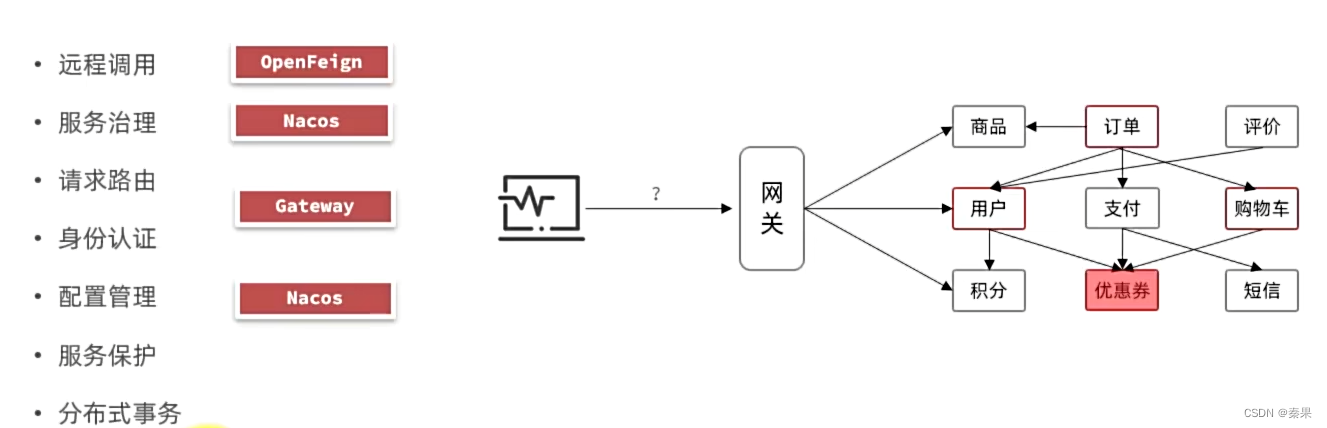
一、微服务保护
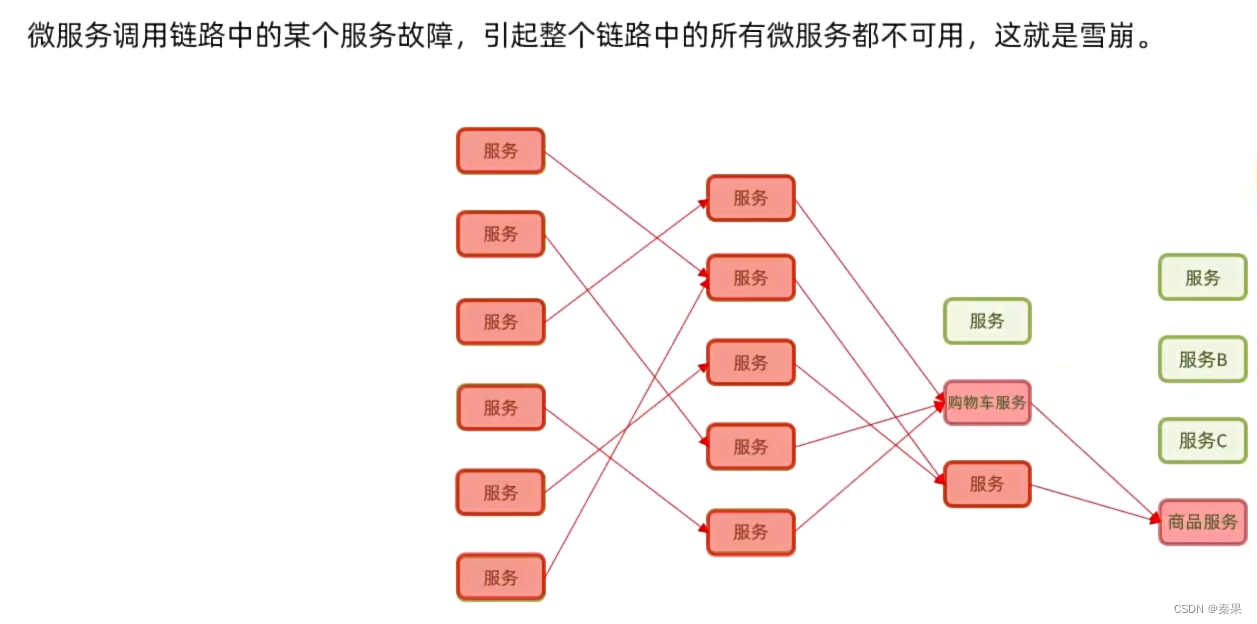
1.雪崩问题

如何做好后备方案就是后续:
2.雪崩解决方案


某一个服务的线程是固定的,出现故障线程占满后,就不会让取调用这个服务,对其他服务就没有影响。



3.Sentinel
①初识Sentinel

配置过程:
day05-服务保护和分布式事务 - 飞书云文档 (feishu.cn)
先搭建sentinel,下载Jar包cmd运行,访问网页控制台;
再项目引入依赖,配置地址。
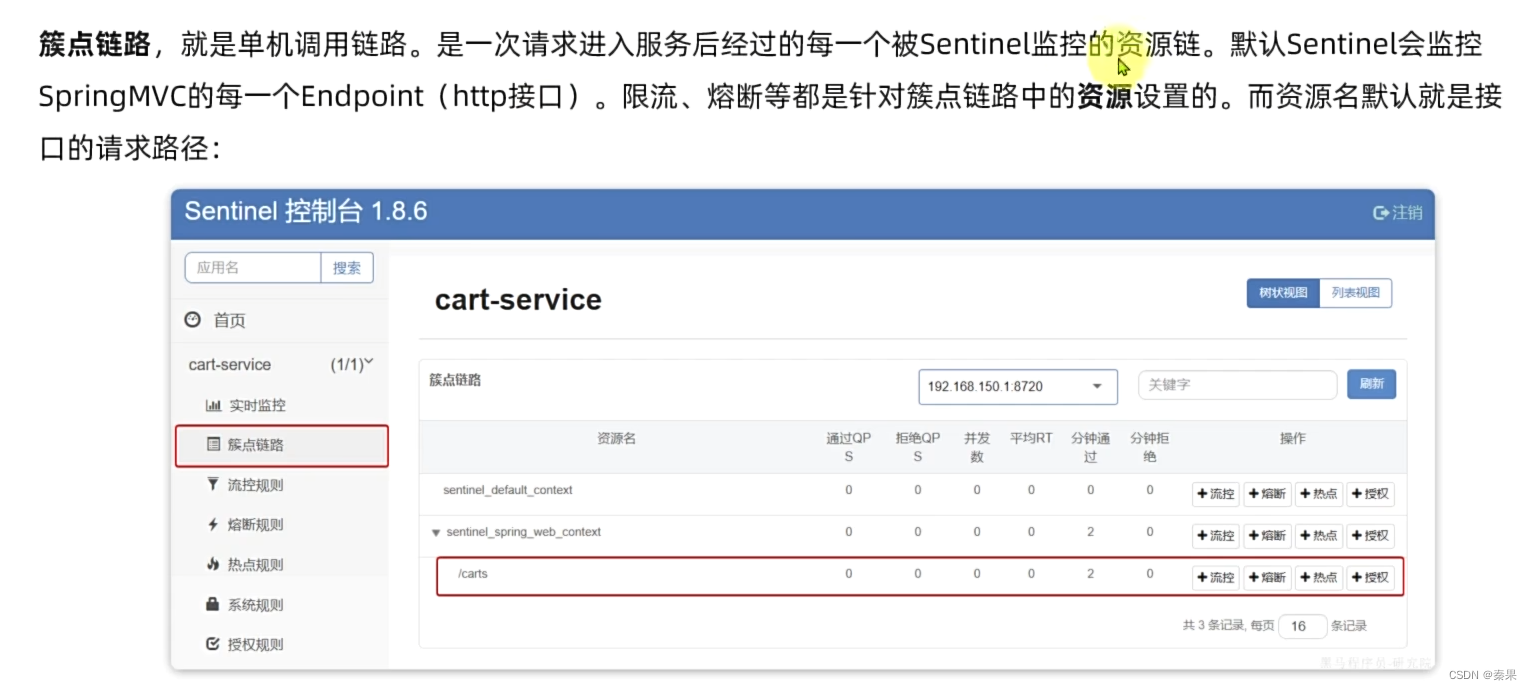

这样设置后就会根据请求方式和请求路径监控接口:比如这里Get,Put是相同路径不同请求方式,也被监控到了
②请求限流
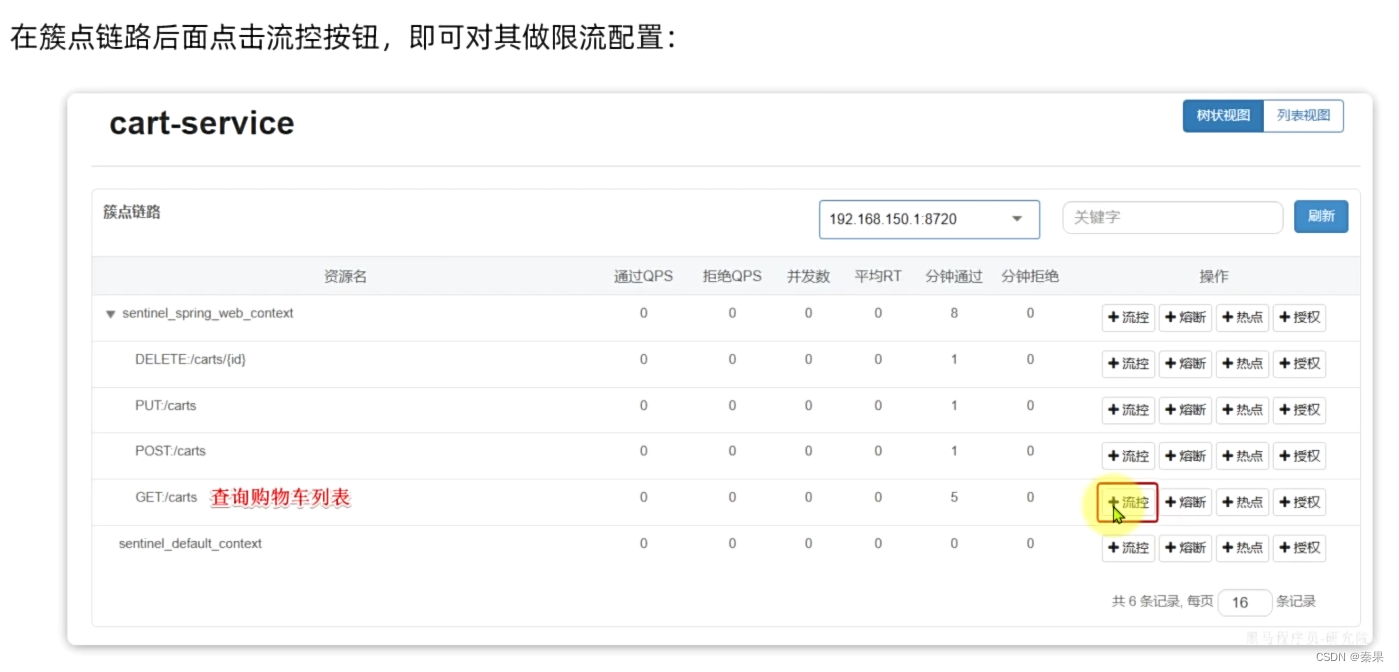

QPS每秒钟请求的数量
填好后就可以限流了:
③线程隔离

在购物车功能中,如果不设置线程隔离,当查询购物车功能并发高了耗尽TomCat资源后,修改购物车商品数量也会收到影响。设置查询购物车功能的并发线程数后,查询不行,但修改不影响。
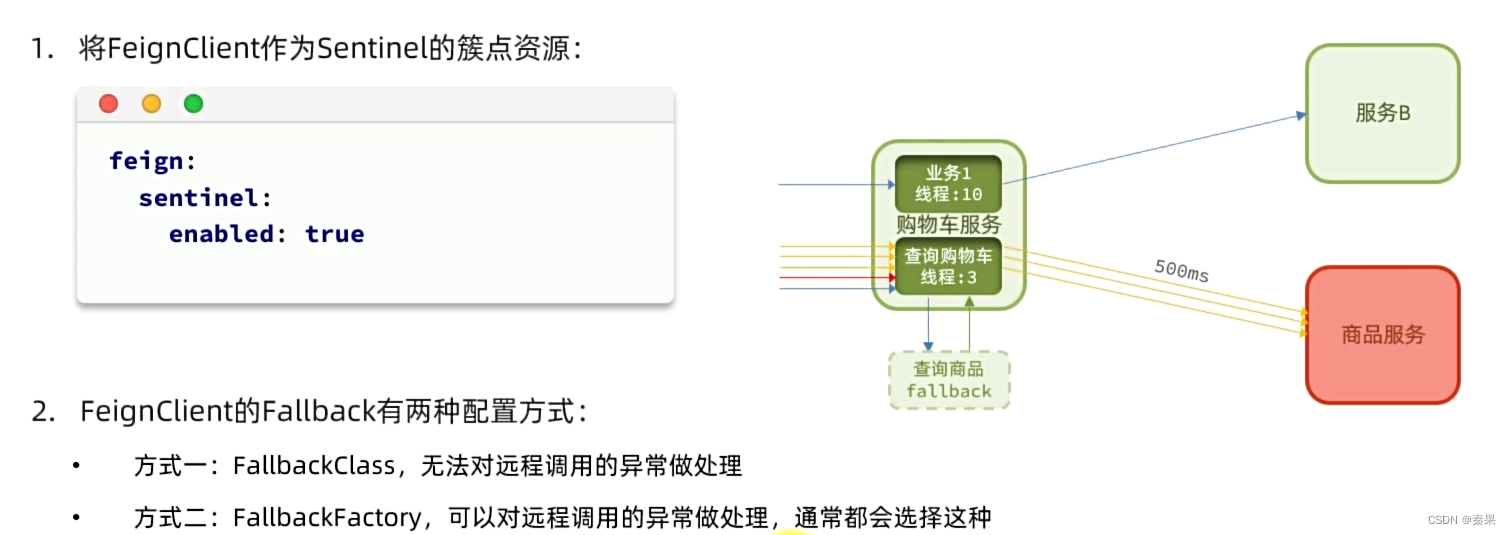
④Fallback
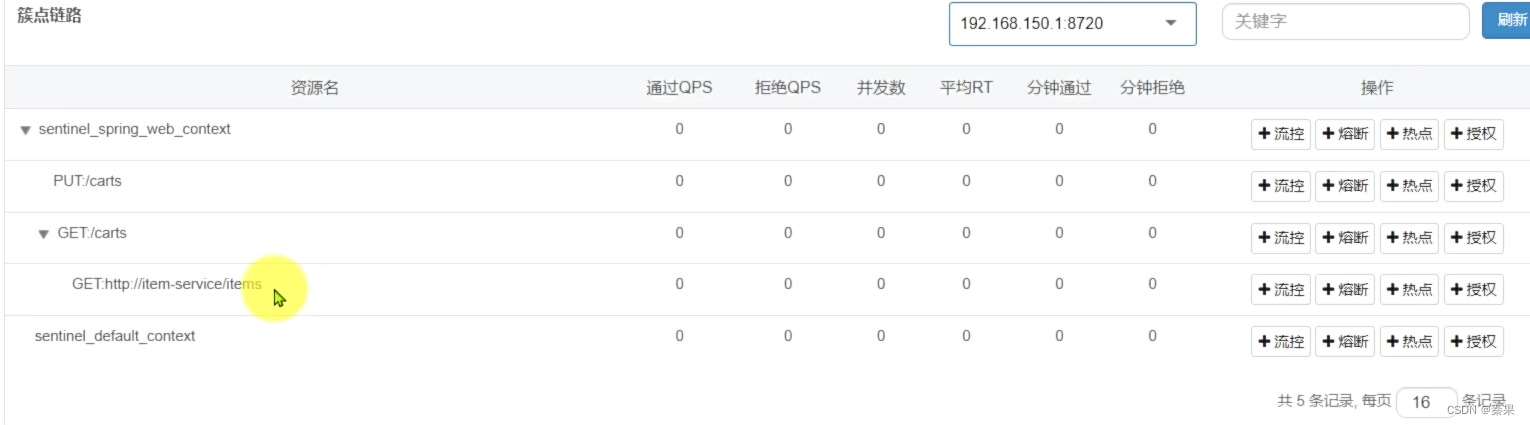
设置enabled为true后就会看到carts产生了子路簇点
采用方式二


⑤服务熔断
熔断就是根据异常比例,慢请求比例,达到一定值就会拒绝去到fallback

切换熔断或者不熔断的原理

响应超过最大RT就是慢比例,熔断时长是熔断时间多久,最小请求数是请求多少次看比例是否达到,统计时长就是最小请求数在这个时间范围内

二、分布式事务
1.认识分布式事务
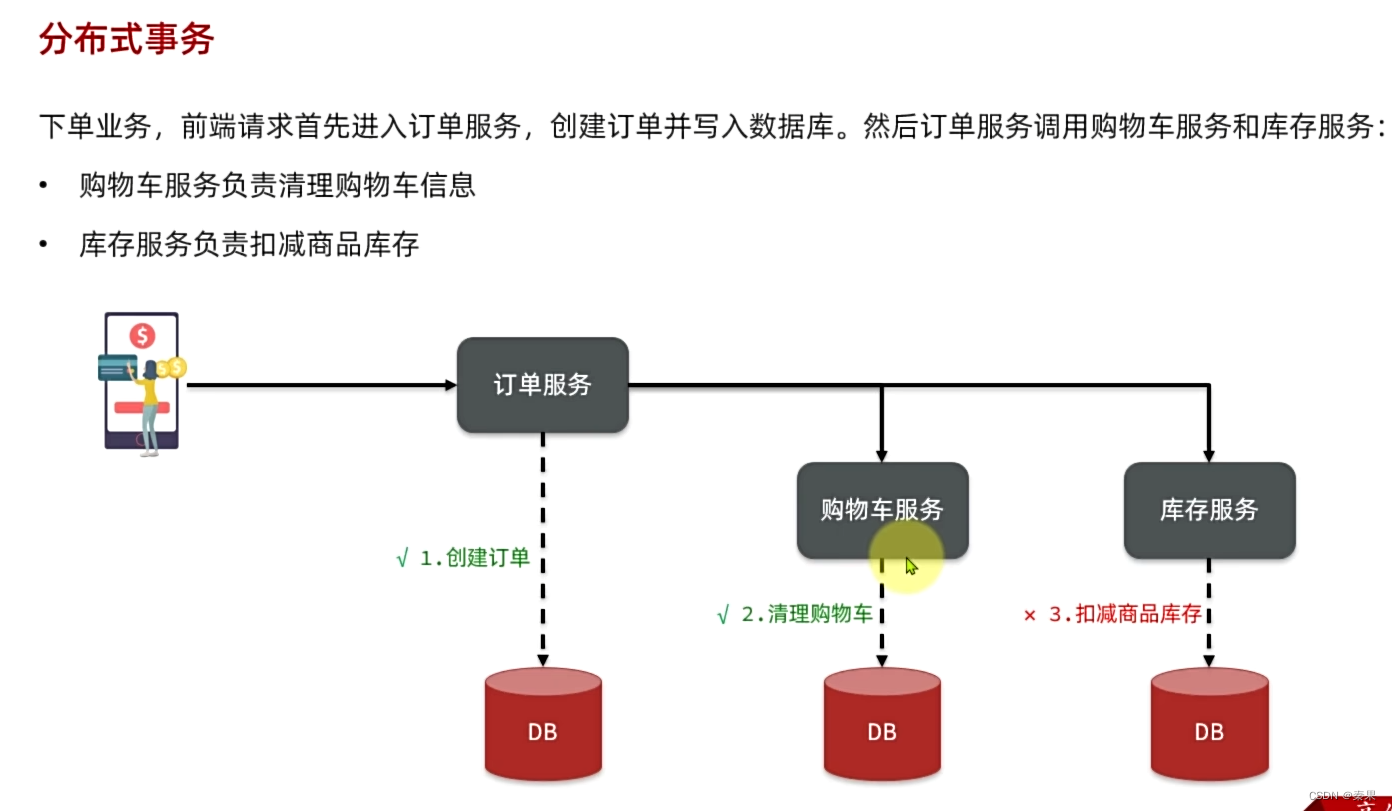

2.Seata

分布式事务解决思路
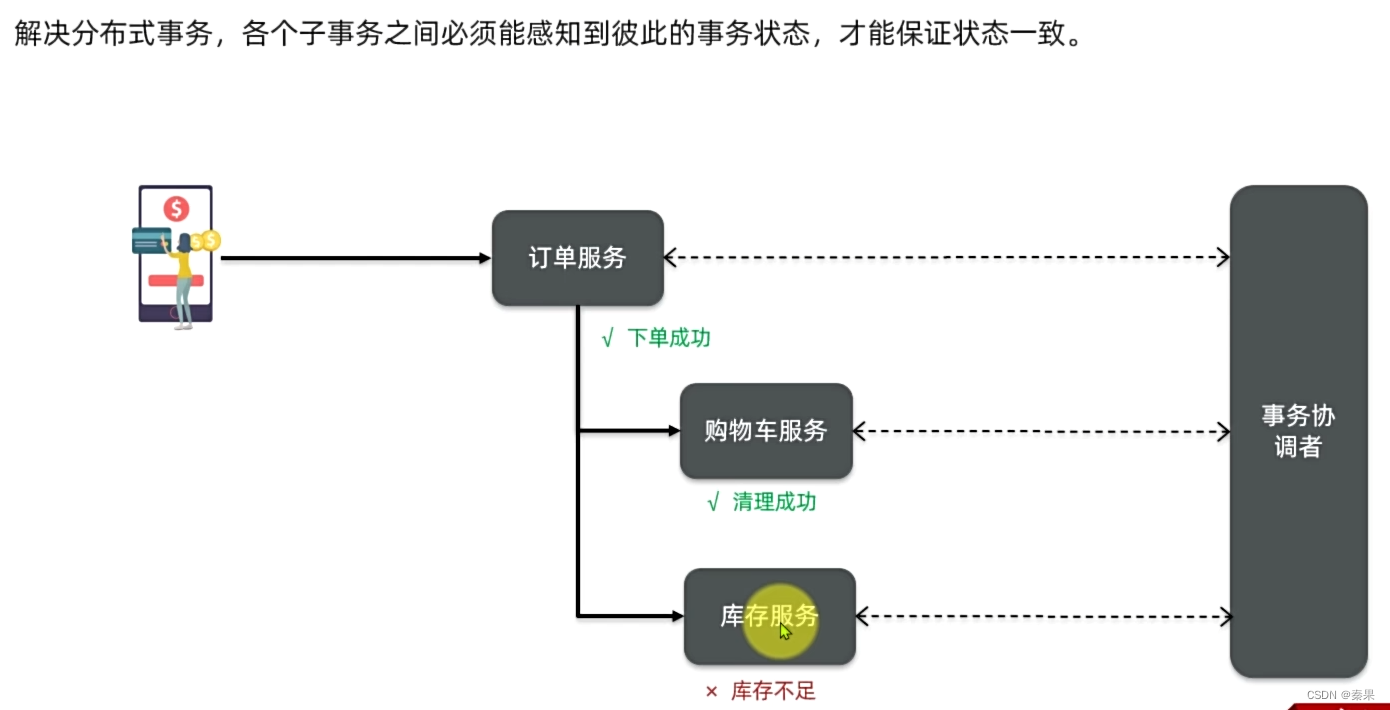
TM会告诉TC全局事务开始和结束,到结束RM会报告状态,只有全部正常才会提交

3.部署TC服务
day05-服务保护和分布式事务 - 飞书云文档 (feishu.cn)
部署需要准备tc数据库,准备配置文件,然后下载镜像,docker再部署
4.微服务集成Seata

由于Seata不知道你是否是Spring项目,就必须根据nacos一个服务放置规则去写配置,来找到TC服务地址

将这个配置文件发布到nacos
然后让需要分布式事务的微服务拉取这个共享配置

引入依赖:
5.XA模式
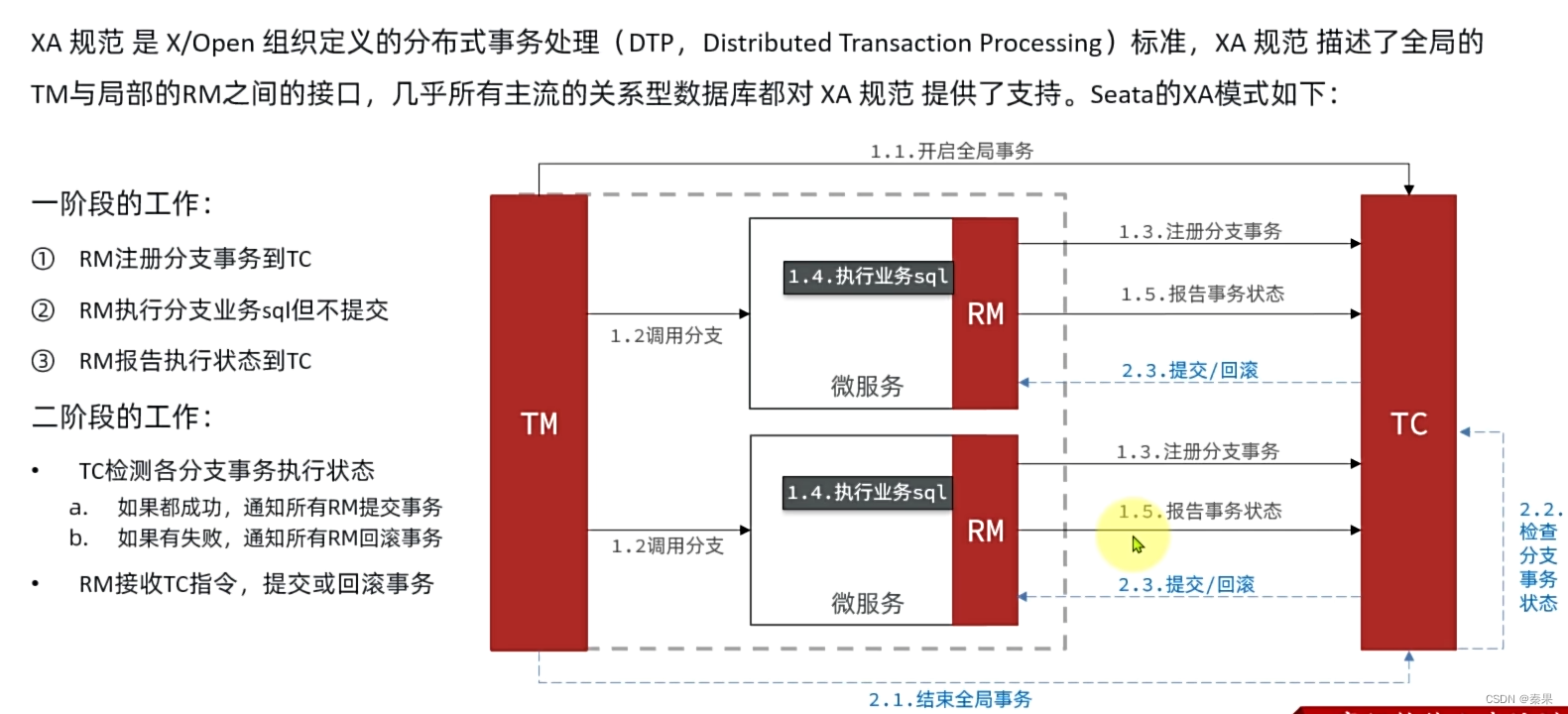
sql等待提交会有性能的问题

修改配置,这个配置在nacos中

6.AT模式
是直接提交,但是在提交前会快照,保存提交前的数据库内容,如果失败从快照中回滚
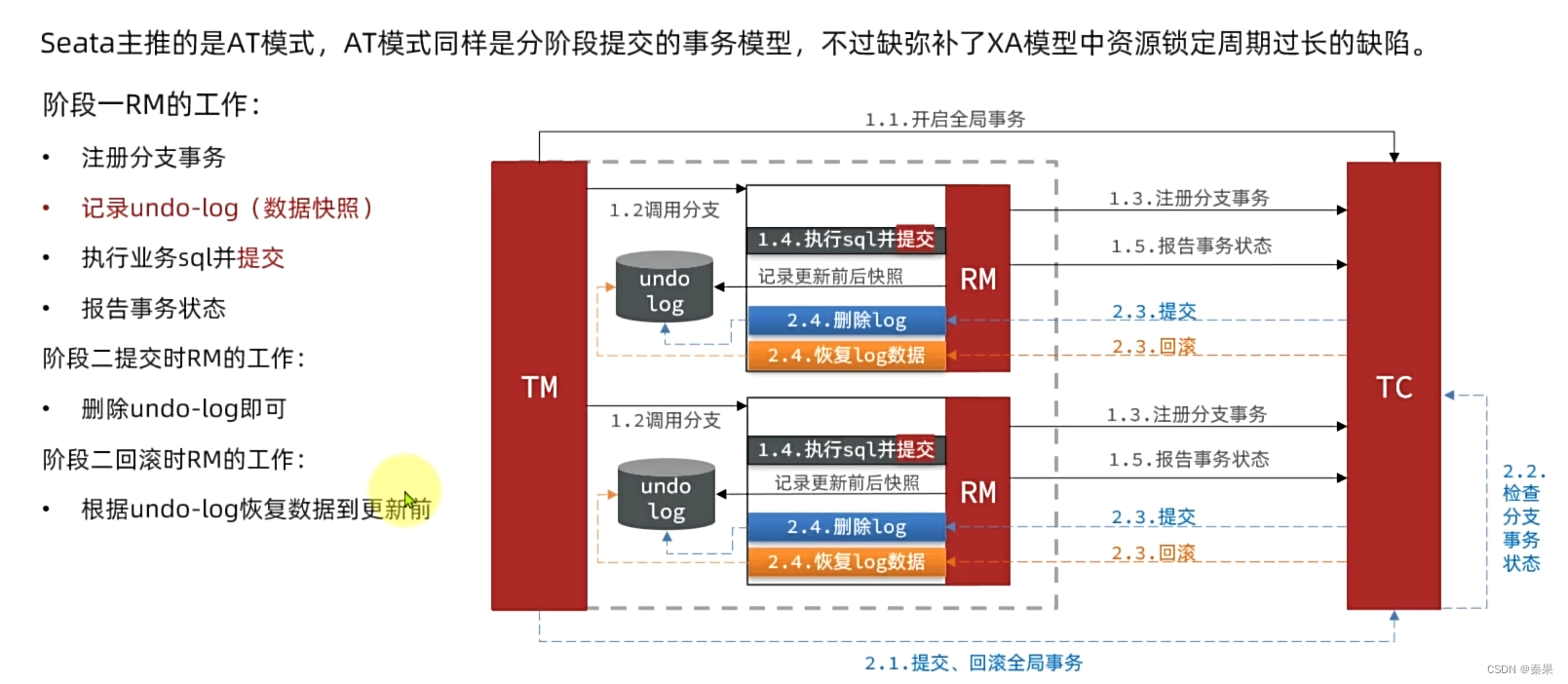
会出现短暂的数据不一致,在回滚前

实现步骤:

添加注释在前面已经加了
三、RabbitMQ

同步通信,要一步一步等待上一步完成才能开始
1.初识MQ
①同步调用

同步调用存在一些问题
这里用户服务扣减余额到下面的服务应该得同步调用,只有扣减余额成功才能有后续操作,后续操作的前提都是只要余额扣除成功就可以执行,所以应该都异步调用,让他们可以一起工作。
②异步调用

发送者发送消息交给消息代理就可以不管了
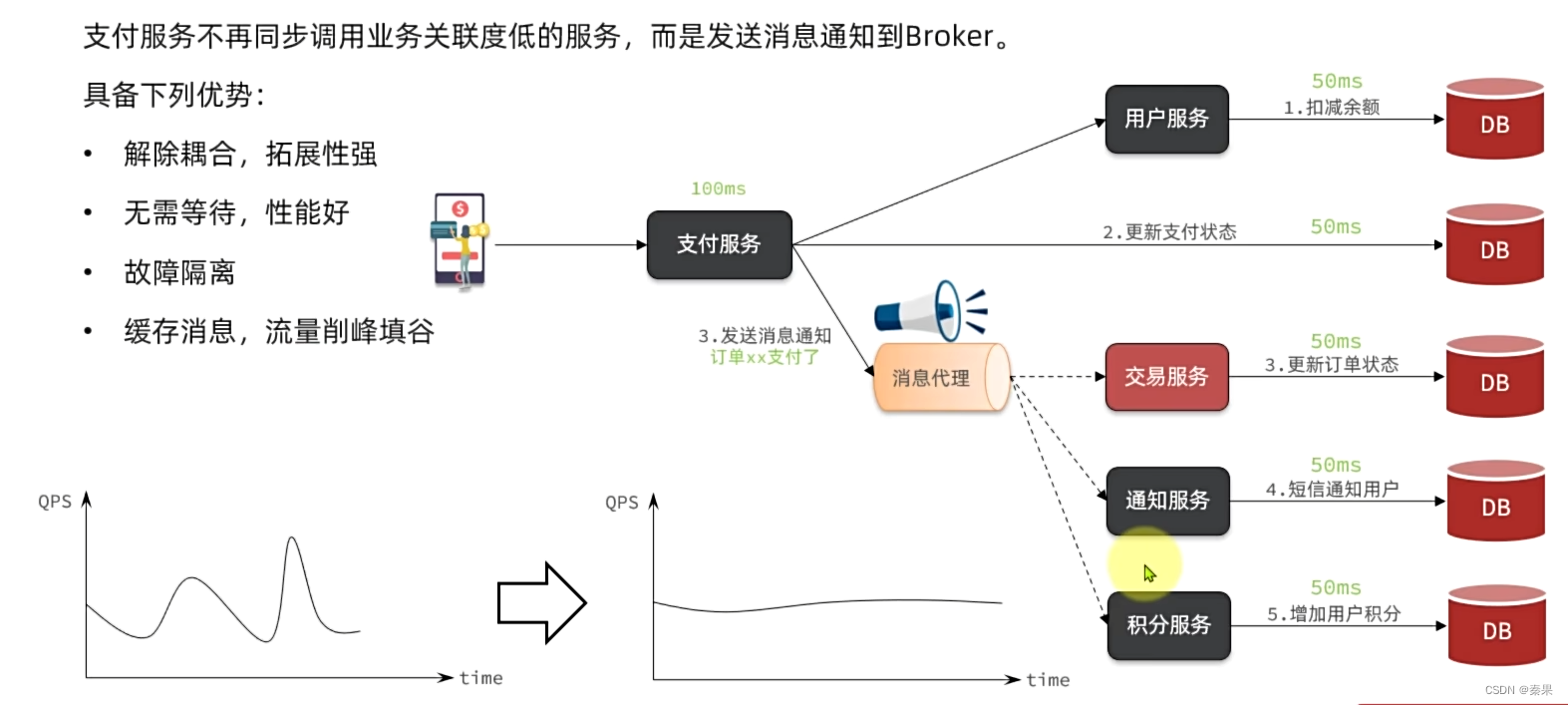
故障隔离的原理是我把消息给消息代理了就不管了,消息代理会一直发送消息给你,你出现故障了,也会一直给你发消息,直到你能处理好之后停止。
流量削峰是说我消息代理可以把所有请求拦截住,后续微服务可以根据自己的能力去消息代理那里取多少来进行处理。

时效性要求高,需要拿到结果才能处理就使用同步调用
对调用后的结果不关心,性能要求高就采用异步调用
③MQ技术选型
Kafka大数据采用

2.RabbitMQ
①安装部署
day06-MQ基础 - 飞书云文档 (feishu.cn)
只需要拉取镜像,部署容器
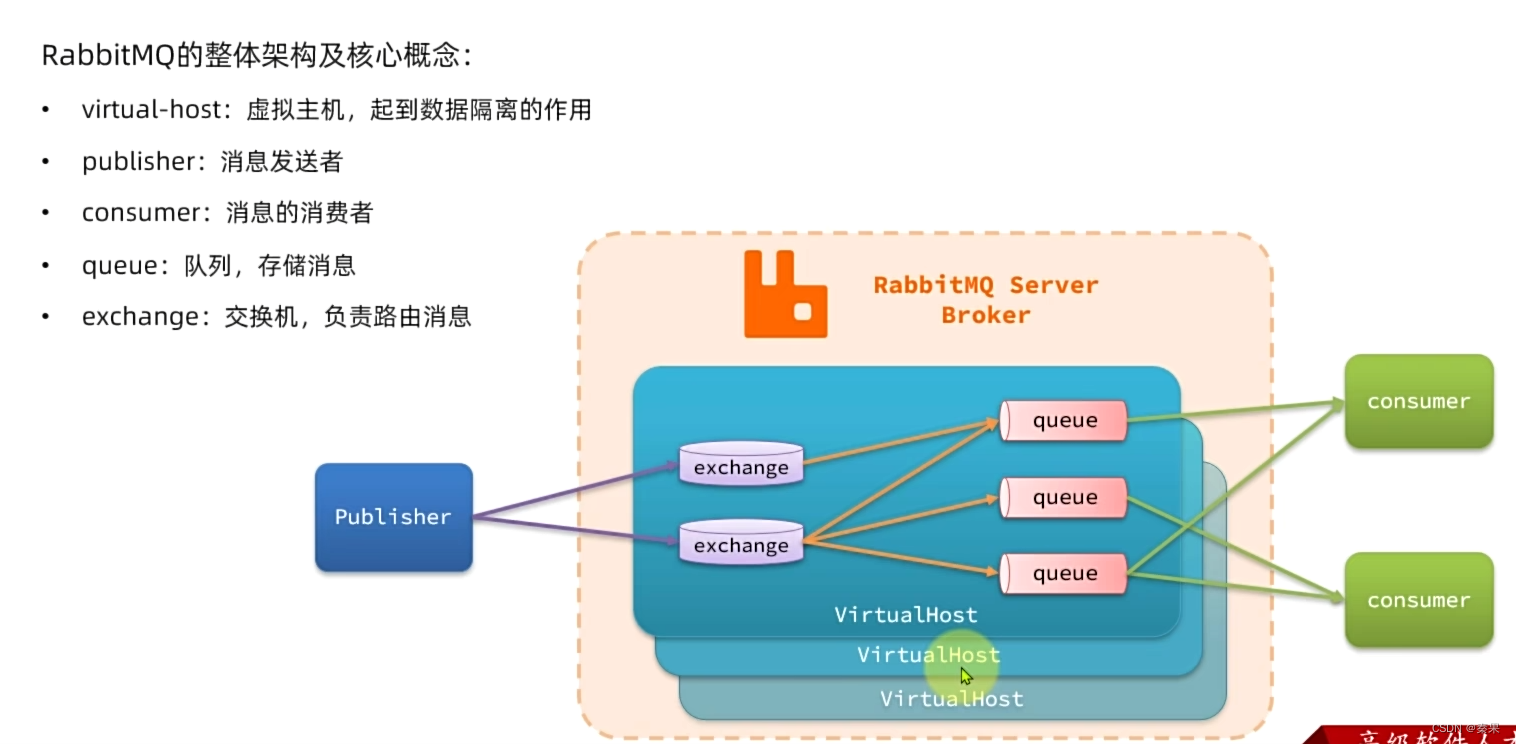
②快速入门

创建队列,填名字就可以;让交换机和队列绑定关系,才能投递消息
③数据隔离
虚拟主机可以让不同MQ隔离开
创建用户:
登录自己的用户后不能操作别的用户创建的交换机和队列
创建虚拟主机:就可以在这个属于该用户的虚拟主机中进行创建交换机和队列了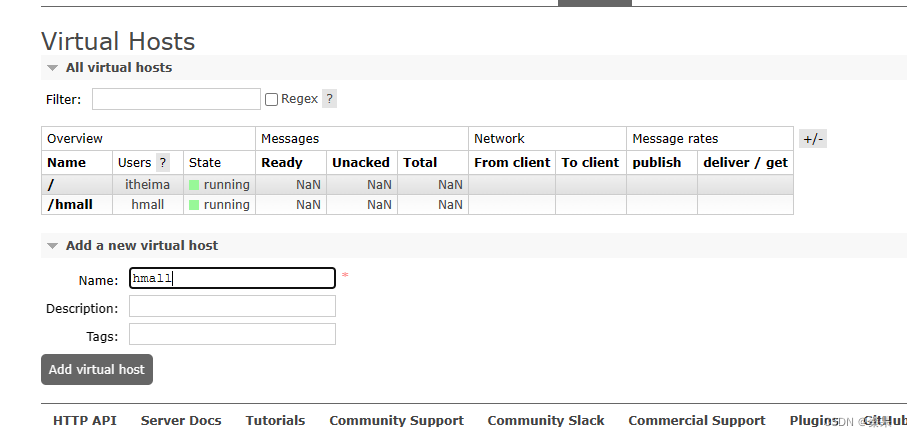
3.Java客户端
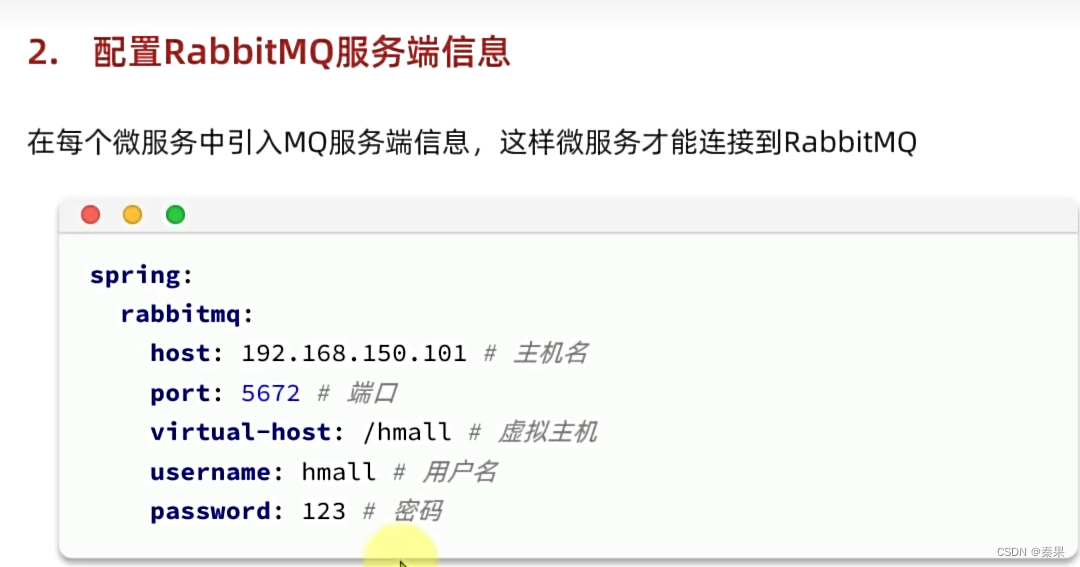
①快速入门

Rabbit可以使用AMQP消息协议

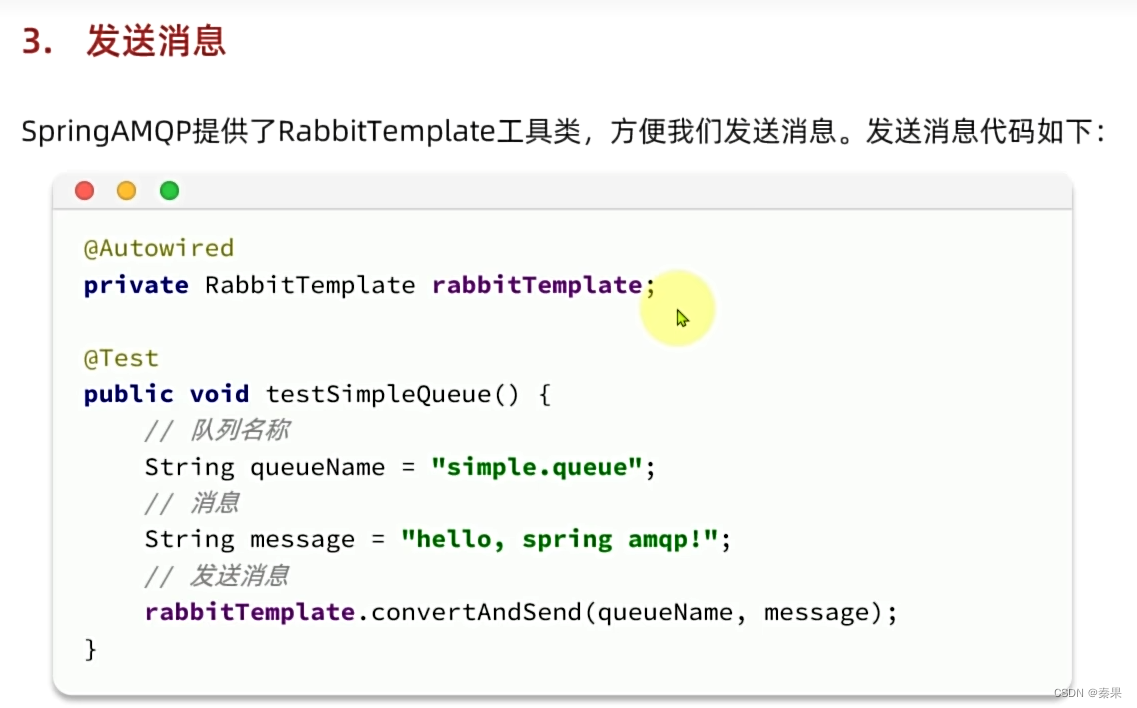

②Work Queues

多个消费者怎么消费队列的消息?
队列中的一个消息只能被一个消费者消费,很多消息的时候就会均匀分配给消费者,类似轮询的规则
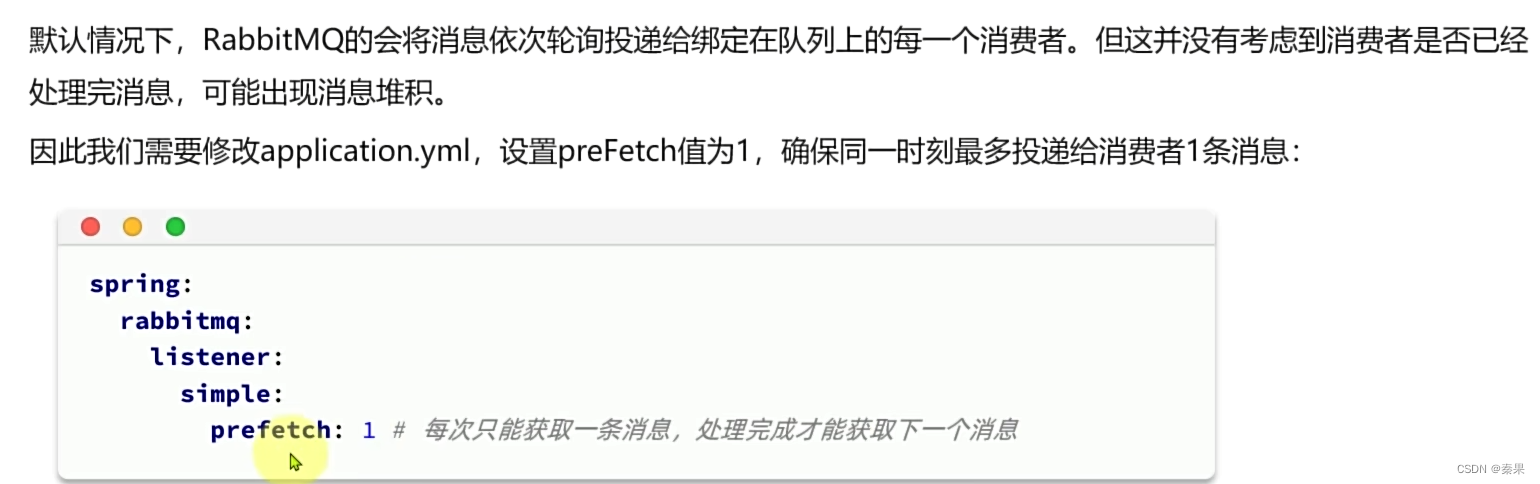
这种规则但是没有考虑消费者处理消息的速度,可能A消费者处理完了,B消费者还没处理完导致整体速度降低
所以可以设置:

③Fanout交换机


交换机的存在可以让发布者发送一次消息,调用不同的微服务,只需要每个微服务去绑定一个队列,然后这些队列去绑定交换机

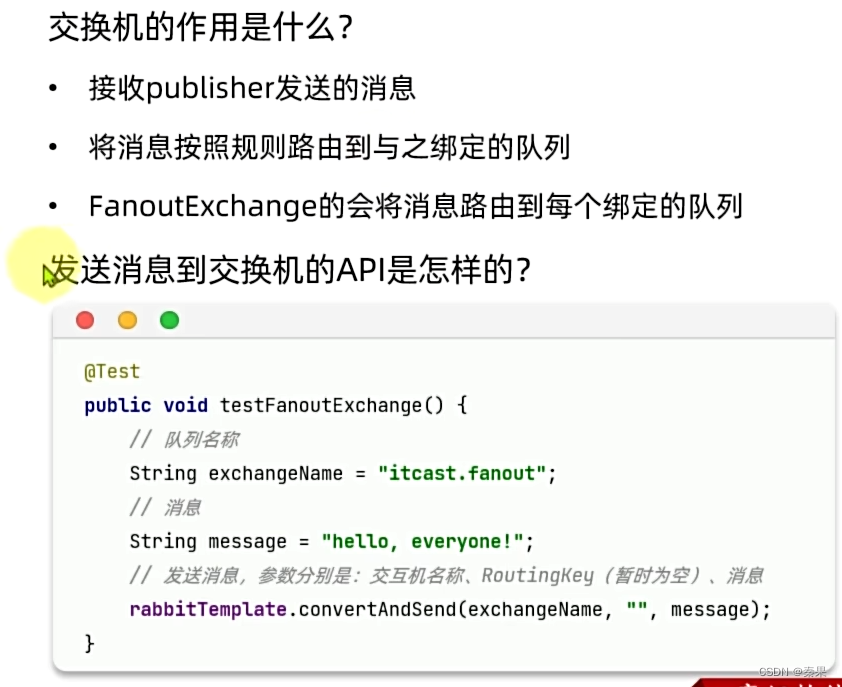
这里发送的API有三个参数,第二个队列填空或空字符
④Direct交换机

类似于给队列添加标签,发送者添加第二个参数,标签对应的队列才会接收到交换机的消息

一个队列可以添加多个标签

发送红色都收得到,发黄色只有二能收到

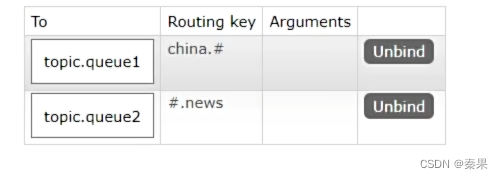
⑤Topic交换机

队列1只关注以china.开头的消息,队列2只关注以japan.开头的消息,一个队列就可以绑定多个消息

⑥声明队列交换机
手工添加交换机和队列会出现错误

这个configuration配置类编写在消费者中,因为发送者只关心发送消息与否,消费者关心从哪里拿消息。


这里要绑定多个routingKey的话,就要返回多个bean。

Javabean绑定方式代码冗杂
注解:就很方便
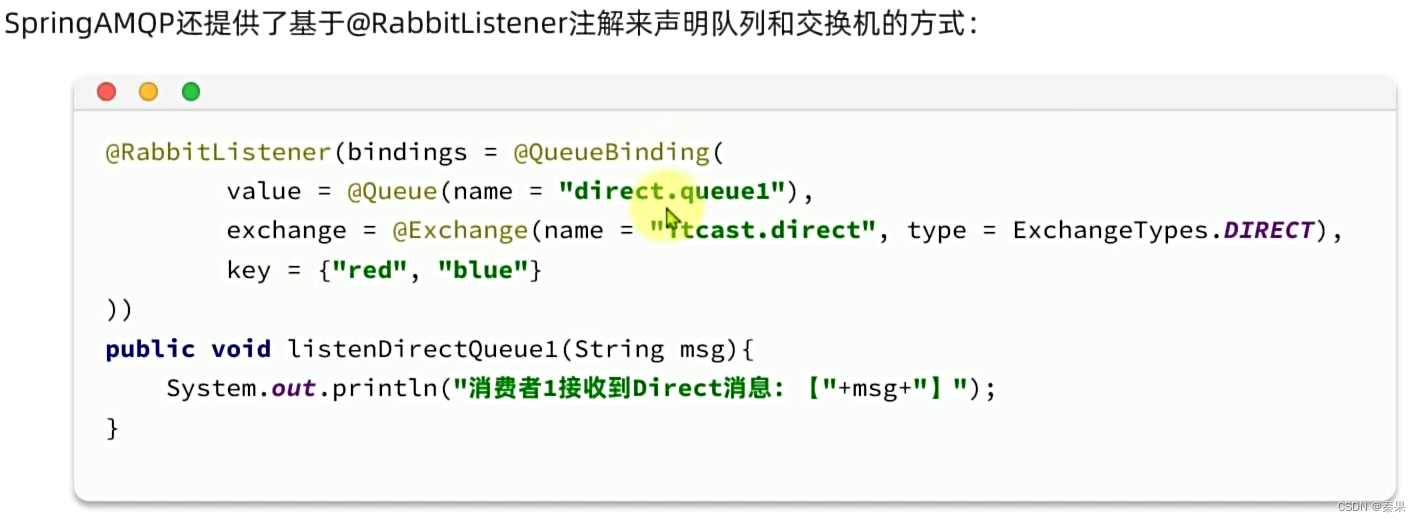
⑥消息转换器


这样使用Json序列化的话传入一个对象,监听也可以拿到这个对象。
4.业务改造

支付服务是发送者,交易服务是消费者
步骤:
1.引入依赖

2.设置MQ地址配置

3.设置转换器配置,由于这个配置类所有需要MQ的都会需要,所以设置在common中

让可以被扫描到
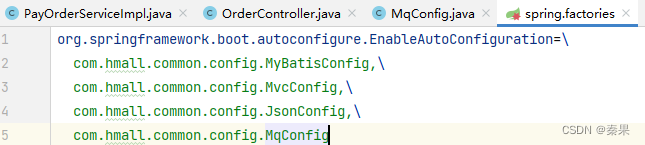
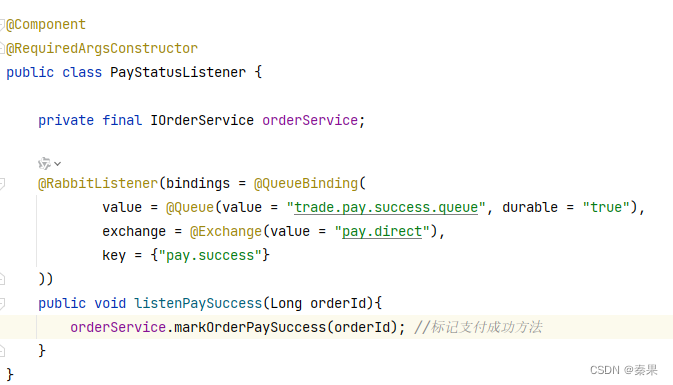
4.在消费者中编写监听代码
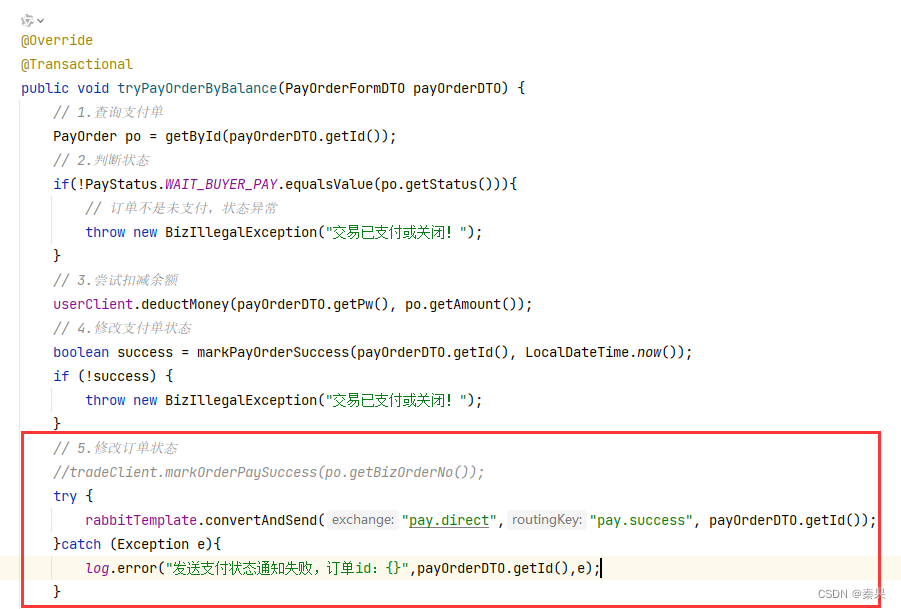
5.在发送者编写发送代码

使用try/catch就不会影响主程序了
四、MQ高级
MQ高级功能就是确保消息能够正确收发
1.发送者的可靠性
①发送者重连

以上配置是关于使用Spring Boot连接到RabbitMQ消息队列的设置。让我用通俗易懂的语言解释一下:
1. `connection-timeout: 1s`: 这是设置与 RabbitMQ 的连接超时时间。也就是说,如果在1秒内无法连接到 RabbitMQ,系统会超时并停止尝试连接。
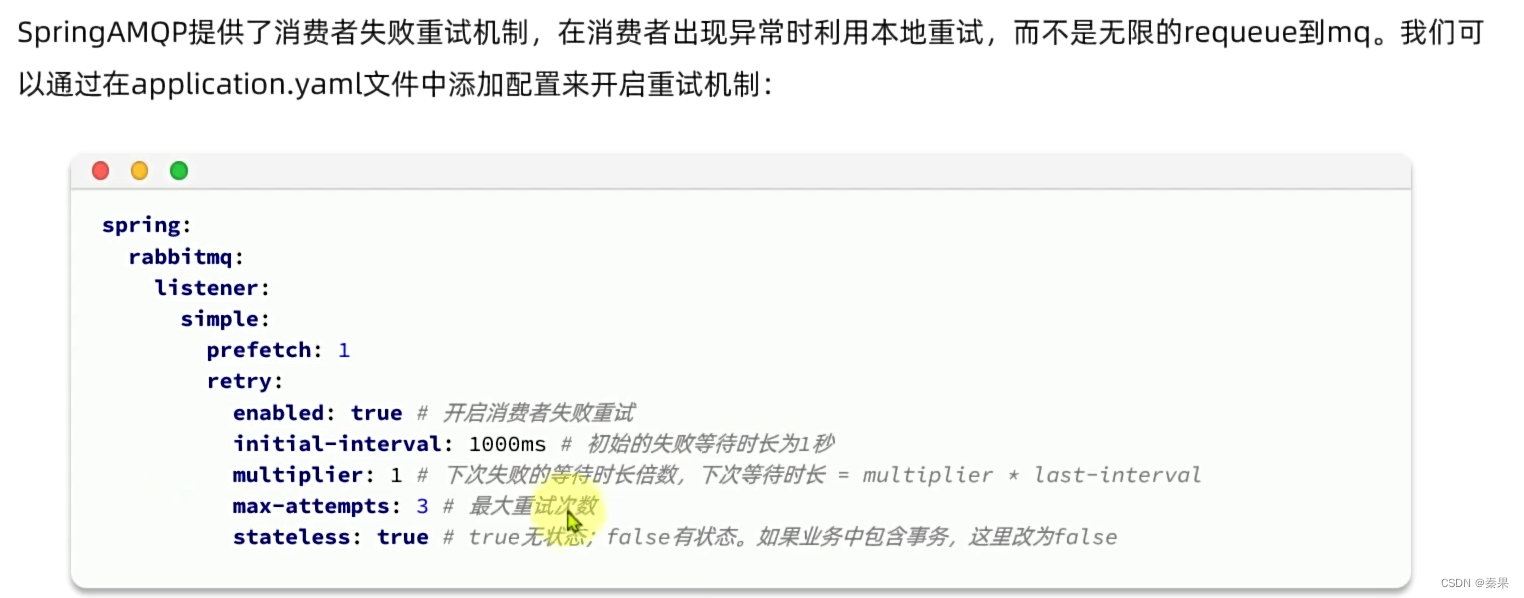
2. `retry` 重试机制:
- `enabled: true`: 这表示开启了消息发送失败后的重试机制。也就是说,如果发送消息失败,系统会尝试重新发送消息,直到达到最大重试次数或成功为止。
- `initial-interval: 1000ms`: 这是在第一次失败后等待重新尝试的时间间隔。在第一次失败后,系统会等待1秒,然后再次尝试发送消息。
- `multiplier: 1`: 这是一个倍数,用于计算下一次重试的等待时间。每次失败后,系统会将 `initial-interval` 乘以这个倍数,以确定下一次等待的时间间隔。在这种情况下,下一次等待时间间隔仍然是1秒。
- `max-attempts: 3`: 这是设置的最大重试次数。如果消息发送失败并且重试次数已达到这个限制,则系统将停止尝试发送消息,并且可能需要采取其他措施来处理消息发送失败的情况。
②发送者确认
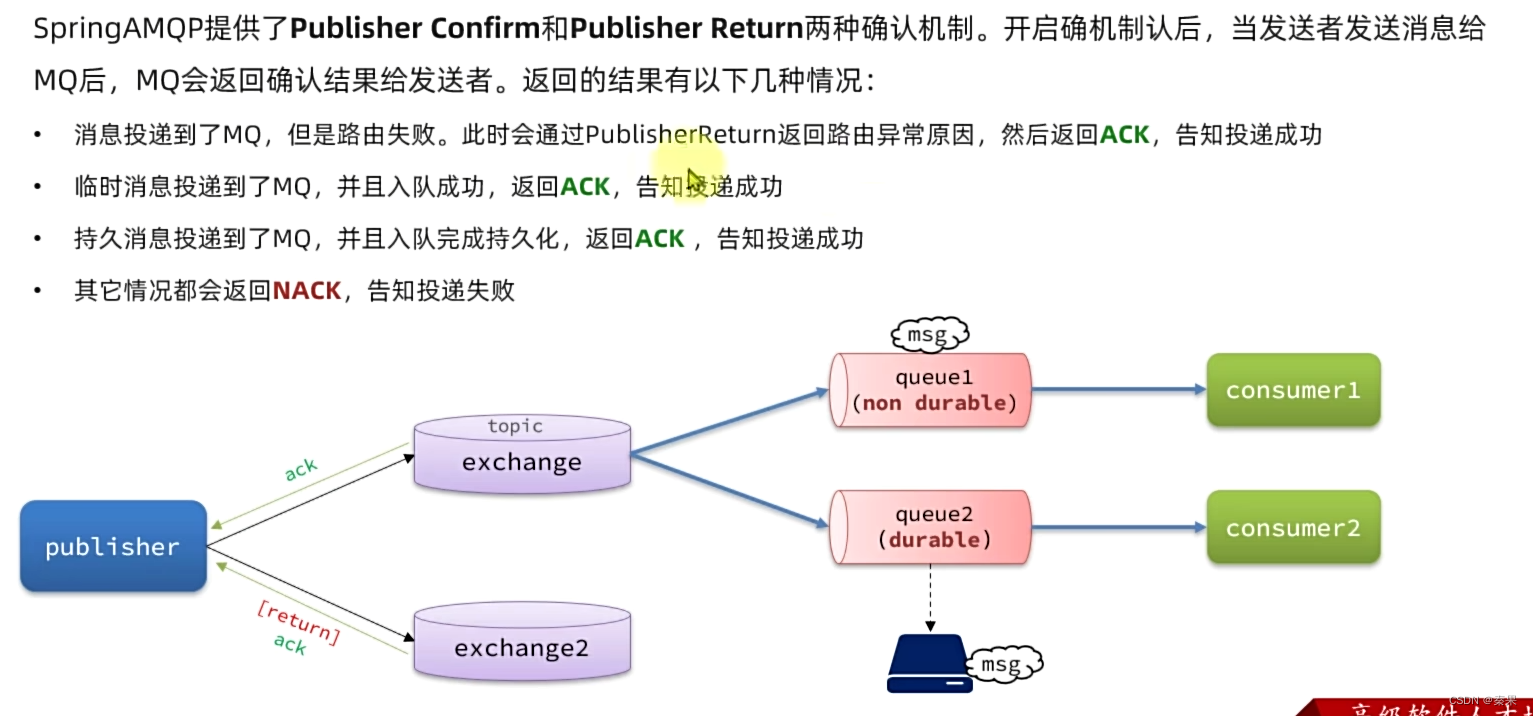
持久消息只有保存到磁盘中才算成功
只要配置正确,exchange和queue正确,nack只会MQ错误才会出现


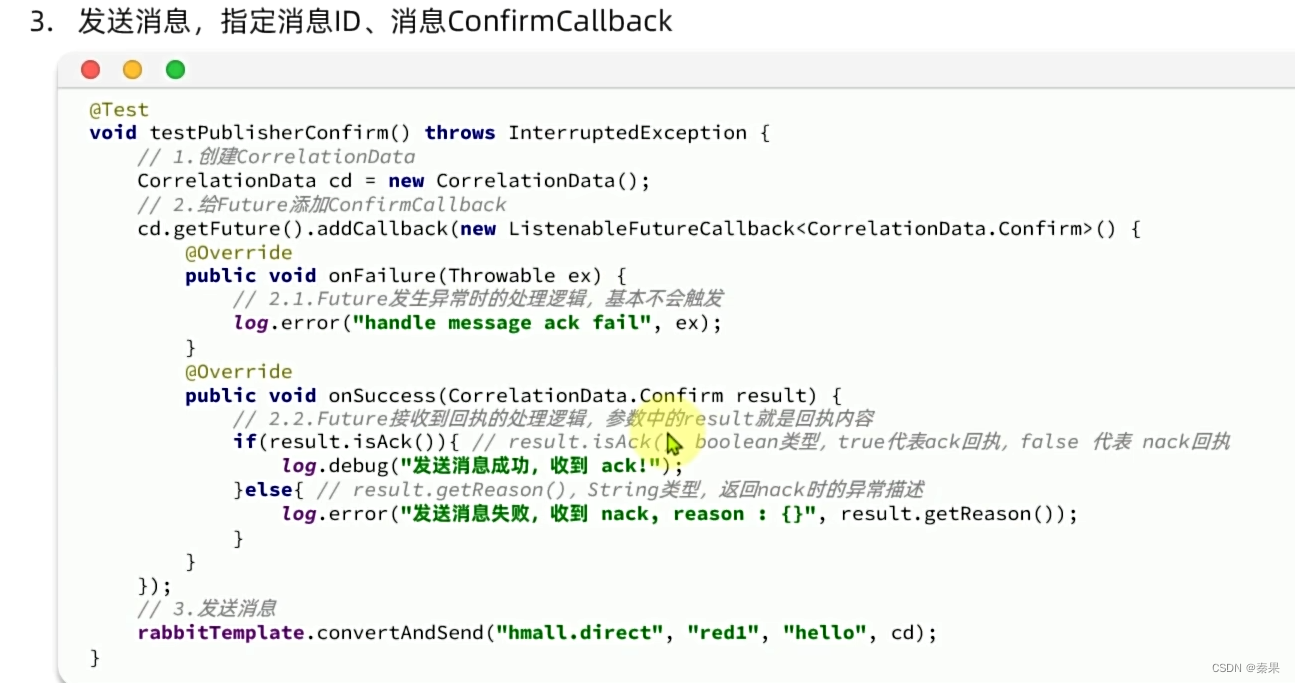
一般不开启。
2.MQ的可靠性
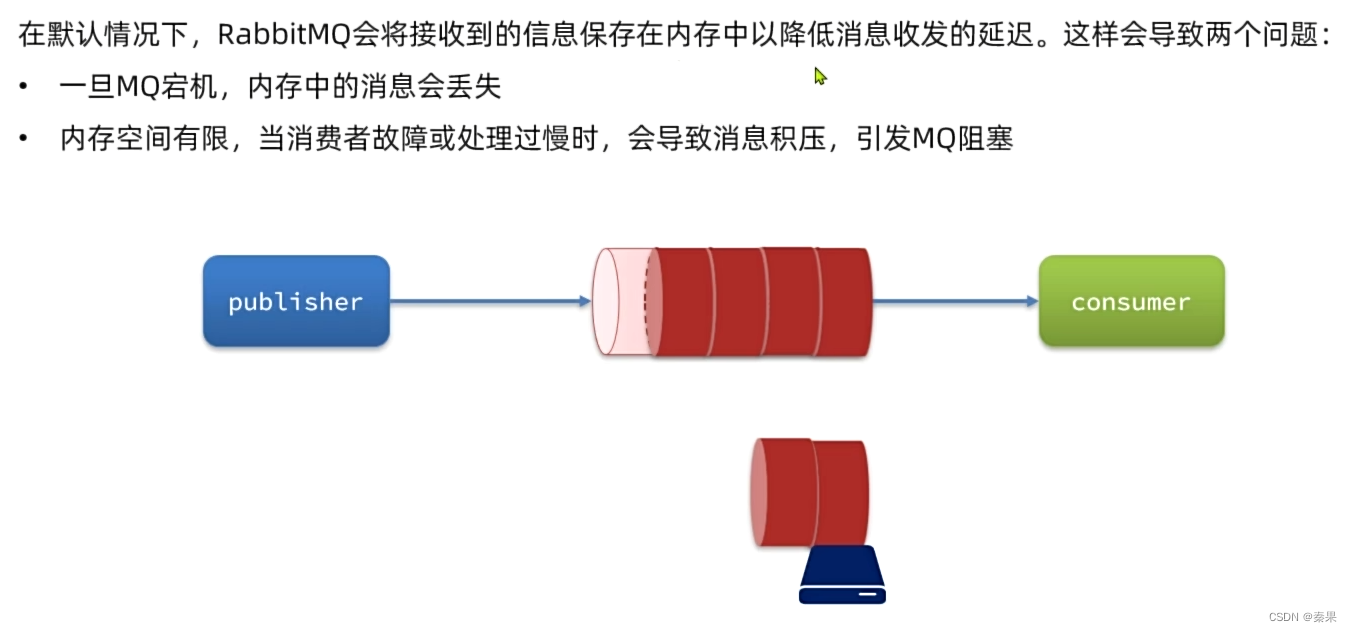
①数据持久化
1.持久化就是放入磁盘中,内存中的内容会消息重启后
2.内存的空间有限,如果瞬间来了很多消息,它会满了后再向磁盘写入,这样会造成阻塞,如果是持久化消息,来一个会先进入内存然后写入磁盘一个,不会造成阻塞,效率更高。
交换机持久化,队列持久化,消息持久化


消息设置为PERSISTENT

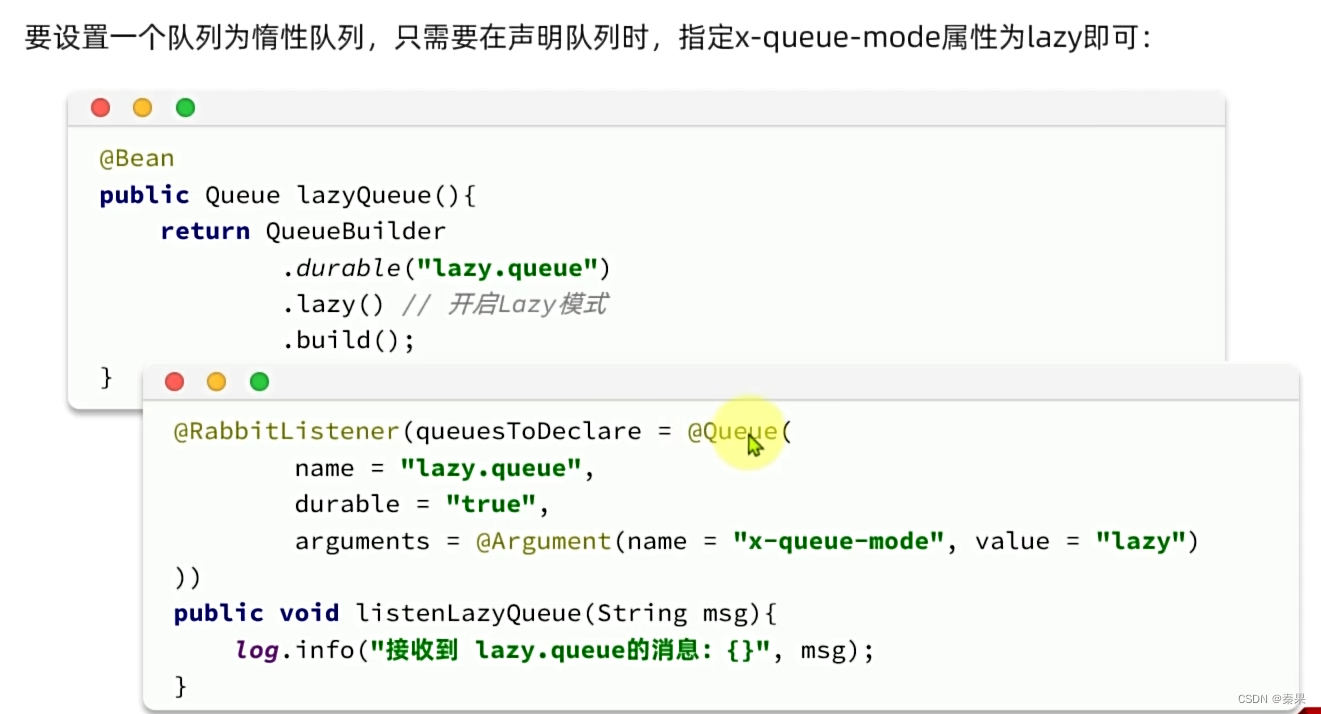
②Lazy Queue
数据持久化会造成并发,同一时间处理消息量很高,Lazy Queue会降低同一时间处理消息量

不会存入内存中,直接到磁盘
会监控消费者处理消息的快慢,快就会提前缓存
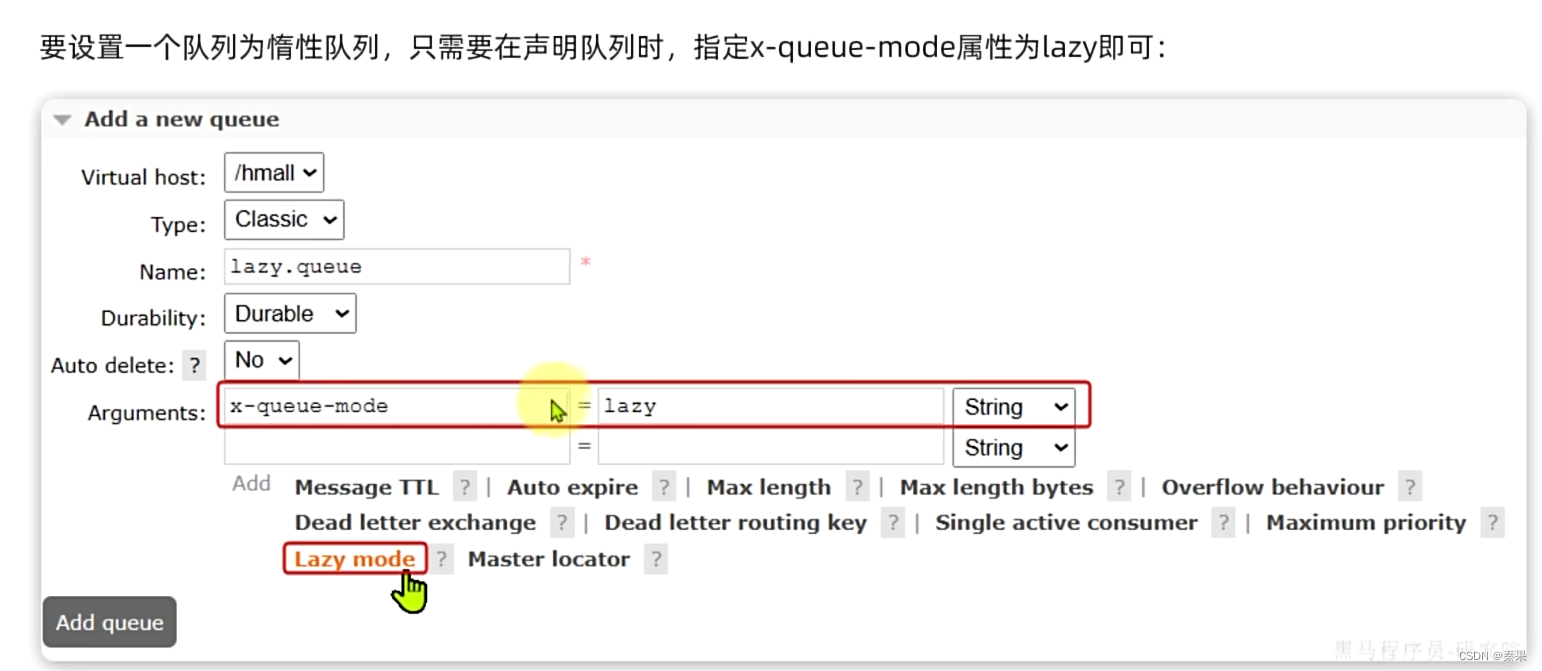
声明队列可以配置configuration也可以加注解。

3.消费者的可靠性
①消费者确认机制
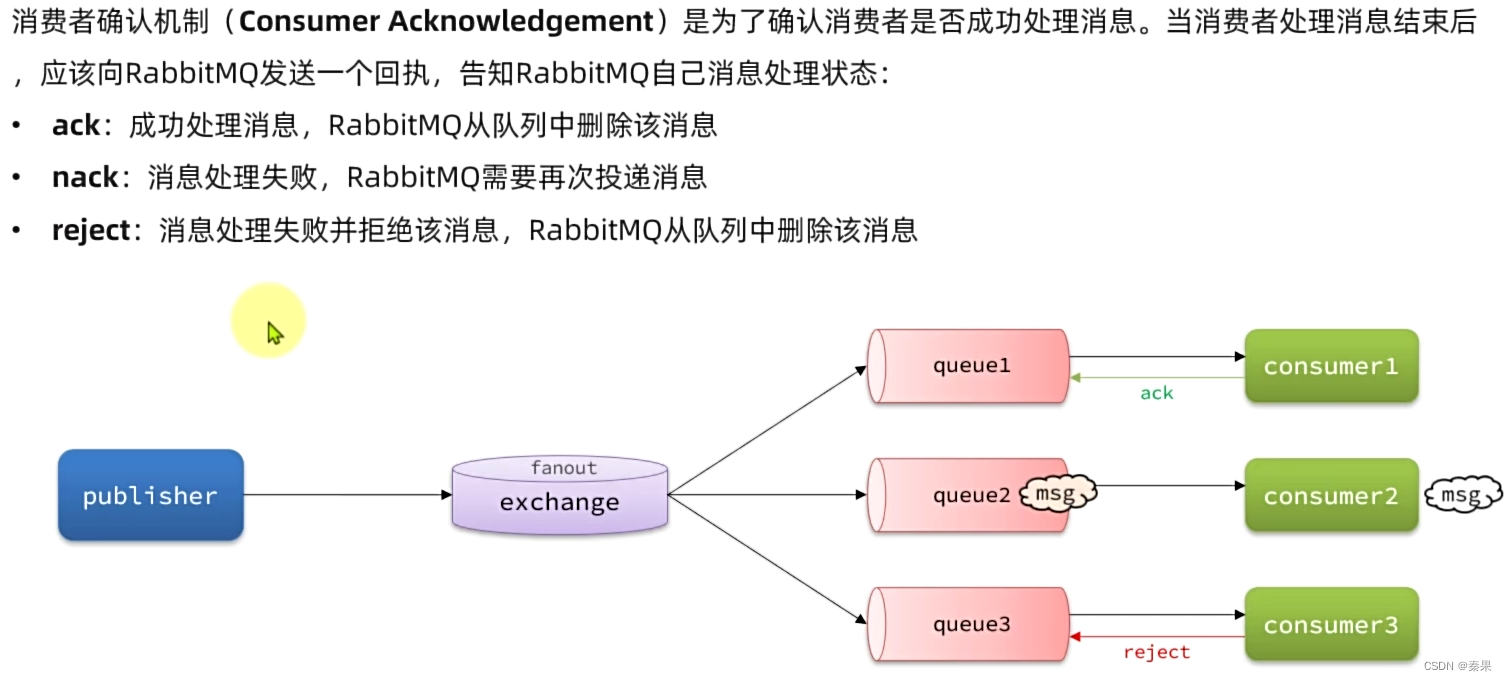
发现消息的内容有问题导致运行失败就返回reject

②失败重试机制
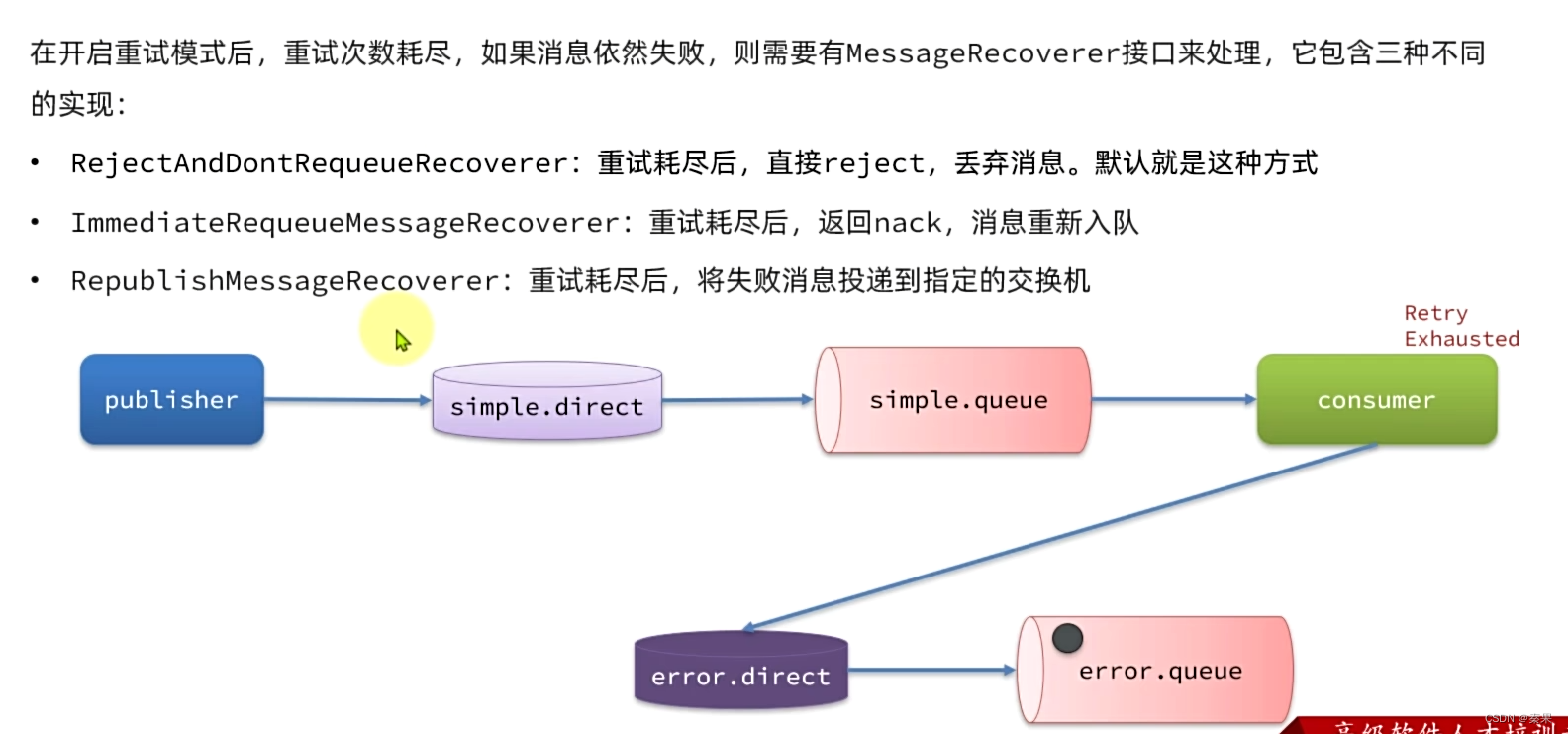
失败重试次数耗尽后策略有三种,默认第一种,不合适。

③业务幂等性
消费者处理好后返回ack中断开了和MQ的连接,会造成再次接受消息处理

一些任务是幂等的,多次接受消息不会有影响。
策略:发送者给消息添加id

消费者可以用message来监听消息

还要处理id的逻辑与业务无关,麻烦且影响性能

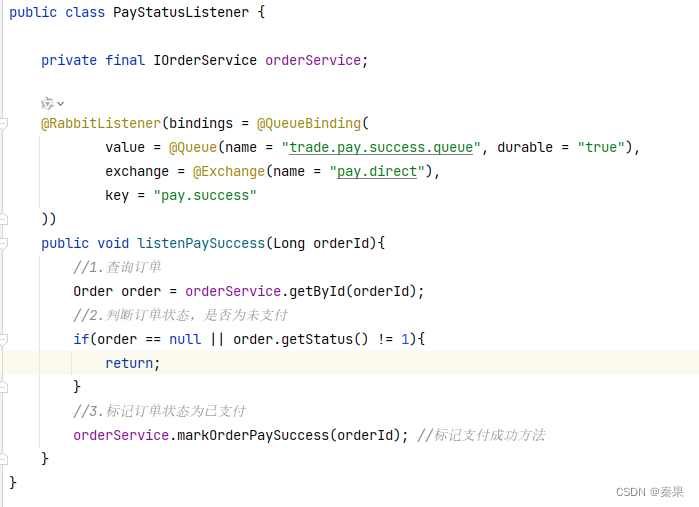

4.延迟消息
兜底方案
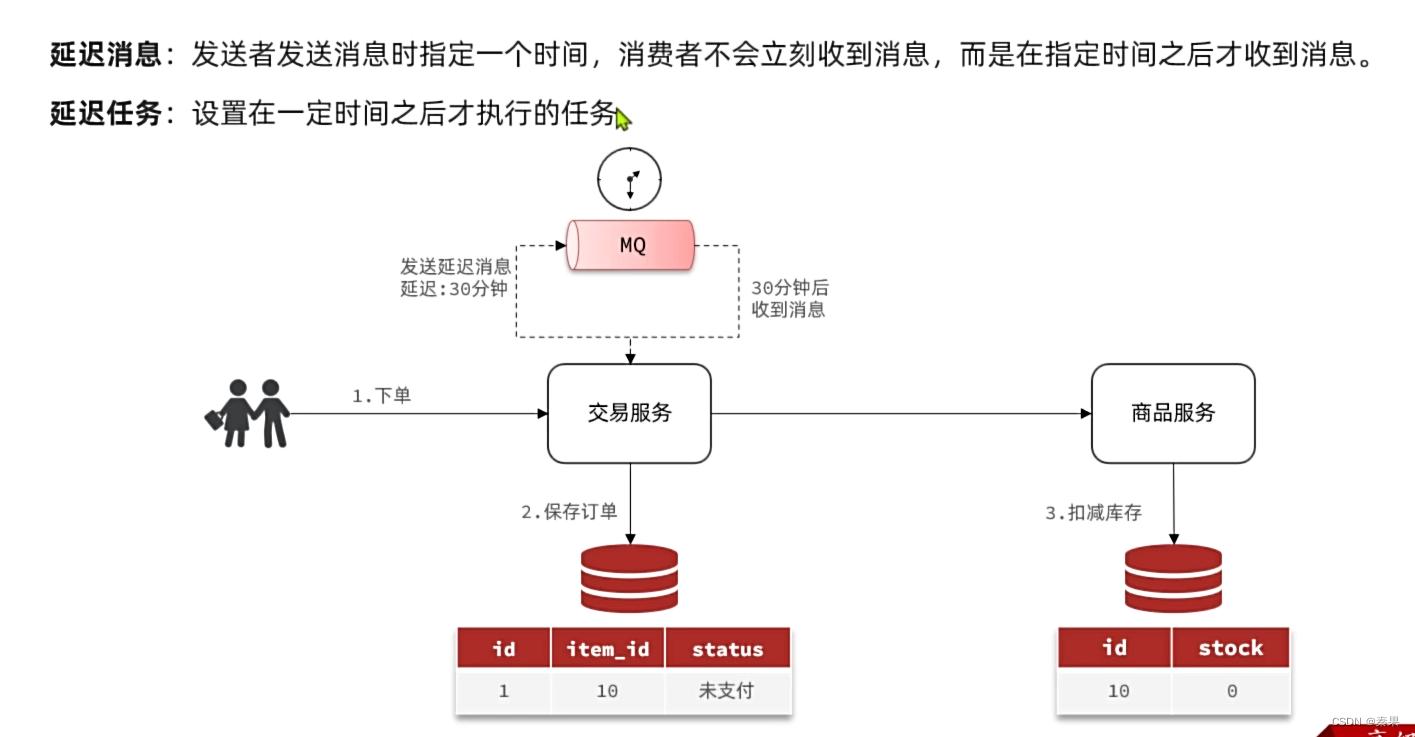
①死信交换机
利用死信交换机的机制实现了延迟消息的效果

创建normal.direct和normal.queue,并声明死信交换机

创建死信交换机和队列绑定

发送者这里设置了延迟时间,时间到未处理就会进入死信交换机

②延迟消息插件
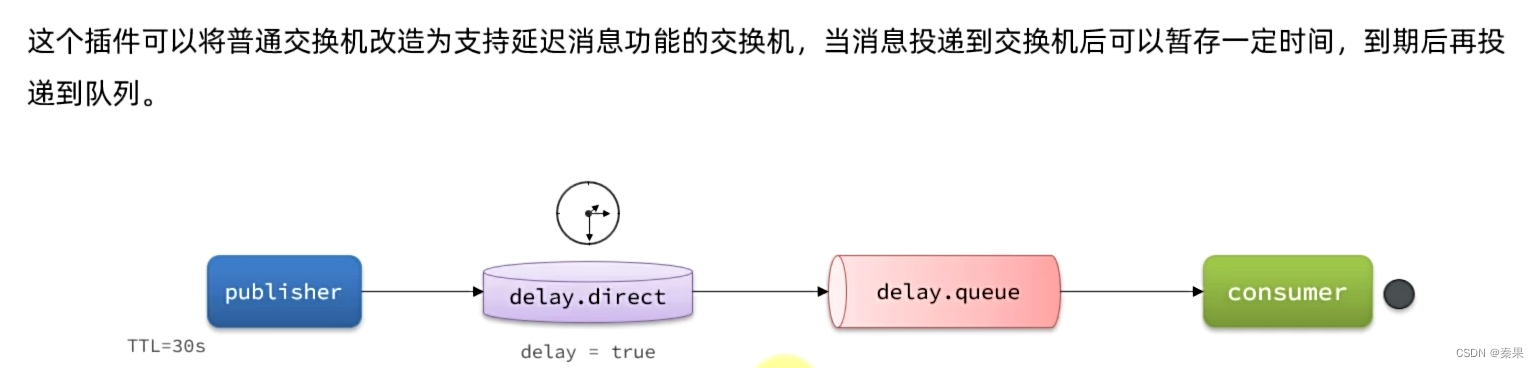
部署过程:下载插件,上传插件,挂载到数据卷(进入数据卷的位置后执行命令)
day07-MQ高级 - 飞书云文档 (feishu.cn)
声明延迟交换机的方式:

发消息:
避免同一个时刻存在大量延迟消息,延迟依赖cpu中的时钟计时,过多会给CPU压力。
让延迟时间不要过长
③取消超时订单
原本程序创建订单功能,和支付功能在两个不同微服务:交易服务,支付服务
当用户下单后会生成订单,并且清理购物车,扣减库存。
之后会弹出等待用户支付的页面,用户支付成功后会调用交易服务中修改订单状态为已支付。
这就存在一个问题:如果用户一直未支付,交易服务处理失败,此时库存已经扣减,但未卖出,存在数据不一致。如果支付服务发送修改订单状态出现问题,已支付但未修改订单状态存在数据不一致。
此时使用延迟消息,交易服务生成订单后,会向自己发送延迟消息,查看订单状态,为未支付会修改库存等。








![[NOIP2002]过河卒 标准递归](https://img-blog.csdnimg.cn/direct/f3ada3545ca34585a2becf5b93f7cba6.png)