属性文法
也称为属性翻译文法,由 Knuth 提出,以上下文无关文法为基础
(1)为每个文法符号(终结符与非终结符)配备相关的属性,代表与该文法符号相关的信息
(2)属性文法对于每个产生式都配备了对应的语义规则,标明了语义关系的传递

属性的分类
综合属性
自下而上的传递信息,根据产生式右部的符号属性计算左部被定义符号的综合属性
在语法树中,即根据子节点的属性和自身的自身属性来计算父节点的综合属性
继承属性
自上而下传递信息,根据右部候选式的符号属性与左部的属性计算右部候选式中符号的继承属性

属性依赖
对于每个产生式
A
→
α
A \to \alpha
A→α都有对应的语义规则,每条规则的形式可以写作:
b,c1,c2 等都为标识符对应的属性
b
=
f
(
c
1
,
c
2
,
.
.
.
,
c
k
)
b = f(c_1,c_2,...,c_k)
b=f(c1,c2,...,ck)
则我们说red:属性 b 依赖于 c1,c2 等
这种依赖又分为我们所提到的综合属性或继承属性
(1)若 b 为综合属性,则 c1,c2 等为产生式右部文法符号的属性
(2)若 b 为右部某个文法符号的继承属性,则 c1,c2 可能为产生式左部或右部任何符号的属性
注意:因为终结符没有子节点,所以终结符只有综合属性,由词法分析器提供
语义规则
(1)对出现在右边的继承属性和左边的综合属性都必须提供相应的计算规则,而且只能使用相应产生式中的文法符号
(2)出现在左边的继承规则和右边的综合属性不由对应产生式的属性计算规则进行计算,而是由其他产生式的属性规则计算或者由相关参数提供
带注释的语法树
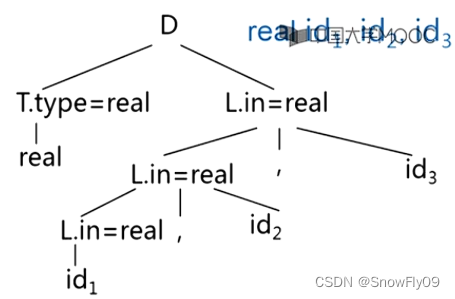
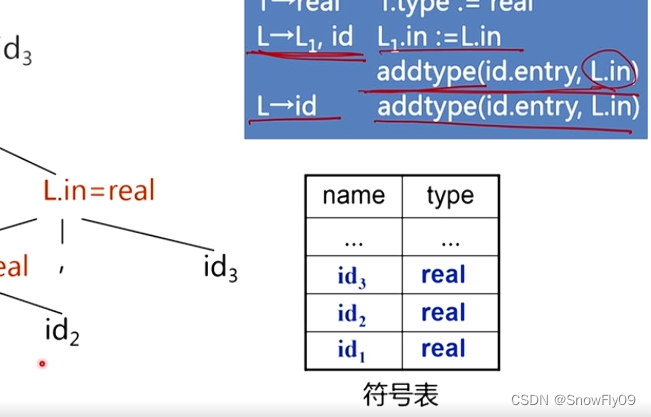
e.g.3*5+4n 利用第一组产生式
对于综合属性,一边自下而上分析构建语法树一边使用语义规则代入
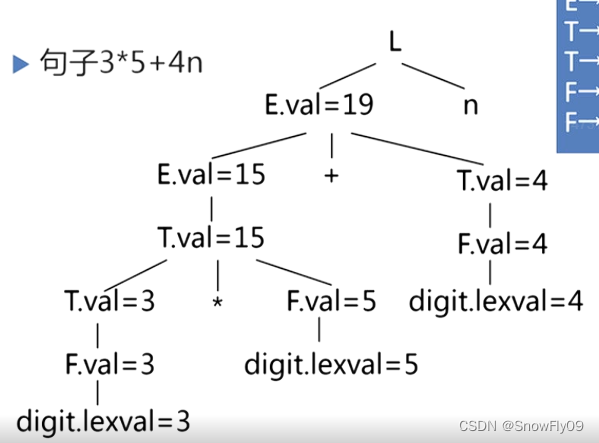
由此可以得到带注释的语法分析树
对于继承属性,则先构建语法树,然后自上而下填写,对于 addtype,就是在符号表中填写其对应名字,属性对应 addtype 中后项(通常为父节点)所对应的属性
属性计算
语义规则的计算可以用来:产生代码/在符号表中存放信息/执行动作,blue:对输入串的翻译就是根据语义规则的计算
语法制导翻译法就是将输入串转化为合适的语法树,然后选择适合的语法规则计算属性
基于语法的语义分析方式是多样的,主要有以下三种:
(1)依赖图
(2)树遍历
(3)依赖扫描
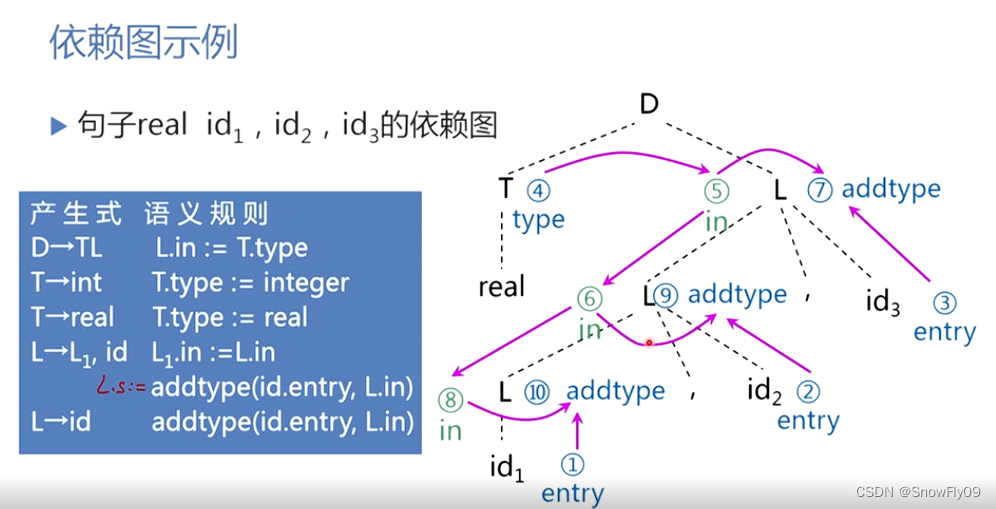
依赖图
一颗语法树中的节点的继承属性和综合属性的依赖关系可以由依赖图来描述
若属性 b 依赖于属性 c,则从 c 有一条有向边指向属性 b
根据依赖图,如果一个属性文法不存在属性之间的循环依赖关系(环),则称则称该文法是良定义的
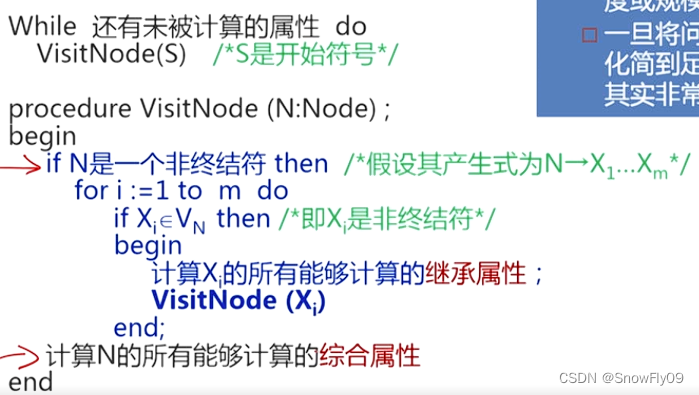
树遍历
假设语法树已建立,且树中已带有开始符号的继承属性和终结符的综合属性,此后以某种遍历顺序遍历语法树,直到最终所有属性都被计算出来
递归的调用 VisitNode 方法
一遍扫描
语法树需要反复使用 visitNode,属于多遍扫描,一遍扫描则是根据语法分析的过程同时计算属性值
语义规则的计算时机:
(1)自上而下分析,一个产生式匹配输入串成功时计算语义规则
(2)自下而上分析,一个产生式被归约时计算语义规则
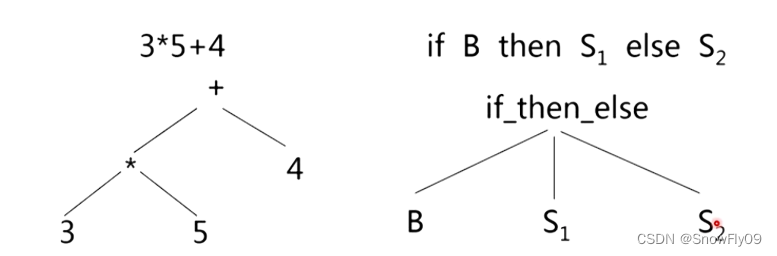
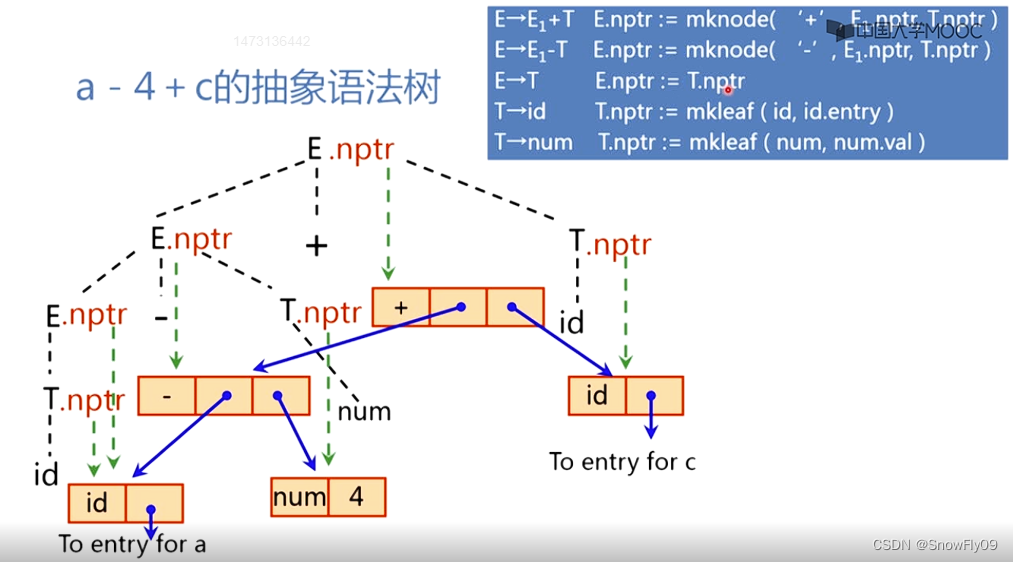
抽象语法树:
建立表达式的抽象语法树
mknode(op,left,right)建立运算符号节点,left 和 right 分别指向左子树和右子树
mkleaf(id,entry)建立标识符节点
mkleaf(num,val)建立数节点
一遍扫描与自下而上的语法分析器配合工作
S属性文法
只含有综合属性,使用自下而上的分析器,在原本的状态-符号栈中 增加附加域存放综合属性值
假设
A
→
X
Y
Z
A \to XYZ
A→XYZ对应的语义规则为
A
.
a
=
f
(
X
.
x
,
Y
.
y
,
Z
.
z
)
A.a = f(X.x,Y.y,Z.z)
A.a=f(X.x,Y.y,Z.z)
归约时,将 X、Y、Z 的状态,符号,属性弹出,然后将 A 的状态符号属性压入栈顶
L 属性文法
L 属性文法适合一遍扫描的自上而下分析,通过深度优先地遍历语法树。对于
A
→
X
1
X
2
.
.
.
X
i
A \to X_1X_2...X_i
A→X1X2...Xi,Xi 的继承属性依赖于:
(1)A 的继承属性
(2)Xi 左边符号 X1,X2 等的属性,而不包括右侧
red:S属性文法属于 L 属性文法
翻译模式
语义规则只给出了属性计算的定义,但是没有给出属性计算的先后顺序,可以在属性文法的基础上进一步给出使用顺序,就叫翻译模式
翻译模式:将语义规则与属性用花括号括起来放在合适的位置上,用来表示语法制导翻译的时机
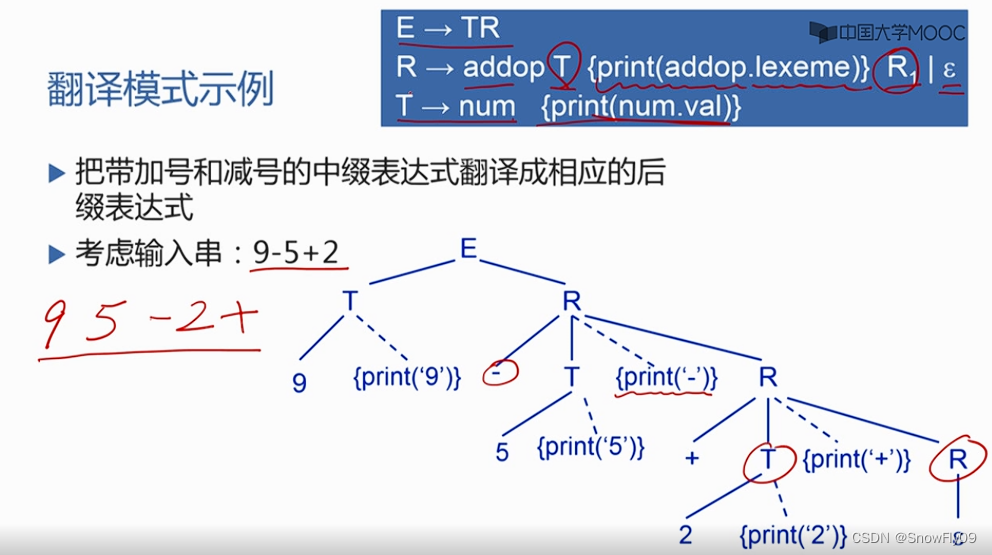
注意将中缀表达式换成了后缀表达式
(1)当只需要综合属性的时候,将赋值动作放在相应产生式最右侧的末尾
T
→
T
1
∗
F
T
.
v
a
l
:
=
T
1
.
v
a
l
×
F
.
v
a
l
T \to T_1*F\\ \\{T.val:=T_1.val\times F.val\\}
T→T1∗FT.val:=T1.val×F.val
(2)如果既有综合属性又有继承属性,在建立翻译模式时就必须保证:产生式右边符号的继承属性必须在这个符号之前计算出来
(3)一个动作不能够使用其右边的综合属性
(4)产生式左部的非终结符的综合属性必须等其所有应用的属性被计算出之后才能计算,且需要放在末尾计算
语义动作时机统一
如果能够使所有语义动作都放在产生式的末尾,就可以使每次语义执行的时机统一
方法:
(1)添加一个产生式:
M
→
ϵ
M \to \epsilon
M→ϵ
(2)把嵌入在产生式中间的语义动作用 M 代替,并将这个动作放在产生式 M TO EPSILON 的末尾

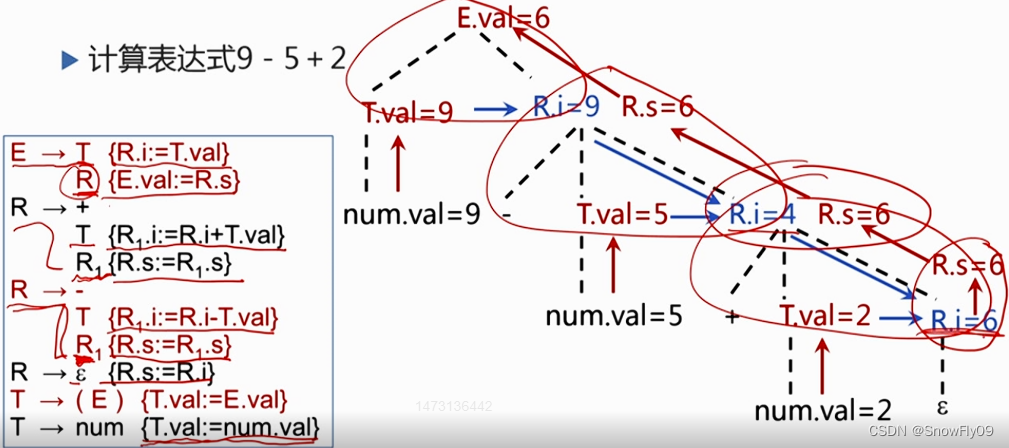
消除翻译模式的左递归

这里可以理解 R.i 为继承属性,R.s 为综合属性,继承属性必须放在非终结符前,所以 Ri 的语义动作都在 Ri 前,Rs 则放在产生式最后给左部赋值





![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-17讲 定时器按键消抖](https://img-blog.csdnimg.cn/direct/0e09c12187a441dda1664cd58b74d6f3.png)