What’s Flink-cdc?
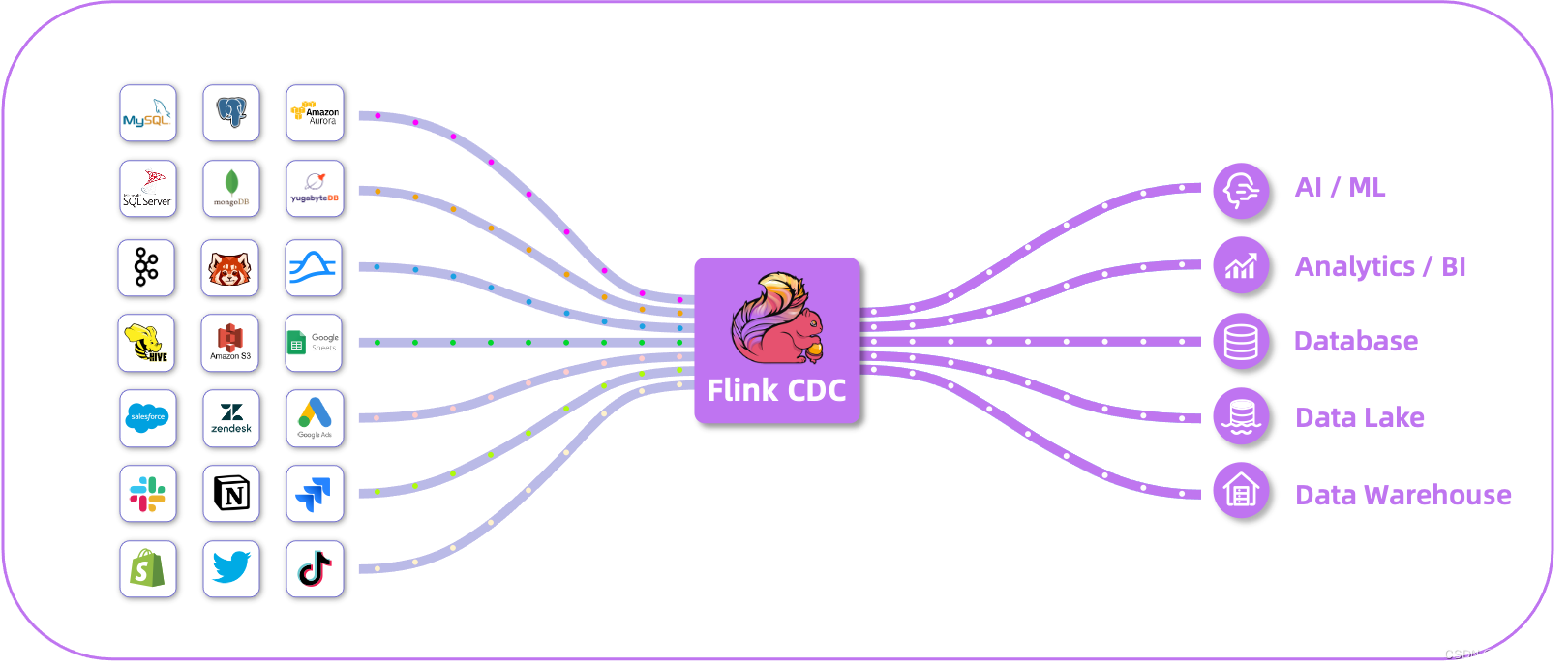
Flink CDC 是基于Apache Flink的一种数据变更捕获技术,用于从数据源(如数据库)中捕获和处理数据的变更事件。CDC技术允许实时地捕获数据库中的增、删、改操作,将这些变更事件转化为流式数据,并能够对这些事件进行实时处理和分析。
Flink CDC提供了与各种数据源集成的功能,包括常见的关系型数据库(如MySQL、PostgreSQL、Oracle等)以及NoSQL数据库(如MongoDB、HBase等)。它通过监控数据库的日志或轮询方式来捕获数据变更,并将变更事件作为数据流发送到Flink的任务中进行处理。
Flink CDC 深度集成并由 Apache Flink 驱动,提供以下核心功能:
✅ 端到端的数据集成框架
✅ 为数据集成的用户提供了易于构建作业的 API
✅ 支持在 Source 和 Sink 中处理多个表
✅ 整库同步
✅具备表结构变更自动同步的能力(Schema Evolution)
在使用者的角度,就是Flink-cdc可以简化流处理的流程:
-
引入Flink-cdc之前流处理流程

-
引入Flink-cdc之后后流处理流程

如上所示,在flink-cdc被引入后大大简化了流处理流程
Flink-cdc支持的链接及对应的版本
Pipeline Connectors
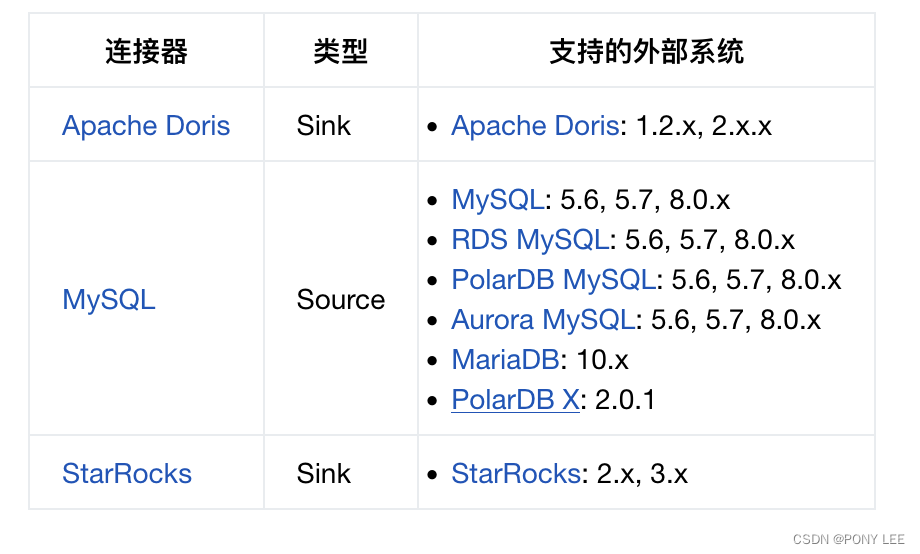
Source Connectors
 截止目前(2024-05-23)
截止目前(2024-05-23)
Flink-cdc与Flink对应对影版本的关系
 截止目前(2024-05-23)
截止目前(2024-05-23)
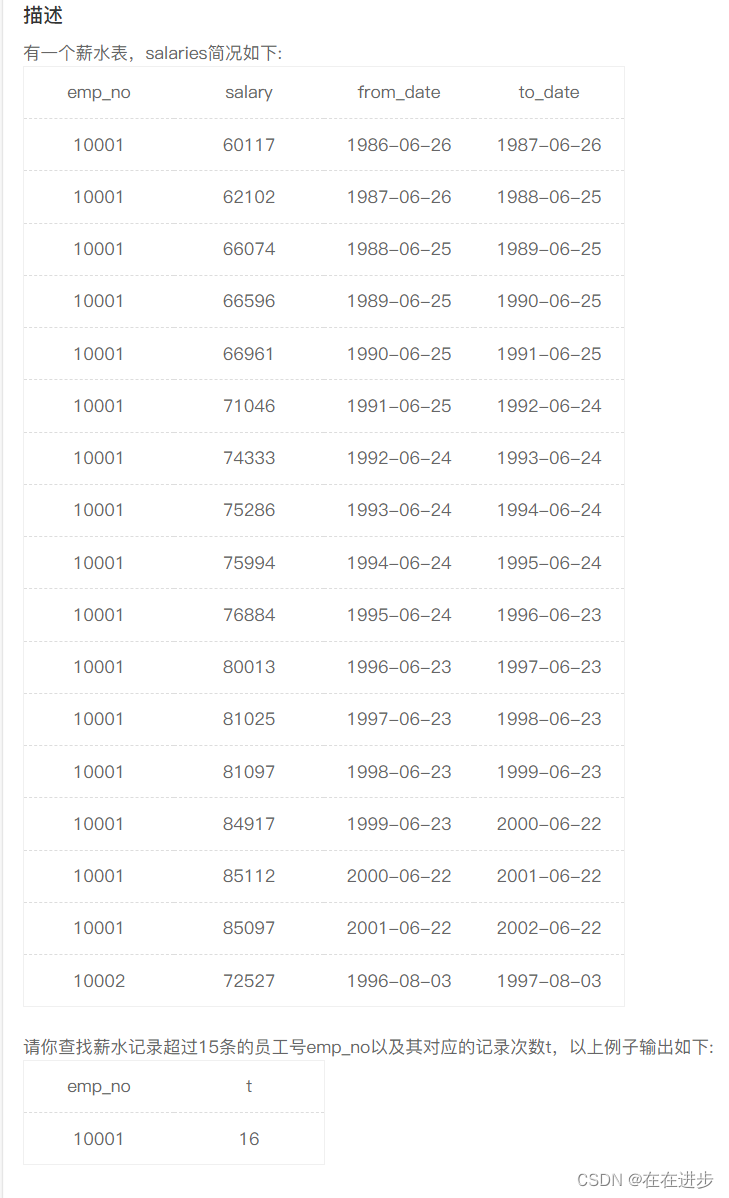
flink-connector-mysql-cdc 实例分析
示例代码
demo代码:
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.runtime.state.hashmap.HashMapStateBackend;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class MySqlSourceDemo {
public static void main(String[] args) throws Exception {
MySqlSource<String> mySqlSource = MySqlSource.<String>builder()
.hostname("mysql-server-host")
.port(3306)
.databaseList("mydb") // 设置捕获的数据库
.tableList("mydb.products") // 设置捕获的表,如果需要同步整个数据库,请将 tableList 设置为 ".*".
// .tableList(".*") // 捕获整个数据库的表
// .tableList("^(?!mysql|information_schema|performance_schema).*") // 设置捕获的表,排除系统库
// .tableList("mydb.(?!products|orders).*") // 同步排除products和orders表之外的整个my_db库
.username("flink-cdc")
.password("xxx")
.serverId("5400-5405")
.deserializer(new JsonDebeziumDeserializationSchema()) // 将 SourceRecord 转换为 JSON 字符串
.serverTimeZone("Asia/Shanghai") // 设置时区
.startupOptions(StartupOptions.initial())
.scanNewlyAddedTableEnabled(true) // 启用扫描新添加的表功能
// .includeSchemaChanges(true) // 包括 schema 变更
.build();
org.apache.flink.configuration.Configuration config = new org.apache.flink.configuration.Configuration();
config.setString("rest.port", "8081");
// StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment(config); //本地环境,调试用
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置 3s 的 checkpoint 间隔
env.enableCheckpointing(3000);
env.setStateBackend(new HashMapStateBackend());
env.getCheckpointConfig().setCheckpointStorage("file:///tmp/ck");//本地文件系统
// env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); 1.14.0 版本开始支持
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.fromSource(mySqlSource, WatermarkStrategy.noWatermarks(), "MySQL Source")
// 设置 source 节点的并行度为 4
.setParallelism(5)
.print()
.setParallelism(1); // 设置 sink 节点并行度为 1
env.execute("Print MySQL Snapshot + Binlog");
}
}
maven依赖:
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.14.5</flink.version>
<scala.binary.version>2.12</scala.binary.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<scope>test</scope>
</dependency>
<!-- 将 Apache Flink 的 Web 运行时模块添加到项目中 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>provided</scope> <!--provided生命周期在test模式才可以运行,在main模式会找不到包-->
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>2.3.0</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
<scope>provided</scope>
</dependency>
</dependencies>
日志配置文件:
log4j.properties
log4j.rootCategory=error,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %p %c{1}:%L - %m%n
启动standalone Flink级群
# jobmanager
docker run -d \
--name flink-jm \
--hostname flink-jm \
-p 8082:8081 \
--env FLINK_PROPERTIES="jobmanager.rpc.address: flink-jm" \
--network flink-network-standalone \
ponylee/flink:1.15.0-java8 \
jobmanager
# taskmanager
docker run -d \
--name flink-tm \
--hostname flink-tm \
--env FLINK_PROPERTIES="jobmanager.rpc.address: flink-jm" \
--network flink-network-standalone \
ponylee/flink:1.15.0-java8 \
taskmanager \
-Dtaskmanager.memory.process.size=1024m \
-Dtaskmanager.numberOfTaskSlots=5 \
-Drest.flamegraph.enabled=true
分析说明
为每个 Reader 设置不同的 Server id
每个用于读取 binlog 的 MySQL 数据库客户端都应该有一个唯一的 id,称为 Server id。 MySQL 服务器将使用此 id 来维护网络连接和 binlog 位置。 因此,如果不同的作业共享相同的 Server id, 则可能导致从错误的 binlog 位置读取数据。 因此,建议通过为每个 Reader 设置不同的 Server id , 假设 Source 并行度为 4,server id 配置必须:serverId(“5400-5405”),5405-5400=5 >= 4。来为 4 个 Source readers 中的每一个分配唯一的 Server id。
查看mysql链接发现
select * from information_schema.processlist where user = ‘flink-cdc’;
 Flink-cdc对mysql的影响
Flink-cdc对mysql的影响
正常情况下,Flink-cdc是No-lock Read,主库可以继续处理事务和查询,而不会导致主库进程阻塞,不会对主库产生直接影响。但是,在某些情况下数据同步的过程中可能会对主库产生一些间接影响,比如:网络、IO、CPU负载以及mysql的并发连接数等资源消耗。但这些对主库的开销影响相对较小(全量同步阶段可能比较耗能,但时间相对比较短)。
断点续传
通过从checkpoint/savepoint 恢复,flink-cdc可以保证断点续传。
-
从checkpoint/savepoint恢复,缩小同步范围,例如:从tableList(“mydb.products,mydb.orders”)或tableList(“.*”) 缩小到 tableList(“mydb.products”),应用更新生效。
-
应用从checkpoint/savepoint恢复,扩大同步范围的部分不会生效,例如:从tableList(“mydb.products”) 到 tableList(“mydb.products,mydb.orders”)或tableList(“.*”),应用更新不生效生效。若想使动态加表生效,可以显示制定scanNewlyAddedTableEnabled(true) ,来启用扫描新添加的表功能。如没有特殊情况,建议在开发环境开启此配置。
参考:
flink-cdc
flink-cdc docs