文章目录
- STL
- 1. #include\<vector>(尾部增删)
- (1) 声明
- (2) size/empty
- (3) clear
- (4) 迭代器(iterator)
- (5) begin/end(遍历)
- (6) front/back
- (7) push_back()/pop_back()
- 2. #include\<queue>(队列先进先出)
- (1) 声明
- (2) 循环队列 queue(队列结构)
- (3) 优先队列 priority_queue(堆结构)
- 3. #include\<stack>(栈先进后出)
- 4. #include\<deque>(双端队列)
- 5. #include\<set>
- (1) 声明
- (2) 迭代器
- (3) begin/end
- (4) insert
- (5) find
- (6) lower_bound/upper_bound
- (7) erase
- (8) count
- 6. #include\<map>
- (1) 声明
- (2) insert/erase
- (3) find
- (4) 操作符
- (5) unorderd_set/unordered_map/bitset
- (6) pair 函数
- 位运算和常用库函数
- 1. 位运算
- 2. 常用库函数(算法库#include\<algorithm>)
- 2.1 reverse 翻转
- 2.2 unique 去重(离散化) 重点!
- 2.3 random_shuffle 随机打乱
- 2.4 sort 排序(重要!)
- 2.5 lower_bound/upper_bound 二分
STL
1. #include<vector>(尾部增删)
- vector是变长数组,支持随机访问,不支持在任意位置O(1)插入。为了保证效率,元素的增删一般应该在末尾进行
(1) 声明
#include <vector> 头文件
vector<int> a; 相当于一个长度动态变化的int数组
vector<int> b[233]; 相当于第一维长233,第二位长度动态变化的int数组
a.size();// 长度
a.empty();// 返回的是bool值
a.clear();// 清空
struct rec
{
int x, y;
};
vector<rec> c; 自定义的结构体类型也可以保存在vector中
(2) size/empty
- size函数返回vector的实际长度(包含的元素个数),empty函数返回一个bool类型,表明vector是否为空。二者的时间复杂度都是O(1)
- 所有的STL容器都支持这两个方法,含义也相同,之后我们就不再重复给出
(3) clear
- clear函数把vector清空
(4) 迭代器(iterator)
- 类似指针或者数组下标的概念,相当于地址
- 迭代器就像STL容器的“指针”,可以用星号“*”操作符解除引用
- 一个保存int的vector的迭代器声明方法为:
vector<int>::iterator it = a.begin();// it + 2相当于访问a[2],it访问的就是a[0]
a.end();// 最后元素的下一个位置
*a.begin();// = a[0], *就是取值,a.begin()可以理解为指针
- vector的迭代器是“随机访问迭代器”,可以把vector的迭代器与一个整数相加减,其行为和指针的移动类似。可以把vector的两个迭代器相减,其结果也和指针相减类似,得到两个迭代器对应下标之间的距离
(5) begin/end(遍历)
- begin函数返回指向vector中第一个元素的迭代器。例如a是一个非空的vector,则*a.begin()与a[0]的作用相同
- 所有的容器都可以视作一个“前闭后开[start, end)”的结构,end函数返回vector的尾部,即第n个元素再往后的“边界”。*a.end()与a[n]都是越界访问,其中n = a.size()
- 下面两份代码都遍历了vectora,并输出它的所有元素
#include<vector>
#include<iostream>
using namespace std;
int main()
{
vector<int> a({1,2,3});
cout << a[0] << ' ' << *a.begin() << endl;// 结果是1 1
// 遍历
for (int i = 0; i < a.size(); i ++) cout << a[i] << ' ';
cout << endl;
// 迭代器遍历
for (vector<int>::iterator it = a.begin(); it != a.end(); it ++) cout << *it << endl;
for (auto it = a.begin(); it != a.end(); it ++) cout << *it << endl;// 使用auto
// 范围遍历
for(int x : a) cout << x << ' ' << endl;
return 0;
}
(6) front/back
- front函数返回vector的第一个元素,等价于*a.begin() 和 a[0]
- back函数返回vector的最后一个元素,等价于*a.end() 和 a[a.size() – 1]
#include<vector>
#include<iostream>
using namespace std;
int main()
{
vector<int> a({1,2,3});
cout << a.front() << ' ' << a[0] << ' ' << *a.begin() << endl;//都输出1,三个表达式是等价的
cout << a.back() << ' ' << a[a.size() - 1] << endl;// 均输出3,表达式等价
return 0;
}
(7) push_back()/pop_back()
- a.push_back(x) 元素x插入到vector a的尾部
- b.pop_back() 删除vector a的最后一个元素
#include<vector>
#include<iostream>
using namespace std;
int main()
{
vector<int> a({1,2,3});
a.push_back(4);// 往队列最后位置添加元素
for(int x : a) cout << x << ' ';// 1 2 3 4
cout << endl;
a.pop_back();// 去除队列最后位置的元素
for(int x : a) cout << x << ' ';// 1 2 3
cout << endl;
}
2. #include<queue>(队列先进先出)
- 头文件queue主要包括循环队列queue和优先队列priority_queue两个容器
- 队列是先进先出的结构,1是先从左边进,也是先从右边出
- 队列queue、优先队列priority_queue、栈stack均没有clear()函数,其他都有clear()函数
(1) 声明
#include<vector>
#include<queue>
#include<iostream>
using namespace std;
int main()
{
// 循环队列
queue<int> q;// 也叫队列
queue<double> q;
struct rec
{
int a, x;
};
queue<rec> q; // 结构体队列
// 优先队列
priority_queue<int> q; // 大根堆
priority_queue<int, vector<int>, greater<int>> q; // 小根堆
priority_queue<pair<int, int>>q;// pair是二元组
// 大根堆重载小于号
struct rec
{
int a, b;
bool operator < (const rec& t) const // 重载小于号
{
return a < t.a;// 编译器无法比较自定义数据的大小,需要自己定义规则
}
};
priority_queue<rec> c; // 定义结构体,内部要重载小于号
d.push({1,2});
// 小根堆重载大于号
struct rec
{
int a, b;
bool operator > (const rec& t) const // 重载大于号
{
return a > t.a;// 编译器无法比较自定义数据的大小,需要自己定义规则
}
};
priority_queue<rec, vector<rec>, greater<rec>> c; // 定义结构体,内部要重载大于号
d.push({1,2});
}
(2) 循环队列 queue(队列结构)
- push 从队尾插入
- pop 从队头弹出
- front 返回队头元素
- back 返回队尾元素
#include<vector>
#include<queue>
#include<iostream>
using namespace std;
int main()
{
// 循环队列
queue<int> q;// 队列
q.push(1); // 队尾插入元素
q.pop();// 弹出队头元素
q.front();// 返回队头元素
q.back();// 返回队尾元素
q = queue<int>();// 不能用clear函数清空队列,只能用左边的初始化清空
}
(3) 优先队列 priority_queue(堆结构)
- push 把元素插入堆
- pop 删除堆顶元素
- top 查询堆顶元素(最大值)
#include<vector>
#include<queue>
#include<iostream>
using namespace std;
int main()
{
// 优先队列
priority_queue<int> a;// 大根堆
a.push(1); // 插入元素
a.top();// 取最大值
a.pop();// 删除最大值
}
3. #include<stack>(栈先进后出)
- 头文件stack包含栈,声明和前面的容器类似,结构类似弹夹
- push 向栈顶插入
- pop 弹出栈顶元素
#include<vector>
#include<queue>
#include<stack>
#include<iostream>
using namespace std;
int main()
{
stack<int> stk;
stk.push(1);// 栈顶插入元素
stk.top();// 返回栈顶元素
stk.pop();// 弹出栈顶元素
return 0;
}
4. #include<deque>(双端队列)
-
双端队列deque是一个支持在两端高效插入或删除元素的连续线性存储空间。它就像是vector和queue的结合。与vector相比,deque在头部增删元素仅需要O(1)的时间;与queue相比,deque像数组一样支持随机访问
-
a[] 随机访问元素
-
begin/end 返回deque的头/尾迭代器
-
front/back 队头/队尾元素
-
push_back 从队尾入队
-
push_front 从队头入队
-
pop_back 从队尾出队
-
pop_front 从队头出队
-
clear 清空队列
#include<vector>
#include<queue>
#include<stack>
#include<deque>
#include<iostream>
using namespace std;
int main()
{
deque<int> a;
a.begin(), a.end();
a.front(), a.back();// 返回队尾和队头元素
a.push_back(1), a.push_front(2);// 队尾插入1,队头插入2
a.pop_front(), a.pop_back();// 弹出队尾元素和队头元素
a.clear();// 清空
return 0;
}
5. #include<set>
- 头文件 set 主要包括 set 和 multiset 两个容器,分别是“有序集合”和“有序多重集合”,即前者 set 的元素不能重复,而后者可以包含若干个相等的元素。set 和 multiset 的内部实现是一棵红黑树,它们支持的函数基本相同
(1) 声明
#include<vector>
#include<queue>
#include<stack>
#include<deque>
#include<iostream>
using namespace std;
int main()
{
set<int> a;// 元素不能重复
multiset<double> b;// 元素可以重复
// set迭代器
set<int>::iterator it = a.begin();
it ++;it --;// 表示有序序列的下一个元素/前一个元素
a.end();// 最后一个元素后一个位置
// 插入元素
a.insert(x);
// 查找元素
a.find(x);// 找到的话返回的是元素的迭代器,没找到则 a.find(x) == a.end()
if(a.find(x) == a.end()) // 判断x在a中是否存在
a.lower_bound(x);// 找到大于等于x值的最小元素的迭代器
a.upper_bound(x);// 找到大于x值的最小元素的迭代器
a.erase(it);// 删除迭代器
a.count(x);// 表示x在a里面的个数
struct rec
{
int x, y;
bool operator < (const rec& t) const // 重载小于号
{
return x < t.x;// 编译器无法比较自定义数据的大小,需要自己定义规则
}
};
set<rec> c; // 结构体rec中必须定义小于号
d.push({1,2});
}
- size/empty/clear
- 与vector类似
(2) 迭代器
- set 和 multiset 的迭代器称为“双向访问迭代器”,不支持“随机访问”,支持星号(*)解除引用,仅支持”++”和–“两个与算术相关的操作
- 设 it 是一个迭代器,例如 set<int>::iterator it;
- 若把 it++,则 it 会指向“下一个”元素。这里的“下一个”元素是指在元素从小到大排序的结果中,排在it 下一名的元素。同理,若把 it–,则 it 将会指向排在“上一个”的元素
(3) begin/end
- 返回集合的首、尾迭代器,时间复杂度均为O(1)
- s.begin() 是指向集合中最小元素的迭代器
- s.end() 是指向集合中最大元素的下一个位置的迭代器。换言之,就像 vector 一样,是一个“前闭后开”的形式。因此–s.end()是指向集合中最大元素的迭代器
(4) insert
- s.insert(x) 把一个元素x插入到集合 s 中,时间复杂度为O(logn)
- 在 set 中,若元素已存在,则不会重复插入该元素,对集合的状态无影响
(5) find
- s.find(x) 在集合s中查找等于x的元素,并返回指向该元素的迭代器。若不存在,则返回s.end()。时间复杂度为O(logn)
(6) lower_bound/upper_bound
- 这两个函数的用法与find类似,但查找的条件略有不同,时间复杂度为 O(logn)
- s.lower_bound(x) 查找大于等于x的元素中最小的一个,并返回指向该元素的迭代器
- s.upper_bound(x) 查找大于x的元素中最小的一个,并返回指向该元素的迭代器
(7) erase
- 设it是一个迭代器,s.erase(it) 从s中删除迭代器it指向的元素,时间复杂度为 O(logn)
- 设x是一个元素,s.erase(x) 从s中删除所有等于x的元素,时间复杂度为 O(k+logn),其中k是被删除的元素个数
(8) count
- s.count(x) 返回集合s中等于x的元素个数,时间复杂度为 O(k +logn),其中k为元素x的个数
6. #include<map>
- map 容器是一个键值对 key-value 的映射,其内部实现是一棵以 key 为关键码的红黑树。map的key和value可以是任意类型,其中 key 必须定义小于号运算符
(1) 声明
#include<vector>
#include<queue>
#include<stack>
#include<deque>
#include<iostream>
#include<map>
using namespace std;
int main()
{
map<int, int> a;
a[1] = 2;
a[1000000] = 3;
cout << a[1000000] << endl;
// 数据类型可以自己定义
map<string, vector<int>> b;
b["nqq"] = vector<int>({1,2,3,4});
cout << b["nqq"][2] << endl;// 结果是3
map<key_type, value_type> name;
map<long, long, bool> vis;
map<string, int> hash;
map<pair<int, int>, vector<int>> test;
}
- size/empty/clear/begin/end均与set类似
(2) insert/erase
- 与set类似,但其参数均是pair<key_type, value_type>
(3) find
- h.find(x) 在变量名为h的map中查找key为x的二元组
(4) 操作符
- h[key] 返回key映射的value的引用,时间复杂度为O(logn)
- 操作符是map最吸引人的地方。我们可以很方便地通过h[key]来得到key对应的value,还可以对h[key]进行赋值操作,改变key对应的value
(5) unorderd_set/unordered_map/bitset
#include<vector>
#include<queue>
#include<stack>
#include<deque>
#include<iostream>
#include<map>
#include<unordered_set>
#include<unordered_map>
#include<bitset>
using namespace std;
int main()
{
unordered_set<int> s;// 哈希表,不能存重复元素
unordered_multiset<int> s;// 哈希表,能存重复元素
unordered_map<int, int> c;
bitset<1000> a;// 中间是数组长度,是0-1串,只有0和1
a[0] = 1;
a[1] = 1;
cout << a.count() << endl;// 表示输出1的个数
a.set(3);// 可以把第3位设置成1
a.reset(3);// 把某一位设置成0
cout << a[3] << endl;// 1
}
(6) pair 函数
pair<int, string> a;
a = {3, "nqq"};
cout << a.first << ' ' << a.second << endl;
位运算和常用库函数
1. 位运算
- &:与
- |: 或
- ~:非
- ^: 异或
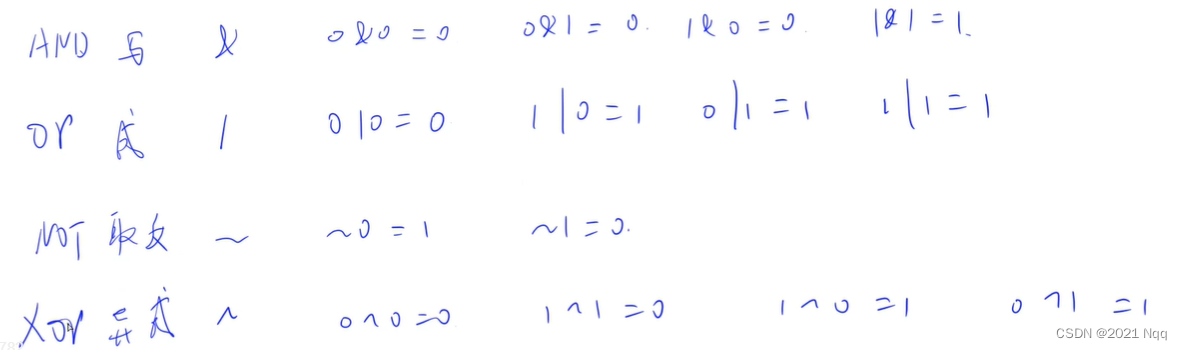
#include<iostream>
using namespace std;
int main()
{
int a = 3, b = 6;
cout << (a ^ b) << endl;// 与,加括号
return 0;
}
- >>: 右移
- <<: 左移

常用操作:
- 求 x 的第 k 位数字:x >> k & 1:向右移动k位,再和1做"与"运算

#include<iostream>
using namespace std;
int main()
{
int a = 13;
cout << (a >> 2 & 1) << endl;// 看第2为是1还是0
for(int i = 5;i >= 0; i --) cout << (a >> i & 1) << ' 0';// 输出每一位
}
- lowbit(x) = x & -x,返回x的最后一位1
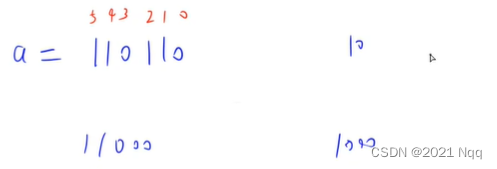
- 推导:-a = a 取反 + 1
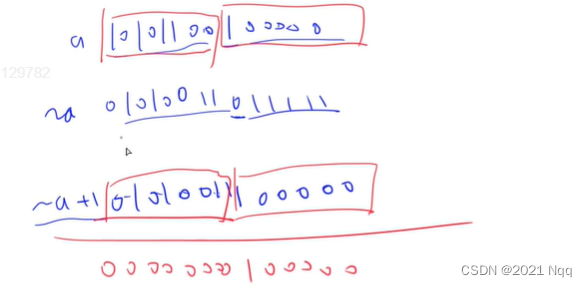
- 负a和a取反再加1效果相同
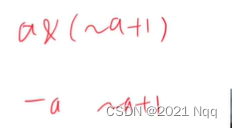
#include<iostream>
using namespace std;
int main()
{
int a = 2312321;
int b = -a;
int c = ~a + 1;
cout << b << ' ' << c << endl;// -2312321
}
2. 常用库函数(算法库#include<algorithm>)
2.1 reverse 翻转
- 翻转一个vector:
reverse(a.begin(), a.end());
- 翻转一个数组,元素存放在下标1~n:
reverse(a + 1, a + 1 + n);
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
int main()
{
vector<int> a({1,2,3,4,5});
reverse(a.begin(),a.end());
int a[] = {1, 2, 3, 4, 5};
reverse(a, a + 5);// 右边是返回的是最后一个元素的下一个位置,左闭右开,a[0] —— a[5]
for(int x : a) cout << x << ' ' ;// 5 4 3 2 1
cout << endl;
return 0;
}
2.2 unique 去重(离散化) 重点!
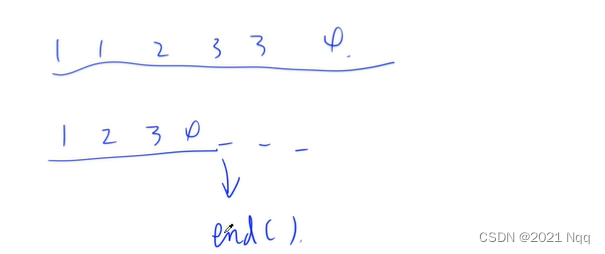
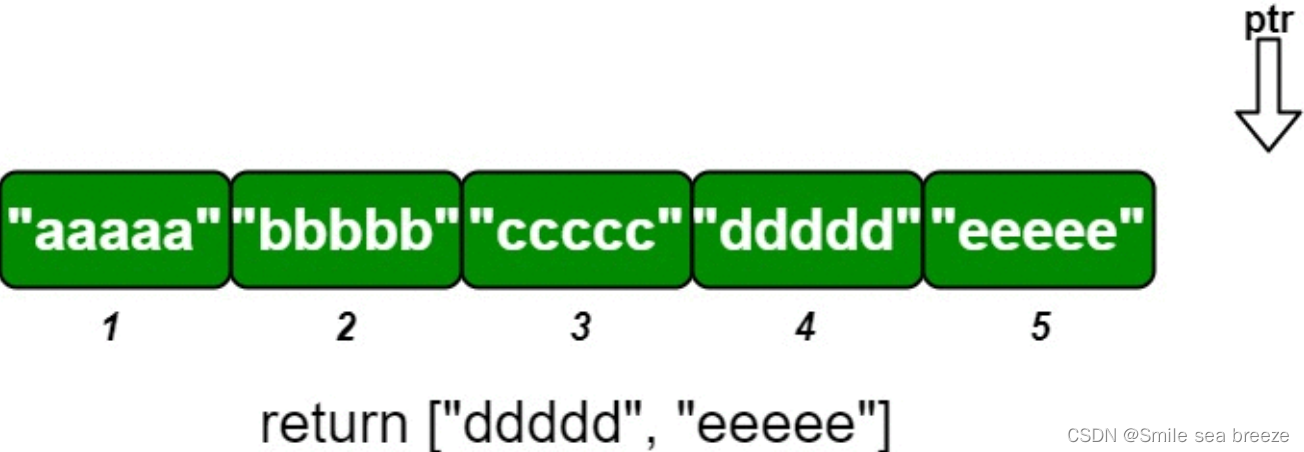
必须保证相同元素是挨着一起的,才能保证判重,会把左右不同的元素放在最前面- 返回去重之后的尾迭代器(或指针),仍然为前闭后开,即这个迭代器是去重之后末尾元素的下一个位置。该函数常用于离散化,利用迭代器(或指针)的减法,可计算去重后的元素个数
- 把一个vector去重:int m = unique(a.begin(), a.end()) – a.begin()。 unique(a.begin(), a.end())返回的是所有不同元素的最后一个元素位置的下一位,就是上图的end()位置
- 把一个数组去重,元素存放在下标 1~n(不是0 — n-1):int m = unique(a + 1, a + 1 + n) – (a + 1)
#include<iostream>
#include<vector>
#include<algorithm>
int main()
{
// 数组写法
int a[] = {1, 1, 2, 2, 3, 3, 4};
int m = unique(a, a + 7) - a;
cout << m << endl;// 结果是4
for(int i = 0; i < m; i ++) cout << a[i] << ' ';// 结果是1,2,3,4
cout << endl;
// vector写法,需要用到迭代器
vector<int> a({1, 1, 2, 2, 3, 3, 4});
int m = unique(a.begin() - a.end()) - a.begin();
cout << m << endl;// 结果是4
for(int i = 0; i < m; i ++) cout << a[i] << ' ';// 结果是1,2,3,4
cout << endl;
// 直接删除重复元素
vector<int> a({1, 1, 2, 2, 3, 3, 4});
a.erase(unique(a.begin() - a.end()), a.end());
for(auto x : a) cout << x << ' ';// 1 2 3 4
cout << endl;
return 0;
}
2.3 random_shuffle 随机打乱
- 用法与reverse相同
#include<iostream>
#include<vector>
#include<algorithm>
#include<ctime>// 传入时间,当作随机种子
using namespace std;
int main()
{
vector<int> a({1,2,3,4,5});
random_shuffle((a.begin(),a.end());// 生成随机数据,每次运行结果都不一样
// 加随机种子
srand(time(0));
for(int x : a) cout << x << ' ';
cout << endl;
// 从小到大排列
sort(a.begin(), a.end());
for(int x : a) cout << x << ' ';// 结果是 1 2 3 4 5
cout << endl;
// 从大到小排列
sort(a.begin(),a.end(),greater<int>)
}
2.4 sort 排序(重要!)
- 对两个迭代器(或指针)指定的部分进行快速排序。可以在第三个参数传入定义大小比较的函数,或者重载“小于号”运算符
- 把一个int数组(元素存放在下标1~n)从大到小排序,传入比较函数:
int a[MAX_SIZE];
bool cmp(int a, int b) {return a > b; }
sort(a + 1, a + 1 + n, cmp);
- 把自定义的结构体vector排序,重载“小于号”运算符:
struct rec{ int id, x, y; }
vector<rec> a;
bool operator <(const rec &a, const rec &b) {
return a.x < b.x || a.x == b.x && a.y < b.y;
}
sort(a.begin(), a.end());
2.5 lower_bound/upper_bound 二分
- lower_bound 第三个参数传入一个元素x,在两个迭代器(指针)指定的部分上执行二分查找,返回指向第一个大于等于x的元素的位置的迭代器(指针)
- upper_bound 用法和lower_bound大致相同,唯一的区别是查找第一个大于x的元素。当然,两个迭代器(指针)指定的部分应该是提前排好序的
- 在有序int数组(元素存放在下标1~n)中查找大于等于x的最小整数的下标:
int I = lower_bound(a + 1, a + 1 + n,. x) – a;
- 在有序vector 中查找小于等于x的最大整数(假设一定存在):
int y = *--upper_bound(a.begin(), a.end(), x);