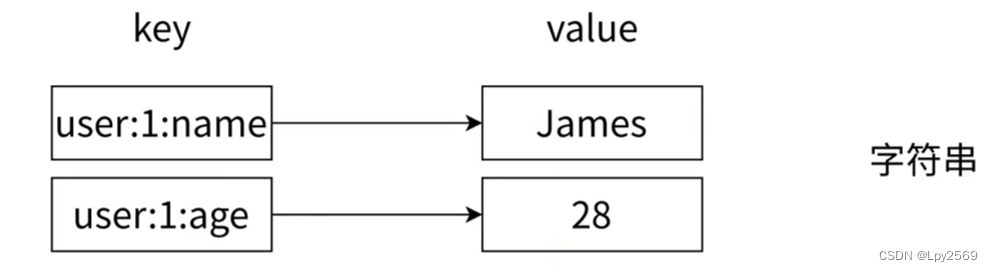
String
用法
1. 设置键值对
(1)设置键值对使用 set 命令设置 key 的值。
![]()
返回值:ok,如果 key 已经存在,set 命令会覆盖旧值。
(2)使用 setex 命令设置 key 的值并为其设置过期时间(以秒为单位)。
![]()
返回值:ok
(3)使用 setnx 命令只在 key 不存在时设置其值。
![]()
返回值:1 - 成功,0 - 失败
(4)设置多个键值对使用 mset 命令同时设置一个或多个key-value对。
![]()
[] 表示可以多写,也可以不写,意思就是可以同时设置多个key-value对
2. 获取键值
使用 get 命令获取key的值。
![]()
返回值:存在返回值,不存在返回nil
3. 数值操作
使用 incr、decr、incrby、decrby 等命令对key对应的整数值进行加、减操作。

![]()
返回值:返回加后的值
内部编码
1. int:当存储的值为整数,且值的大小可以用long类型表示时,Redis使用int编码。 Redis启动时会预先建立10000个分别存储0到9999的redisObject变量作为共享对象。这意味着如果设置的字符串键值在0到10000之间,Redis可以直接指向这些共享对象,从而节省内存空间。
2. embstr:当存储的值为字符串,且长度大于某个阈值(不同资料中给出的具体数字可能有所不同,但常见的是39字节或44字节)时,Redis使用embstr编码。 embstr编码中,String对象的实际值会被存储在一个特殊的字符串对象中,该对象包含了字符串的长度和字符数组的指针,但是不包含额外的空间。
3. raw:当存储的值为字符串,且长度超过embstr编码的阈值时,Redis使用raw编码。 raw编码是最基本的字符串表示方式,底层类似于Java中的byte数组。 raw编码在处理大字符串时具有较好的灵活性。
redis会根据当前值的类型和长度动态决定使用哪种内部编码实现。上述的阈值(如39字节或44字节)一般是可以根据实际的应用场景在redis的配置文件redis.conf中进行修改的。
使用场景
1. 作为缓存对象
将经常访问的数据(如用户信息、商品详情等)存储在Redis中,作为缓存使用,以减少对数据库的访问次数,提高系统性能。
2. 计数操作
利用Redis的原子性操作(如incr命令)来实现计数器功能,如网站的访问量、点赞数、评论数等。
3. 共享Session信息
在多应用或多服务器架构中,使用Redis存储用户Session信息,实现Session的共享和持久化。
4. 限制访问
限制一个用户只能在一个设备上登录,或者在发送短信时设置key的过期时长等。
5. 分布式锁
使用Redis的String类型结合 setnx 命令实现分布式锁,以确保在分布式系统中多个进程或线程对共享资源的互斥访问。
Hash
用法
redis 自身用的就是键值对(key-value),而使用 hash 类型用来存储的时候防止搞混,映射关系就为 field-value
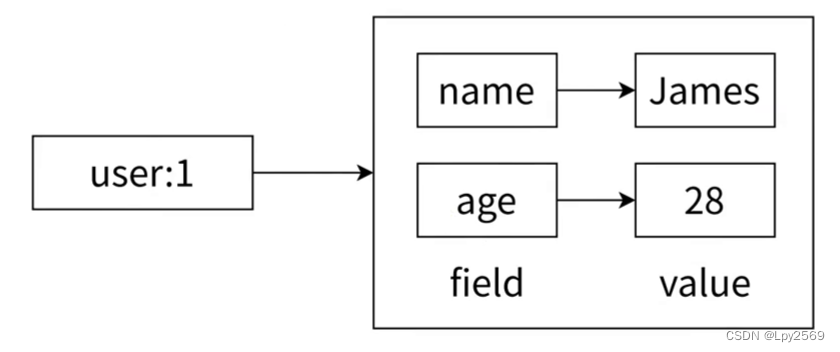
1. 设置字段和值
(1)设置 hash 指定字段(field)的值(valueh)

[] 表示可以多写,也可以不写,意思就是可以同时设置多组键值对
返回值:设置成功的键值对的个数
(2)在 key 不存在时设置其值。

2. 获取 flild / value
(1)获取 key 的 field

返回值:存在返回值,不存在返回nil
(2)获取 key 的所有 fleid

先根据 key 找到对应的 hash,然后再遍历 hash
(3) 获取对应 key 中所有 field 的个数
![]()
返回值:个数
(4)查询多个 value
![]()
(5)获取 key 所有 value

返回值:找到的 value
(6)获取 key 所有的 field 和 value
![]()
假设有两组 hash:key1 f1 111,key2 f2 222
返回值:(1)"f1" (2)"111"(3)"f2"(4)"222"
3. 判断 / 删除
(1)判断指定的 field 是否存在
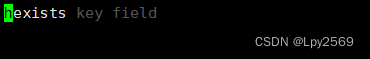
返回值:1 - 存在,0 - 不存在
(2)删除 hash 中指定的 field

如果直接写 del key 会直接把所有的 key 删除
返回值:删除的个数
返回值:找到的 field
4. 数值操作
对值进行加/减

![]()
返回值:计算后的值
内部编码
1. iplist(压缩列表):当哈希类型元素个数小于hash-max-ziplist-entries配置(默认512个)且同时所有值都小于hash-max-ziplist-value配置(默认64字节)时,Redis会使用ziplist作为哈希的内部实现。 ziplist使用更加紧凑的结构实现多个元素的连续存储,所以在节省内存方面比hashtable更加好,但是读的比较慢(数据越多越慢)。
2. hashtable(哈希表):当哈希类型无法满足ziplist的条件时,Redis会使用hashtable作为哈希的内部实现。 hashtable的读写时间复杂度为O(1),提供了高效的键值对存储和访问能力。 Redis在内部会根据存储的数据类型和实际使用情况动态选择使用哪种编码方式,以达到性能和存储空间的最佳平衡。
hash-max-ziplist-entries和hash-max-ziplist-value可以在Redis的配置文件redis.conf中进行自己配置。
使用场景
1.用户信息存储:
- 存储用户的基本信息,如用户名、密码(通常是哈希后的密码)、邮箱、手机号等。
- 可以用用户的唯一 ID 作为 key,将用户的其他信息存储在 Hash 中。
2. 购物车:
- 对于电商网站,可以使用 Hash 来存储用户的购物车信息。
- key 可以是用户的 ID,field 可以是商品的 ID,value 则是商品的数量或其他相关信息。
3. 缓存热点数据
- 将频繁访问的、结构化的数据(如文章详情、商品详情等)存储在 Hash 中,以提高访问速度。
- 当需要从数据库或其他慢速数据源中获取这些数据时,可以先检查 Redis 中是否存在缓存。
List,set,bitfield 等后面我会再总结出来。