LSTM在股价数据集上的预测实战
- 使用完整的JPX赛题数据,并向大家提供完整的lstm流程。
导包
import numpy as np #数据处理
import pandas as pd #数据处理
import matplotlib as mlp
import matplotlib.pyplot as plt #绘图
from sklearn.preprocessing import MinMaxScaler #·数据预处理
from sklearn.metrics import mean_squared_error
import torch
import torch.nn as nn #导入pytorch中的基本类
from torch.autograd import Variable
from torch.utils.data import DataLoader, TensorDataset
import torch.optim as optim
import torch.utils.data as data
# typing 模块提供了一些类型,辅助函数中的参数类型定义
from typing import Union,List,Tuple,Iterable
from sklearn.preprocessing import LabelEncoder,MinMaxScaler
from decimal import ROUND_HALF_UP, Decimal
一、数据加载与处理
# 一、数据加载与处理
# 1、查看数据集信息
stock= pd.read_csv('stock_prices.csv') # (2332531,12)
stock_list = pd.read_csv('stock_list.csv') # (4417,16)
stock["SecuritiesCode"].unique().__len__() #2000支股票
# 2、为了效率我们抽取其中的10支股票
selected_codes = stock['SecuritiesCode'].drop_duplicates().sample(n=10)
stock = stock[stock['SecuritiesCode'].isin(selected_codes)] # (9833,12)
stock["SecuritiesCode"].unique().__len__() #只有10支股票了
stock.isnull().sum() #查看缺失值
# 3、预处理数据集
#将Target名字修改为Sharpe Ratio
stock.rename(columns={'Target': 'Sharpe Ratio'}, inplace=True)
#将Close列添加到最后
close_col = stock.pop('Close')
stock.loc[:,'Close'] = close_col
#填补Dividend缺失值、删除具有缺失值的行
stock["ExpectedDividend"] = stock["ExpectedDividend"].fillna(0)
stock.dropna(inplace=True)
#恢复索引
stock.index = range(stock.shape[0])
二、数据分割与数据重组
# 二、数据分割与数据重组
# 1、数据分割
train_size = int(len(stock) * 0.67)
test_size = len(stock) - train_size
train, test = stock[:train_size], stock[train_size:] # train (6580,12) test(3242,12)
# 2、带标签滑窗
def create_multivariate_dataset_2(dataset, window_size, pred_len): #
"""
将多变量时间序列转变为能够用于训练和预测的数据【带标签的滑窗】
参数:
dataset: DataFrame,其中包含特征和标签,特征从索引3开始,最后一列是标签
window_size: 滑窗的窗口大小
pred_len:多步预测的预测范围/预测步长
"""
X, y, y_indices = [], [], []
for i in range(len(dataset) - window_size - pred_len + 1): # (len-ws-pl+1) --> (6580-30-5+1) = 6546
# 选取从第4列到最后一列的特征和标签
feature_and_label = dataset.iloc[i:i + window_size, 3:].values # (ws,fs_la) --> (30,9)
# 下一个时间点的标签作为目标
target = dataset.iloc[(i + window_size):(i + window_size + pred_len), -1] # pred_len --> 5
# 记录本窗口中要预测的标签的时间点
target_indices = list(range(i + window_size, i + window_size + pred_len)) # pl*(len-ws-pl+1) --> 5*6546 = 32730
X.append(feature_and_label)
y.append(target)
#将每个标签的索引添加到y_indices列表中
y_indices.extend(target_indices)
X = torch.FloatTensor(np.array(X, dtype=np.float32))
y = torch.FloatTensor(np.array(y, dtype=np.float32))
return X, y, y_indices
# 3、数据重组
window_size = 30 #窗口大小
pred_len = 5 #多步预测的步数
X_train_2, y_train_2, y_train_indices = create_multivariate_dataset_2(train, window_size, pred_len) # x(6546,30,9) y(6546,5) (32730,)
X_test_2, y_test_2, y_test_indices = create_multivariate_dataset_2(test, window_size, pred_len) # x(3208,30,9) y(3208,5) (16040,)
三、网络架构与参数设置
# 三、网络架构与参数设置
# 1、定义架构
class MyLSTM(nn.Module):
def __init__(self,input_dim, seq_length, output_size, hidden_size, num_layers):
super().__init__()
self.lstm = nn.LSTM(input_size=input_dim, hidden_size=hidden_size, num_layers=num_layers, batch_first=True)
self.linear = nn.Linear(hidden_size, output_size)
def forward(self, x):
x, _ = self.lstm(x)
#现在我要的是最后一个时间步,而不是全部时间步了
x = self.linear(x[:,-1,:])
return x
# 2、参数设置
input_size = 9 #输入特征的维度
hidden_size = 20 #LSTM隐藏状态的维度
n_epochs = 2000 #迭代epoch
learning_rate = 0.001 #学习率
num_layers = 1 #隐藏层的层数
output_size = 5
#设置GPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
# 加载数据,将数据分批次
loader = data.DataLoader(data.TensorDataset(X_train_2, y_train_2), shuffle=True, batch_size=8)
# 3、实例化模型
model = MyLSTM(input_size, window_size, pred_len,hidden_size, num_layers).to(device)
optimizer = optim.Adam(model.parameters(),lr=learning_rate) #定义优化器
loss_fn = nn.MSELoss() #定义损失函数
loader = data.DataLoader(data.TensorDataset(X_train_2, y_train_2)
#每个表单内部是保持时间顺序的即可,表单与表单之间可以shuffle
, shuffle=True
, batch_size=8) #将数据分批次
四、实际训练流程
# 四、实际训练流程
# 初始化早停参数
early_stopping_patience = 3 # 设置容忍的epoch数,即在这么多epoch后如果没有改进就停止
early_stopping_counter = 0 # 用于跟踪没有改进的epoch数
best_train_rmse = float('inf') # 初始化最佳的训练RMSE
train_losses = []
test_losses = []
for epoch in range(n_epochs):
model.train()
for X_batch, y_batch in loader:
y_pred = model(X_batch.to(device))
loss = loss_fn(y_pred, y_batch.to(device))
optimizer.zero_grad()
loss.backward()
optimizer.step()
#验证与打印
if epoch % 10 == 0:
model.eval()
with torch.no_grad():
y_pred = model(X_train_2.to(device)).cpu()
train_rmse = np.sqrt(loss_fn(y_pred, y_train_2))
y_pred = model(X_test_2.to(device)).cpu()
test_rmse = np.sqrt(loss_fn(y_pred, y_test_2))
print("Epoch %d: train RMSE %.4f, test RMSE %.4f" % (epoch, train_rmse, test_rmse))
# 将当前epoch的损失添加到列表中
train_losses.append(train_rmse)
test_losses.append(test_rmse)
# 早停检查
if train_rmse < best_train_rmse:
best_train_rmse = train_rmse
early_stopping_counter = 0 # 重置计数器
else:
early_stopping_counter += 1 # 增加计数器
if early_stopping_counter >= early_stopping_patience:
print(f"Early stopping triggered after epoch {epoch}. Training RMSE did not decrease for {early_stopping_patience} consecutive epochs.")
break # 跳出训练循环
结果显示:
Epoch 0: train RMSE 1470.9308, test RMSE 1692.0652
Epoch 5: train RMSE 1415.7896, test RMSE 1639.1147
Epoch 10: train RMSE 1364.8196, test RMSE 1590.2207
......
Epoch 100: train RMSE 654.3458, test RMSE 904.7958
Epoch 105: train RMSE 638.2536, test RMSE 886.3511
Epoch 110: train RMSE 625.7336, test RMSE 870.9800
......
Epoch 200: train RMSE 598.3364, test RMSE 820.4078
Epoch 205: train RMSE 598.3354, test RMSE 820.3406
Epoch 210: train RMSE 598.3349, test RMSE 820.2874
......
Epoch 260: train RMSE 598.3341, test RMSE 820.1312
Epoch 265: train RMSE 598.3341, test RMSE 820.1294
Early stopping triggered after epoch 265. Training RMSE did not decrease for 3 consecutive epochs.
五、可视化结果
# 五、可视化结果
# 1、损失曲线
plt.figure(figsize=(10, 5))
plt.plot(train_losses, label='Train RMSE')
plt.plot(test_losses, label='Test RMSE')
plt.xlabel('Epochs')
plt.ylabel('RMSE')
plt.title('Train and Test RMSE Over Epochs')
plt.legend()
plt.show()
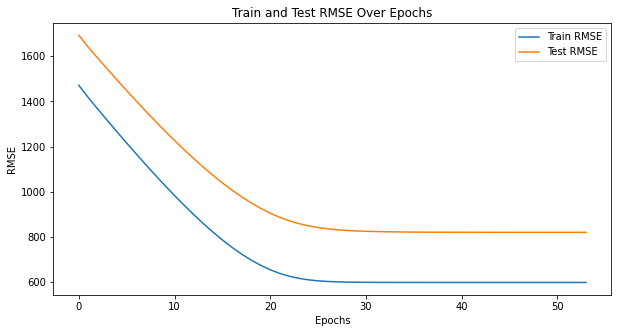
结果分析:预测效果不是很好,考虑进行数据预处理和特征工程
【扩展】股票数据的数据预处理与特征工程(后续更新~)