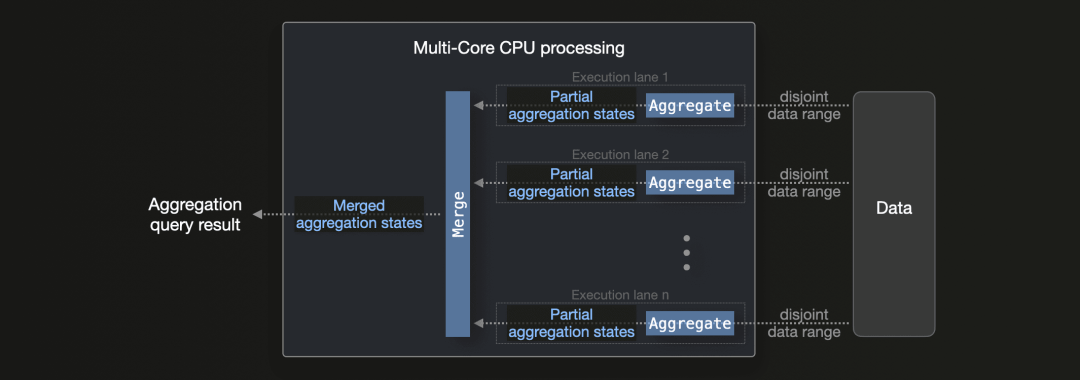
上图展示了 ClickHouse 如何并行处理 n 个不重叠的数据范围。这些数据范围可以是任意的,例如,不需要基于分组键。当聚合查询包含 WHERE 子句形式的过滤条件,并且主索引能够评估这个过滤条件时,ClickHouse 会定位匹配的表数据范围,并在 n 个执行通道之间动态分配这些范围。
这种并行化方法是通过部分聚合状态实现的:每个执行通道都会生成部分聚合状态。这些部分聚合状态最终会被合并成最终的聚合结果。
对于 count(*) 聚合,部分聚合状态仅仅是一个不断更新的计数变量。实际上,count(*) 聚合是最简单的一种聚合,甚至可以在没有部分聚合状态概念的情况下进行内部并行化。为了提供一个利用部分聚合状态实现并行化的具体示例,我们使用这个聚合查询来计算基于英国房地产价格数据集的各个城镇的平均房价:
SELECT
town,
avg(price) AS avg_price
FROM uk_price_paid
GROUP BY town;假设数据库要使用两个并行执行通道计算伦敦的平均房价:
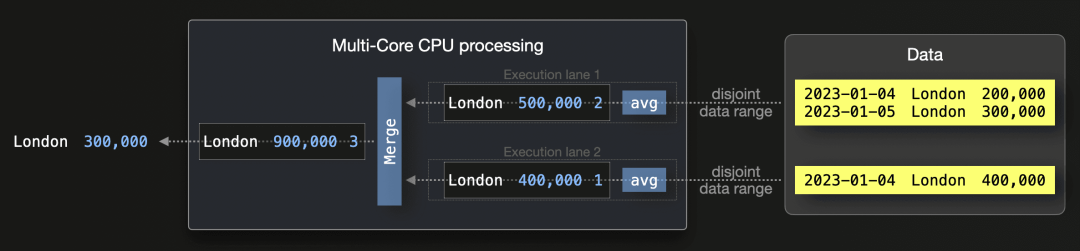
执行通道 1 计算其数据范围内所有伦敦记录的房价平均值。对于执行通道 1,部分聚合状态通常包括:
-
一个总和(如这里的 500,000,为伦敦的房价总和)和
-
一个计数(如这里的 2,为处理的伦敦记录数)。
执行通道 2 计算类似的部分聚合状态。这两个部分聚合状态合并后,可以得出最终结果:伦敦的平均房价为 (500,000 + 400,000) / (2 + 1) = 900,000 / 3 = 300,000。
部分聚合状态对于计算准确的结果是必要的。简单地对子范围的平均值进行平均会产生错误结果。例如,如果我们将第一个子范围的平均值 (250,000) 与第二个子范围的平均值 (400,000) 平均化,我们会得到 (650,000 / 2) = 325,000,这是不正确的。
ClickHouse 在所有可用 CPU 核心上并行化了其支持的 90 多种聚合函数及其与聚合函数组合器的组合。
③ 多节点并行化
如果聚合查询的源表已经分片并分布在多个节点上,ClickHouse 会在所有节点的所有 CPU 核心上并行执行聚合函数。
每个节点使用前面提到的多核并行化技术在本地执行聚合,然后将生成的部分聚合状态传输到发起节点(接收到聚合查询的节点)进行合并:
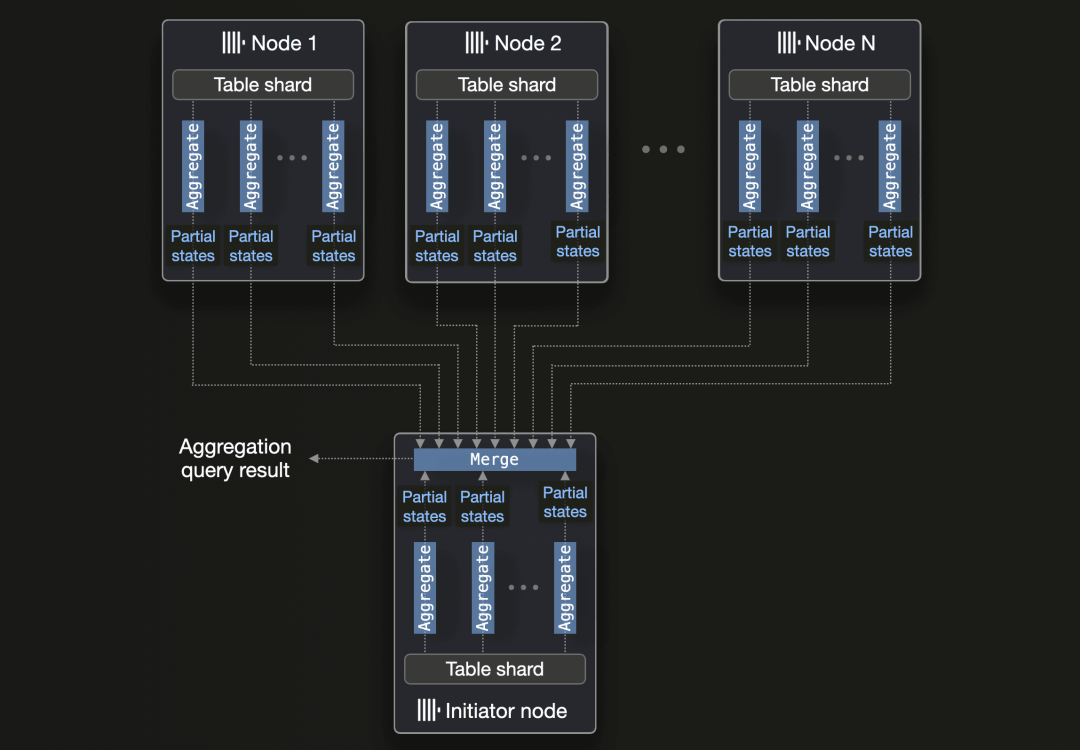
作为优化,如果聚合查询的 GROUP BY 键是分片键的前缀,那么发起节点无需合并部分聚合状态,合并将在每个节点的最后一步完成,然后将最终结果传回发起节点。
增量聚合
前述技术都应用于“查询时”,即当用户运行 SELECT count(*) FROM ... GROUP BY ... 查询时。如果需要频繁执行相同的耗时聚合查询,例如每小时一次,或者需要实现亚秒级延迟,但数据集太大无法实现,ClickHouse 提供了一种额外的优化,可以将负载从查询时间转移到插入时间和后台合并时间。具体而言,上述基于部分聚合状态的技术也可以在数据部分的(并行)后台合并期间应用。
这是一种强大且高度可扩展的持续数据汇总技术,使得聚合查询时大部分数据已经被预先聚合。以下图表展示了这一过程:
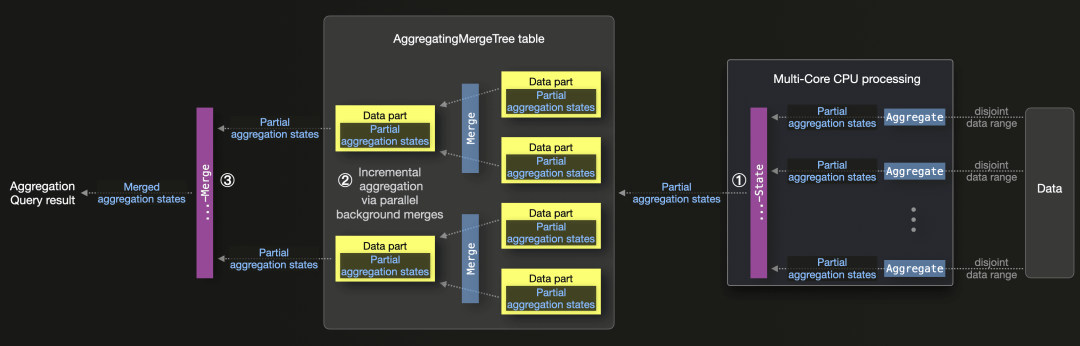
① -State 聚合函数组合器可以让 ClickHouse 查询引擎只合并部分聚合状态(由并行执行通道生成),而不是直接计算最终结果:
SELECT
town,
avgState(price) AS avg_price_state
FROM uk_price_paid
GROUP BY town;当您运行此查询时,avg_price_state 中的部分聚合状态并不会实际显示在屏幕上。
这些合并的部分聚合状态可以作为数据部分写入使用 AggregatingMergeTree 表引擎的表中:
INSERT INTO <table with AggregatingMergeTree engine>
SELECT
town,
avgState(price) AS avg_price_state
FROM uk_price_paid
GROUP BY town;② 此表引擎在后台合并部分数据时,会持续并行地进行部分聚合。最终的合并结果相当于在所有原始数据上运行聚合查询。
物化视图会自动执行上述的插入步骤。以下是基于我们之前使用的每个城镇平均房价示例的具体例子。
③ 在查询时,可以使用 -Merge 聚合函数组合器将部分聚合状态合并成最终的聚合结果:
SELECT
town,
avgMerge(avg_price_state) AS avg_price
FROM <table with AggregatingMergeTree engine>
GROUP BY town;Elasticsearch
与 ClickHouse 不同,Elasticsearch 在 terms 聚合(用于计算计数)中采用了一种完全不同的并行化方法,这导致硬件利用效率低于 ClickHouse:
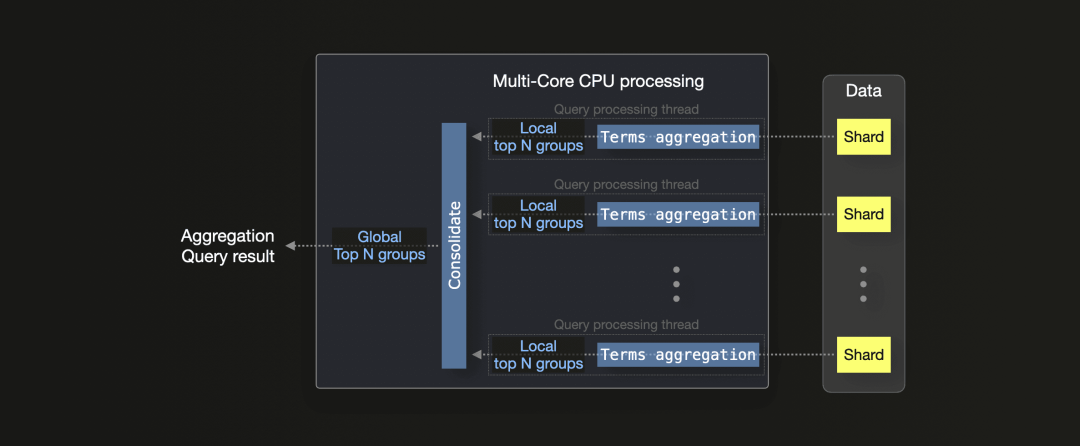
terms aggregation 总是需要一个 size 参数(下文称为 n),Elasticsearch 在每个分片上使用一个 CPU 线程运行该聚合,而不考虑 CPU 核心数量。每个线程计算其处理的分片内的 top n 个结果(默认按每组的最大计数值排序)。分片的本地结果最终会合并为全局的 top n 个最终结果。
Elasticsearch 的多节点并行化 terms aggregation 方法类似。当分片分布在多个节点上时,每个节点会生成一个本地的 top n 个结果(使用上述技术),这些本地结果最终由协调节点(接收到聚合查询的节点)合并为全局最终结果。
这种并行化方法基于数据在分片上的分布方式,可能会导致精度问题。我们用一个例子来说明:
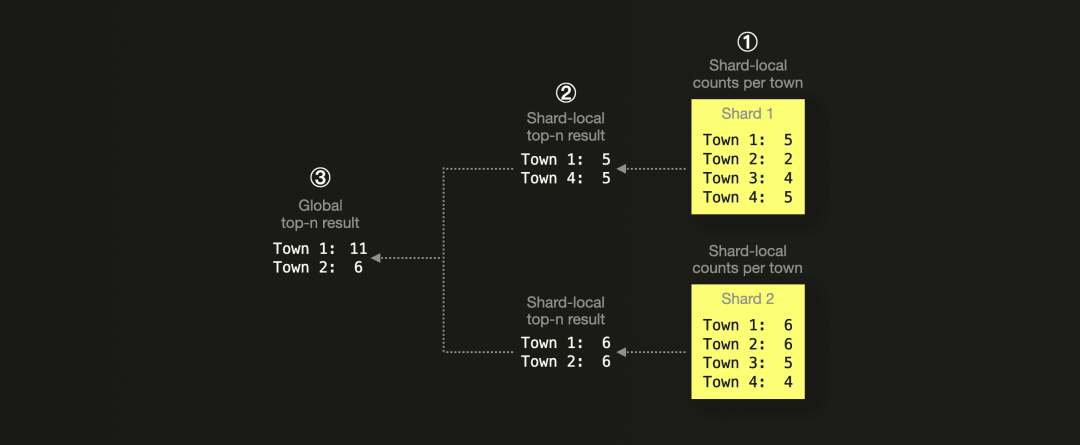
假设我们基于英国房价数据集,想计算销售房产最多的前两个城镇。数据分布在两个分片上。上图抽象地展示了 ① 每个分片内各城镇的房产销售记录数。每个处理线程 ② 返回一个分片内的 top 2 个结果,这些结果 ③ 会被合并为全局的 top 2 个结果。然而,这个结果是不正确的。基于全局数据,每个城镇的正确记录数如下:
-
Town 1: 11
-
Town 2: 8
-
Town 3: 9
-
Town 4: 9
Elasticsearch 计算的结果中,Town 2 的数量和排名都是错误的。可以通过分析返回的数量错误并调整 shard size 参数来提高精度——这会让每个处理线程从每个 shard 返回比查询请求更大的 top n 结果,但也会增加内存需求和运行时间。
Elasticsearch 还利用了基于 JVM 自动向量化和 Java Panama Vector API 的 SIMD 硬件单元。此外,从 Elasticsearch 8.12 版本开始,除 terms 聚合外,查询处理线程可以并行搜索段。因为将上述技术应用于段而不是 shard 同样会遇到精度问题。由于一个 shard 包含多个段,这也会随着 shard size 参数的增加而增加每个处理线程的工作量。
精度
Elasticsearch
如上所述,当查询的数据分布在多个 shard 上时,Elasticsearch 的 terms 聚合中的计数值默认是近似值。可以通过分析返回的数量错误并调整 shard size 参数来提高结果的准确性,但这会增加运行时间和内存需求。
ClickHouse
ClickHouse 的 count(*) 聚合函数计算完全准确的结果。
ClickHouse 的 count(*) 聚合使用起来很简单,不需要像 Elasticsearch 那样进行额外配置。
无限制子句
Elasticsearch
由于其执行模型,Elasticsearch 中的 count 聚合无法使用无限制子句——用户必须始终指定一个 size 设置。即使设置了较大的 size 值,对于高基数数据集的桶聚合也会受到 max_buckets 设置的限制,或者需要通过使用昂贵的复合聚合分页结果。
ClickHouse
ClickHouse 的 count(*) 聚合不受 size 限制。此外,如果查询的内存消耗超过(可选的)用户指定的最大内存阈值,它还支持将临时结果溢出到磁盘。除此之外,无论数据集大小如何,如果聚合中的分组列形成主键的前缀,ClickHouse 可以以最小的内存需求运行聚合。
同样,ClickHouse 的 count(*) 聚合相比 Elasticsearch 具有较低的复杂性。
连续数据汇总的方法
无论数据库中的聚合和查询处理效率有多高,聚合数十亿或数万亿行数据(这是现代数据分析应用中的典型情况)总是会因为必须处理的大量数据而本质上代价高昂。
因此,专门处理分析工作负载的数据库通常会提供数据汇总作为构建块,用户可以自动将传入数据转换为汇总数据集,以预聚合且通常显著缩小的格式表示原始数据。查询将利用预计算数据在交互式应用中(如前面提到的 ClickPy 应用)提供亚秒级的延迟。
Elasticsearch 和 ClickHouse 都提供了内置的自动连续数据汇总技术。它们的技术在功能上具有相同的能力,但在实现、效率及计算成本上有着显著不同。
Elasticsearch
Elasticsearch 提供了一种称为 transforms 的机制,用于批量将现有索引转换为汇总索引或连续转换摄入的数据。
基于 Elasticsearch 的磁盘格式,我们在此详细描述了 transforms 的工作原理。
我们注意到 Elasticsearch 方法的三个缺点,即:
-
需要保留旧的原始数据:否则,transforms 无法正确重新计算聚合。
-
可扩展性差和计算成本高:每当在检查点后检测到新的原始数据文档时,所有的桶数据都会从不断增长的原始数据源索引中查询并重新聚合。这无法扩展到数十亿,更不用说万亿级的文档集,并导致高计算成本。
-
不是实时的:transforms 预聚合目标索引只有在下一次检查间隔之后才与原始数据源索引同步。
专用于时间序列度量数据,Elasticsearch 还提供了一种降采样技术,通过以较低的粒度存储数据来减少数据的占用空间。降采样是 rollups 的后继技术,相当于一种 transform,通过将度量数据文档按其时间戳转换为固定时间间隔(例如小时、天、月或年)进行分组,然后应用一组固定的聚合(min、max、sum、value_count 和 average)。与 ClickHouse 链式物化视图的比较可以作为未来博客的主题。
ClickHouse
ClickHouse 通过结合物化视图与 AggregatingMergeTree 表引擎以及部分聚合状态,进行自动且(与 Elasticsearch 相比)增量的数据转换。
基于 ClickHouse 的磁盘格式,我们在此详细解释增量物化视图的机制。
ClickHouse 的物化视图相较于 Elasticsearch 的 transforms 具有三个主要优点:
-
无原始数据依赖:源表中的原始数据从未被查询,即使用户想执行精确的聚合计算也是如此。这允许对源表和预聚合目标表应用不同的 TTL 设置。此外,在仅需执行同一组聚合查询的情况下,用户可以选择在预聚合后完全舍弃源数据(使用 Null 表引擎)。
-
高可扩展性和低计算成本:增量聚合专为源数据表包含数十亿或数万亿行的场景设计。与反复查询不断增长的源表并重新计算属于同一组的所有现有行的聚合值相比,当存在新的原始数据行时,ClickHouse 仅从新插入的原始数据行的值计算部分聚合状态。此状态在后台与先前计算的状态增量合并。换句话说,每个原始数据值只与其他原始数据值聚合一次。与通过对原始数据进行蛮力聚合相比,这显著降低了计算成本。
-
实时性:当原始数据源表的插入操作成功确认时,预聚合目标表保证是最新的。
回填预聚合
在我们附带的基准测试博客文章中,我们使用 Elasticsearch 的连续 transforms 和 ClickHouse 中的等效物化视图将摄入的数据即时预聚合到独立的数据集中。有时,这并不可行。例如,当大量数据已经摄入时,重新摄入是不可能的或太昂贵,而且引入的查询会受益于以预聚合格式运行这些数据。
Elasticsearch
我们在 Elasticsearch 中通过对已经摄入的 100 亿行数据集运行批量 transform 来模拟这种情况,预先计算计数到一个单独的数据集中,以加速我们基准测试中使用的聚合查询。连续和批量 transforms 都使用上述的基于检查点的机制。由于该机制的缺点,即在检查点处重复查询和聚合相同的值:
通过批量 transform 进行回填花了整整 5 天(使用了大量计算成本)。这是一个很长的等待时间,直到查询可以从预聚合数据中受益。
ClickHouse
在 ClickHouse 中,回填预聚合通过使用 INSERT INTO SELECT 语句直接插入到物化视图的目标表中,使用视图的 SELECT 查询(转换):
对于 100 亿行数据集,这只需 20 秒,而不是整整 5 天。
这 20 秒包括聚合完整的 100 亿行数据集并将结果(作为部分聚合状态)写入目标表,之后物化视图将使用该表处理额外的传入数据。根据原始数据集的基数,这可能是一种内存密集型方法,因为完整的原始数据集是临时聚合的。或者,用户可以使用一种需要最少内存的变体。
请注意,ClickHouse 手动聚合原始数据集并将结果直接插入目标表的 20 秒方法在 Elasticsearch 中是不可行的。理论上,这可以通过 reindex(索引到索引复制)操作实现。然而,这需要在原始数据集中保留 _source 数据(需要显著更多的存储空间)。还需要一种机制来手动创建必要的检查点,以便在开始流式数据时正确继续预聚合过程。在 ClickHouse 中,在我们运行上述回填后,物化视图将继续对新传入的数据进行增量聚合。
ClickHouse 中的高性能聚合
大多数数据库,包括 ClickHouse,在实现 GROUP BY 时都使用某种变体的哈希聚合算法,其中输入行的聚合值存储并更新在以分组列为键的哈希表中。选择正确的哈希表类型对性能至关重要。在底层,ClickHouse 利用复杂的哈希表框架来实现聚合。根据分组列的数据类型、估计基数和其他因素,每个聚合查询都会从截至 2024 年 4 月的 30 多种不同实现中,单独选择最快的哈希表。ClickHouse 是专门为在大量数据上进行高性能聚合而构建的。
ClickHouse 目前是市场上最快的数据库之一,具有用于数据分析的独特功能:
-
最先进的矢量化查询引擎,利用所有服务器和集群资源并行执行,将硬件使用推至理论极限
-
现代 SQL 方言和丰富的数据类型,包括地图和数组(加上用于操作数组的 80 多个函数),优雅而简单地建模和解决各种问题
-
超过 90 个预构建的聚合函数,支持大数据集的增量聚合,以及强大的聚合组合器以扩展其他聚合函数的行为
-
超过 1000 个常规数据处理函数,涵盖数学、地理、机器学习、时间序列等领域
-
完全并行化的窗口函数
-
并行连接算法
-
原生支持从几乎任何数据源加载 90 多种文件格式的数据
总结
在这篇博客文章中,我们深入回答了为什么 ClickHouse 在处理数据分析和日志/可观测性使用场景中常需的计数聚合时,比 Elasticsearch 更快、更高效。
我们解释了 ClickHouse 和 Elasticsearch 在并行化方法、结果质量和可用性复杂度方面的差异。我们探讨了 Elasticsearch 和 ClickHouse 内置的预计算计数机制。我们强调了 ClickHouse 的物化视图在处理数十亿/万亿级行集方面为何比 Elasticsearch 的 transforms 更高效、更适合。
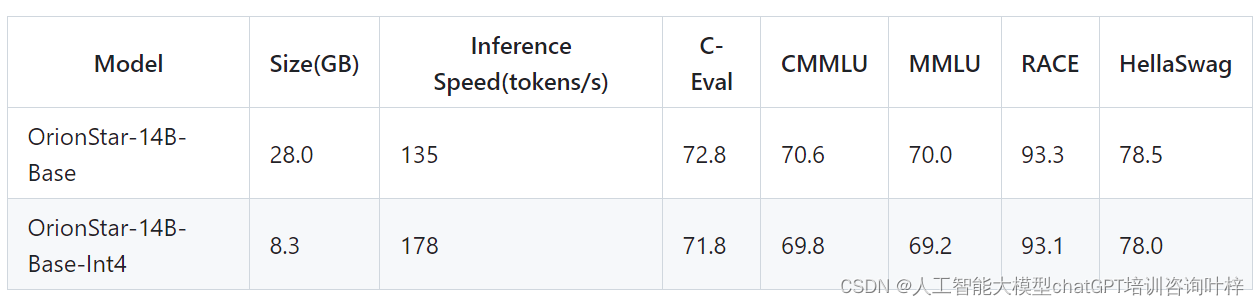
我们建议阅读我们附带的博客文章《ClickHouse vs. Elasticsearch: The Billion-Row Matchup》【https://clickhouse.com/blog/clickhouse_vs_elasticsearch_the_billion_row_matchup】,以了解 ClickHouse 的高性能聚合实际表现。作为预告,我们在此包括了一些基准测试结果:



征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com

联系我们
手机号:13910395701
邮箱:Tracy.Wang@clickhouse.com
满足您所有的在线分析列式数据库管理需求