wide&deep模型
- 1.简介
- 2.原理
- 2.1 网络结构
- 3. 稀疏密集特征
- 4.API和子类方式实现
1.简介
Wide and deep 模型是 TensorFlow 在 2016 年 6 月左右发布的一类用于分类和回归的模型,并应用到了 Google Play 的应用推荐中。wide and deep 模型的核心思想是结合线性模型的记忆能力(memorization)和 DNN 模型的泛化能力(generalization),在训练过程中同时优化 2 个模型的参数,从而达到整体模型的预测能力最优。
记忆(memorization)即从历史数据中发现item或者特征之间的相关性。
泛化(generalization)即相关性的传递,发现在历史数据中很少或者没有出现的新的特征组合。
相关论文链接
2.原理
2.1 网络结构
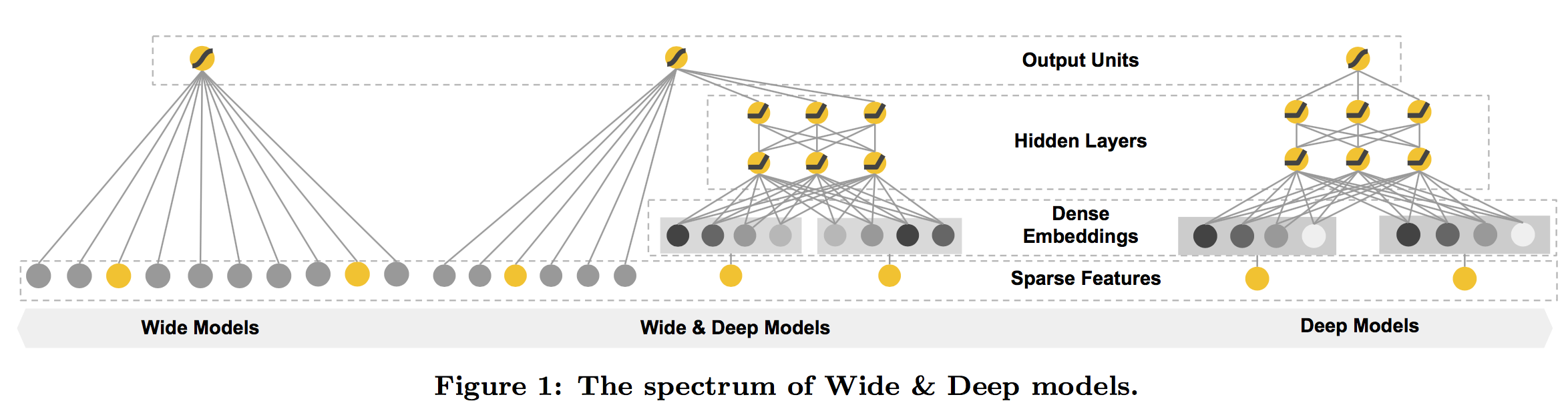
Wide & Deep 模型通过以下方式结合了 LR 和 DNN:
- 特征交叉:在 Wide 部分,可以显式地创建特征交叉项,这有助于模型学习特征间的组合效应。
- 共享嵌入:在 Deep 部分,可以使用嵌入层来学习稀疏特征(如类别特征)的低维表示,这些嵌入表示可以捕捉非线性关系。
- 联合训练:Wide 部分和 Deep 部分在模型的输出层之前进行合并,共享相同的输出,如预测概率。这样,两部分可以同时训练,共同学习。
- 权重平衡:通过正则化和超参数调整,可以平衡 Wide 部分和 Deep 部分对最终预测的贡献。
为什么可以看作 LR + DNN:
- 模型结构:Wide & Deep 模型的结构可以看作是将一个线性模型(LR)和一个深度学习模型(DNN)结合在一起。
- 学习特征:LR 部分负责学习线性特征和一阶交互,而 DNN 部分负责学习高阶非线性特征。
- 训练过程:在训练过程中,LR 和 DNN 部分可以独立更新,但最终的损失函数是联合的,这意味着它们共同贡献于模型的预测。
优点:
- 灵活性:结合了线性模型的解释性和深度学习的自动特征学习能力。
- 性能:在许多任务中,Wide & Deep 模型比单独使用 LR 或 DNN 表现更好。
- 泛化能力:通过结合两种类型的模型,可以提高对不同类型特征的泛化能力。
Wide & Deep 模型是一种强大的模型架构,适用于需要同时考虑线性关系和复杂非线性关系的任务,特别是在大规模的推荐系统和分类问题中。
3. 稀疏密集特征
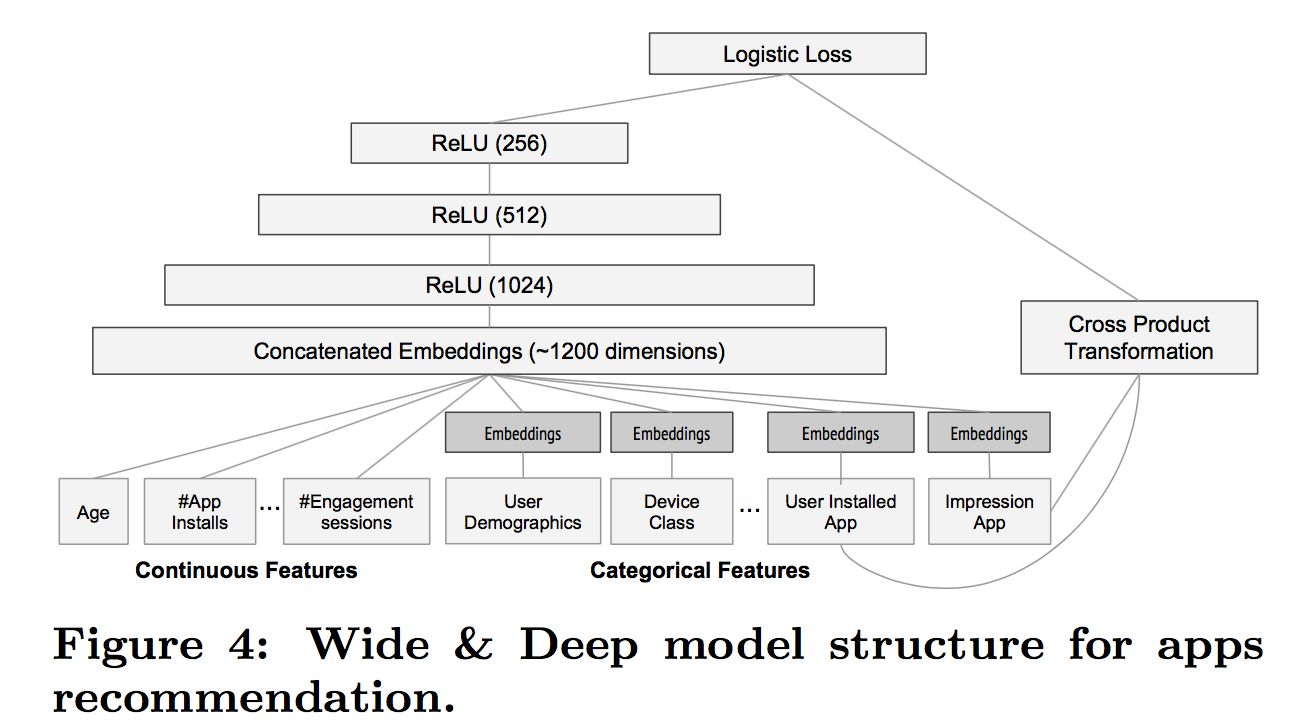
模型中把密集特征和做了one-hot 编码的稀疏特征拼接后作为 deep 模型的输入,Embeddings 表示one-hot 编码处理,把稀疏特征中的user installed App和 Impresson叉乘后作为wide模型的输入。
离散值特征:只能从N个值中选择一个,比如性别, 只能是男女
叉乘可以用来精确刻画样本, 实现记忆效果。
- 优点:
有效, 广泛用于工业界, 比如广告点击率预估(谷歌, 百度的主要业务), 推荐算法. - 缺点:
需要人工设计.
叉乘过度, 可能过拟合, 所有特征都叉乘, 相当于记住了每一个样本.
泛化能力差, 没出现过就不会起效果
密集特征:每个词都可以用一个密集向量表示, 那么词和词之间就可以计算距离
使用Word2vec工具可以方便的将词语转化为向量.
- 优点:
带有语义信息, 不同向量之间有相关性.
兼容没有出现过的特征组合.
更少人工参与 - 缺点:
过度泛化, 比如推荐不怎么相关的产品.
在机器学习和数据科学中,密集(Dense)和稀疏(Sparse)特征的联合使用可以带来多方面的好处,尤其是在处理现实世界的数据集时。以下是一些主要优点:
- 更全面的模型:密集特征通常表示连续的数值数据,而稀疏特征通常表示分类数据或离散值。将两者结合可以更全面地捕捉数据的不同方面。
- 特征交叉:在某些模型中,如宽深模型(Wide & Deep Model),可以显式地创建密集和稀疏特征的交叉项,这有助于模型学习更复杂的模式。
- 利用线性和非线性关系:密集特征可以通过线性模型(如逻辑回归)来学习数据中的线性关系,而稀疏特征可以通过深度学习模型来学习非线性关系。
- 提高模型性能:结合密集和稀疏特征可以帮助模型更好地泛化,提高模型在分类、回归或其他预测任务中的性能。
- 特征工程的灵活性:在特征工程过程中,可以灵活地选择和转换特征,以适应不同的模型需求。
稀疏数据的高效存储:稀疏特征通常使用特殊的数据结构(如稀疏矩阵)来存储,这可以显著减少内存使用并提高计算效率。 - 处理大规模数据集:在处理大规模数据集时,稀疏特征可以显著减少数据集的大小,使得模型训练更加高效。
- 更好的解释性:密集特征的线性模型通常更容易解释,而稀疏特征的非线性模型可以揭示数据中的复杂模式。两者的结合可以提供更好的模型解释性。
- 适应不同类型的数据:不同的数据集可能天然地包含密集或稀疏特征。通过联合使用,模型可以适应不同类型的数据。
- 提高推荐系统的效果:在推荐系统中,密集特征可以表示用户或物品的连续属性,而稀疏特征可以表示用户的分类偏好。结合两者可以提供更准确的推荐。
总之,密集和稀疏特征的联合使用可以使得模型更加健壮和灵活,能够处理更广泛的应用场景,并提高模型的整体性能。在实际应用中,选择合适的特征组合和模型架构是实现最佳效果的关键。
4.API和子类方式实现
使用tensorflow框架构建wide&deep模型参考代码:
# tensorflow写法1:函数式API
# 每一层结构都可以当成一个函数去使用.
input = keras.layers.Input(shape=x_train.shape[1:])
hidden1 = keras.layers.Dense(30, activation='relu')(input)
hidden2 = keras.layers.Dense(30, activation='relu')(hidden1)
# wide和deep模型用相同的输入数据
concat = keras.layers.concatenate([input, hidden2])
output = keras.layers.Dense(1)(concat)
# 包装成一个model
model = keras.models.Model(inputs=[input], outputs=output)
# tensorflow写法2:子类api
class WideDeepModel(keras.models.Model):
def __init__(self):
"""定义模型的层次"""
super().__init__()
self.hidden1 = keras.layers.Dense(30, activation='relu')
self.hidden2 = keras.layers.Dense(30, activation='relu')
self.output_layer = keras.layers.Dense(1)
def call(self, input):
"""完成模型的正向传播"""
hidden1 = self.hidden1(input)
hidden2 = self.hidden2(hidden1)
# 拼接
concat = keras.layers.concatenate([input, hidden2])
output = self.output_layer(concat)
return outpu
model = WideDeepModel()
# 或者使用keras构造一个model
# model = keras.Sequential([WideDeepModel(),])
# 使用两种方式model构造好后构造并查看model结构
model.build(input_shape=(None, 8))
model.summary()