项目源码
已上传至githubCIFAR10Model,如果有帮助可以点个star
简介
在前文【Pytorch】10.CIFAR10模型搭建我们学习了用Module来模拟搭建CIFAR10的训练流程
本节将会加入损失函数,梯度下降,TensorBoard来完整搭建一个训练的模型
基本步骤
搭建神经网络最主要的流程是
- 导入数据集(包括训练集和测试集)
- 创建
DataLoader - 创建自定义的神经网络
- 选择损失函数与梯度下降算法
- 进行n轮训练
- n轮训练完成后通过测试集进行验证
- 引入
TensorBoard进行可视化 - 保存每轮训练好的模型
接下来将逐步拆解这每一个步骤
1.导入数据集
因为我们本文是要训练CIFAR10的模型,所以我们导入CIFAR10的数据集
# 1.创建训练数据集
train_dataset = torchvision.datasets.CIFAR10(root='../dataset', train=True, download=True,
transform=torchvision.transforms.ToTensor())
test_dataset = torchvision.datasets.CIFAR10(root='../dataset', train=False, download=True,
transform=torchvision.transforms.ToTensor())
# 记录数据集大小
train_size = len(train_dataset)
test_size = len(test_dataset)
分别导入训练集与测试集,并且分别记录训练集与测试集的大小
对参数的解释可以看【Pytorch】4.torchvision.datasets的使用这篇文章
2.创建DataLoader
DataLoader主要定义了如何在数据集中取数据的规则,具体讲解可以看【Pytorch】5.DataLoder的使用
# 2.创建dataloader
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=True)
3.创建自定义的神经网络
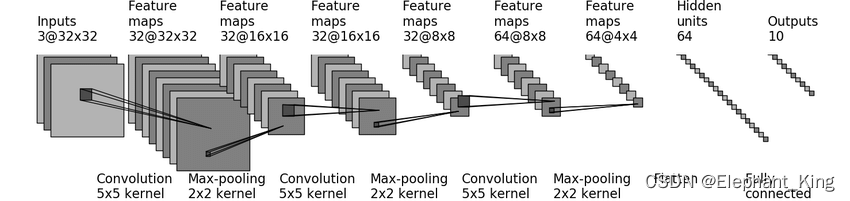
我们可以在网上搜到CIFAR10的网络模型,通过网络模型来搭建网络,具体可以看【Pytorch】10.CIFAR10模型搭建
import torch
from torch import nn
class CIFAR10Model(nn.Module):
def __init__(self):
super(CIFAR10Model, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 5, padding=2)
self.maxpool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(32, 32, 5, padding=2)
self.maxpool2 = nn.MaxPool2d(2, 2)
self.conv3 = nn.Conv2d(32, 64, 5, padding=2)
self.maxpool3 = nn.MaxPool2d(2, 2)
self.flatten = nn.Flatten()
self.fc1 = nn.Linear(1024, 64)
self.fc2 = nn.Linear(64, 10)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.fc1(x)
x = self.fc2(x)
return x
if __name__ == '__main__':
model = CIFAR10Model()
input_test = torch.ones((64, 3, 32, 32))
output_test = model(input_test)
print(output_test.shape)
这里我们新创建了一个model.py用于专门存储网络结构,这样在我们的训练文件中,可以通过
from model import *
# 3.创建神经网络
model = CIFAR10Model()
来导入我们自定义的神经网络
4.选择损失函数和梯度下降的方法
我们选择了交叉熵损失函数与SGD的梯度下降算法,具体讲解可以看【Pytorch】11.损失函数与梯度下降
# 4.设置损失函数与梯度下降算法
loss_fn = nn.CrossEntropyLoss()
learn_rate = 1e-2
optimizer = torch.optim.SGD(model.parameters(), lr=learn_rate)
5.开始进行训练
首先将模型设置为训练模式
model.train()
具体的训练流程分为以下几部
- 从DataLoader中获取图片以及对应的编号
- 将图片传入神经网络并获取输出
- 将优化器清零
- 计算损失函数
- 进行梯度下降
- 调用优化器进行更新
for data in train_loader:
# 训练基本流程
inputs, labels = data
outputs = model(inputs)
optimizer.zero_grad()
loss = loss_fn(outputs, labels)
loss.backward()
optimizer.step()
在基础训练的基础上,还安排了每进行100次训练就将训练数据print出来,并且写入tensorboard
# 第i轮训练次数加一
pre_train_step += 1
pre_train_loss += loss.item()
total_train_step += 1
# 每100次输出一下
if pre_train_step % 100 == 0:
end_train_time = time.time()
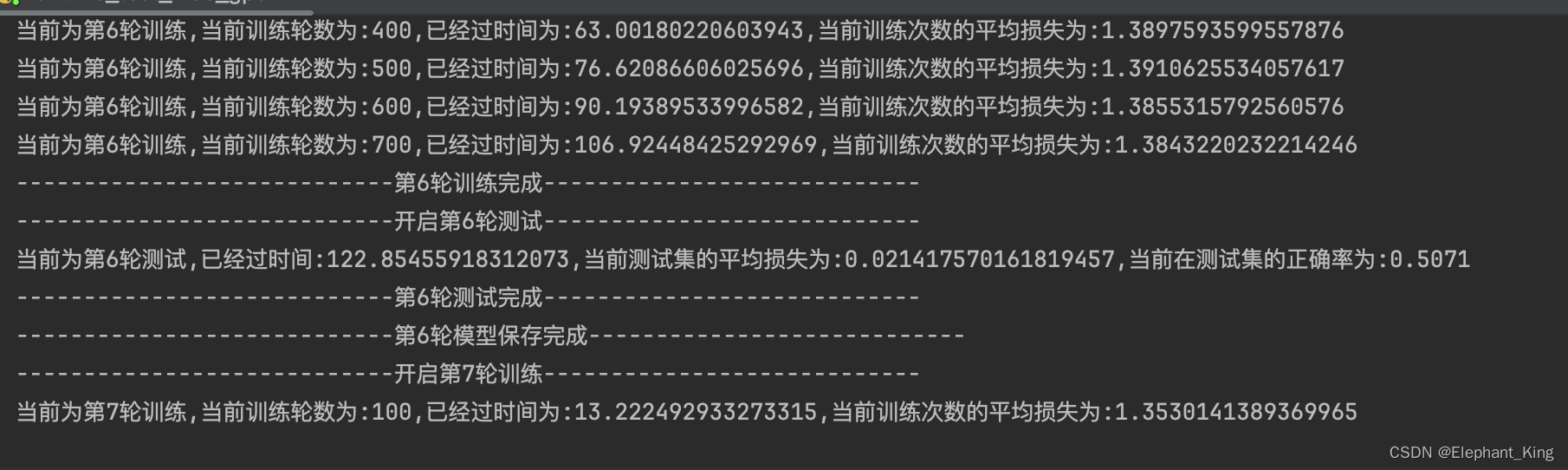
print(f'当前为第{i+1}轮训练,当前训练轮数为:{pre_train_step},已经过时间为:{end_train_time-start_time},当前训练次数的平均损失为:{pre_train_loss / pre_train_step}')
# 添加可视化
writer.add_scalar('train_loss', pre_train_loss / pre_train_step, total_train_step)
print(f"----------------------------第{i + 1}轮训练完成----------------------------")
6.测试集验证
首先将模型设置为测试集模式
model.eval()
首先通过with关键字来创建一个没有梯度的上下文
验证方法与训练集类似,但是没有计算梯度与更新优化器的步骤
with torch.no_grad():
for data in test_loader:
# 测试集流程
inputs, labels = data
outputs = model(inputs)
loss = loss_fn(outputs, labels)
然后通过torch.argmax用于计算所有标签的最大值
- 参数为1时代表横向判断
- 参数为0的代表纵向判断
计算当前模型在训练集中的正确次数
pre_accuracy += outputs.argmax(1).eq(labels).sum().item()
7.引入TensorBoard进行可视化
我们主要是通过Summary中的add_scalar来建立可视化函数来进行可视化的,具体可以看【Pytorch】2.TensorBoard的运用
# 创建TensorBoard
writer = SummaryWriter('./CIFAR10_logs')
# 在训练集中,输出每一百次训练的损失函数平均值
# 每100次输出一下
if pre_train_step % 100 == 0:
end_train_time = time.time()
print(f'当前为第{i+1}轮训练,当前训练轮数为:{pre_train_step},已经过时间为:{end_train_time-start_time},当前训练次数的平均损失为:{pre_train_loss / pre_train_step}')
# 添加可视化
writer.add_scalar('train_loss', pre_train_loss / pre_train_step, total_train_step)
# 在测试集中,输出模型在测试集中的正确率
pre_accuracy += outputs.argmax(1).eq(labels).sum().item()
writer.add_scalar('test_accuracy', pre_accuracy / test_size, i)
8.保存模型
具体可以看【Pytorch】12.网络模型的加载、修改与保存
# 保存每轮的训练模型
torch.save(CIFAR10Model, f'./CIFAR10TrainModel{i}.pth')
完整代码
import time
import torch
import torchvision.transforms
from torch.utils.tensorboard import SummaryWriter
from model import *
# 1.创建训练数据集
train_dataset = torchvision.datasets.CIFAR10(root='../dataset', train=True, download=True,
transform=torchvision.transforms.ToTensor())
test_dataset = torchvision.datasets.CIFAR10(root='../dataset', train=False, download=True,
transform=torchvision.transforms.ToTensor())
# 记录数据集大小
train_size = len(train_dataset)
test_size = len(test_dataset)
# 2.创建dataloader
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=True)
# 3.创建神经网络
model = CIFAR10Model()
# 4.设置损失函数与梯度下降算法
loss_fn = nn.CrossEntropyLoss()
learn_rate = 0.0001
optimizer = torch.optim.SGD(model.parameters(), lr=learn_rate)
# 训练轮数
total_train_step = 0
total_test_step = 0
# 训练轮数
epoch = 20
# 创建TensorBoard
writer = SummaryWriter('./CIFAR10_logs')
# 5.开始训练
for i in range(epoch):
# 将模型设置为训练模式
print(f"----------------------------开启第{i+1}轮训练----------------------------")
model.train()
# 第i轮训练的次数
pre_train_step = 0
# 第i轮训练的总损失
pre_train_loss = 0
# 第i轮训练的起始时间
start_time = time.time()
for data in train_loader:
# 训练基本流程
inputs, labels = data
outputs = model(inputs)
optimizer.zero_grad()
loss = loss_fn(outputs, labels)
loss.backward()
optimizer.step()
# 第i轮训练次数加一
pre_train_step += 1
pre_train_loss += loss.item()
total_train_step += 1
# 每100次输出一下
if pre_train_step % 100 == 0:
end_train_time = time.time()
print(f'当前为第{i+1}轮训练,当前训练轮数为:{pre_train_step},已经过时间为:{end_train_time-start_time},当前训练次数的平均损失为:{pre_train_loss / pre_train_step}')
# 添加可视化
writer.add_scalar('train_loss', pre_train_loss / pre_train_step, total_train_step)
print(f"----------------------------第{i + 1}轮训练完成----------------------------")
# 设置为测试模式
model.eval()
# 第i轮训练集的总损失
pre_test_loss = 0
# 第i轮训练集的总正确次数
pre_accuracy = 0
print(f"----------------------------开启第{i + 1}轮测试----------------------------")
# 配置没有梯度下降的环境
with torch.no_grad():
for data in test_loader:
# 测试集流程
inputs, labels = data
outputs = model(inputs)
loss = loss_fn(outputs, labels)
# 定义参数
pre_test_loss += loss.item()
# 记录训练集的总正确率
# argmax(1)代表横向判断,argmax(0)代表纵向判断
pre_accuracy += outputs.argmax(1).eq(labels).sum().item()
# 记录测试集运行完后的事件
end_test_time = time.time()
print(f'当前为第{i + 1}轮测试,已经过时间:{end_test_time - start_time},当前测试集的平均损失为:{pre_test_loss / test_size},当前在测试集的正确率为:{pre_accuracy / test_size}')
writer.add_scalar('test_accuracy', pre_accuracy / test_size, i)
print(f"----------------------------第{i + 1}轮测试完成----------------------------")
# 保存每轮的训练模型
torch.save(CIFAR10Model, f'./CIFAR10TrainModel{i}.pth')
print(f"----------------------------第{i + 1}轮模型保存完成----------------------------")
writer.close()
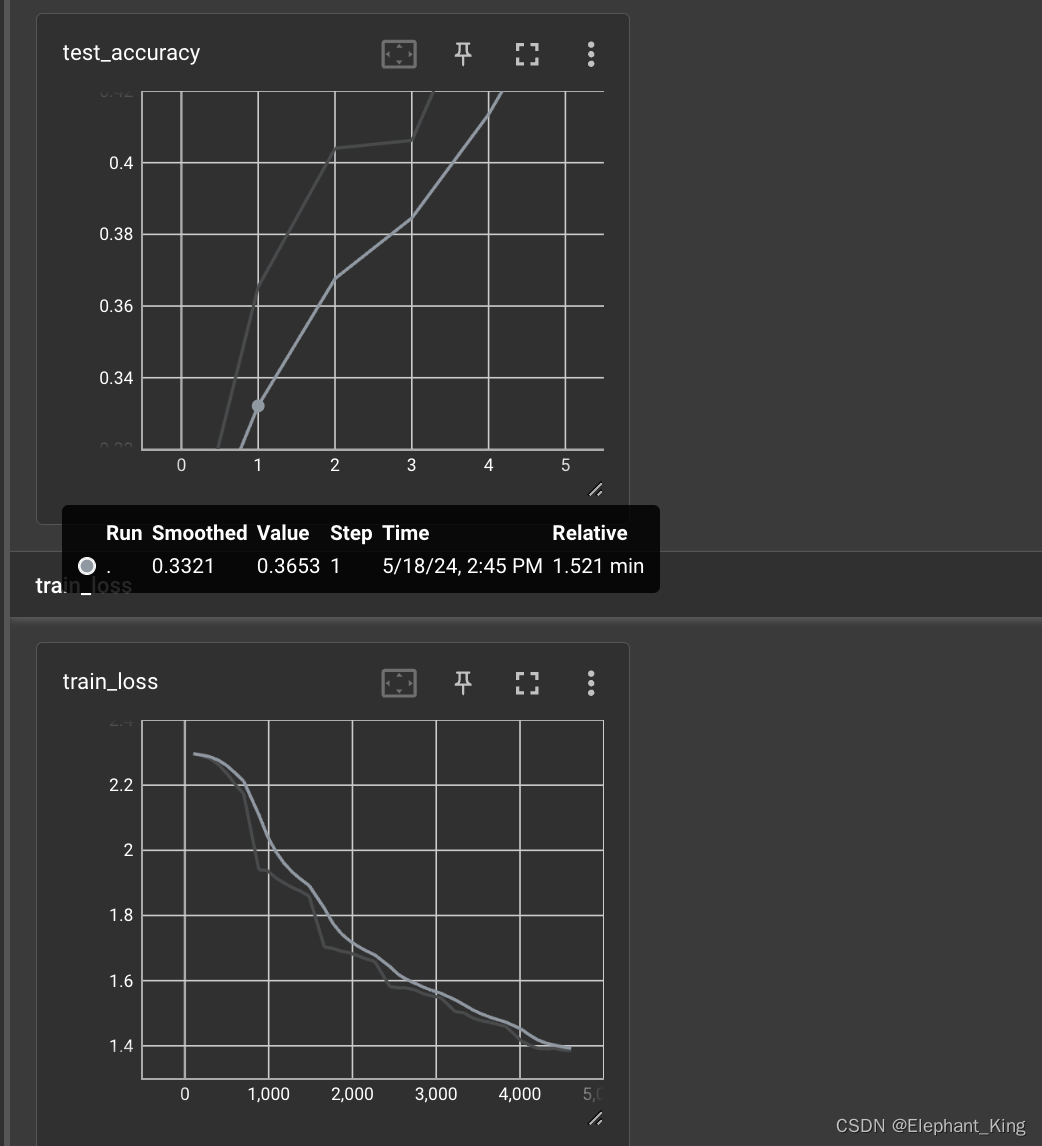
训练效果







![[Algorithm][动态规划][路径问题][下降路径最小和][最小路径和][地下城游戏]详细讲解](https://img-blog.csdnimg.cn/direct/73b23b2484314c249c3e961f5ac92650.png)