论文:AHPPEBot: Autonomous Robot for Tomato Harvesting based on Phenotyping and Pose Estimation
作者:Xingxu Li, Nan Ma, Yiheng Han, Shun Yang, Siyi Zheng
收录:ICRA2024
编辑:东岸因为@一点人工一点智能
AHPPEBot:基于表型和姿态估计的自主番茄采摘机器人在本文中,我们设计了一个名为AHPPEBot的先进机器人,专门用于自动采摘番茄。为了确保机器人采摘的自主性和精确性,我们整合了两个关键技术:基于对象检测的快速表型学方法和用于番茄托架的姿态估计技术。![]() https://mp.weixin.qq.com/s/HFMIB5yv3jqdMveDAClwaw
https://mp.weixin.qq.com/s/HFMIB5yv3jqdMveDAClwaw
01 简要
为了应对传统自动化采摘机器人固有的局限性,特别是其不理想的采摘成功率和可能对作物造成损害的风险,我们设计了一种新型机器人:AHPPEBot,它能够基于作物表型和姿态估计进行自主采摘。
具体来说,在表型方面,通过一个多任务的YOLOv5模型,结合一个基于检测的自适应DBScan聚类算法,实现了番茄托架和单个果实的检测、关联和成熟度估计。在姿态估计方面,我们使用一个深度学习模型来预测果梗上的七个语义关键点。这些关键点有助于机器人的路径规划,最小化目标接触,并有助于我们专门设计的末端执行器进行采摘。
在商业温室进行的自主番茄采摘实验中,我们提出的机器人取得了86.67%的采摘成功率,平均成功采摘时间为32.46秒,展示了其连续和稳健的采摘能力。结果突出了采摘机器人填补农业劳动力短缺的潜力。
02 相关工作
在使机器人能够自主进行选择性采摘方面,认识、解析和理解作物环境中的作物至关重要。早期的研究主要通过图像处理技术(如颜色分割和形态运算)或机器学习方法([7]-[13])来识别和定位果实。
最近的进展表明,基于深度学习模型的感知技术在真实世界场景中的检测、分类和分割挑战中比传统方法更具鲁棒性。Zhang等人[11]使用CNN对番茄图像进行成熟度分类,而Afonso等人[12]使用Mask R-CNN在温室中检测成熟的和不成熟的番茄,实现了令人称赞的准确性和鲁棒性。
作物姿态或坐标的准确确定对于准确的采摘至关重要。Wei等人[14]使用Mask R-CNN提取葡萄串的像素区域,并使用RANSAC算法将点云拟合成圆柱形形状以确定姿态。Rong等人[15]使用YOLOv4-Tiny检测番茄束的主体和梗,使用YOLACT++模型对梗进行语义分割,然后使用最小二乘法将其拟合为曲线,得到三个关键点,并最终通过几何模型估计梗的姿态。Li等人[16]使用多摄像头系统和DCNN模型检测苹果目标,从可见目标点云中重构被遮挡的部分,并估计果实中心。在Alessandra等人[17]的方法中,为每个番茄定义了五个关键点,作为执行抓取动作的末端执行器参考点。Fan等人[18]提出了一种基于关键点的番茄束姿态估计方法。他们的方法仅限于含有六个果实的托架。即使在作物检测和采摘点定位完成后,实际的采摘过程仍然可能失败。在采摘过程中,配备有末端执行器的机械手臂可能会由于障碍物、姿态估计错误或作物损害而失败。
在2017年,Bac等人[19]在CROPS(聪明机器人作物)项目下设计了一个甜椒采摘机器人,在商业温室中使用两种不同的末端执行器进行实验。Lehner等人[9]设计了一个名为“Harvey”的甜椒采摘机器人,通过吸力吸取目标并使用刀片切割梗。在特定失败案例中,由于甜椒不规则的形态导致模型估计的抓取角度偏差。因此,刀片无法准确切断梗,或者不小心造成果实损害。Gao等人[6]研究了一个两指夹持器末端执行器,用于从樱桃番茄托架上采摘单个果实。
回顾先前的研究,采摘失败的原因可以归类为以下几点:不准确的果实定位、叶丛或果实聚团的障碍物、极端的果实位置、作物损害和分离失败。
03 方法
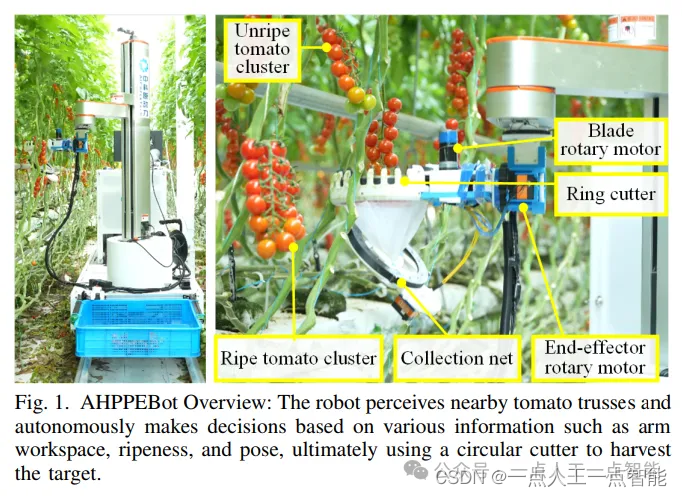
AHPPEBot专为商业温室环境中的自动化托架番茄采摘而设计,如图1所示。采摘系统可以分为四个主要组件:“表型学”、“姿态估计”、“信息融合”和“决策与运动规划”。系统算法和工作流程的流程图如图2所示。
我们预计,通过优化感知技术和末端执行器设计,并精确规划基于作物姿态的机器人手臂运动,我们可以最小化不必要的接触,从而实现提高采摘成功率和安全性的目标。
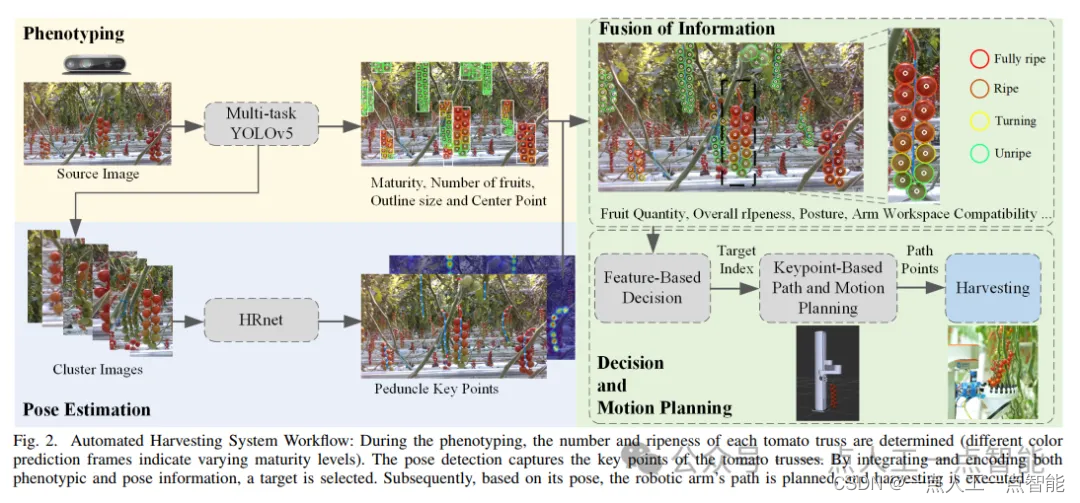
3.1 平台设计
AHPPEBot的硬件架构由五个主要组件组成:两个RGB-D摄像头、一个机器人手臂、一个末端执行器、一个计算单元和一个移动底盘。考虑到温室内部空间的狭窄,我们选择了一个SCARA机器人手臂,并在其末端增加了旋转电机,如图1所示。这种配置旨在简化机器人手臂的路径规划,同时保持灵活性。
执行器的表面特征有多处尖刺状引导凹槽和锯齿状刀片。根据番茄藤和托架果梗的宽度量身定制凹槽尺寸,确保只有果梗可以插入并被切割,同时防止藤蔓进入,提高安全性。一旦切断果梗,番茄托架暂时收集在网格口袋中。
3.2 表型学
成熟度、果实数量和果实大小是采摘和质量分级的重要表型信息。我们采用一种方法,根据每个果实的状态推断托架的整体成熟度和质量分级。
在本论文中,果实成熟度根据农业标准分为四个阶段:绿熟、变色、成熟和完全成熟,如图2所示。同时,我们规定如果托架末端的果实达到变色阶段,且其余果实为成熟或更高级别,则整体托架被视为成熟,适合采摘、储存和运输。这一标准与我们实验所在温室生产基地的采摘标准一致。
我们增强了YOLOv5模型以进行多任务处理,在预测部分引入了一个额外的分支来确定果实成熟度。我们设计的基于原YOLOv5损失函数的多任务YOLOv5损失函数如下所示:
![]()
其中λ代表不同损失函数的权重。表示分类损失,
表示置信度损失,
表示边界框损失。使用二元交叉熵损失函数
来计算番茄果实成熟度损失。
尽管模型可以检测到每个单独的果实,但它并没有提供果实与番茄托架之间的关系。我们根据果实与番茄托架的2D/3D空间关系进行匹配和分组,从而获得给定托架内的果实数量和成熟度信息。在2D空间中,我们计算果实边界框与番茄托架边界框的交并比(IOU),以确定一个果实是否属于特定的托架。然而,当多个番茄托架在摄像头的视场中重叠时,此算法可能会产生匹配错误。为解决此问题,我们采用点云聚类来区分前景和背景中的重叠番茄托架,从而确定果实的归属。
传统的DBScan聚类在最近的邻域搜索和随机初始点选择上存在大量且低效的问题,影响了其计算速度。我们提出了一种基于对象检测的自适应DBScan算法。检测结果中的边界框提供了目标空间位置的先验知识。通过精确裁剪番茄托架的精确边界框,实现对输入点云的精确裁剪,消除了对完整点云计算的需求。使用果实边界框的中心点作为聚类的初始点集,实现对高密度目标点云的自适应选择。通过采用自适应输入裁剪和初始点选择,可以显著减少附近的搜索次数,从而显著提高计算速度。此外,聚类算法的阈值可以根据各种番茄托架品种的结构先验知识进行确定。
为了快速估计果实体积并确定其空间位置,我们不对深度相机返回的点云中的每个果实现的精确点云进行分区。相反,我们在图像中使用与矩形预测边界框的平均宽度和高度相等的圆形来近似果实轮廓。结合深度相机的内在参数,我们进行反投影,在三维空间中生成球形虚拟点云,为路径规划期间的碰撞检测做准备,如图2所示。这种估计方法具有低计算复杂性,且对于我们的采摘方法,误差在可接受的范围内。
3.3 姿态估计
为了更好地支持机械臂路径规划,我们融入了番茄果穗的结构先验知识,并定义了七个果梗关键点。它们的命名和缩写如图3所示。SP、CP和FP以及它们之间的连接曲线代表可以切割的果梗部分。
SP位于番茄果穗的梗与主茎的交汇处,既是番茄曲线的起点,也是我们末端执行器预期切割位置。CP位于梗的最大曲率处,也是传统夹持式末端执行器的切割点。理想情况下,在我们的机器人中,切割应发生在梗的SP位置附近。FP是第一个果实柄与梗连接的位置,而EP在梗的末端,结合其他梗和果实关键点,表示番茄果穗的姿势。这个区域应避免接触或切割。
即使对同一番茄果穗进行梗关键点标注,不同的标注者可能会产生不完全一致的结果,可能导致不同程度的差异。例如,QP、MP和TQP的位置沿从FP到EP的梗区域均匀分布。与SP和CP相比,它们的结构特征不太明显。类似于COCO人体关键点数据集[20],我们使用OKS(目标关键点相似性)值作为评价梗关键点预测准确性的指标。梗关键点的'sigmas'参数是通过计算多个人类标注者关键点与专家地面真实标注之间的标准差获得的。
不同之处在于,COCO人体关键点数据集中的所有关键点并不都同等重要。对于采摘任务,每个关键点的重要性和预测误差的后果是不同的。SP、CP和FP梗关键点需要尽可能高的预测和定位精度。如果它们预测的位置与梗不完美对齐,采摘可能会失败,甚至可能损坏番茄藤。其他点主要用于避免末端执行器与番茄果穗之间的碰撞,不需要超高的精度。OKS计算了目标上多个关键点的地面真实值与预测值之间的总体相似性。一个潜在的问题是,一个准确度评价得分很高的模型可能在预测从FP到EP的关键点时表现很好,但可能在预测SP和CP时缺乏精度。这与我们的采摘目标相矛盾。
我们手动调整了每个关键点获得的'sigmas'值,以获得基于OKS评估的关键点检测模型,以更好地符合采摘需求。手动调整包括减小SP和CP点的'sigmas'值,同时增加其余点的'sigmas'值。这个调整表明我们希望模型评估更倾向于更高准确性的SP和CP关键点预测。
对于检测番茄花梗上的关键点,我们采用了HRnet-w48模型。此外,我们还尝试了在COCO关键点检测数据集上的几种最先进的网络,包括RTMPose、CID、UDP和DarkPose,其中CID、DarkPose和UDP都使用HRnet作为它们的骨干网络。此外,我们还探索了基于回归的关键点检测方法,如YOLOv8-pose,以及使用Resnet101作为回归预测骨干网络的模型。
3.4 决策与运动规划
在温室中,有限的操作空间和纠缠的藤蔓给自动化采摘任务带来了挑战。我们认为,采摘机器人的操作必须建立在“不对周围环境造成伤害”的原则之上。因此,我们设计和优化了决策过程,将“尽可能降低风险”作为核心宗旨。
通过将在表型测试阶段获得的番茄果穗的局部信息与在姿态估计阶段获取的整体姿态信息进行整合,我们对每个番茄果穗对象进行特征编码。利用这些特征数据,我们进一步优化了采摘目标的选择。不成熟或质量低劣的目标被排除在外。具有极端生长位置或方向的番茄果穗也被丢弃。例如,当采摘面向培养槽内部或与藤蔓悬挂方向相反的番茄果穗时,可能会发生机械臂与加热管碰撞或与藤蔓纠缠等情况。排除这样的目标将有效降低事故风险,并有助于提高整个采摘过程的连续性和成功率。
在选择目标后,机器人根据目标的体积和姿态关键点进行末端执行器路径规划,参见图3。最初,EP、TQP、MP、QP和FP点作为末端执行器的运动路径点,生成平滑的末端执行器轨迹。为了增加采摘成功率,执行碰撞检测,以确保末端执行器的内壁和上边缘不会与番茄果穗碰撞。利用对番茄果穗生长的先前知识,观察到果实主要朝着花梗曲线的法线方向生长。如果存在碰撞风险,末端执行器路径点沿着花梗曲线的法线方向向外移动。随后,末端执行器沿着计划的轨迹包围包含果实的番茄果穗主体,刀片所在的边缘达到SP点。末端执行器旋转,施加压力并切割花梗,从而完成采摘过程。

04 实验
4.1 数据集与训练
由于缺乏公开的樱桃番茄数据集,我们在北京市海淀区的一个商业温室中收集了图像数据。在专家的手动注释后,生成了两个数据集:数据集1,用于番茄目标检测和成熟度区分,包含2000张带有112,000个目标的注释图像;数据集2,用于果梗关键点检测,包含1000张带有5432个注释对象的图像。
为了进行表型多任务建模,我们使用了Yolov5m模型,并在数据集1上对其进行了训练,验证集使用了300张图像。多种用于果梗关键点预测的模型在数据集2上进行了训练,验证集使用了150张图像。
4.2 表型学测试
我们训练的多任务YOLOv5m在验证集上对番茄束和四种成熟度果实的mAP达到了90.18%,IOU阈值设为0.5。我们对整体成熟度和其他表型应用的评估基于此模型和自适应DBscan方法。随后,通过增强的自适应聚类算法,系统地将果实与相应的托架匹配,从而推断出番茄束的整体成熟度。作为一个基准,传统方法使用监督的二元分类模型直接评估托架的成熟度。在一个包含300个图像样本的验证数据集中,两种方法都被严格测试,结果如表1所示。

实验结果表明,我们的方法在估计整个番茄束的成熟度方面具有显著的准确性优势。此外,这种方法与农业标准一致,保持了良好的可解释性和可调整性。例如,如果成熟度标准发生变化,认为一个番茄束只有当每个单独的果实达到或超过某个成熟度阈值时才是成熟的,那么传统的分类方法将需要在整个数据集中进行耗尽的重新评估和调整注释。
4.3 姿态估计测试
我们整理了一个包含150张图像的果梗关键点验证集,以评估各种模型在姿态估计精度方面的表现。测试结果如表2所示。

根据实验结果,当使用OKS指标,阈值为0.75时,我们的方法表现出色,达到了0.7561的精度。尽管我们的算法在推断速度上有所欠缺,但考虑到采摘机器人的操作效率主要受其机械组件的几秒动作周期的限制,这种不足似乎相对微不足道,与感知速度相比。
此外,我们观察到基于热图的关键点预测模型通常在检测果梗关键点方面优于直接回归关键点位置的模型。这可能与果梗在图像中所占的像素区域较小有关。例如,在一个包含番茄托架图像的720P帧中,果梗的像素宽度为8。在输入到HRnet的192x168输入层之前,这个果梗像素区域被放大。相反,使用全局计算的模型,如YOLO,具有640x640的输入层,会压缩果梗图像,从而损害精确预测。
4.4 自动化采摘实验
在一个温室中进行了两轮实验。首先,在受控场景下,我们评估了基于姿态估计的采摘路径规划(也称为“自下而上包裹”)和末端执行器在面对各种方向的番茄托架时的表现,以及AHPPEBot的连续采摘能力。
4.4.1 不同目标姿态下的采摘测试
在实验中,我们手动修剪以确保机器人的工作区中只存在一个番茄托架集群,以防止与藤蔓的干扰。收到开始命令后,机器人开始采摘。如果连续三次尝试失败,或者存在安全问题或对番茄造成损害,则该操作被视为不成功。在这种情况下,操作员介入,停止操作并移除目标番茄托架。成功采摘后,机器人移动到下一个采摘点。在初步测试中,由于种植基础设施和番茄植物悬挂方向的限制,朝左或向内(朝向培养槽生长)的集群在机器人的视角下很难采摘。因此,这些异常值被排除,仅关注适合采摘的集群,即朝右或朝向机器人的集群。采摘过程中关键步骤的成功率在表3中详细说明。
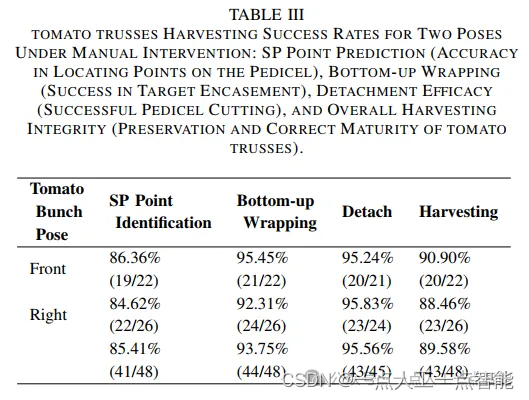

在实验结果中,自下而上包裹的成功率达到了93.75%,分离成功率为95.56%,总体采摘成功率为89.58%。值得注意的是,成功采摘不仅依赖于目标关键点的准确预测,末端执行器精确环绕番茄托架的能力也同样重要。
4.4.2 自主连续采摘测试
在此实验中,我们继续采用前述部分的目标选择策略,主要关注两种采摘姿态的目标。与之前不同,本次测试的环境没有经过人工修剪,机器人只尝试每个目标一次。机器人在一个充满潜在采摘目标的环境中自主操作,包括前进、目标识别、评估采摘可行性
05 结论
在本文中,我们设计了一个名为AHPPEBot的先进机器人,专门用于自动采摘番茄。
为了确保机器人采摘的自主性和精确性,我们整合了两个关键技术:基于对象检测的快速表型学方法和用于番茄托架的姿态估计技术。这些整合提高了机器人识别番茄托架、决策和规划采摘路径的能力。
温室设置中的实验结果表明,在有效的视觉引导和高性能末端执行器的帮助下,我们的机器人实现了最先进的采摘成功率,展示了其连续采摘的能力。结果为农业机器人提供了一个高效可靠的自动化解决方案。