Kafka概述
Kafka-集群管理者(Controller)选举机制
Kafka中的Controller是Kafka集群中的一个特殊角色,负责对整个集群进行管理和协调。Controller的主要职责包括分区分配、副本管理、Leader选举等。当当前的Controller节点失效或需要进行重新选举时,Kafka集群会启动一个Controller选举过程来选出新的Controller节点。
在Kafka中,Controller节点的选举机制是通过ZooKeeper来实现的。Zookeeper是一个分布式协调服务,可以用于选举和管理分布式系统中的关键角色,如Kafka中的Controller。

Controller节点选举
1.Controller候选者注册:
- 在Kafka集群启动时,每个
Broker都可以成为Controller候选者。 - 各候选者会在ZooKeeper中创建临时有序节点来表明自己的参与。
2.竞选过程:
- 每个Controller候选者会尝试创建一个ZooKeeper临时有序节点。节点的路径通常是“/controller”。
- ZooKeeper会对这些节点进行排序,具有最小序号的节点将成为新的Controller。
- 如果有多个候选者具有相同的最小序号,那么ZooKeeper将根据节点的创建时间来选择最终的Controller。
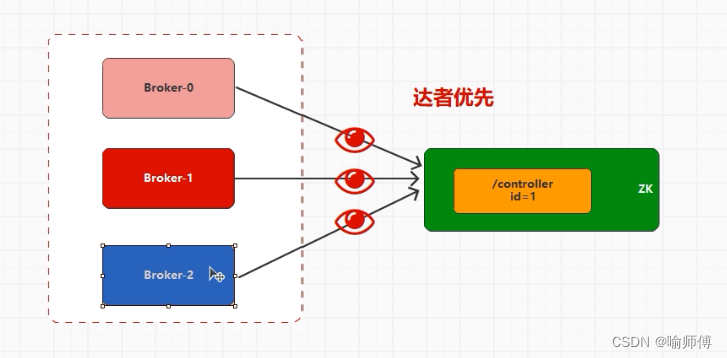
3.选举结果:
-
一旦选举完成,新的Controller节点将被选出,并且其他候选者将知道哪个节点成为了新的Controller。
-
新的Controller节点将负责管理Kafka集群的状态、执行分区分配、Leader选举等操作。
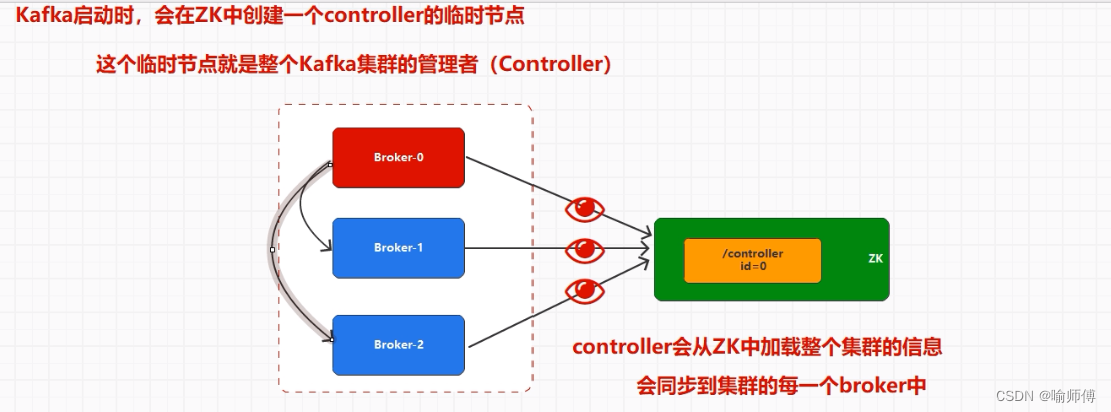
Controller节点故障
当当前的Controller节点发生故障或失效时,Kafka集群会自动触发Controller的重新选举过程。这个过程通常由ZooKeeper的临时节点和节点监听机制来保证。
1.失效检测:
- 当Kafka集群中的Controller节点失效时,集群会检测该节点是否还在正常工作。
- 失效检测可以通过心跳机制或其他健康检查来实现。
- 一旦发现当前Controller失效,集群会启动新的Controller选举。
2.候选者注册:
- 新的Controller候选者将尝试在ZooKeeper中创建临时有序节点,参与新一轮的Controller选举过程。
3.重新选举:
- ZooKeeper将重新处理候选者节点,选举出新的Controller节点。
- 新的Controller节点接管集群管理任务,确保Kafka集群的正常运行和高可用性。
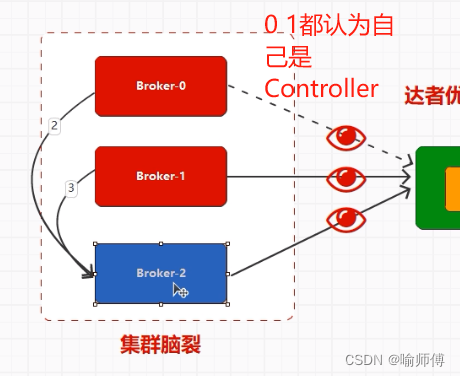
Kafka集群任期机制(脑裂现象)
在Apache Kafka中,Controller存在任期(epoch)的机制是为了解决集群脑裂(Split Brain)问题。
集群脑裂是分布式系统中常见的一种问题,指的是集群中的节点之间失去了正常通信,导致出现多个子集无法达成一致的情况。
在Kafka中,Controller的任期机制通过增加对Controller角色的细致控制和额外的元数据管理,可以有效地解决此类问题。
Controller任期(epoch)机制解决集群脑裂问题:
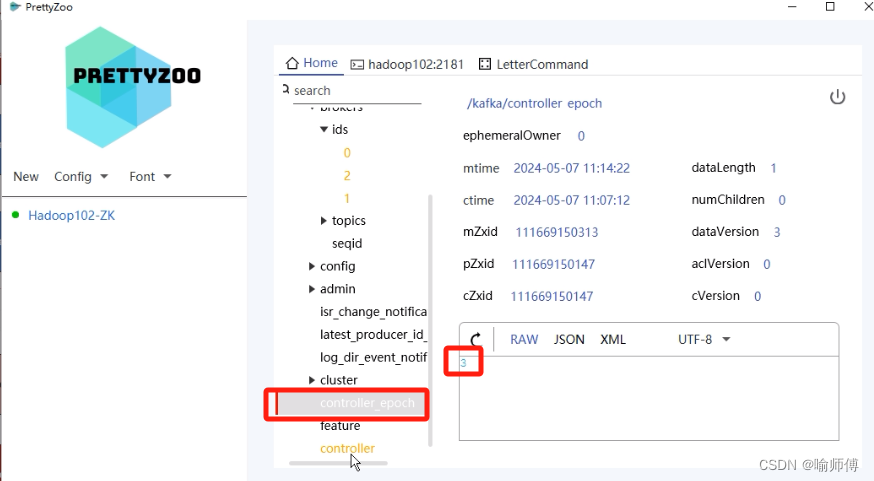
1.Controller任期概念:
- Controller在Kafka中有一个特定的任期号码(epoch),它通过ZooKeeper来进行分布式协调。
- 每次Controller选举完成后,选出的Controller节点会增加其任期号码。
- 如果某个节点成为Controller,并且同时拥有的任期号码最大,那么它就是当前的有效Controller。
2.解决集群脑裂问题:
-
当发生集群脑裂时,可能会导致多个部分集群认为自己是有效的Controller,这会导致数据不一致和操作冲突。
-
Controller任期的引入可以确保仅有任期号码最大的有效Controller拥有管理权限。
-
每个操作都会包含当前的Controller任期信息,从而确保在执行操作时只有来自有效Controller的操作才会被接受,保证了操作的一致性。
3.失效探测与恢复:
- 如果Controller节点在一段时间内无法继续提供服务(如由于网络问题等),集群中的其他节点会探测到Controller失效。
- 当失效被检测到后,会触发Controller重新选举过程,新选出的Controller将拥有更大的任期号码,成为有效的Controller来管理集群。
通过Controller存在任期的机制,Kafka有效地解决了集群脑裂问题。只有任期号码最大的Controller才会对集群的状态进行管理和操作,确保了集群的一致性和可靠性。在发生Controller失效或通信问题时,集群能够快速检测到并重新选举出新的Controller,进而保证系统的稳定运行。