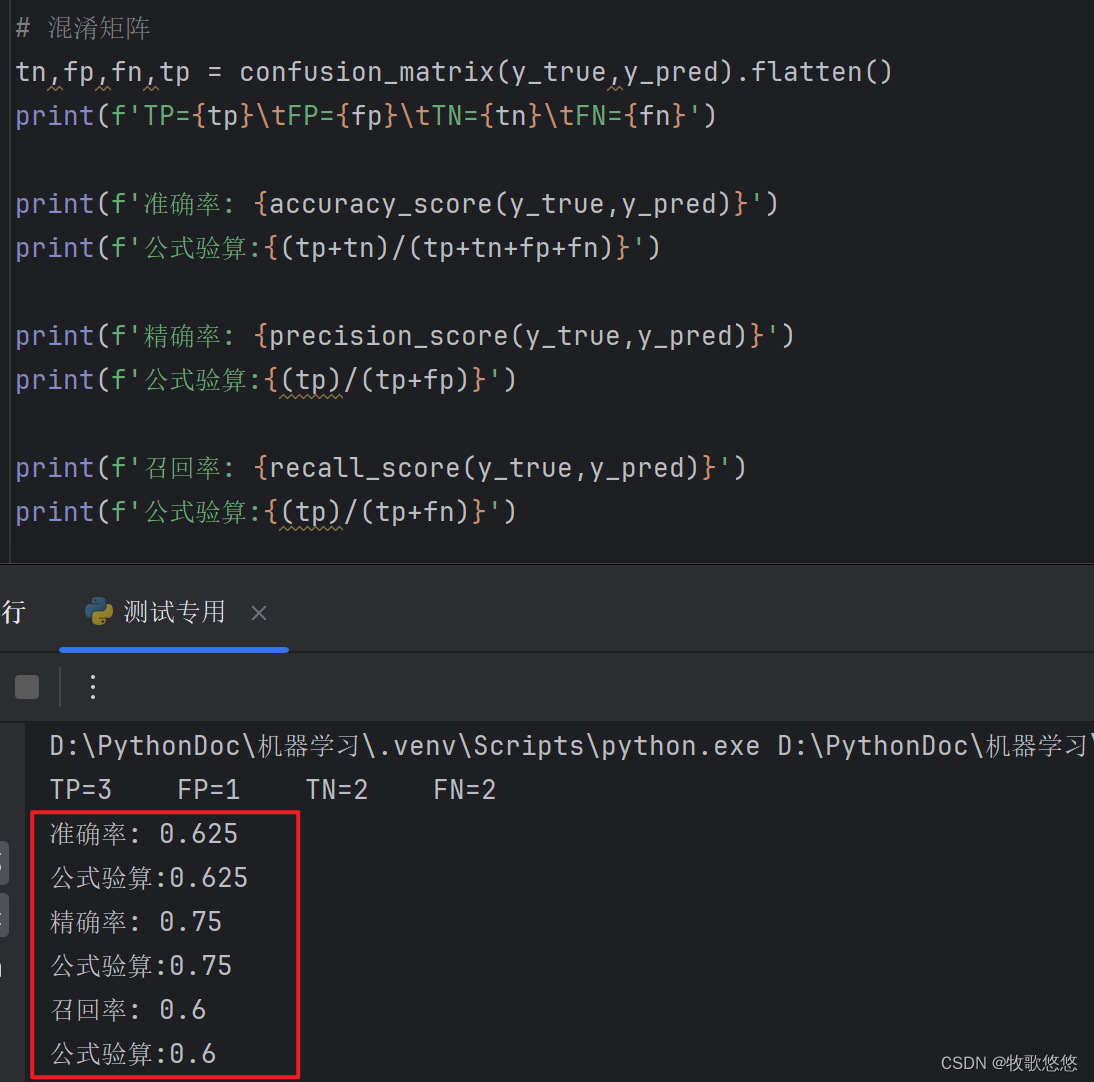
1. 克隆仓库
首先,克隆PySODEvalToolkit仓库到你的本地机器:
git clone https://github.com/lartpang/PySODEvalToolkit.git
2. 创建虚拟环境
cd PySODEvalToolkit
conda create -n pysodeval python=3.7
3. 安装依赖
pip install -r requirements.txt
4. 放置要参与评估的数据
在 PySODEvalToolkit 目录下创建 Data 文件夹,如下图所示,在其中创建要评估测试的数据集文件夹,这里我创建了 2 个 CHAMELEON 和 COD10K,然后 Test/GT/ 下面放的是 Ground Truth 二值图,Test/Mask/ 下面放的是模型预测的 mask 二值图
PySODEvalToolkit/
├── Data/
│ ├── CHAMELEON/
│ │ ├── Test/
│ │ │ ├── GT/
│ │ │ └── Mask/
│ ├── COD10K/
│ │ ├── Test/
│ │ │ ├── GT/
│ │ │ └── Mask/
│
├── config_dataset_json_example.json
├── config_method_json_example.json
├── eval.py
5. 修改数据配置文件
config_dataset_json_example.json 和 config_method_json_example.json 这两个文件,
config_dataset_json_example.json 里对不同数据集的ground truth图像进行配置
config_method_json_example.json 里是模型在不同数据集上预测的mask图像进行配置
修改 config_dataset_json_example.json
以 CHAMELEON 为例,在配置文件中添加如下内容,实际只读取 “mask” 部分的内容,“prefix” 是 Data/CHAMELEON/Test/GT/ 中所有图像文件名的共同前缀,“suffix” 则是共同后缀
"CHAMELEON": {
"image": {
"path": "Data/CHAMELEON/Test/GT",
"prefix": "animal-",
"suffix": ".png"
},
"mask": {
"path": "Data/CHAMELEON/Test/GT",
"prefix": "animal-",
"suffix": ".png"
}
}
修改 config_method_json_example.json
只评估 CHAMELEON 数据集的话,修改后的 config_method_json_example.json 文件内容如下,删除了 Method1,Method2,Method3,因为这里我只评估 SINetV2 这种方法在 CHAMELEON 数据集上的预测结果,如果要评估该方法在其他数据集上的预测结果,在该方法对应的方括号内按照 “CHAMELEON” 找猫画虎添加配置信息即可。
这里注意,新建"Method4",里面的名字替换成你要测试的模型方法,例如我要测SINetV2_2022,需要把 “Method4” 改成 “SINetV2_2022”,不然后面会报错。
{
"Method4": {
"CHAMELEON": {
"path": "Data/CHAMELEON/Test/Mask",
"prefix": "animal-",
"suffix": ".png"
}
}
}
正确的:
{
"SINetV2_2022": {
"CHAMELEON": {
"path": "Data/CHAMELEON/Test/Mask",
"prefix": "animal-",
"suffix": ".png"
}
}
}
6. 修改 yaml 文件 和 alias_for_plotting.json
alias_for_plotting.json 照猫画虎修改,添加 dataset 和 method
{
"dataset": {
"Name_In_Json": "Name_In_SubFigure",
"NJUD": "NJUD",
"NLPR": "NLPR",
"DUTRGBD": "DUTRGBD",
"STEREO1000": "SETERE",
"RGBD135": "RGBD135",
"SSD": "SSD",
"SIP": "SIP",
"CHAMELEON": "CHAMELEON"
},
"method": {
"Name_In_Json": "Name_In_Legend",
"GateNet_2020": "GateNet",
"MINet_R50_2020": "MINet",
"SINetV2_2022": "SINetV2"
}
}
converter_config.yaml 照猫画虎添加
dataset_names: [
'NJUD',
'NLPR',
'SIP',
'STEREO1000',
'SSD',
'LFSD',
'RGBD135',
'DUTRGBD',
'COD10K',
'CHAMELEON' // 添加测试数据集
]
# 使用单引号保证不被转义
method_names: {
'2020-ECCV-DANetV19': 'DANet$_{20}$',
'2020-ECCV-HDFNetR50': 'HDFNet$_{20}$',
'2022-AAAI-SSLSOD-ImageNet': 'SSLSOD$_{22}$',
'2022-TPAMI-SINetV2': 'SINetV2$_{22}$', // 添加了这一行
}
# 使用单引号保证不被转义
metric_names: {
'sm': '$S_{m}~\uparrow$',
'wfm': '$F^{\omega}_{\beta}~\uparrow$',
'mae': '$MAE~\downarrow$',
'adpf': '$F^{adp}_{\beta}~\uparrow$',
'avgf': '$F^{avg}_{\beta}~\uparrow$',
'maxf': '$F^{max}_{\beta}~\uparrow$',
'adpe': '$E^{adp}_{m}~\uparrow$',
'avge': '$E^{avg}_{m}~\uparrow$',
'maxe': '$E^{max}_{m}~\uparrow$',
}
rgbd_aliases.yaml 照猫画虎添加
dataset: {
"NJUD": "NJUD",
"NLPR": "NLPR",
"SIP": "SIP",
"STEREO1000": "STEREO1000",
"RGBD135": "RGBD135",
"SSD": "SSD",
"LFSD": "LFSD",
"DUTRGBD": "DUTRGBD",
"CHAMELEON": "CHAMELEON"
}
method: {
'2020-ECCV-DANetV19': 'DANet$_{20}$',
'2020-ECCV-HDFNetR50': 'HDFNet$_{20}$',
'2022-AAAI-SSLSOD-ImageNet': 'SSLSOD$_{22}$',
'2022-TPAMI-SINetV2': 'SINetV2$_{22}$'
}
7. 检测修改后的配置文件是否有问题
在修改完数据集配置文件和方法配置文件后,执行这个命令检查
python tools/check_path.py -m examples/config_method_json_example.json -d examples/config_dataset_json_example.json
如果正确配置的话会打印
examples/config_method_json_example.json &
examples/config_dataset_json_example.json 基本正常
如果未正确配置的话,会打印错误信息,
根据错误信息调试,如果提示 Data/CHAMELEON/Test/GT/ 和 Data/CHAMELEON/Test/Mask 文件名不匹配的话,首先检查这两个路径下的文件数量是否相同,前缀名和后缀名是否全部相同且json文件中是否正确配置。
如果确保Data/CHAMELEON/Test/GT/ 和 Data/CHAMELEON/Test/Mask 文件名是匹配的且json文件中也正确配置了,此时需要检查 check_path.py 文件中解析文件名的逻辑是否有问题,大概率是这里出错了,修改 check_path.py 添加调试打印信息根据输出进行排查。
8. 运行评估
运行评估脚本以计算评估指标和生成可视化图表:
python eval.py \
--dataset-json config_dataset_json_example.json \
--method-json config_method_json_example.json \
--metric-npy output/metrics.npy \
--curves-npy output/curves.npy \
--record-txt output/results.txt \
--record-xlsx output/results.xlsx \
--num-workers 4 \
--num-bits 3 \
--metric-names sm wfm mae fmeasure em \
--include-datasets datasettobeevaled \
--include-methods yourmethod
参数解释
--dataset-json:数据集配置文件的路径。--method-json:方法配置文件的路径,可以指定多个文件。--metric-npy:用于保存评估指标结果的.npy文件路径。--curves-npy:用于保存曲线结果的.npy文件路径。--record-txt:用于保存评估结果的.txt文件路径。--record-xlsx:用于保存评估结果的.xlsx文件路径。--num-workers:用于多线程或多进程的工作线程数,默认值为4。--num-bits:结果显示的小数位数,默认值为3。--metric-names:要计算的评估指标的名称列表。--include-datasets:要评估的特定数据集的名称。--include-methods:要评估的特定方法的名称。
执行命令时 --num-workers 和 --num-bits 可以省略,
然后我实际执行的eval命令语句是:
python eval.py --dataset-json examples/config_dataset_json_example.json
--method-json examples/config_method_json_example.json
--metric-npy output/metrics.npy
--curves-npy output/curves.npy
--record-txt output/results.txt
--record-xlsx output/results.xlsx
--metric-names sm wfm mae fmeasure em precision recall
--include-datasets CHAMELEON
--include-methods SINetV2_2022
执行该命令后评估的结果会自动创建并保存到这个目录下 PySODEvalToolkit/output ,可以看到,命令在 metric-names 中添加了 precision recall 指标,对SINetV2_2022 模型方法在 CHAMELEON 数据集的结果进行评估,如果要对多种模型方法在多个数据集的结果进行评估,空格并列添加就行,这里 --include-methods 中的方法名来自于 alias_for_plotting.json 中。
解释输出结果
运行脚本后,你将在指定的输出路径中找到结果文件:
metrics.npy:包含计算的评估指标结果的numpy数组。curves.npy:包含生成的曲线结果的numpy数组。results.txt:包含评估结果的文本文件。results.xlsx:包含评估结果的Excel文件。
这些文件将详细记录你的模型在 CHAMELEON 数据集上的性能,包括各种评估指标和可视化曲线。
9. 绘制曲线图
plot.py 脚本用于绘制评估曲线,例如 Fm 曲线和 PR 曲线。该脚本通过读取保存的 .npy 文件中的曲线数据,并使用指定的样式配置文件生成图像。
使用方法
参数说明
--alias-yaml:数据集和方法别名的 YAML 文件。--style-cfg:用于绘制曲线的 YAML 配置文件。--curves-npys:保存曲线结果的.npy文件。--our-methods:我们的方法的名称,用于突出显示。--num-rows:子图的行数。--num-col-legend:图例的列数。--mode:绘图模式,可以是pr、fm或em。--separated-legend:使用分离的图例。--sharey:使用共享的 y 轴。--save-name:导出文件路径。
示例用法
绘制的命令
python plot.py --style-cfg examples/single_row_style.yml
--num-rows 1
--curves-npys output/curves.npy
--mode em
--save-name output/simple_curve_em
--alias-yaml examples/rgbd_aliases.yaml
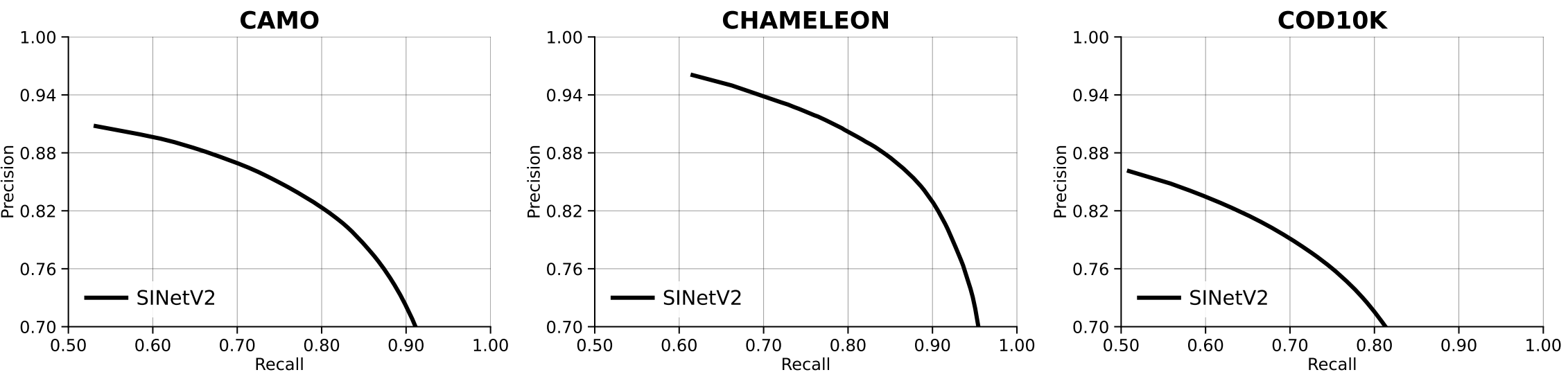
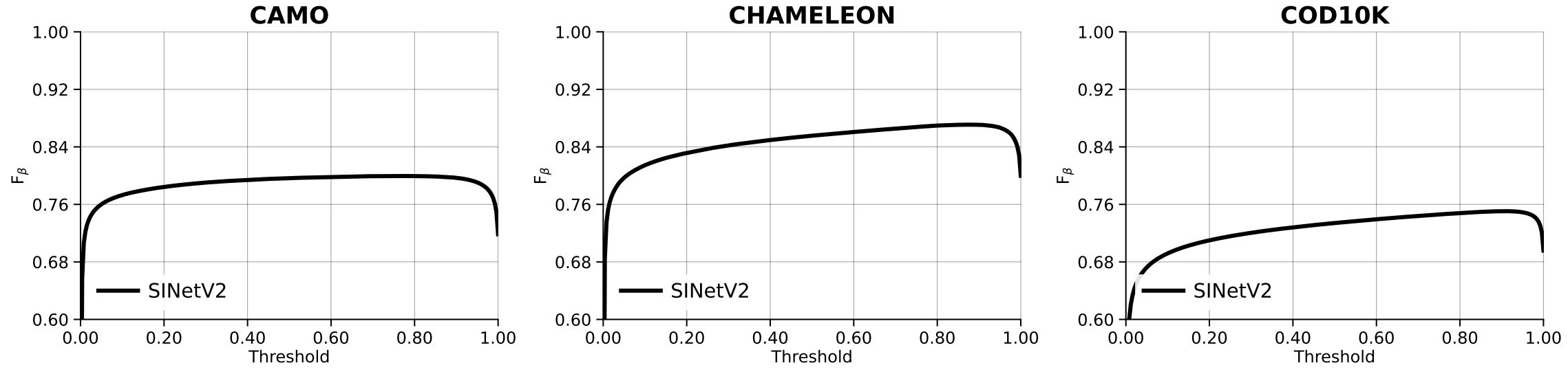
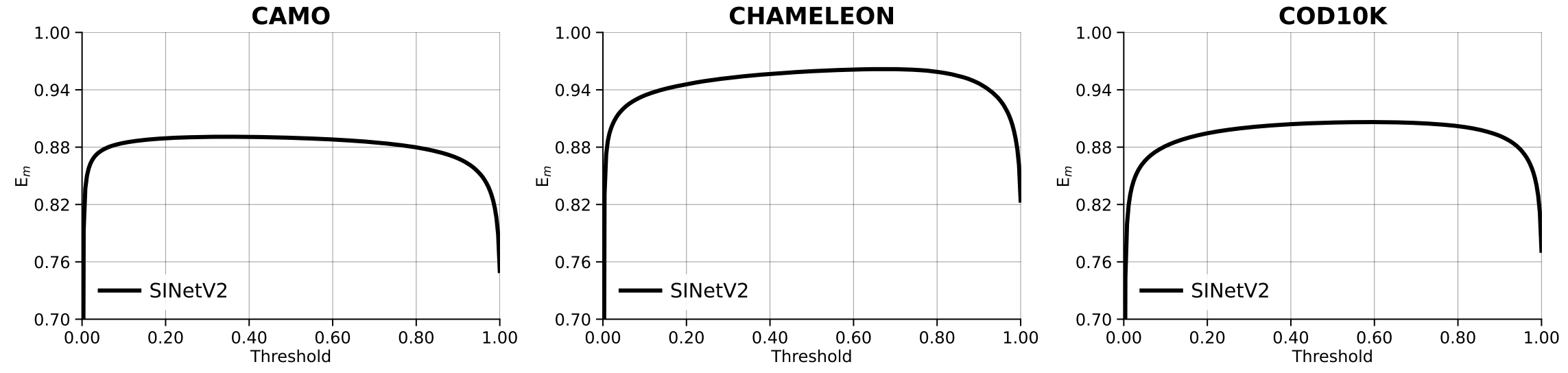
例如 output/simple_curve_em 会在 output 目录下生成 simple_curve_em.pdf 文件,该文件打开就是绘制的曲线图
参数详细说明
--curves-npys:指定一个或多个保存曲线结果的.npy文件,这些文件包含了曲线的数据。--style-cfg:指定用于绘图的样式配置文件,包含了 matplotlib 的配置,例如图例位置、字体大小等。--num-rows:指定生成图像的行数。--num-col-legend:指定图例的列数。--mode:指定绘图的模式,有三种选择:pr:绘制 Precision-Recall 曲线。fm:绘制 F-measure 曲线。em:绘制 E-measure 曲线。
--separated-legend:如果设置了这个选项,将使用分离的图例。--sharey:如果设置了这个选项,将使用共享的 y 轴。--save-name:指定保存图像的文件路径。
draw_curves 的使用
脚本的核心功能由 draw_curves.draw_curves 实现。以下是该函数的参数:
mode:绘图模式 (pr、fm或em)。axes_setting:不同曲线的绘图配置。curves_npy_path:包含曲线数据的.npy文件路径。row_num:子图的行数。method_aliases:方法的别名。dataset_aliases:数据集的别名。style_cfg:样式配置文件路径。ncol_of_legend:图例的列数。separated_legend:是否使用分离的图例。sharey:是否使用共享的 y 轴。our_methods:需要高亮显示的方法。save_name:保存图像的文件路径。
配置文件示例
single_row_style.yml 配置文件可能如下:
savefig.format: "png"
savefig.dpi: 300
savefig.bbox: "tight"
savefig.pad_inches: 0.1
axes.labelsize: 12
axes.titlesize: 14
xtick.labelsize: 10
ytick.labelsize: 10
legend.fontsize: 10
绘制图像的步骤
- 确保已经生成了包含曲线数据的
.npy文件。 - 准备好样式配置文件,例如
single_row_style.yml。 - 运行
plot.py,指定必要的参数。
总结
plot.py 脚本通过读取 .npy 文件中的曲线数据,并使用指定的样式配置文件生成图像。用户可以通过不同的参数控制生成图像的样式、子图的布局以及图例的配置。使用示例命令可以帮助用户快速上手绘制评估曲线。
10. 查看结果
评估结果和可视化图表将保存在配置文件中指定的save_dir目录中。
出现的问题
在修改完数据集配置文件和方法配置文件后,执行这个命令
python tools/check_path.py -m examples/config_method_json_example.json -d examples/config_dataset_json_example.json
出错提示:
(pysodeval) root@autodl-container-d9084da129-76991c4d:~/PySODEvalToolkit# python tools/check_path.py -m examples/config_method_json_example.json -d examples/config_dataset_json_example.json
Checking for Method1 ...
Traceback (most recent call last):
File "tools/check_path.py", line 30, in <module>
dataset_mask_info = datasets_info[dataset_name]["mask"]
KeyError: 'PASCAL-S'
解决方法:
在 examples/config_dataset_json_example.json 中添加
"PASCAL-S": {
"image": {
"path": "Path_Of_RGBDSOD_Datasets/PASCAL-S/Image",
"suffix": ".jpg"
},
"mask": {
"path": "Path_Of_RGBDSOD_Datasets/PASCAL-S/Mask",
"suffix": ".png"
}
},
"ECSSD": {
"image": {
"path": "Path_Of_RGBDSOD_Datasets/ECSSD/Image",
"suffix": ".jpg"
},
"mask": {
"path": "Path_Of_RGBDSOD_Datasets/ECSSD/Mask",
"suffix": ".png"
}
},
"HKU-IS": {
"image": {
"path": "Path_Of_RGBDSOD_Datasets/HKU-IS/Image",
"suffix": ".jpg"
},
"mask": {
"path": "Path_Of_RGBDSOD_Datasets/HKU-IS/Mask",
"suffix": ".png"
}
},
"DUT-OMRON": {
"image": {
"path": "Path_Of_RGBDSOD_Datasets/DUT-OMRON/Image",
"suffix": ".jpg"
},
"mask": {
"path": "Path_Of_RGBDSOD_Datasets/DUT-OMRON/Mask",
"suffix": ".png"
}
},
"DUTS-TE": {
"image": {
"path": "Path_Of_RGBDSOD_Datasets/DUTS-TE/Image",
"suffix": ".jpg"
},
"mask": {
"path": "Path_Of_RGBDSOD_Datasets/DUTS-TE/Mask",
"suffix": ".png"
}
}
之后重新执行,又出错:
Checking for Method1 ...
Checking for Method2 ...
Checking for Method3 ...
Checking for Method4 ...
Path_Of_Method1/PASCAL-S/DGRL 不存在
Path_Of_Method1/ECSSD/DGRL 不存在
Path_Of_Method1/HKU-IS/DGRL 不存在
Path_Of_Method1/DUT-OMRON/DGRL 不存在
Path_Of_Method1/DUTS-TE/DGRL 不存在
Path_Of_Method2/pascal 不存在
Path_Of_Method2/ecssd 不存在
Path_Of_Method2/hku 不存在
Path_Of_Method2/duto 不存在
Path_Of_Method2/dut_te 不存在
Path_Of_Method3/pascal 不存在
Path_Of_Method3/ecssd 不存在
Path_Of_Method3/hku 不存在
Path_Of_Method3/duto 不存在
Path_Of_Method3/dut_te 不存在
Data/COD10K/Test/Mask 中数据名字与真值 Data/COD10K/Test/GT 不匹配
解决办法:
把config_method_json_example.json下面这段代码删除掉可以解决掉不存在的报错,但是仍然存在数据名字不匹配的错误,
"Method1": {
"PASCAL-S": {
"path": "Path_Of_Method1/PASCAL-S/DGRL",
"prefix": "some_method_prefix",
"suffix": ".png"
},
"ECSSD": {
"path": "Path_Of_Method1/ECSSD/DGRL",
"prefix": "some_method_prefix",
"suffix": ".png"
},
"HKU-IS": {
"path": "Path_Of_Method1/HKU-IS/DGRL",
"prefix": "some_method_prefix",
"suffix": ".png"
},
"DUT-OMRON": {
"path": "Path_Of_Method1/DUT-OMRON/DGRL",
"prefix": "some_method_prefix",
"suffix": ".png"
},
"DUTS-TE": {
"path": "Path_Of_Method1/DUTS-TE/DGRL",
"suffix": ".png"
}
},
"Method2": {
"PASCAL-S": {
"path": "Path_Of_Method2/pascal",
"prefix": "pascal_",
"suffix": ".png"
},
"ECSSD": {
"path": "Path_Of_Method2/ecssd",
"prefix": "ecssd_",
"suffix": ".png"
},
"HKU-IS": {
"path": "Path_Of_Method2/hku",
"prefix": "hku_",
"suffix": ".png"
},
"DUT-OMRON": {
"path": "Path_Of_Method2/duto",
"prefix": "duto_",
"suffix": ".png"
},
"DUTS-TE": {
"path": "Path_Of_Method2/dut_te",
"prefix": "dut_te_",
"suffix": ".png"
}
},
"Method3": {
"PASCAL-S": {
"path": "Path_Of_Method3/pascal",
"prefix": "pascal_",
"suffix": "_fused_sod.png"
},
"ECSSD": {
"path": "Path_Of_Method3/ecssd",
"prefix": "ecssd_",
"suffix": "_fused_sod.png"
},
"HKU-IS": {
"path": "Path_Of_Method3/hku",
"prefix": "hku_",
"suffix": "_fused_sod.png"
},
"DUT-OMRON": {
"path": "Path_Of_Method3/duto",
"prefix": "duto_",
"suffix": "_fused_sod.png"
},
"DUTS-TE": {
"path": "Path_Of_Method3/dut_te",
"prefix": "dut_te_",
"suffix": "_fused_sod.png"
}
},
数据名字不匹配的错误原因是 check_path.py 文件中解析文件名的逻辑有问题:
修改后增加了打印调试信息的 check_path.py 代码:
# -*- coding: utf-8 -*-
import argparse
import json
import os
from collections import OrderedDict
parser = argparse.ArgumentParser(description="A simple tool for checking your json config file.")
parser.add_argument(
"-m", "--method-jsons", nargs="+", required=True, help="The json file about all methods."
)
parser.add_argument(
"-d", "--dataset-jsons", nargs="+", required=True, help="The json file about all datasets."
)
args = parser.parse_args()
for method_json, dataset_json in zip(args.method_jsons, args.dataset_jsons):
with open(method_json, encoding="utf-8", mode="r") as f:
methods_info = json.load(f, object_hook=OrderedDict) # 有序载入
with open(dataset_json, encoding="utf-8", mode="r") as f:
datasets_info = json.load(f, object_hook=OrderedDict) # 有序载入
total_msgs = []
for method_name, method_info in methods_info.items():
print(f"Checking for {method_name} ...")
for dataset_name, results_info in method_info.items():
if results_info is None:
continue
dataset_mask_info = datasets_info[dataset_name]["mask"]
mask_path = dataset_mask_info["path"]
mask_suffix = dataset_mask_info["suffix"]
dir_path = results_info["path"]
file_prefix = results_info.get("prefix", "")
file_suffix = results_info["suffix"]
if not os.path.exists(dir_path):
total_msgs.append(f"{dir_path} 不存在")
continue
elif not os.path.isdir(dir_path):
total_msgs.append(f"{dir_path} 不是正常的文件夹路径")
continue
else:
pred_names = [
name[len(file_prefix):-len(file_suffix)]
for name in os.listdir(dir_path)
if name.startswith(file_prefix) and name.endswith(file_suffix)
]
if len(pred_names) == 0:
total_msgs.append(f"{dir_path} 中不包含前缀为 {file_prefix} 且后缀为 {file_suffix} 的文件")
continue
mask_names = [
name[len(file_prefix):-len(mask_suffix)]
for name in os.listdir(mask_path)
if name.endswith(mask_suffix)
]
# 调试输出
print(f"Prefix: {file_prefix}")
print(f"Suffix: {file_suffix}")
print(f"Prediction names in {dir_path}: {pred_names}")
print(f"Ground truth mask names in {mask_path}: {mask_names}")
pred_names_set = set(pred_names)
mask_names_set = set(mask_names)
intersection_names = pred_names_set.intersection(mask_names_set)
if len(intersection_names) == 0:
total_msgs.append(f"{dir_path} 中数据名字与真值 {mask_path} 不匹配")
elif len(intersection_names) != len(mask_names):
difference_names = mask_names_set.difference(pred_names_set)
total_msgs.append(
f"{dir_path} 中数据({len(pred_names_set)})与真值({len(mask_names_set)})不一致: {difference_names}"
)
if total_msgs:
print(*total_msgs, sep="\n")
else:
print(f"{method_json} & {dataset_json} 基本正常")
重新检查配置文件后输出如下:
Checking for Method4 ...
Prefix: animal-
Suffix: .png
Prediction names in Data/CHAMELEON/Test/Mask: ['1', '10', '11', '12',
'13', '14', '15', '16', '17', '18', '19', '2', '20', '21', '22', '23',
'24', '25', '26', '27', '28', '29', '3', '30', '31', '32', '33', '34',
'35', '36', '37', '38', '39', '4', '40', '41', '42', '43', '44', '45',
'46', '47', '48', '49', '5', '50', '51', '52', '53', '54', '55',
'56', '57', '58', '59', '6', '60', '61', '62', '63', '64', '65',
'66', '67', '68', '69', '7', '70', '71', '72', '73', '74', '75',
'76', '8', '9']
Ground truth mask names in Data/CHAMELEON/Test/GT: ['1', '10', '11',
'12', '13', '14', '15', '16', '17', '18', '19', '2', '20', '21',
'22', '23', '24', '25', '26', '27', '28', '29', '3', '30', '31',
'32', '33', '34', '35', '36', '37', '38', '39', '4', '40', '41',
'42', '43', '44', '45', '46', '47', '48', '49', '5', '50', '51',
'52', '53', '54', '55', '56', '57', '58', '59', '6', '60', '61',
'62', '63', '64', '65', '66', '67', '68', '69', '7', '70', '71',
'72', '73', '74', '75', '76', '8', '9']
examples/config_method_json_example.json &
examples/config_dataset_json_example.json 基本正常
可以看到此时对比两个路径下文件名信息是匹配的。
绘制pr曲线时
Traceback (most recent call last):
File "plot.py", line 139, in <module>
main(args)
File "plot.py", line 133, in main
save_name=args.save_name,
File "/root/PySODEvalToolkit/metrics/draw_curves.py", line 71, in draw_curves
raise ValueError(f"{x} must be contained in\n{dataset_names_from_npy}")
ValueError: NJUD must be contained in
['CHAMELEON', 'CAMO', 'COD10K']
原因是 rgbd_aliases.yaml 中的数据集需要删掉这样部分,因为 plot.py 脚本尝试绘制的曲线数据集包含 NJUD,但实际提供的 .npy 文件中只有 CHAMELEON、CAMO 和 COD10K。删除掉 rgbd_aliases.yaml 中下面这些数据集
"NJUD": "NJUD",
"NLPR": "NLPR",
"SIP": "SIP",
"STEREO1000": "STEREO1000",
"RGBD135": "RGBD135",
"SSD": "SSD",
"LFSD": "LFSD",
"DUTRGBD": "DUTRGBD",
绘制的曲线是空白
首先确保 output/curves.npy 文件中确实包含了正确的数据。可以使用以下代码来查看 .npy 文件的内容:
在 PySODEvalToolkit 目录下创建一个 check_nyp.py 文件然后执行该脚本查看输出的数据
import numpy as np
data = np.load('output/curves.npy', allow_pickle=True).item()
print(data)
排查了半天才发现是 alias_for_plotting.json 和 rgbd_aliases.yaml 中 method 配置不匹配导致 提供的 method_aliases 中的方法别名与 curves.npy 文件中的方法名称不匹配。因为别名不匹配,target_unique_method_names 为空,所以没有绘制任何曲线。为了解决这个问题,首先确保 method_aliases 中的方法别名与 curves.npy 中的方法名称一致。修改如下
alias_for_plotting.json
{
"dataset": {
"Name_In_Json": "Name_In_SubFigure",
"NJUD": "NJUD",
"NLPR": "NLPR",
"DUTRGBD": "DUTRGBD",
"STEREO1000": "SETERE",
"RGBD135": "RGBD135",
"SSD": "SSD",
"SIP": "SIP",
"CAMO": "CAMO",
"CHAMELEON": "CHAMELEON",
"COD10K": "COD10K"
},
"method": {
"Name_In_Json": "Name_In_Legend",
"GateNet_2020": "GateNet",
"MINet_R50_2020": "MINet",
"SINetV2_2022": "SINetV2"
}
}
rgbd_aliases.yaml
dataset: {
"CAMO": "CAMO",
"CHAMELEON": "CHAMELEON",
"COD10K": "COD10K"
}
method: {
'2020-ECCV-DANetV19': 'DANet$_{20}$',
'2020-ECCV-HDFNetR50': 'HDFNet$_{20}$',
'2022-AAAI-SSLSOD-ImageNet': 'SSLSOD$_{22}$',
'SINetV2_2022': 'SINetV2'
}
然后执行 plot 就可以得到绘制的非空白曲线了!