大家好,机器学习(ML)作为人工智能的核心,近来得到巨大应用,ML是使计算机能够在无需显式编程的情况下进行学习和预测或决策。ML算法通过学习历史数据模式,来对新的未见数据做出明智的预测或决策。然而,构建和训练ML模型只是第一步,同样重要的是对这些模型进行分析和解释,以深入了解其行为、性能和局限性。模型分析帮助我们了解模型对数据底层模式的捕捉程度,识别潜在的偏差或错误,并对模型改进或部署做出明智决策。
随着机器学习模型变得日益复杂,理解其内部工作原理和有效评估其性能变得更加具有挑战性。各个机器学习框架也实现各种各样评估、分析及可视化模型的工具和软件包,Yellowbrick就是其中的一个,提供了强大的模型可视化分析库,可以帮助我们直观地分析和诊断机器学习模型的表现。接下来的内容,我们将深入了解Yellowbrick,探索其功能及表现,看看它如何成为机器学习模型可视化分析与诊断的神器。
1.Yellowbrick
Yellowbrick是一个专注于视觉诊断和模型分析的Python库,它与流行的机器学习库如scikit-learn和XGBoost无缝集成,提供了多种可视化工具,以帮助模型评估和解释。Yellowbrick由District Data Labs团队开发,提供了一个直观的界面,使用户仅需几行代码就能创建信息丰富的可视化图表。
github 地址:https://github.com/DistrictDataLabs/yellowbrick
使用pip命令安裝Yellowbrick:
pip install yellowbrick -i https://pypi.tuna.tsinghua.edu.cn/simple下面介绍特征可视化和模型评估可视化的实例,包括特征可视化(Feature Visualization)、K-Means肘部图(Elbow Plot)、混淆矩阵(Confusion Matrix)、残差图(Residual Plot)、流形学习(Manifold Learning),进而理解Yellowbrick特征和用处。
2.特征可视化
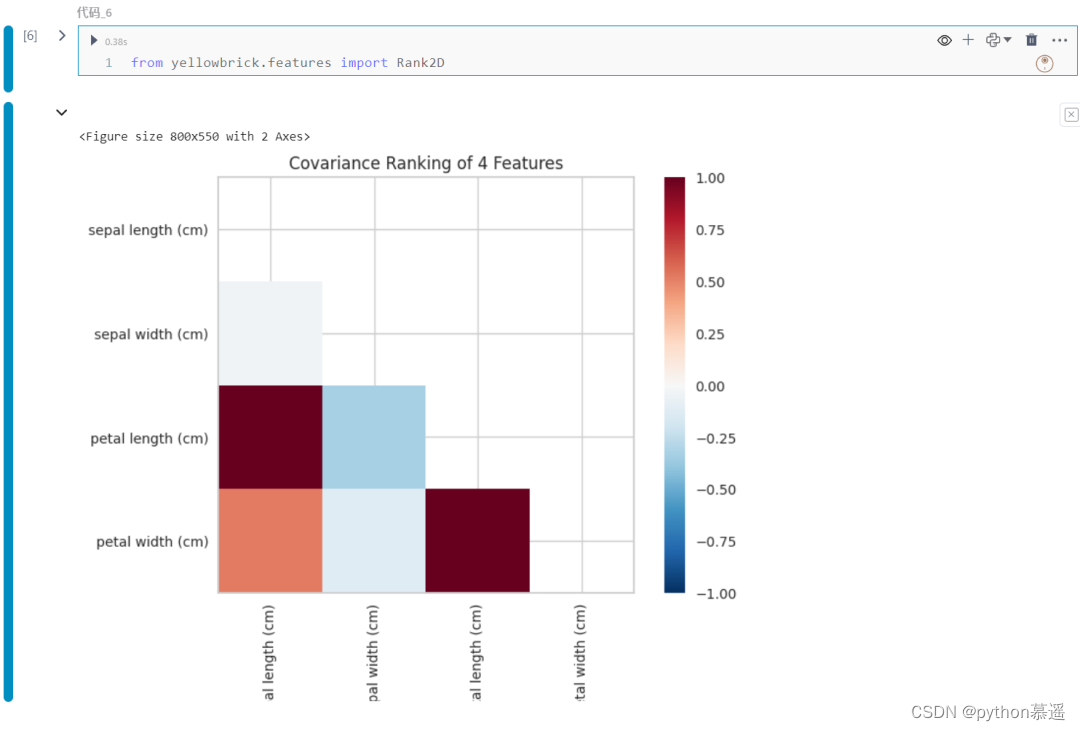
在此实例中,可以看到Rank2D如何使用协方差对数据集中的每个特征进行成对比较。通过计算特征之间的协方差,Rank2D能够度量它们之间的相关性,然后将它们按照排名显示为左下角三角形图。
from yellowbrick.features import Rank2D
from sklearn.datasets import load_iris
# 加载示例数据
data = load_iris()
X = data.data
y = data.target
features = data.feature_names
# 创建 Rank2D 可视化器
visualizer = Rank2D(features=features, algorithm='covariance')
# 将数据拟合到可视化器中
visualizer.fit(X, y)
# 转换数据
visualizer.transform(X)
# 渲染可视化图
visualizer.show()
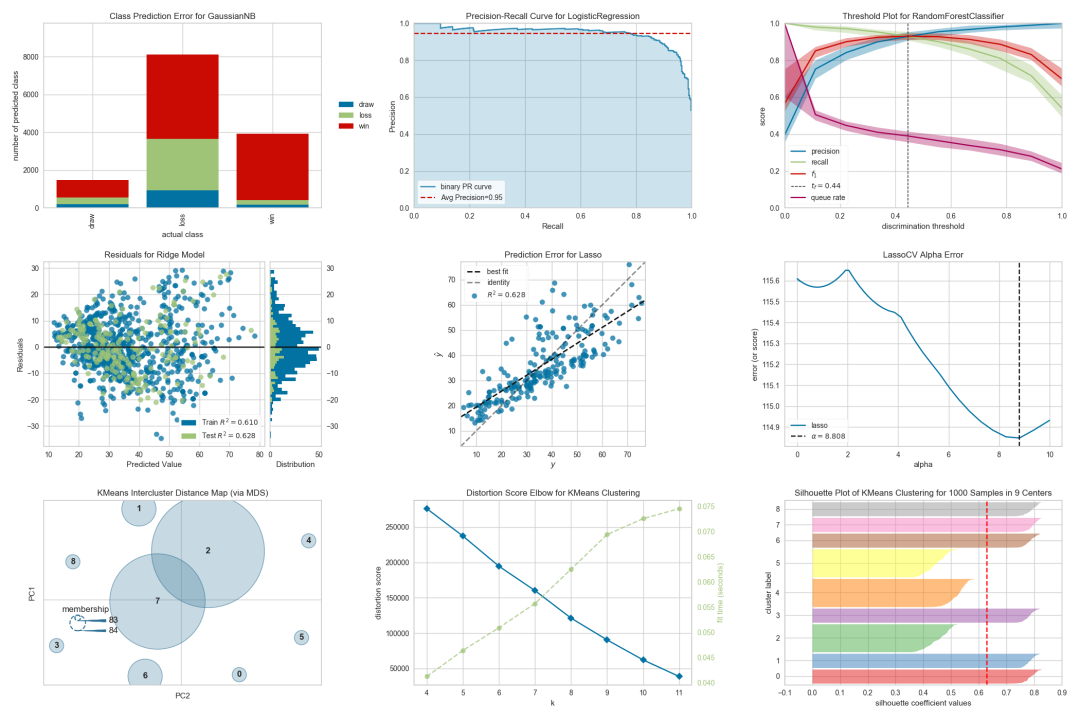
3.K-Means肘部图(Elbow Plot)
肘部图(Elbow Plot)是通过可视化平方距离和来帮助确定K-means聚类中的最佳簇数,使用Yellowbrick预定义函数来创建此可视化图表。
import logging
logging.getLogger('matplotlib').setLevel(logging.ERROR)
from sklearn.cluster import KMeans
from yellowbrick.cluster import KElbowVisualizer
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=100, centers=4, random_state=42)
model = KMeans()
visualizer = KElbowVisualizer(model, k=(2, 10))
visualizer.fit(X)
visualizer.show()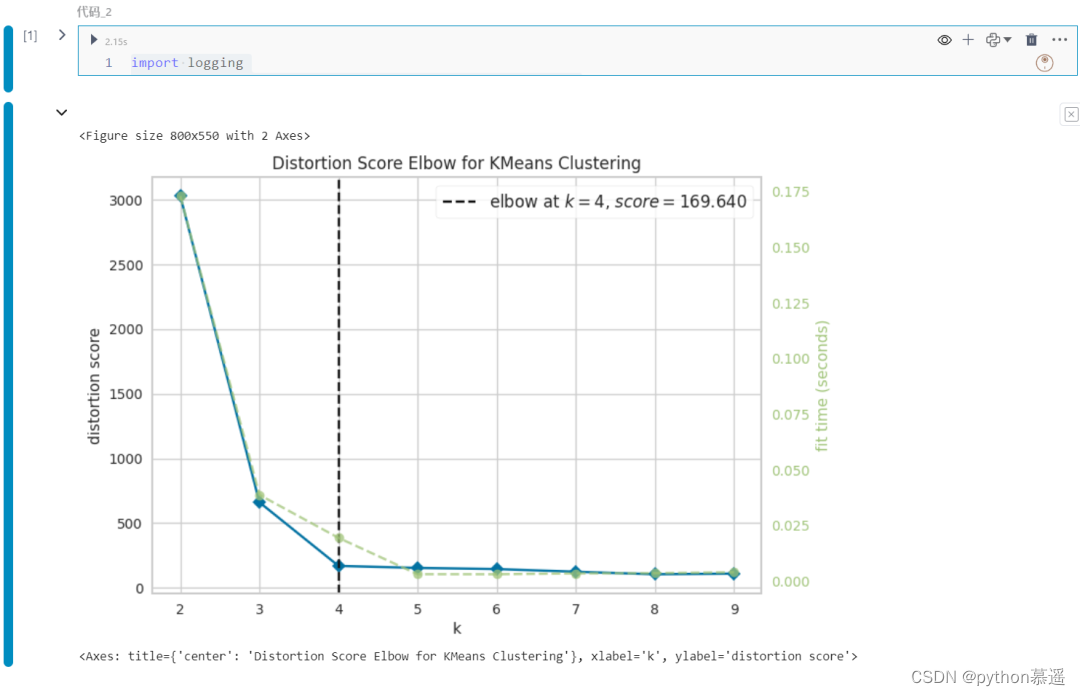
在可视化图表中清楚地看到最佳簇数为4,只需几行代码就可创建图表,操作简便、省时高效。
4.混淆矩阵(Confusion Matrix)
混淆矩阵有助于可视化分类模型的真正阳性、真正阴性、假阳性和假阴性预测。下面是分类模型的混淆矩阵:
from yellowbrick.classifier import ConfusionMatrix
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
classifier = SVC(kernel='linear')
classifier.fit(X_train, y_train)
visualizer = ConfusionMatrix(classifier)
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.show()
5.残差图(Residual Plot)
残差图有助于分析回归模型中预测值与实际值之间的差异。下面是回归模型的可视化残差图的示例:
from sklearn.datasets import make_regression
from sklearn.linear_model import LinearRegression
from yellowbrick.regressor import ResidualsPlot
X, y = make_regression(n_samples=100, n_features=1, noise=0.3, random_state=42)
model = LinearRegression()
visualizer = ResidualsPlot(model)
visualizer.fit(X, y)
visualizer.show()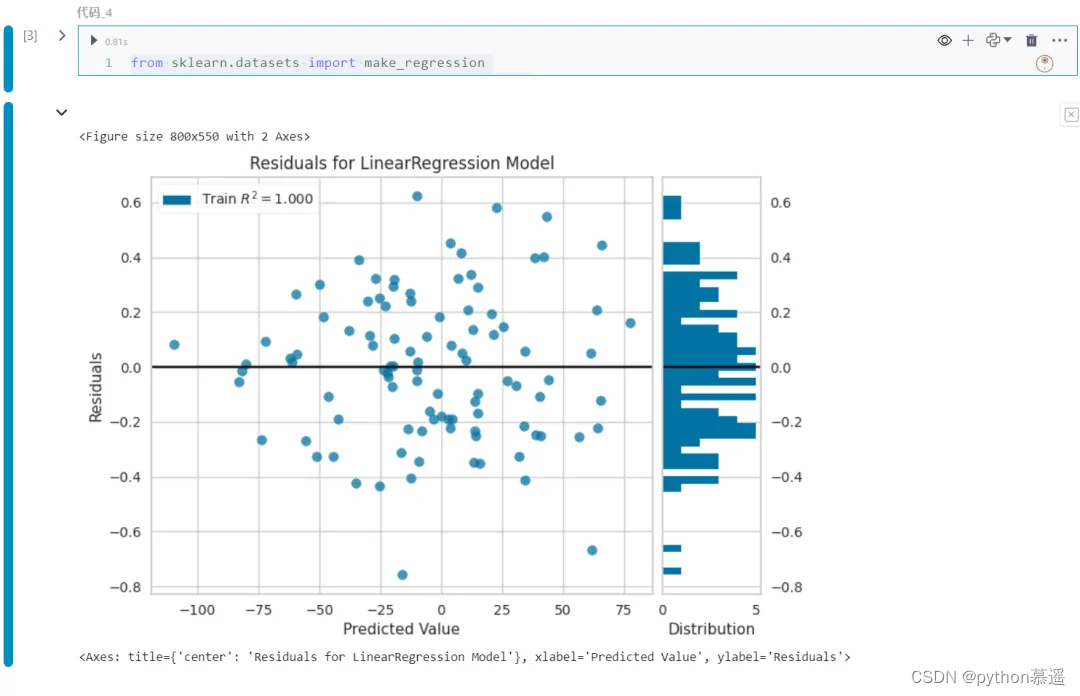
以上只展示了Yellowbrick的四个简单实例,Yellowbrick支持创建更多的图表和图形,以进行更全面的机器学习模型分析。










![[图解]产品经理创新之阿布思考法](https://img-blog.csdnimg.cn/direct/fde91235b2904b45b8b06208b7936eb7.png)