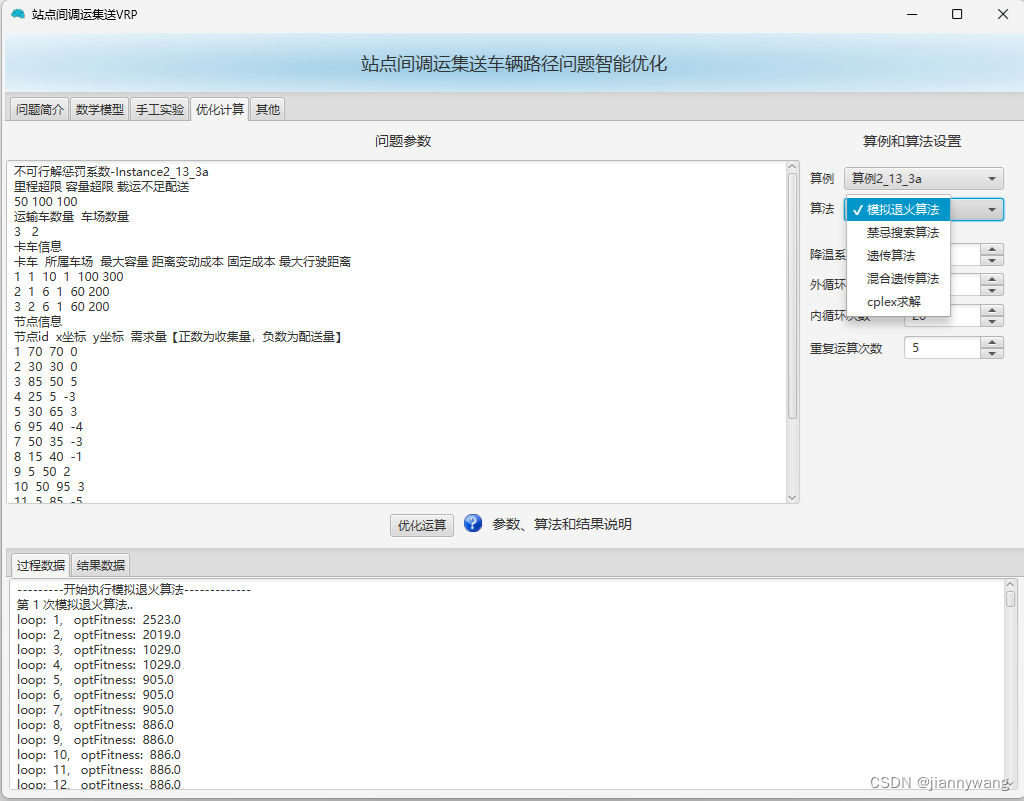
论文题目:YOLOv10: Real-Time End-to-End Object Detection
研究单位:清华大学
论文链接:http://arxiv.org/abs/2405.14458
代码链接:https://github.com/THU-MIG/yolov10
作者提供的模型性能评价图,如下:
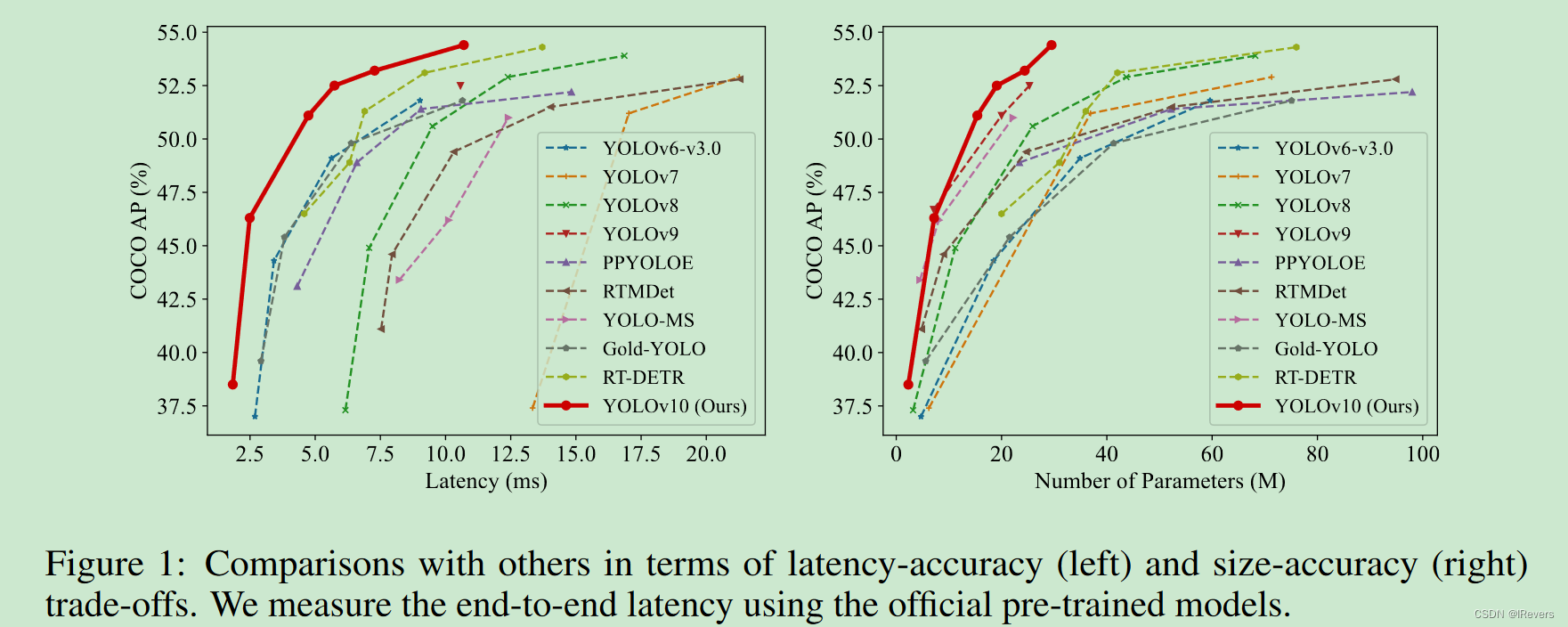
| Model | Test Size | #Params | FLOPs | APval | Latency |
|---|---|---|---|---|---|
| YOLOv10-N | 640 | 2.3M | 6.7G | 38.5% | 1.84ms |
| YOLOv10-S | 640 | 7.2M | 21.6G | 46.3% | 2.49ms |
| YOLOv10-M | 640 | 15.4M | 59.1G | 51.1% | 4.74ms |
| YOLOv10-B | 640 | 19.1M | 92.0G | 52.5% | 5.74ms |
| YOLOv10-L | 640 | 24.4M | 120.3G | 53.2% | 7.28ms |
| YOLOv10-X | 640 | 29.5M | 160.4G | 54.4% | 10.70ms |
YOLOv10-N:https://github.com/jameslahm/yolov10/releases/download/v1.0/yolov10n.pt
YOLOv10-S:https://github.com/jameslahm/yolov10/releases/download/v1.0/yolov10s.pt
YOLOv10-M:https://github.com/jameslahm/yolov10/releases/download/v1.0/yolov10m.pt
YOLOv10-B:https://github.com/jameslahm/yolov10/releases/download/v1.0/yolov10b.pt
YOLOv10-L:https://github.com/jameslahm/yolov10/releases/download/v1.0/yolov10l.pt
YOLOv10-X:https://github.com/jameslahm/yolov10/releases/download/v1.0/yolov10x.pt
总结:从结果上看,模型延迟方面有较大的提升,相对于参数来说,AP提升相比最先进的v9较为微小,简单来说就是模型更适合端侧部署,因为推理延迟时间低。
!!!重要说明:YOLOv10的代码参考ultralytics (YOLOv8)and RT-DETR,很多命令都可以复用ultralytics (YOLOv8)的。
一、环境配置
测试平台:Ubuntu18.04 x64,编译语言:Python3.9
- (1)克隆YOLOv10项目地址:
git clone https://github.com/THU-MIG/yolov10.git
- (2)安装环境【可不看】
如果之前配置过YOLOv8等其他环境可以略过下面内容,因为这些包基本都差不多,后面训练的时候出问题再pip安装也是可以的。
conda create -n yolov10 python=3.9
conda activate yolov10
cd yolov10
pip install -r requirements.txt
- (3)编译
如果读者已经进入yolov10的目录下可以略过第一行的进行目录命令(cd yolov10)
cd yolov10
pip install -e . -i https://pypi.tuna.tsinghua.edu.cn/simple
YOLOv10延续了YOLOv8的方式,将项目封装成命令的方式进行训练和测试等操作,因此如果顺利运行完会提示:

至此,yolov10的项目安装编译完毕。
二、模型训练
训练模型的话直接用命令行就可以了,这里以coco数据集(官网是要求数据集放在../datasets/coco文件夹下,如果改位置,可以修改coco.yaml的path变量)为例。
yolo detect train data=coco.yaml model=yolov10s.yaml epochs=500 batch=256 imgsz=640 device=0,1
device:设备id,如果只有一张显卡,则device=0,如果有两张,则device=0,1,依次类推。
imgsz:图像放缩大小resize,默认是640,如果资源不够可以设置为320试试。
笔者自己测试了一下yolov10s,需要21.2GB的显存,yolov10n需要16GB左右,其他的模型由于设备资源有限,没有进行尝试。
三、模型测试
- COCO2017数据集AP验证,命令如下:
yolo val model=yolov10s.pt data=coco.yaml batch=256
- 模型推理测试((默认读取
yolov10/ultralytics/assets文件夹下的所有图像)
yolo predict model=yolov10s.pt
如果测试别的路径下的文件可以在上面命令后面加上source='xxx/bus.jpg',下述命令跟yolo predict相关的都可以在后面加上改参数。
推理结果如下:


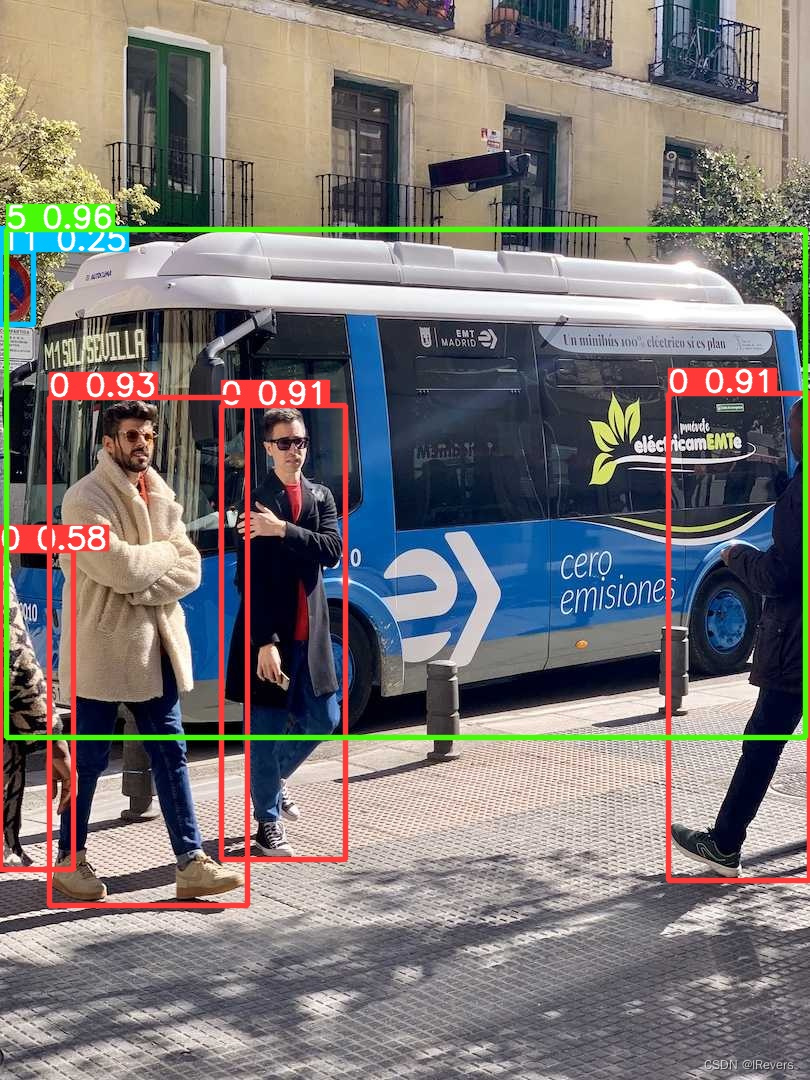
总结:YOLOv10s的检测效果还是可圈可点的,连左上角的交通标志牌都识别到了,推理时间也比较快。
四、ONNXRUNTIME测试
说明:本节测试需要提前安装
onnx和onnxruntime。
- (1)模型转换
yolo export model=yolov10s.pt format=onnx opset=13 simplify
运行后会在yolov10s.pt文件存放路径下生成一个yolov10s.onnx的ONNX模型文件。
- (2)模型推理测试((默认读取
yolov10/ultralytics/assets文件夹下的所有图像)
yolo predict model=yolov10s.pt
推理结果如下:


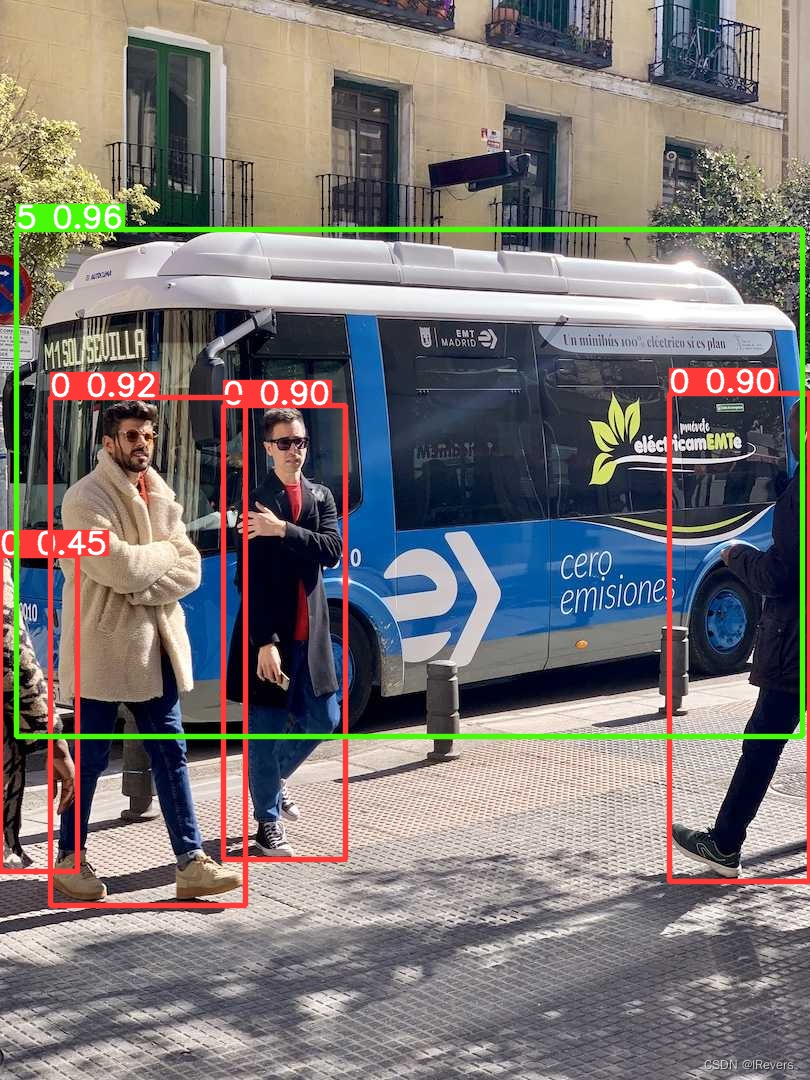
总结:左上角的交通标志检测不到了,而且速度还慢了,不知道是不是没有用gpu的原因。
五、TensorRT测试
TensorRT加速推理(需要使用NVIDIA的显卡或者嵌入式设备系列Jetson),而且需要根据自身需求指定对应的模型路径,这里以项目目录下的yolov10s.pt为例。 本节测试需要提前安装Tensorrt(如果没装,可以直接看下面问题,有说明安装方式)。
- (1)模型转换
方式一:使用项目命令进行转换(笔者使用)
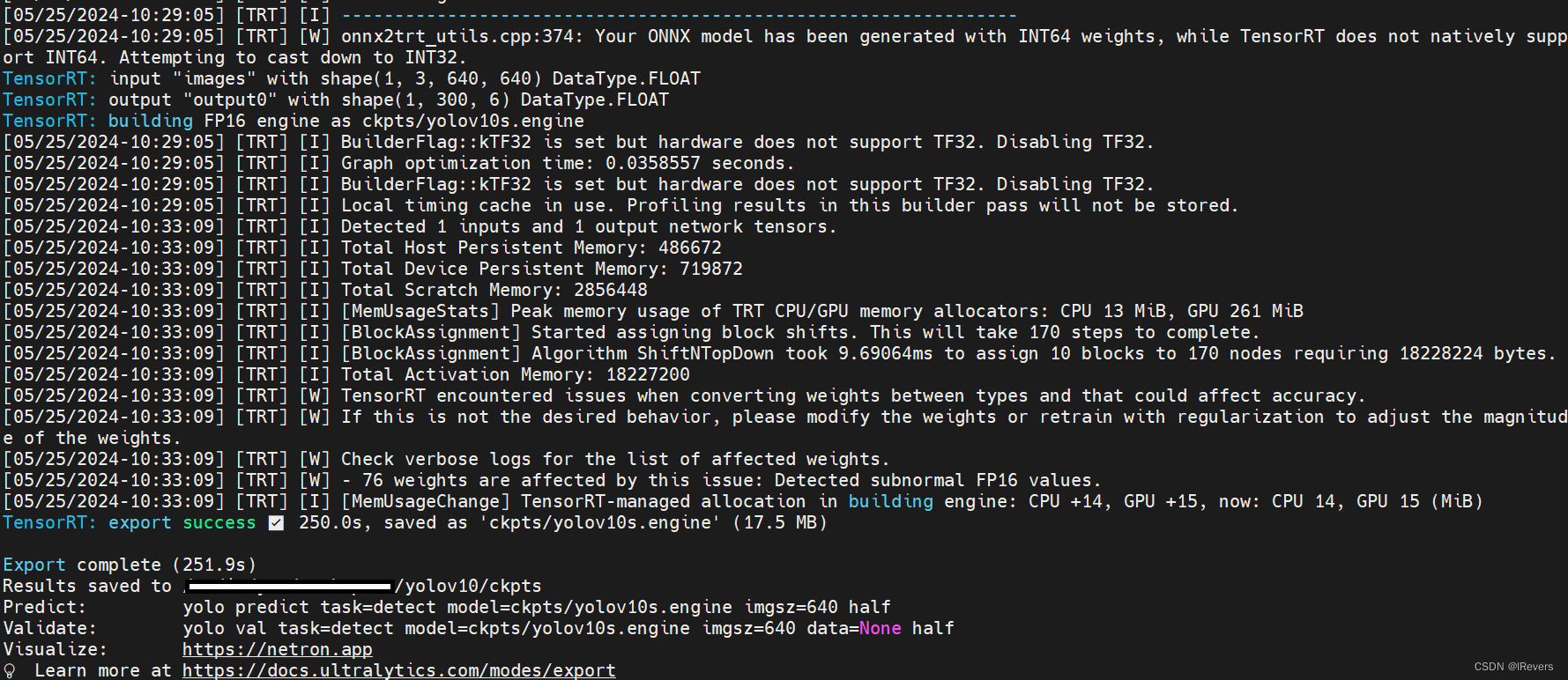
yolo export model=yolov10s.pt format=engine half=True simplify opset=13 workspace=16
转换成功结果如下:
方式二:使用TensorRT命令行形式进行转换
trtexec --onnx=yolov10s.onnx --saveEngine=yolov10s.engine --fp16
- (1)模型推理
# Predict with TensorRT
yolo predict model=yolov10s.engine
推理结果如下(默认读取yolov10/ultralytics/assets文件夹下的所有图像):
推理结果如下:

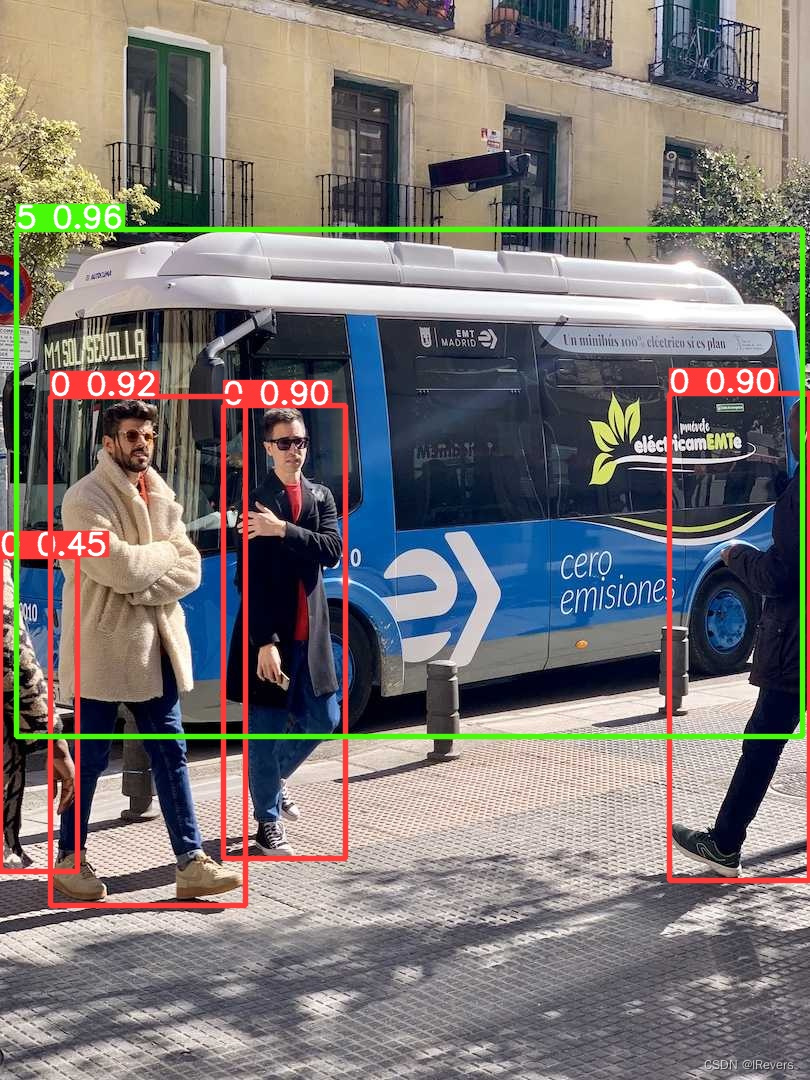 总结:整体来说,推理时间比PT模型和ONNX模型推理还快不少。
总结:整体来说,推理时间比PT模型和ONNX模型推理还快不少。
- (3)问题:如果在运行Tensorrt模型生成时出现错误,大概率是在转为INT32时出现了问题,标志为:
onnx2trt_utils.cpp:369: Your ONNX model has been generated with INT64 weights,如果后面提示操作有问题,就是因为Tensorrt版本的问题,YOLOv10很多算子操作都需要tensorrt > 8.5.2.1,所以如果不是对应版本的话就会报某些算子不支持操作,如:
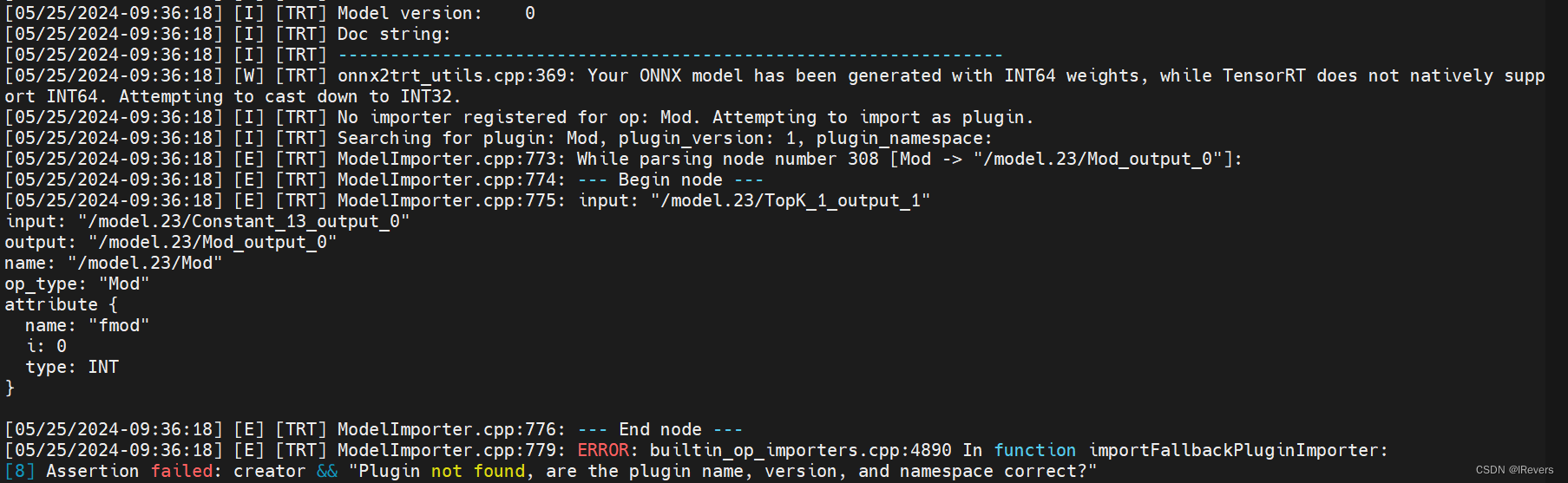
如果是因为TensorRT版本的问题,那就要去NVIDIA官网下载对应的TensorRT安装包进行安装,笔者在Ubuntu x64上选择v8.6.1进行安装。
TensorRT下载地址如下:https://developer.nvidia.com/nvidia-tensorrt-8x-download
注意要安装TAR压缩包进行编译才有效,下载TAR包后,进行解压,命令如下(记得将命令改成读者自己的文件名称和路径):
tar -xvf TensorRT-8.6.1.6.Linux.x86_64-gnu.cuda-11.8.tar.gz
然后,在~/.bashrc文件下设置环境变量
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/xxx/TensorRT-8.6.1.2/lib
export PATH=$PATH:/xxx/TensorRT-8.6.1.2/bin
最后,如果想安装python版的tensorrt可以运行如下命令:
cd TensorRT-8.6.1.2/python
pip install tensorrt-8.6.1.2-cp39-none-linux_x86_64.whl
六、总结
YOLOv10比最先进的YOLOv9延迟时间更低,测试结果可以与YOLOv9媲美,可能会成为YOLO系列模型部署的“新宠”。
七、参考
[1] https://github.com/ultralytics/ultralytics/issues/9962











![[图解]产品经理创新之阿布思考法](https://img-blog.csdnimg.cn/direct/fde91235b2904b45b8b06208b7936eb7.png)