Project Reactor 响应式编程
什么是响应式编程
响应式编程(Reactive Programming)是一种编程范式,致力于处理异步数据流和变化。它的核心思想是构建响应于变化的系统,即当数据流或事件发生变化时,系统能够自动地调整和响应。与传统的编程方法相比,响应式编程能够更自然地处理异步操作以及事件驱动的场景,如用户交互、实时数据更新等。
我们现实生活就是对响应式很好的解释,我们人类的举动大多都是基于事件驱动模式,当有人呼喊你的名字,你会根据这个事件来判断要不要进行应答,这个过程其实就是产生事件,然后我们作为消费者对事件进行处理,而我们的处理结果也会继续向下传递。
在响应式编程中,通常是采用异步回调的方式,回调方法的调用和控制则会由响应式框架来完成,对于应用开发来说只需要关注回调方法的实现就可以了。
在响应式编程中,有几个关键概念:
- 数据流(Streams):数据流是响应式编程中的基本构件,它表示在时间轴上异步传递的一系列事件。这些事件可以是用户输入、传感器数据、网络请求等。数据流可以被观察和转化。
- 观察者(Observers)和订阅(Subscriptions):观察者是响应式编程中的核心组件,用于接收和处理数据流中的事件。订阅则是将观察者绑定到数据流上的机制。通过订阅,观察者可以开始接收数据流中的事件。
- 操作符(Operators):操作符用于对数据流进行变换和组合。操作符可以过滤、映射、合并、分组等,使得开发者可以构建复杂的数据处理流程。常见的操作符有map、filter、flatMap、reduce等。
- 背压(Backpressure):当处理大量数据流时,消费者可能无法跟上生产者的速度。这时需要一种机制来处理这种压力,避免系统过载。背压机制允许消费者向生产者发送信号,控制数据流的生产速率。
响应式编程的优点包括:
- 简化异步编程:通过使用数据流和函数式操作符,响应式编程能够简化对异步操作和回调的处理。
- 高度可组合性:通过灵活的操作符,可以将多个数据流进行组合和变换,构建复杂的数据处理流程。
- 自动响应变化:当数据源发生变化时,响应式系统能够自动更新和响应,无需人工干预。
响应式编程的实现可以通过各种库和框架来完成。例如:
- RxJava、RxJS、RxPY:这些是ReactiveX(Rx)家族中的不同语言实现,提供了丰富的操作符和工具,帮助开发者进行响应式编程。
- Reactor:这是一个用于Java和JVM生态的响应式库,支持Reactive Streams标准。
- Akka Streams:这是一个用于处理流数据的库,基于Actor模型,适用于高吞吐量和低延迟的系统。
Reactive Streams
其中Reactive Streams是一种编程规范,专为提供一个标准的异步流处理协议,用以在Java虚拟机语言中处理带回压的流式数据。它为在JVM上构建响应式应用提供了一套公认的低层次API接口。简而言之,Reactive Streams旨在标准化响应式编程中流的处理方式。
核心概念
Reactive Streams侧重于以下几点:
- 异步处理:支持数据的异步处理,以非阻塞方式执行数据流的操作。
- 非阻塞背压:提供机制来通知数据的生产者更改其数据生成速率,防止消费者被过多的数据淹没(避免内存溢出)。
- 流式处理:强调数据流的流式处理,从而可以处理流状的数据序列(例如来自文件、网络、集合等)。
组件接口
Reactive Streams定义了四个接口:
- Publisher:<T> - 一个发布者,能够生成数据序列,并将其传输给订阅者(Subscribers)。
- Subscriber:<T> - 一个订阅者,通过订阅发布者(Publisher)来接收数据序列和通知信号。
- Subscription - 一种订阅关系,用于连接Publishers和Subscribers。它允许订阅者向发布者请求数据,或者取消订阅以停止接收数据。
- Processor:<T, R> - 它作为一个特殊的发布者(Publisher)和订阅者(Subscriber),可以转换数据,并在订阅者和发布者之间提供背压控制。
Reactive Streams 是规范,Reactor 实现了 Reactive Streams。
Reactor 进行响应式编程
传统编程与响应式编程的区别
在传统的编程范式中,我们一般通过迭代器(Iterator)模式来遍历一个序列。这种遍历方式是由调用者来控制节奏的,采用的是拉的方式。每次由调用者通过 next()方法来获取序列中的下一个值。使用反应式流时采用的则是推的方式,即常见的发布者-订阅者模式。当发布者有新的数据产生时,这些数据会被推送到订阅者来进行处理。在反应式流上可以添加各种不同的操作来对数据进行处理,形成数据处理链。这个以声明式的方式添加的处理链只在订阅者进行订阅操作时才会真正执行。
响应式流中第一个重要概念是负压(backpressure)。在基本的消息推送模式中,当消息发布者产生数据的速度过快时,会使得消息订阅者的处理速度无法跟上产生的速度,从而给订阅者造成很大的压力。当压力过大时,有可能造成订阅者本身的奔溃,所产生的级联效应甚至可能造成整个系统的瘫痪。负压的作用在于提供一种从订阅者到生产者的反馈渠道。订阅者可以通过 request()方法来声明其一次所能处理的消息数量,而生产者就只会产生相应数量的消息,直到下一次 request()方法调用。这实际上变成了推拉结合的模式。
Reactor 简介
前面提到的 RxJava 库是 JVM 上反应式编程的先驱,也是反应式流规范的基础。RxJava 2 在 RxJava 的基础上做了很多的更新。不过 RxJava 库也有其不足的地方。RxJava 产生于反应式流规范之前,虽然可以和反应式流的接口进行转换,但是由于底层实现的原因,使用起来并不是很直观。RxJava 2 在设计和实现时考虑到了与规范的整合,不过为了保持与 RxJava 的兼容性,很多地方在使用时也并不直观。Reactor 则是完全基于反应式流规范设计和实现的库,没有 RxJava 那样的历史包袱,在使用上更加的直观易懂。Reactor 也是 Spring 5 中反应式编程的基础。学习和掌握 Reactor 可以更好地理解 Spring 5 中的相关概念。
在 Java 程序中使用 Reactor 库非常的简单,只需要通过 Maven 或 Gradle 来添加对 io.projectreactor:reactor-core 的依赖即可
<dependency>
<groupId>org.projectreactor</groupId>
<artifactId>reactor-core</artifactId>
<version>1.1.6.RELEASE</version>
</dependency>
Reacot的使用场景
Reactor作为一种基于Reactive Streams规范的响应式编程库,提供了大量的操作符来处理异步的数据流,因此,它适用于多种场景下的应用开发,尤其是在需要处理高并发、大数据量或高响应性的系统中表现尤为突出。以下是一些Reactor能够发挥巨大作用的场景:
- 微服务间的非阻塞通信:在基于微服务的架构中,Reactor提供的非阻塞异步数据处理能力能显著提升服务间通信的效率和性能,适合于构建高效的微服务应用。
- 实时数据处理:对于需要实时处理数据流的应用,例如金融市场数据分析、社交媒体数据流分析等,Reactor能够有效地处理和分析实时生成的大量数据。
- 高性能Web应用:结合Spring WebFlux等框架,Reactor可以用于开发高性能的响应式Web应用,支持高并发访问和快速响应用户请求。
- 后端数据服务:Reactor能够有效地提升后端服务处理请求的能力,特别是在需要对数据库进行大量异步非阻塞IO操作时,能够显著提高数据处理速率和系统的整体性能。
- 消息驱动的应用:对于需要处理消息队列(如Kafka、RabbitMQ等)的应用,Reactor提供了灵活的响应式API来处理流式的消息,适用于构建高效、稳定的消息驱动应用。
- IoT(物联网)应用:IoT应用通常需要处理来自大量设备的数据,Reactor通过响应式流的方式能够有效地处理这些数据,同时保证低延迟和高吞吐量。
- 文件处理与批量数据处理:Reactor能够处理大量的文件I/O操作,适用于需要高效读写文件或进行大规模数据批处理的应用。
这些场景利用了Reactor的主要特点:响应式、非阻塞、支持高并发的数据处理能力。通过利用
Reactor的这些特性,可以构建出性能高效、可扩展、响应快速的应用系统。
阻塞式编程与非阻塞式编程的区别
使用Reactor等响应式编程库,确实可以将原先的阻塞式编程模型转变为非阻塞式的。
在传统的阻塞式编程中,当一个线程正在执行一个耗时的操作,比如从磁盘读取数据时,它会停留在那个操作上,直到操作完成。这意味着在这段时间里,这个线程不能执行其他任何操作。
而在响应式编程模型中,当遇到耗时的操作时,比如磁盘I/O或网络请求,程序会立即返回一个“占位符”(如Reactor中的Mono或Flux对象),而不是阻塞等待操作完成。这个过程不会占用当前线程,让它可以继续执行其他任务。一旦耗时操作完成,程序会通过回调或者流的方式处理结果,这时也可能是在另一个线程中。
执行顺序
当你使用Reactor等响应式编程库时,你的代码结构实际上会变为基于事件的非阻塞模型。在这种模型中,IO操作(如读取文件、数据库查询、网络请求等)不会立即执行,而是注册一个操作,在未来的某个时间点完成,并通过回调机制返回结果。
这意味着在Reactor流中放置的耗时异步操作(如从磁盘读取数据)会在背后异步执行,而主线程可以继续向下执行其他代码。这个异步任务完成并产生结果的时间点,可能会在主线程执行完接下来的一些代码之后。这是非阻塞I/O模型的一大优点,它允许系统在等待耗时的I/O操作完成时,可以处理其他任务,提高了程序的整体效率和响应性。
简单来说,当使用Reactor开发响应式应用时,流中的异步操作不会阻塞调用线程。而调用线程继续执行位于异步调用之后的代码是完全可能的。异步操作真正完成并处理结果(比如读取数据并处理)是在未来的某个时间点,并且这个处理可能由不同的线程完成,这取决于你的调度策略和Reactor上下文。这种方式提高了程序的并发性和吞吐量,但同时也要求开发者更加注意数据的同步和执行顺序。
Reactor结果返回时机
Reactor事件完成后,不会立即中断当前命令去执行回调函数。在Reactor等响应式编程库中,当异步操作完成并准备好调用其回调函数(或者处理结果的操作链)时,并不会中断当前正在执行的其他任务。相反,这些通过回调函数或者操作链处理的操作将会按照响应式流的调度策略在适当的时间和线程上执行。
响应式编程模型中,回调函数或者结果处理通常是在事件循环或者特定的调度线程中执行的。Reactor库提供了多种Scheduler,可以让这些操作异步地在不同的线程中执行,而不会干扰当前正在执行的代码流。这就意味着,回调函数或者响应式流中的操作符处理不会"中断"正在执行的操作,而是在一个合适的时机,通常是当前操作完成后,按照调度的策略来执行。
例如,如果你使用subscribeOn(Schedulers.elastic())来指定一个操作,那么当操作完成后,它的结果会被安排在一个弹性的线程池中处理,而不会影响到主线程或当前执行线程的其他操作。
当然,如果是在单线程环境或特定情况下,如使用Schedulers.immediate()(即立即执行调度器),回调或结果处理可以在同一线程上紧接着之前的操作执行,但仍然不会造成中断,而是顺序执行。
总的来说,Reactor等响应式编程模型通过合理的调度策略和事件循环管理,确保了所有操作(包括回调函数的执行)都以高效和可预测的方式进行,而不会导致执行流程的无序中断。
Reactor与主线程关系
当主函数(或主线程)的代码执行完毕,但Reactor响应式流中的异步操作还未完成时,程序是否结束取决于应用程序的类型和如何管理这些异步任务。
在传统的Java应用程序中,如果主线程结束了,但是还有非守护(non-daemon)线程在运行,则JVM进程不会立即退出,它会等待所有非守护线程执行完成。因此,如果你的Reactor流正在非守护线程上异步执行,则即使主线程结束了,JVM进程也会等待异步任务完成。
然而,Reactor框架底层使用的是守护线程(Daemon Threads)来执行异步任务。守护线程的特点是,不会阻止JVM的退出。也就是说,如果主线程执行完成而异步操作还未来得及完成,程序可能会直接终止,Reactor流中的异步任务也会随之中断,不会执行到最终的回调函数。
为了确保Reactor流中所有异步任务都能完整执行,一种常见的做法是在主线程中显式等待这些异步任务的完成。这可以通过订阅响应式流并阻塞等待其完成来实现。Reactor提供了block()方法,用于等待Mono或Flux的单个或多个结果。但需要注意的是,长时间阻塞主线程(尤其是在Web应用中)通常不是最佳实践,因为这会降低程序的响应性。
或者,使用计数器、CountDownLatch等同步辅助类等待异步任务的完成,也是处理这种情况的一种方式。
综上所述,如果不采取措施确保异步任务完成,当主函数或主线程结束时,使用Reactor框架的异步任务可能会因为程序结束而未能完成。因此,在设计应用时,应该考虑如何确保异步操作能够完整执行,特别是在命令行或单线程应用程序中。
Reactor的类型
Reactor有两种类型,Flux<T>和Mono<T>。Flux类似RaxJava的Observable,它可以触发零到多个事件,并根据实际情况结束处理或触发错误。
Mono最多只触发一个事件,它跟RxJava的Single和Maybe类似,所以可以把Mono用于在异步任务完成时发出通知。
因为这两种类型之间的简单区别,我们可以很容易地区分响应式API的类型:从返回的类型我们就可以知道一个方法会“发射并忘记”或“请求并等待”(Mono),还是在处理一个包含多个数据项的流(Flux)。
Flux和Mono的一些操作利用了这个特点在这两种类型间互相转换。例如,调用Flux的single()方法将返回一个Mono,而使用concatWith()方法把两个Mono串在一起就可以得到一个Flux。类似地,有些操作对Mono来说毫无意义(例如take(n)会得到n>1的结果),而有些操作只有作用在Mono上才有意义(例如or(otherMono))。
Reactor设计的原则之一是要保持API的精简,而对这两种响应式类型的分离,是表现力与API易用性之间的折中。
Flux 和 Mono 是 Reactor 中的两个基本概念。Flux 表示的是包含 0 到 N 个元素的异步序列。在该序列中可以包含三种不同类型的消息通知:正常的包含元素的消息、序列结束的消息和序列出错的消息。当消息通知产生时,订阅者中对应的方法 onNext(), onComplete()和 onError()会被调用。Mono 表示的是包含 0 或者 1 个元素的异步序列。该序列中同样可以包含与 Flux 相同的三种类型的消息通知。Flux 和 Mono 之间可以进行转换。对一个 Flux 序列进行计数操作,得到的结果是一个 Mono<Long>对象。把两个 Mono 序列合并在一起,得到的是一个 Flux 对象。
其中,序列结束的消息和序列出错的消息都代表终止消息,终止消息用于告诉订阅者数据流结束了,错误消息终止数据流同时把错误信息传递给订阅者。
三种消息的特点:
- 错误消息和完成消息都是终止消息,不能共存
- 如果没有发送任何元素值,而是直接发送错误或者完成消息,表示是空数据流
- 如果没有错误消息,也没有完成消息,表示是无限数据流
具体特点
由于响应流的特点,我们不能再返回一个简单的POJO对象来表示结果了。必须返回一个类似Java中的Future的概念,在有结果可用时通知消费者进行消费响应。
Reactive Stream规范中这种被定义为Publisher
Publisher是一个可以提供0-N个序列元素的提供者,并根据其订阅者Subscriber<? super T>的需求推送元素。
一个Publisher可以支持多个订阅者,并可以根据订阅者的逻辑进行推送序列元素。
下面这个Excel计算就能说明一些Publisher的特点。
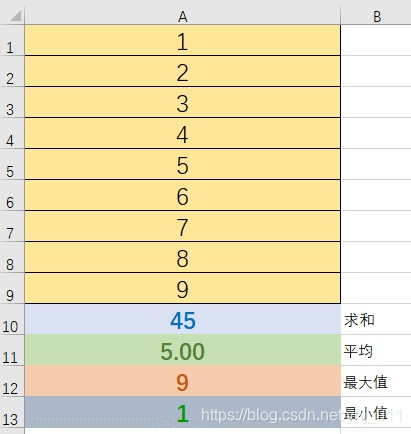
A1-A9就可以看做Publisher及其提供的元素序列。
A10-A13分别是求和函数SUM(A1:A9)、平均函数AVERAGE(A1:A9)、最大值函数MAX(A1:A9)、最小值函数MIN(A1:A9),
A10-A13可以看作订阅者Subscriber。
假如说我们没有A10-A13,那么A1-A9就没有实际意义,它们并不产生计算。
这也是响应式的一个重要特点:当没有订阅时发布者什么也不做。而Flux和Mono都是Publisher在Reactor 3实现。
Publisher提供了subscribe方法,允许消费者在有结果可用时进行消费。
如果没有消费者Publisher不会做任何事情,他根据消费情况进行响应。
Publisher可能返回零或者多个,甚至可能是无限的,为了更加清晰表示期待的结果就引入了两个实现模型Mono和Flux。
Flux
Flux 是一个发出(emit)0-N个元素组成的异步序列的Publisher,可以被onComplete信号或者onError信号所终止。
在响应流规范中存在三种给下游消费者调用的方法 onNext, onComplete, 和onError。下面这张图表示了Flux的抽象模型:
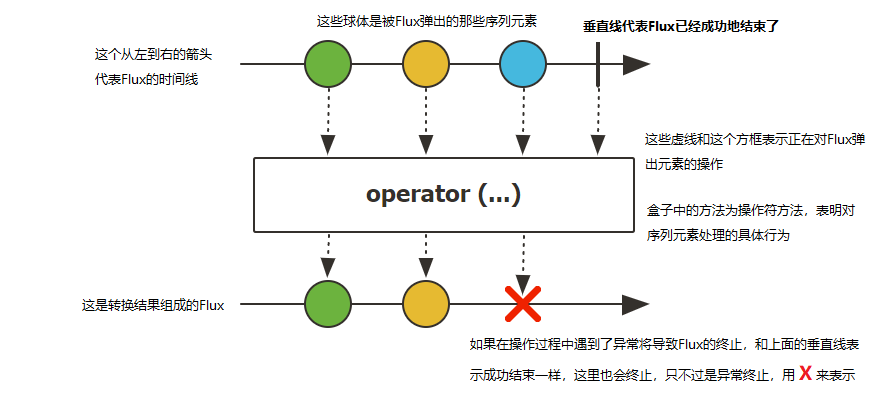
Flux<T>是一个标准Publisher<T>,表示0到N个发射项的异步序列,可选地以完成信号或错误终止。与Reactive Streams规范中一样,这三种类型的信号转换为对下游订阅者的onNext()、onComplete()或onError()方法的调用。
在这种大范围的可能信号中,Flux是通用的reactive 类型。注意,所有事件,甚至终止事件,都是可选的:没有onNext事件,但是onComplete事件表示一个空的有限序列,但是移除onComplete并且您有一个无限的空序列(除了关于取消的测试之外,没有特别有用)。同样,无限序列不一定是空的。例如,Flux.interval(Duration) 产生一个Flux<Long>,它是无限的,从时钟发出规则的数据。
在Reactor中使用Flux序列时,如果序列中的某个元素处理过程中发生了异常,那么在异常发生之前的元素可以正常执行。Reactor的错误处理机制确保了这一点。具体来说,Flux序列中的每个元素都是依次处理的,如果在处理某个元素时发生异常,Reactor会将这个异常传递给订阅者的错误处理函数(如果提供了的话),而不是立即终止整个程序。
比如,你有一个处理若干个元素的Flux流,并且每个元素的处理都可能抛出异常。在这种情况下,可以为这个Flux流设置错误处理逻辑。这样,当处理某个元素时发生异常,之前的元素因为已经被处理过,不会受到影响,而发生异常的元素及其之后的元素的处理会根据你设置的错误处理逻辑来决定程序的行为。你可以决定是终止流的处理,还是跳过出错的元素继续处理后面的元素,或者是执行其他的一些恢复策略。
Reactor提供了多种错误处理操作符,如onErrorResume、onErrorReturn、onErrorMap等,允许你灵活地处理错误。例如:
- 使用
onErrorResume可以在发生错误时提供一个新的数据流作为替代,继续流的处理。 onErrorReturn可以在出错的时候提供一个备用的值,替换异常的元素,然后继续执行。onErrorMap允许你将某个类型的异常映射(转换)成另一种异常。
下面是一个简单的例子,展示了如何使用onErrorResume来处理错误:
Flux.just(1, 2, 0, 3, 4)
.map(x -> 1 / x) // 这里0会导致异常
.onErrorResume(e -> Flux.just(-1)) // 发生错误时发射-1并继续
.subscribe(System.out::println, System.err::println);
在这个例子中,当尝试处理元素0时会发生ArithmeticException,然后触发onErrorResume指定的逻辑,输出-1并结束流。请注意,触发错误的元素(0)及其之后的元素(3和4)不会被处理,因为流已经转向了错误处理逻辑。
综上所述,在Reactor中,Flux序列中的元素在处理过程中发生异常不会影响之前元素的正常执行,你可以通过错误处理操作符来控制异常之后的行为。
Flux简单创建
-
just():可以指定序列中包含的全部元素。创建出来的Flux序列在发布这些元素之后会自动结束 -
fromArray(),fromIterable(),fromStream():可以从一个数组,Iterable对象或Stream对象中穿件Flux对象 -
empty():创建一个不包含任何元素,只发布结束消息的序列 -
error(Throwable error):创建一个只包含错误消息的序列 -
never():传建一个不包含任务消息通知的序列 -
range(int start, int count):创建包含从start起始的count个数量的Integer对象的序列 -
interval(Duration period)和interval(Duration delay, Duration period):创建一个包含了从0开始递增的Long对象的序列。其中包含的元素按照指定的间隔来发布。除了间隔时间之外,还可以指定起始元素发布之前的延迟时间 -
intervalMillis(long period)和intervalMillis(long delay, long period):与interval()方法相同,但该方法通过毫秒数来指定时间间隔和延迟时间
Flux.just("Hello", "World").subscribe(System.out::println);
Flux.fromArray(new Integer[]{1, 2, 3}).subscribe(System.out::println);
Flux.empty().subscribe(System.out::println);
Flux.range(1, 10).subscribe(System.out::println);
Flux.interval(Duration.of(10, ChronoUnit.SECONDS)).subscribe(System.out::println);
Flux.intervalMillis(1000).subscirbe(System.out::println);
复杂的序列创建 generate()
当序列的生成需要复杂的逻辑时,则应该使用generate()或create()方法。
generate()方法通过同步和逐一的方式来产生Flux序列。
序列的产生是通过调用所提供的的SynchronousSink对象的next(),complete()和error(Throwable)方法来完成的。
逐一生成的含义是在具体的生成逻辑中,next()方法只能最多被调用一次。
在某些情况下,序列的生成可能是有状态的,需要用到某些状态对象,此时可以使用
generate(Callable<S> stateSupplier, BiFunction<S, SynchronousSink<T>, S> generator),
其中stateSupplier用来提供初始的状态对象。
在进行序列生成时,状态对象会作为generator使用的第一个参数传入,可以在对应的逻辑中对改状态对象进行修改以供下一次生成时使用。
第一个序列的生成逻辑中通过next()方法产生一个简单的值,然后通过complete()方法来结束该序列。如果不调用complete()方法,所产生的是一个无限序列。第二个序列的生成逻辑中的状态对象是一个 ArrayList 对象。实际产生的值是一个随机数。产生的随机数被添加到 ArrayList 中。当产生了 10 个数时,通过complete()方法来结束序列
Flux.generate(sink -> {
sink.next("Hello");
sink.complete();
}).subscribe(System.out::println);
final Random random = new Random();
Flux.generate(ArrayList::new, (list, sink) -> {
int value = random.nextInt(100);
list.add(value);
sink.next(value);
if( list.size() ==10 )
sink.complete();
return list;
}).subscribe(System.out::println);
复杂的序列创建 create()
create()方法与generate()方法的不同之处在于所使用的是FluxSink对象。
FluxSink支持同步和异步的消息产生,并且可以在一次调用中产生多个元素。
在一次调用中就产生了全部的 10 个元素。
Flux.create(sink -> {
for(int i = 0; i < 10; i ++)
sink.next(i);
sink.complete();
}).subscribe(System.out::println);
Mono
Mono 是一个发出(emit)0-1个元素的Publisher,可以被onComplete信号或者onError信号所终止。

Mono整体和Flux差不多,只不过这里只会发出0-1个元素。也就是说不是有就是没有。
Mono<T>是一个专门的Publisher<T>,它最多发出一个项,然后可选地以onComplete信号或onError信号结束。
它只提供了可用于Flux的操作符的子集,并且一些操作符(特别是那些将Mono与另一个发布者组合的操作符)切换到Flux。
例如,Mono#concatWith(Publisher)返回一个Flux ,而Mono#then(Mono)则返回另一个Mono。
注意,Mono可以用于表示只有完成概念(类似于Runnable)的无值异步进程。若要创建一个,请使用Mono<Void>。
Mono特有静态方法
Mono类包含了与Flux类中相同的静态方法:just(),empty()和never()等。
除此之外,Mono还有一些独有的静态方法:
-
fromCallable(),fromCompletionStage(),fromFuture(),fromRunnable()和fromSupplier():分别从Callable,CompletionStage,CompletableFuture,Runnable和Supplier中创建Mono -
delay(Duration duration)和delayMillis(long duration):创建一个Mono序列,在指定的延迟时间之后,产生数字0作为唯一值 -
ignoreElements(Publisher source):创建一个Mono序列,忽略作为源的Publisher中的所有元素,只产生消息 -
justOrEmpty(Optional<? extends T> data)和justOrEmpty(T data):从一个Optional对象或可能为null的对象中创建Mono。只有Optional对象中包含之或对象不为null时,Mono序列才产生对应的元素
Mono.fromSupplier(() -> "Hello").subscribe(System.out::println);
Mono.justOrEmpty(Optional.of("Hello")).subscribe(System.out::println);
Mono.create(sink -> sink.success("Hello")).subscribte(System.out::println);
具体用法参考:
Reactor Mono和Flux 进行反应式编程详解
Flux 和 Mono 、reactor实战 (史上最全)
Project Reactor 响应式编程
在redis中的简单应用:
【Java开发】 Spring 05 :Project Reactor 响应式流框架(以Reactive方式访问Redis为例)