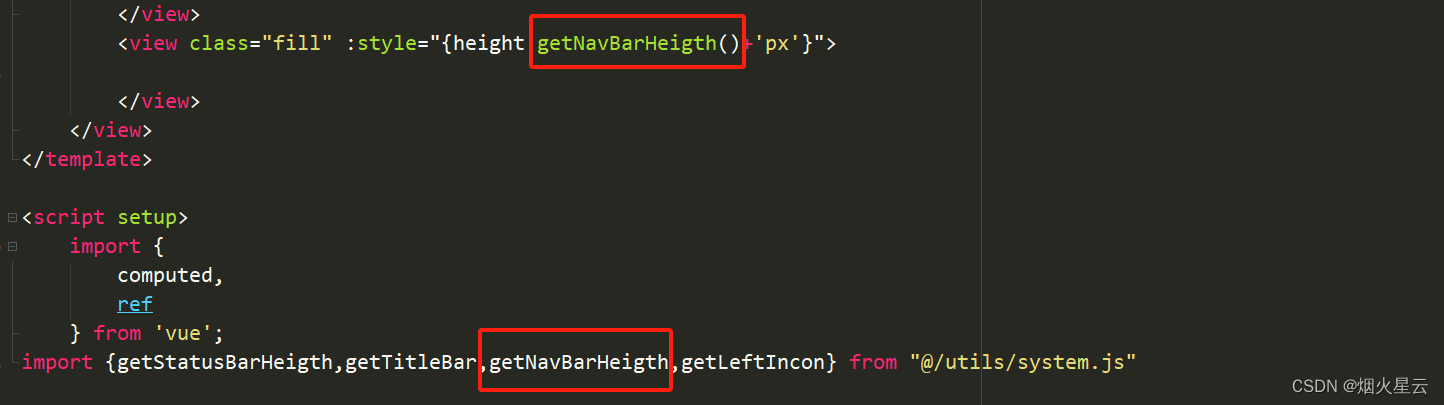
本文以 SQL 异常重试场景为例,使用基于 日志文件 和 gv$sql_aduit 视图 这两种方式,找出具体的报错原因。
作者:郑增权,爱可生 DBA 团队成员,OceanBase 和 MySQL 数据库技术爱好者。
爱可生开源社区出品,原创内容未经授权不得随意使用,转载请联系小编并注明来源。
本文约 2000 字,预计阅读需要 8 分钟。
简介
我们在 OCP 云平台 Top SQL 界面看到一些异常 SQL,但并未提示具体报错原因或提示了原因但不够详细。
本文以 SQL 异常重试场景为例,使用基于 日志文件 和 gv$sql_aduit 视图 这两种方式,找出具体的报错原因。
本文更推荐 PC 端浏览~
背景
- OceanBase 3.X 企业版 MySQL 模式
- 某客户在性能压测过程中反馈,在对某张表 UPDATE 时响应缓慢,一直无法执行成功。
gv$sql_aduit关于此 SQL 相关信息已被清理,且 Top SQL 未提示报错具体原因,只能基于日志文件进行排查。- OCP 云平台查看初始状态如下:
- UPDATE 语句重试 440 次
- 平均响应时间为 5491.15 ms
- 文中后半部分对此场景进行延伸。
- 假设 SQL 正处于异常重试状态中,且关联的
gv$sql_audit视图信息未被清除的情况下,如何展开排查提供思路。
- 假设 SQL 正处于异常重试状态中,且关联的
排查过程
1. 导出 Top SQL
列管理 按需勾选需查看的信息(如:SQL ID,重试次数)。
2. 复制 SQL 文本

3. 查找 UPDATE 语句
在对应的服务器上 grep 此 SQL 语句的打印次数:
- 结果为 1 小时内执行了 505 次,判断针对该行数据的 UPDATE 行为可能存在异常。
- 日志打印 SQL 次数可能与 Top SQL 不同,大致对应上即可。
- 一般异常 SQL 会在
observer.log中打印,正常执行完成的可能不会存在记录。
# grep -i "UPDATE evan.evan_zheng SET name = 'test0409' WHERE id = 1" observer.log.2024040916* | wc -l
5054. 查找错误位置
以 SQL 语句 和 ret= 作为条件进行检索,看是否存在相关错误码。
- 若 SQL 文本无法精准匹配,则只复制部分关键字。
- 可以看到 4012,6003 等超时相关错误码。
- 复制一条
trace id用于检索
# grep -i "UPDATE evan.evan_zheng SET name = 'test0409' WHERE id = 1" observer.log.2024040916* | grep "ret="
5. 查看报错信息
检索 trace_id,查看主要报错信息。
- 写写冲突:on_wlock_retry、lock_for_write conflict
- 错误码:6005
- 更新某行数据失败:failed to update row (xxx)

6. 写写冲突部分日志
# grep -i "YB420ABA40A1-000615A29EDEEA36-0-0" observer.log.2024040916* | grep "lock_for_write conflict"
7. 确认行为
确认此 trace_id 关联的 SQL 存在重试行为。
# grep -i "YB420ABA40A1-000615A29EDEEA36-0-0" observer.log.2024040916* | grep -i "will retry"
8. 错误码含义
错误码 6005:更新操作加锁失败


错误码 6003:等待锁超时


错误码 6212:SQL 语句超时


对于语句超时的情况,首先要确定当前租户下 ob_query_timeout 变量设置,然后根据 trace_id 搜索 observer.log 日志,找到当前语句的 cur_query_start_time。
如果 超时时间点 - cur_query_start_time = ob_query_timeout,说明是符合预期的。下面来验证一下。
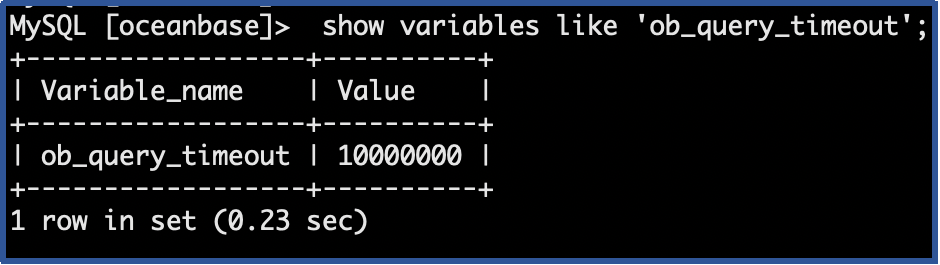
- 查询租户变量
ob_query_timeout为 10s。
- 在
observer.log中检索此trace_id的起始时间。
开始时间:
# grep -i "YB420ABA40A1-000615A29EDEEA36-0-0" observer.log.20240409* | grep -m 1 "cur_query_start_time"
超时时间:
# grep -i "YB420ABA40A1-000615A29EDEEA36-0-0" observer.log.20240409* | grep "timeout_timestamp" | tail -n 1

可以看到超时时间减去开始时间等于 10s,说明此处超时行为符合预期。
问题总结
当执行 SQL UPDATE evan.evan_zheng SET name = 'test0409' WHERE id = 1; 更新操作加锁失败,达到当前租户 ob_query_timeout 变量设置的值(10s)触发 6212 报错(语句超时)回滚语句。
可能造成此问题的原因:
- 业务使用了较大的超时时间,且存在一个会话中的未知长事务持有锁,阻塞了其他事务的执行。
- 开发人员并发更新同一行数据,并发处理逻辑存在错误。
优化措施
- 合理设置超时变量时间。
- 合理设置程序代码并发控制逻辑。
- 关注长事务告警。
延伸场景
如果 SQL 正在持续重试中,且 gv$sql_audit 视图信息未被清除,可参考如下步骤进行排查。
1. OCP 云平台,复制 SQL ID

2. 基于 SQL ID 查看主要的错误代码
可以看到 4012,6003 等超时相关错误码。
select
/*+ PARALLEL(8)*/
trace_id,
sid,
tenant_name,
svr_ip,
svr_port,
retry_cnt,
ret_code,
query_sql,
usec_to_time(request_time) as start_time
from
gv$sql_audit
where
sql_id = 'D884EA797E73F466819BAE2AE4AC1FE1'
and retry_cnt > 1
group by
ret_code
order by
retry_cnt desc;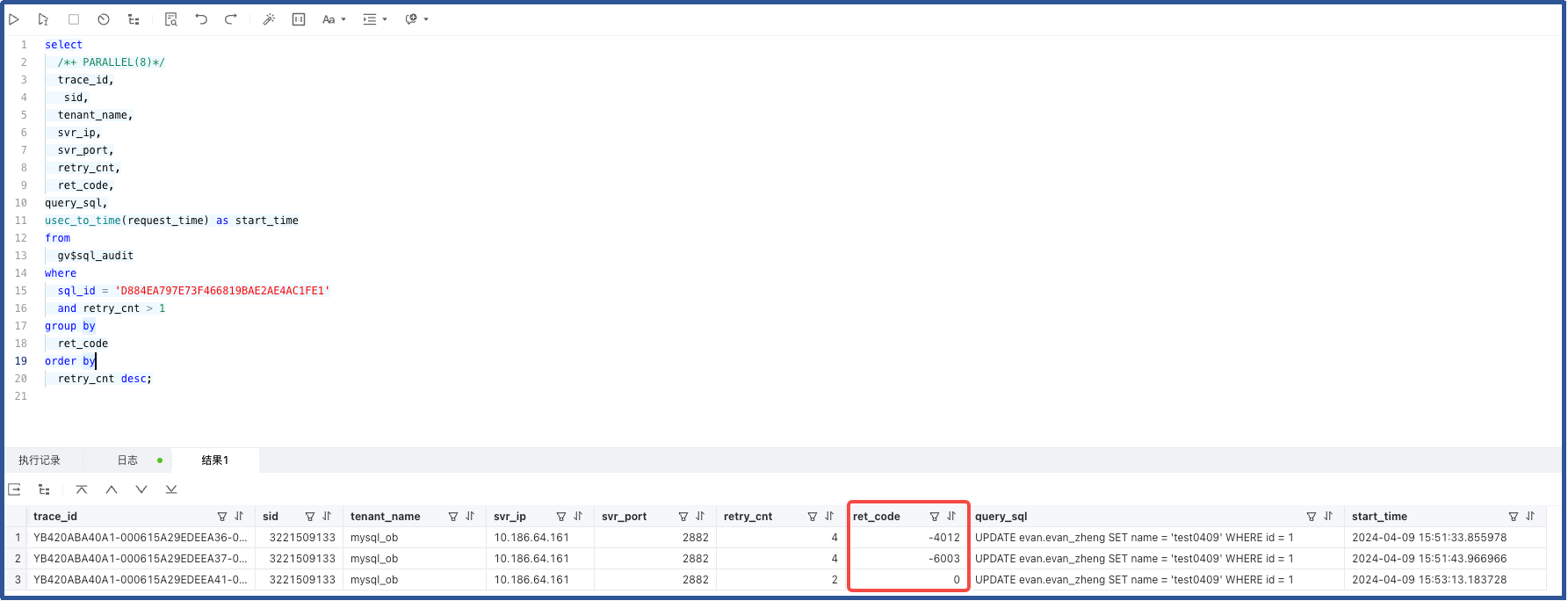
3. 查看 session_id
select
/*+ PARALLEL(8)*/
trace_id,
sid,
tenant_name,
svr_ip,
svr_port,
retry_cnt,
ret_code,
query_sql,
usec_to_time(request_time) as start_time
from
gv$sql_audit
where
sql_id = 'D884EA797E73F466819BAE2AE4AC1FE1'
group by
sid
order by
request_time desc;
4. 查询 table_id
select
database_name,
table_id,
table_name,
tenant_id,
tenant_name
from
oceanbase.gv$table
where
tenant_id = 1001
and database_name = 'evan'
and table_name = 'evan_zheng';
5. 查询锁持有者事务信息
使用 sys 租户执行。
select * from __all_virtual_trans_lock_stat where table_id = '1100611139453778'\G
6. 查询锁等待者事务信息
使用 sys 租户执行。
可以看到此处 session_id 与 gv$sql_audit 查询出来的是一致的(即,异常重试的 SQL 的会话)。
select * from __all_virtual_lock_wait_stat where table_id = '1100611139453778'\G
7. 查询锁持有者 session 的 SQL
select
trace_id,
usec_to_time(request_time),
query_sql
from
gv$sql_audit
where
TENANT_ID = 1001
AND USER_NAME = 'root'
AND SID = '3221616444'
order by
request_time desc;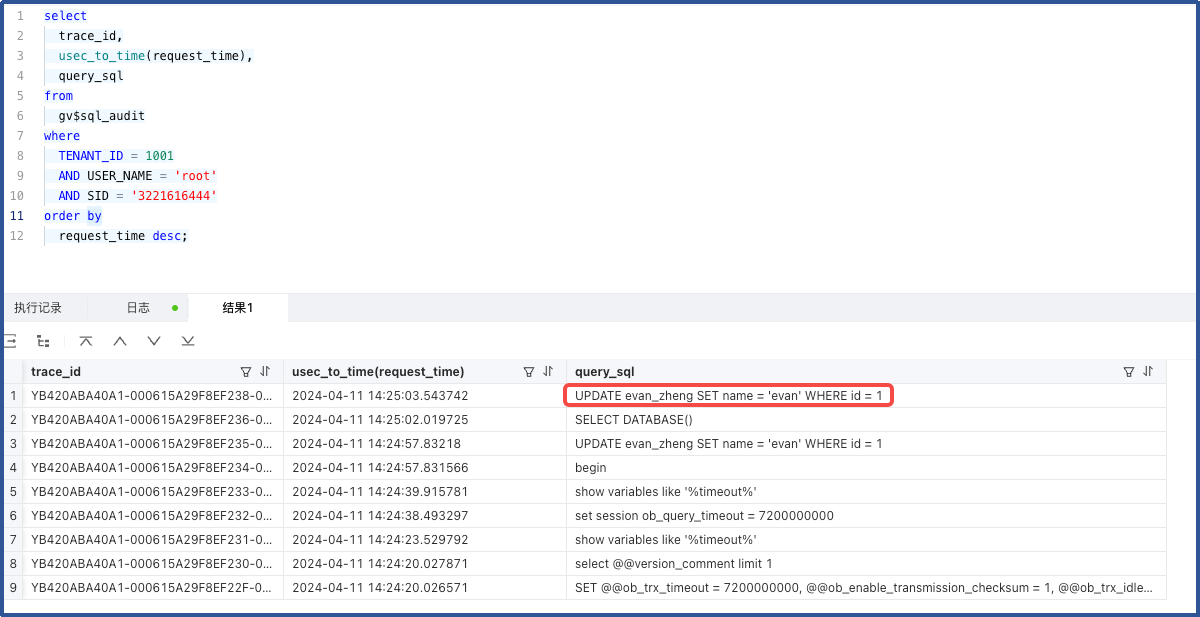
8. 查看锁等待者 session 的 SQL
select
trace_id,
usec_to_time(request_time),
query_sql
from
gv$sql_audit
where
TENANT_ID = 1001
AND USER_NAME = 'root'
AND SID = ' 3221618060'
order by
request_time desc;
可以看到锁持有者的会话和锁等待者的会话都针对表 evan_zheng 中 id=1 的字段进行更新,由于锁持有者开启了手动提交且未进行提交导致锁等待者持续重试 UPDATE 操作。
9. KILL 锁持有者会话
解决方法:经确认风险后,kill 锁持有者会话。

进一步分析可参考前方步骤,结合 observer.log 等信息进行分析。
其他错误码
通过如下几个错误码可以判断 SQL 超时原因(语句超时/事务超时/事务空闲超时):
- 系统变量
ob_query_timeout: 该变量控制着语句执行时间的上限,语句执行时间超过此值会给应用返回语句超时的错误,错误码为 6212,并回滚语句,通常该值默认为 10s。 - 系统变量
ob_trx_timeout: 该变量控制着事务超时时间,事务执行时间超过此值会给应用返回事务超时的错误,错误码为 6210,此时需要应用发起 ROLLBACK 语句回滚该事务。 - 系统变量
ob_trx_idle_timeout: 该变量表示 session上一个事务处于的 IDLE 状态的最长时间,即长时间没有 DML 语句或结束该事务。超过该时间值后,事务会自动回滚。再执行 DML 语句会给应用返回错误码 6224,应用需要发起 ROLLBACK 语句清理 session 状态。
参考资料
- 《OceanBase 数据库日志解读示例》https://www.oceanbase.com/knowledge-base/oceanbase-database-1000000000207691
- 《OceanBase 数据库事务问题排查指南》https://www.oceanbase.com/knowledge-base/oceanbase-database-20000000026
- 《OceanBase 数据库中的行锁问题排查指南》https://www.oceanbase.com/knowledge-base/oceanbase-database-20000000016
- 《事务控制概述》https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000000642694
更多技术文章,请访问:https://opensource.actionsky.com/
关于 SQLE
SQLE 是一款全方位的 SQL 质量管理平台,覆盖开发至生产环境的 SQL 审核和管理。支持主流的开源、商业、国产数据库,为开发和运维提供流程自动化能力,提升上线效率,提高数据质量。
SQLE 获取
| 类型 | 地址 |
|---|---|
| 版本库 | https://github.com/actiontech/sqle |
| 文档 | https://actiontech.github.io/sqle-docs/ |
| 发布信息 | https://github.com/actiontech/sqle/releases |
| 数据审核插件开发文档 | https://actiontech.github.io/sqle-docs/docs/dev-manual/plugins/howtouse |


父子通信,传递元素内容](https://img-blog.csdnimg.cn/direct/23bf7a05a7bf4326a6d08994873350e5.png)