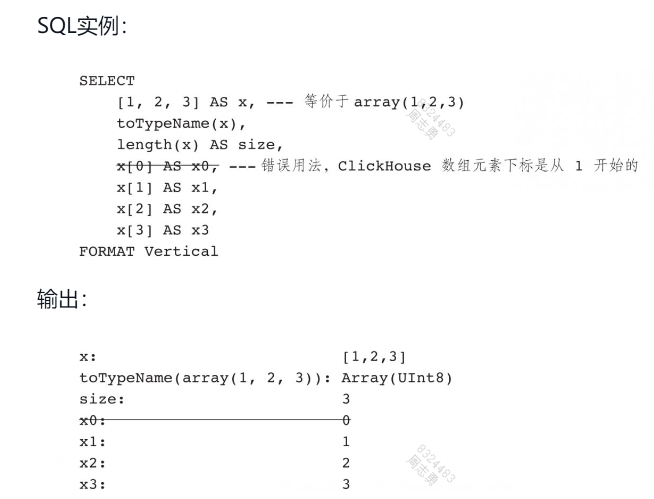
本文转载自:Prompt Engineering Guide
https://www.promptingguide.ai/zh/introduction/basics
文章目录
- 提示工程简介
- 1、基本概念
- 1)基础提示词
- 2)提示词格式
- 2、提示词要素
- 3、设计提示的通用技巧
- 从简单开始
- 指令
- 具体性
- 避免不精确
- 做还是不做?
- 4、提示词示例
- 文本概括
- 信息提取
- 问答
- 文本分类
- 对话
- 代码生成
- 推理
- Notebook
- 提示技术
- 1、零样本提示
- 2、少样本提示
- 少样本提示的限制
- 3、Chain-of-Thought Prompting
- 链式思考(CoT)提示
- 零样本 COT 提示
- 自动思维链(Auto-CoT)
- 4、自我一致性
- 5、生成知识提示
- 6、链式提示
- 简介
- 链式提示使用示例
- 文档问答中的链式提示
- 7、思维树 (ToT)
- 8、检索增强生成 (RAG)
- 9、自动推理并使用工具 (ART)
- 10、自动提示工程师(APE)
- 11、Active-Prompt
- 12、方向性刺激提示
- 13、PAL(程序辅助语言模型)
- 14、ReAct 框架
- 它是如何运作的?
- ReAct 提示
- 在知识密集型任务上的表现结果
- 在决策型任务上的表现结果
- 长链 ReAct 的使用
- 15、自我反思(Reflexion)
- 结果
- 何时自我反思?
- 参考文献
- 16、多模态思维链提示方法
- 17、GraphPrompts
提示工程简介
提示工程是一个较新的学科,应用于开发和优化提示词(Prompt),帮助用户有效地将语言模型用于各种应用场景和研究领域。
掌握了提示工程相关技能将有助于用户更好地了解大型语言模型的能力和局限性。
研究人员可利用提示工程来提高大语言模型处理复杂任务场景的能力,如问答和算术推理能力。
开发人员可通过提示工程设计和研发出强大的技术,实现和大语言模型或其他生态工具的高效接轨。
本指南介绍了提示词相关的基础知识,帮助用户了解如何通过提示词和大语言模型进行交互并提供指导建议。
除非另有说明,本指南默认所有示例都是在 OpenAI 的 Playground 上使用 gpt-3.5-turbo 进行测试。
模型使用默认配置,即 temperature=1 和 top_p=1 。
这些提示也应适用于具有类似功能的其他模型,如gpt-3.5-turbo,但模型响应可能会有所不同。
1、基本概念
1)基础提示词
您可以通过简单的提示词(Prompts)获得大量结果,但结果的质量与您提供的信息数量和完善度有关。一个提示词可以包含您传递到模型的_指令_或_问题_等信息,也可以包含其他详细信息,如_上下文_、_输入_或_示例_等。您可以通过这些元素来更好地指导模型,并因此获得更好的结果。
看下面一个简单的示例:
提示词
The sky is
输出结果
blue.
如果使用的是 OpenAI Playground 或者其他任何 LLM Playground,则可以提示模型,如以下屏幕截图所示:
需要注意的是,当使用 OpenAI 的 gpt-4 或者 gpt-3.5-turbo 等聊天模型时,您可以使用三个不同的角色来构建 prompt: system、user 和 assistant。
其中 system 不是必需的,但有助于设定 assistant 的整体行为,帮助模型了解用户的需求,并根据这些需求提供相应的响应。
上面的示例仅包含一条 user 消息,您可以使用 user 消息直接作为 prompt。
为简单起见,本指南所有示例(除非明确提及)将仅使用 user 消息来作为 gpt-3.5-turbo 模型的 prompt。
上面示例中 assistant 的消息是模型的响应。
您还可以定义 assistant 消息来传递模型所需行为的示例。
您可以在此处 了解有关使用聊天模型的更多信息。
从上面的提示示例中可以看出,语言模型能够基于我们给出的上下文内容 `“The sky is” 完成续写。
而输出的结果可能是出人意料的,或远高于我们的任务要求。 但是,我们可以通过改进提示词来获得更好的结果。
让我们试着改进以下:
提示词
完善以下句子:The sky is
输出结果
blue during the day and dark at night.
结果是不是要好一些了?本例中,我们告知模型去完善句子,因此输出的结果和我们最初的输入是完全符合的。
提示工程(Prompt Engineering)就是探讨如何设计出最佳提示词,用于指导语言模型帮助我们高效完成某项任务。
以上示例基本说明了现阶段的大语言模型能够发挥的功能作用。它们可以用于执行各种高级任务,如文本概括、数学推理、代码生成等。
2)提示词格式
前文中我们还是采取的比较简单的提示词。 标准提示词应该遵循以下格式:
<问题>?
或
<指令>
这种可以被格式化为标准的问答格式,如:
Q: <问题>?
A:
以上的提示方式,也被称为 零样本提示(zero-shot prompting),即用户不提供任务结果相关的示范,直接提示语言模型给出任务相关的回答。
某些大型语言模式有能力实现零样本提示,但这也取决于任务的复杂度和已有的知识范围。
具体的零样本提示示例如下:
提示词
Q: What is prompt engineering?
对于一些较新的模型,你可以跳过 Q: 部分,直接输入问题。
因为模型在训练过程中被暗示并理解问答任务,换言之,提示词可以简化为下面的形式:
提示词
What is prompt engineering?
基于以上标准范式,目前业界普遍使用的还是更高效的 小样本提示(Few-shot Prompting) 范式,即用户提供少量的提示范例,如任务说明等。小样本提示一般遵循以下格式:
<问题>?
<答案>
<问题>?
<答案>
<问题>?
<答案>
<问题>?
而问答模式即如下:
Q: <问题>?
A: <答案>
Q: <问题>?
A: <答案>
Q: <问题>?
A: <答案>
Q: <问题>?
A:
注意,使用问答模式并不是必须的。你可以根据任务需求调整提示范式。
比如,您可以按以下示例执行一个简单的分类任务,并对任务做简单说明:
提示词
This is awesome! // Positive
This is bad! // Negative
Wow that movie was rad! // Positive
What a horrible show! //
输出结果
Negative
语言模型可以基于一些说明了解和学习某些任务,而小样本提示正好可以赋能上下文学习能力。
我们将在接下来的章节中更广泛的讨论如何使用零样本提示和小样本提示。
2、提示词要素
如果您接触过大量提示工程相关的示例和应用,您会注意到提示词是由一些要素组成的。
提示词可以包含以下任意要素:
- 指令:想要模型执行的特定任务或指令。
- 上下文:包含外部信息或额外的上下文信息,引导语言模型更好地响应。
- 输入数据:用户输入的内容或问题。
- 输出指示:指定输出的类型或格式。
为了更好地演示提示词要素,下面是一个简单的提示,旨在完成文本分类任务:
提示词
请将文本分为中性、否定或肯定
文本:我觉得食物还可以。
情绪:
在上面的提示示例中,指令是“将文本分类为中性、否定或肯定”。
输入数据是“我认为食物还可以”部分,使用的输出指示是“情绪:”。
请注意,此基本示例不使用上下文,但也可以作为提示的一部分提供。
例如,此文本分类提示的上下文可以是作为提示的一部分提供的其他示例,以帮助模型更好地理解任务并引导预期的输出类型。
注意,提示词所需的格式取决于您想要语言模型完成的任务类型,并非所有以上要素都是必须的。我们会在后续的指南中提供更多更具体的示例。
3、设计提示的通用技巧
以下是设计提示时需要记住的一些技巧:
从简单开始
在设计提示时,需要记住这是一个迭代的过程,需要大量的实验来获得最佳结果。使用像 OpenAI 或 Cohere 这样的简单平台是一个很好的起点。
您可以从简单的提示开始,随着您的目标是获得更好的结果,不断添加更多的元素和上下文。
在此过程中对您的提示进行版本控制是至关重要的。
当您阅读本指南时,您会看到许多例子,其中具体性、简洁性和简明性通常会给您带来更好的结果。
当您有一个涉及许多不同子任务的大任务时,您可以尝试将任务分解为更简单的子任务,并随着获得更好的结果而不断构建。
这避免了在提示设计过程中一开始就添加过多的复杂性。
指令
您可以使用命令来指示模型执行各种简单任务,例如“写入”、“分类”、“总结”、“翻译”、“排序”等,从而为各种简单任务设计有效的提示。
请记住,您还需要进行大量的实验,以查看哪种方法最有效。尝试使用不同的关键字、上下文和数据尝试不同的指令,看看哪种方法最适合您的特定用例和任务。
通常情况下,上下文与您要执行的任务越具体和相关,效果越好。
我们将在即将推出的指南中介绍采样和添加更多上下文的重要性。
其他人建议将指令放在提示的开头。建议使用一些清晰的分隔符,如“###”,来分隔指令和上下文。
例如:
提示:
### 指令 ###将以下文本翻译成西班牙语:文本:“hello!”
输出:
¡Hola!
具体性
对您希望模型执行的指令和任务非常具体。提示越具体和详细,结果就越好。
当您有所期望的结果或生成样式时,这一点尤为重要。没有特定的令牌或关键字会导致更好的结果。
更重要的是具有良好的格式和描述性提示。实际上,在提示中提供示例非常有效,可以以特定格式获得所需的输出。
在设计提示时,您还应考虑提示的长度,因为提示的长度有限制。
考虑到您应该具体和详细的程度是需要考虑的。
包含太多不必要的细节并不一定是一个好方法。这些细节应该是相关的,并有助于完成手头的任务。
这是您需要进行大量实验的事情。我们鼓励大量实验和迭代,以优化您的应用程序的提示。
例如,让我们尝试从一段文本中提取特定信息的简单提示。
提示:
提取以下文本中的地名。
所需格式:
地点:<逗号分隔的公司名称列表>
输入:“虽然这些发展对研究人员来说是令人鼓舞的,但仍有许多谜团。里斯本未知的香帕利莫德中心的神经免疫学家 Henrique Veiga-Fernandes 说:“我们经常在大脑和我们在周围看到的效果之间有一个黑匣子。”“如果我们想在治疗背景下使用它,我们实际上需要了解机制。””
输出:
地点:里斯本,香帕利莫德中心
输入文本来自这篇 Nature 文章 。
避免不精确
在上面关于详细和格式改进的提示中,很容易陷入想要过于聪明的提示陷阱,从而可能创建不精确的描述。通常最好是具体和直接。这里的类比非常类似于有效的沟通——越直接,信息传递就越有效。
例如,您可能有兴趣了解提示工程的概念。您可以尝试这样做:
解释提示工程的概念。保持解释简短,只有几句话,不要过于描述。
从上面的提示中不清楚要使用多少句话和什么样的风格。您可能仍然可以通过上面的提示获得良好的响应,但更好的提示是非常具体、简洁和直接的。例如:
使用 2-3 句话向高中学生解释提示工程的概念。
做还是不做?
设计提示时的另一个常见技巧是避免说不要做什么,而是说要做什么。这鼓励更具体化,并关注导致模型产生良好响应的细节。
以下是一个电影推荐聊天机器人的示例,因为我写的指令——关注于不要做什么,而失败了。
提示:
以下是向客户推荐电影的代理程序。不要询问兴趣。不要询问个人信息。
客户:请根据我的兴趣推荐电影。
代理:
输出:
当然,我可以根据您的兴趣推荐电影。您想看什么类型的电影?您喜欢动作片、喜剧片、爱情片还是其他类型的电影?
以下是更好的提示:
提示:
以下是向客户推荐电影的代理程序。代理负责从全球热门电影中推荐电影。它应该避免询问用户的偏好并避免询问个人信息。如果代理没有电影推荐,它应该回答“抱歉,今天找不到电影推荐。”。
```顾客:请根据我的兴趣推荐一部电影。
客服:
输出:
抱歉,我没有关于您兴趣的任何信息。不过,这是目前全球热门的电影列表:[电影列表]。希望您能找到喜欢的电影!
上述示例中的一些内容摘自 “Best practices for prompt engineering with OpenAI API” article.
4、提示词示例
在上一节中,我们介绍并给出了如何赋能大语言模型的基本示例。
在本节中,我们会提供更多示例,介绍如何使用提示词来完成不同的任务,并介绍其中涉及的重要概念。通常,学习概念的最佳方法是通过示例进行学习。下面,我们将通过示例介绍说明如何使用精细的提示词来执行不同类型的任务。
文本概括
自然语言生成的标准任务之一是文本概括。文本概括可能涉及到不同的风格和领域。
事实上,语言模型最前景的应用场景之一就是能够快速概括出易于理解的文章大意和相关概念。 我们可以使用提示词尝试一个简单的概括任务。
假设我想了解抗生素的相关信息,我可以给出这样的提示:
提示词
Explain antibiotics
A:
输出结果
Antibiotics are a type of medication used to treat bacterial infections. They work by either killing the bacteria or preventing them from reproducing, allowing the body’s immune system to fight off the infection. Antibiotics are usually taken orally in the form of pills, capsules, or liquid solutions, or sometimes administered intravenously. They are not effective against viral infections, and using them inappropriately can lead to antibiotic resistance.
在问答形式中,“A:” 是一种明确的提示格式。
在这个示例中,我用它去提示模型,我想要该概念的进一步解释。 在这个例子中,我们可能还不清楚使用它是否有用,我们会在之后的示例中探讨这一点。
现在假设我们感觉模型给了太多的信息,想要进一步提炼它。 我们可以指导模型帮我们用一句话总结相关内容:
提示词
Antibiotics are a type of medication used to treat bacterial infections. They work by either killing the bacteria or preventing them from reproducing, allowing the body’s immune system to fight off the infection. Antibiotics are usually taken orally in the form of pills, capsules, or liquid solutions, or sometimes administered intravenously. They are not effective against viral infections, and using them inappropriately can lead to antibiotic resistance.
Explain the above in one sentence: // 用一句话解释上面的信息:
输出结果
Antibiotics are medications used to treat bacterial infections by either killing the bacteria or stopping them from reproducing, but they are not effective against viruses and overuse can lead to antibiotic resistance.
本示例是模型在没有过多关注上文输出内容的准确性的情况下,尝试用一个句子来总结段落内容。
关于上文准确性,我们可以通过指令或说明进一步改善它,这一点我们会在后续指南中进行探讨。 读到这里,您可以暂时停住并进行实验,看看是否能获得更好的结果。
信息提取
语言模型通过训练不仅可以用于执行自然语言生成相关任务,还可以用于执行文本分类和其他一系列自然语言处理 (NLP) 任务。
使用以下示例提示词从指定段落中提取信息:
提示词
Author-contribution statements and acknowledgements in research papers should state clearly and specifically whether, and to what extent, the authors used AI technologies such as ChatGPT in the preparation of their manuscript and analysis. They should also indicate which LLMs were used. This will alert editors and reviewers to scrutinize manuscripts more carefully for potential biases, inaccuracies and improper source crediting. Likewise, scientific journals should be transparent about their use of LLMs, for example when selecting submitted manuscripts.Mention the large language model based product mentioned in the paragraph above: // 指出上文中提到的大语言模型:
输出结果
The large language model based product mentioned in the paragraph above is ChatGPT.
我们可以通过许多方式改进以上结果,但当前方式已经非常有用。
现在应该很明显,您可以通过简单地指示语言模型去执行不同的任务。 AI 研发人员也利用这种能力来构建强大的产品和体验。
Paragraph source: ChatGPT: five priorities for research
问答
提高模型响应精确度的最佳方法之一是改进提示词的格式。
如前所述,提示词可以通过指令、上下文、输入和输出指示以改进响应结果。
虽然这些要素不是必需的,但如果您的指示越明确,响应的结果就会越好。 以下示例可以说明结构化提示词的重要性。
提示词
Answer the question based on the context below. Keep the answer short and concise. Respond "Unsure about answer" if not sure about the answer. // 基于以下语境回答问题。如果不知道答案的话,请回答“不确定答案”。Context: Teplizumab traces its roots to a New Jersey drug company called Ortho Pharmaceutical. There, scientists generated an early version of the antibody, dubbed OKT3. Originally sourced from mice, the molecule was able to bind to the surface of T cells and limit their cell-killing potential. In 1986, it was approved to help prevent organ rejection after kidney transplants, making it the first therapeutic antibody allowed for human use.Question: What was OKT3 originally sourced from?Answer:
输出结果
Mice.
语境参考至 Nature 。
文本分类
目前,我们已经会使用简单的指令来执行任务。 作为提示工程师,您需要提供更好的指令。 此外, 您也会发现,对于更负责的使用场景,仅提供指令是远远不够的。 所以,您需要思考如何在提示词中包含相关语境和其他不同要素。 同样,你还可以提供其他的信息,如输入数据和示例。
可以通过以下示例体验文本分类:
提示词
Classify the text into neutral, negative or positive. // 将文本按中立、负面或正面进行分类
Text: I think the food was okay.
Sentiment:
输出结果
Neutral
我们给出了对文本进行分类的指令,语言模型做出了正确响应,判断文本类型为 'Neutral'。
如果我们想要语言模型以指定格式做出响应, 比如,我们想要它返回 neutral 而不是 Neutral, 那我们要如何做呢? 我们有多种方法可以实现这一点。
此例中,我们主要是关注绝对特性,因此,我们提示词中包含的信息越多,响应结果就会越好。 我们可以使用以下示例来校正响应结果:
提示词
Classify the text into neutral, negative or positive. Text: I think the vacation is okay.Sentiment: neutral Text: I think the food was okay. Sentiment:
输出结果
neutral
完美! 这次模型返回了 neutral,这正是我们想要的特定标签。
提示词中的示例使得模型可以给出更具体的响应。 有时给出具体的指令十分重要,可以通过以下示例感受这一点:
提示词
Classify the text into nutral, negative or positive. Text: I think the vacation is okay.
Sentiment:
输出结果
Neutral
这时候你知道给出具体指令的重要性了吧?
对话
你可以通过提示工程进行更有趣的实验,比如指导大语言模型系统如何表现,指定它的行为意图和身份。 如果你正在构建客服聊天机器人之类的对话系统时,这项功能尤其有用。
比如,可以通过以下示例创建一个对话系统,该系统能够基于问题给出技术性和科学的回答。 你可以关注我们是如何通过指令明确地告诉模型应该如何表现。 这种应用场景有时也被称为 角色提示(Role Prompting)。
提示词
The following is a conversation with an AI research assistant. The assistant tone is technical and scientific. // 以下是与 AI 助理的对话,语气应该专业、技术性强。
Human: Hello, who are you?
AI: Greeting! I am an AI research assistant. How can I help you today?
Human: Can you tell me about the creation of blackholes?AI:
输出结果
Sure! Black holes are regions of spacetime where the gravitational force is so strong that nothing, not even light, can escape from it. They are created when a very massive star dies and its core collapses in on itself, forming a singularity of infinite density. The intense gravity of the singularity pulls in all the matter and radiation around it, creating the black hole.
我们的 AI 助理给出的回答非常技术对吧? 下面,我们让它给出更易于理解的答案。
提示词
The following is a conversation with an AI research assistant. The assistant answers should be easy to understand even by primary school students. // 以下是与 AI 助理的对话。请给出易于理解的答案,最好是小学生都能看懂的那种。
Human: Hello, who are you?
AI: Greeting! I am an AI research assistant. How can I help you today?
Human: Can you tell me about the creation of black holes?
AI:
输出结果
Sure! Black holes are created when a very massive star runs out of fuel and collapses in on itself. The gravity of the star is so strong that nothing, not even light, can escape its pull. This creates a point in space-time with an intense gravitational force called a black hole.
我想我们应该取得了一些进展, 你也可以继续改进它。 如果你再添加更多的示例,可能会得到更好的结果。
代码生成
大语言模型另外一个有效的应用场景是代码生成。 在此方面,Copilot 就是一个很好的示例。 你可以通过一些有效的提示词执行代码生成任务。 让我们来看一下下面的例子。
我们先用它写个简单的用户欢迎程序:
提示词
/*
询问用户的姓名并说“ Hello”
*/
输出结果
let name = prompt("What is your name?");
console.log(`Hello, ${name}!`);
你看,我们甚至都不需要指定要使用的编程语言。
来,我们再稍微升级一下。 下面的例子会向你展示提示词会让大语言模型变得多么强大。
提示词
"""
Table departments, columns = [DepartmentId, DepartmentName]Table students, columns = [DepartmentId, StudentId, StudentName]Create a MySQL query for all students in the Computer Science Department
"""
输出结果
SELECT StudentId, StudentName FROM students WHERE DepartmentId IN (SELECT DepartmentId FROM departments WHERE DepartmentName = 'Computer Science');
挺厉害的嘛。 本例中,我们提供了有关数据库架构并要求它生成有效的 MySQL 查询。
推理
目前对于大语言模型来说,推理任务算是最具有挑战性的了。
推理任务最让人兴奋的地方就是可以促使各种复杂的应用程序从大语言模型中诞生。
目前,涉及数学能力的推理任务已经有了一些改进。 对于当前的大型语言模型来说,执行推理任务可能会有一些难度,因此就需要更高级的提示词工程技术。 我们会在后面的指南中介绍这些高级技术。 现在,我们将介绍几个基本示例来展示算术功能。
提示词
What is 9,000 * 9,000?
输出结果
81,000,000
来,我们加大难度:
提示词
The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1.
A:
输出结果
No, the odd numbers in this group add up to an odd number: 119.
这不对! 我们试着用提示词去改进它:
提示词
The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1. Solve by breaking the problem into steps. First, identify the odd numbers, add them, and indicate whether the result is odd or even.
输出结果
Odd numbers: 15, 5, 13, 7, 1Sum: 41 41 is an odd number.
好多了吧? 顺便说一句,我试过几次,有时还是会失败。 如果你可以用示例给模型说明一下,可能会获得更准确的结果。
我们后面还会在本章节中介绍更多常见应用示例。
在后面的章节,我们将介绍更高级的提示工程概念和技术,以完成更困难任务。
Notebook
如果您想使用 Python 练习上述提示,我们准备了一个 Notebook 来测试使用 OpenAI 模型的一些提示。
提示工程入门 : https://github.com/dair-ai/Prompt-Engineering-Guide/blob/main/notebooks/pe-lecture.ipynb
提示技术
时至今日,改进提示词显然有助于在不同任务上获得更好的结果。这就是提示工程背后的整个理念。
尽管基础示例很有趣,但在本节中,我们将介绍更高级的提示工程技术,使我们能够完成更复杂和有趣的任务。
1、零样本提示
如今,经过大量数据训练并调整指令的LLM能够执行零样本任务。我们在前一节中尝试了一些零样本示例。以下是我们使用的一个示例:
提示:
将文本分类为中性、负面或正面。
文本:我认为这次假期还可以。
情感:
输出:
中性
请注意,在上面的提示中,我们没有向模型提供任何示例——这就是零样本能力的作用。
指令调整已被证明可以改善零样本学习Wei等人(2022) 。指令调整本质上是在通过指令描述的数据集上微调模型的概念。此外,RLHF (来自人类反馈的强化学习)已被采用以扩展指令调整,其中模型被调整以更好地适应人类偏好。这一最新发展推动了像ChatGPT这样的模型。我们将在接下来的章节中讨论所有这些方法和方法。
当零样本不起作用时,建议在提示中提供演示或示例,这就引出了少样本提示。在下一节中,我们将演示少样本提示。
2、少样本提示
虽然大型语言模型展示了惊人的零样本能力,但在使用零样本设置时,它们在更复杂的任务上仍然表现不佳。少样本提示可以作为一种技术,以启用上下文学习,我们在提示中提供演示以引导模型实现更好的性能。演示作为后续示例的条件,我们希望模型生成响应。
根据 Touvron et al. 2023 等人的在 2023 年的论文,当模型规模足够大时,小样本提示特性开始出现 (Kaplan et al., 2020) 。
让我们通过Brown等人2020年 提出的一个例子来演示少样本提示。在这个例子中,任务是在句子中正确使用一个新词。
提示:
“whatpu”是坦桑尼亚的一种小型毛茸茸的动物。一个使用whatpu这个词的句子的例子是:
我们在非洲旅行时看到了这些非常可爱的whatpus。
“farduddle”是指快速跳上跳下。一个使用farduddle这个词的句子的例子是:
输出:
当我们赢得比赛时,我们都开始庆祝跳跃。
我们可以观察到,模型通过提供一个示例(即1-shot)已经学会了如何执行任务。对于更困难的任务,我们可以尝试增加演示(例如3-shot、5-shot、10-shot等)。
根据Min等人(2022) 的研究结果,以下是在进行少样本学习时关于演示/范例的一些额外提示:
- “标签空间和演示指定的输入文本的分布都很重要(无论标签是否对单个输入正确)”
- 使用的格式也对性能起着关键作用,即使只是使用随机标签,这也比没有标签好得多。
- 其他结果表明,从真实标签分布(而不是均匀分布)中选择随机标签也有帮助。
让我们尝试一些例子。让我们首先尝试一个随机标签的例子(意味着将标签Negative和Positive随机分配给输入):
提示:
这太棒了!// Negative
这太糟糕了!// Positive
哇,那部电影太棒了!// Positive
多么可怕的节目!//
输出:
Negative
即使标签已经随机化,我们仍然得到了正确的答案。请注意,我们还保留了格式,这也有助于。实际上,通过进一步的实验,我们发现我们正在尝试的新GPT模型甚至对随机格式也变得更加稳健。例如:
提示:
Positive This is awesome!
This is bad! Negative
Wow that movie was rad!
Positive
What a horrible show! --
输出:
Negative
上面的格式不一致,但模型仍然预测了正确的标签。
我们必须进行更彻底的分析,以确认这是否适用于不同和更复杂的任务,包括提示的不同变体。
少样本提示的限制
标准的少样本提示对许多任务都有效,但仍然不是一种完美的技术,特别是在处理更复杂的推理任务时。让我们演示为什么会这样。
您是否还记得之前提供的任务:
这组数字中的奇数加起来是一个偶数:15、32、5、13、82、7、1。
A:
如果我们再试一次,模型输出如下:
是的,这组数字中的奇数加起来是107,是一个偶数。
这不是正确的答案,这不仅突显了这些系统的局限性,而且需要更高级的提示工程。
让我们尝试添加一些示例,看看少样本提示是否可以改善结果。
提示:
这组数字中的奇数加起来是一个偶数:4、8、9、15、12、2、1。
A:答案是False。
这组数字中的奇数加起来是一个偶数:17、10、19、4、8、12、24。
A:答案是True。
这组数字中的奇数加起来是一个偶数:16、11、14、4、8、13、24。
A:答案是True。
这组数字中的奇数加起来是一个偶数:17、9、10、12、13、4、2。
A:答案是False。
这组数字中的奇数加起来是一个偶数:15、32、5、13、82、7、1。
A:
输出:
答案是True。
这没用。似乎少样本提示 不足以获得这种类型的推理问题的可靠响应。上面的示例提供了任务的基本信息。
如果您仔细观察,我们引入的任务类型涉及几个更多的推理步骤。换句话说,如果我们将问题分解成步骤并向模型演示,这可能会有所帮助。最近,思维链(CoT)提示 已经流行起来,以解决更复杂的算术、常识和符号推理任务。
总的来说,提供示例对解决某些任务很有用。
当零样本提示和少样本提示不足时,这可能意味着模型学到的东西不足以在任务上表现良好。
从这里开始,建议开始考虑微调您的模型或尝试更高级的提示技术。
接下来,我们将讨论一种流行的提示技术,称为思维链提示,它已经获得了很多关注。
3、Chain-of-Thought Prompting
链式思考(CoT)提示
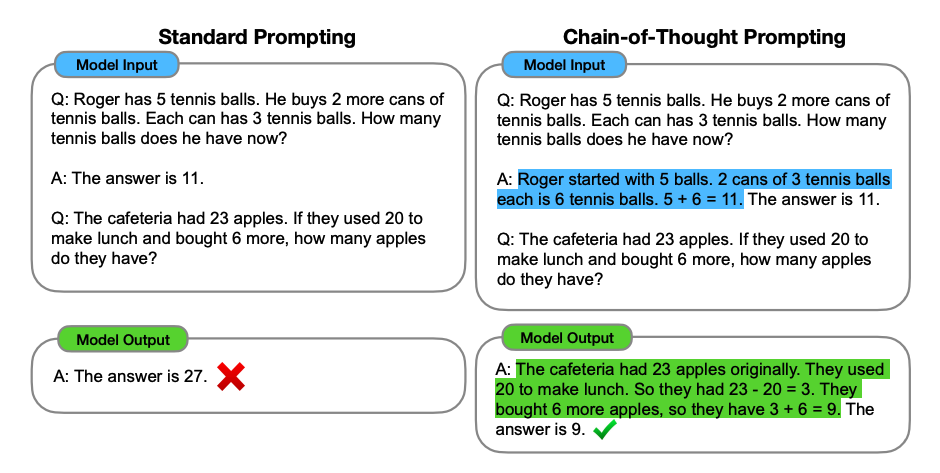
图片来源:Wei等人(2022)https://arxiv.org/abs/2201.11903
在 Wei等人(2022 中引入的链式思考(CoT)提示通过中间推理步骤实现了复杂的推理能力。
您可以将其与少样本提示相结合,以获得更好的结果,以便在回答之前进行推理的更复杂的任务。
提示:
这组数中的奇数加起来是偶数:4、8、9、15、12、2、1。
A:将所有奇数相加(9、15、1)得到25。答案为False。
这组数中的奇数加起来是偶数:17、10、19、4、8、12、24。
A:将所有奇数相加(17、19)得到36。答案为True。
这组数中的奇数加起来是偶数:16、11、14、4、8、13、24。
A:将所有奇数相加(11、13)得到24。答案为True。
这组数中的奇数加起来是偶数:17、9、10、12、13、4、2。
A:将所有奇数相加(17、9、13)得到39。答案为False。
这组数中的奇数加起来是偶数:15、32、5、13、82、7、1。
A:
输出:
将所有奇数相加(15、5、13、7、1)得到41。答案为False。
哇!我们可以看到在提供推理步骤时得到了完美的结果。实际上,我们可以通过提供更少的示例来解决此任务,即仅一个示例似乎就足够了:
提示:
这组数中的奇数加起来是偶数:4、8、9、15、12、2、1。
A:将所有奇数相加(9、15、1)得到25。答案为False。
这组数中的奇数加起来是偶数:15、32、5、13、82、7、1。
A:
输出:
将所有奇数相加(15、5、13、7、1)得到41。答案为False。
请记住,作者声称这是足够大的语言模型才会出现的新兴能力。
零样本 COT 提示

图片来源:Kojima等人(2022)
最近提出的一个新想法是 零样本CoT ( Kojima 等人,2022年),它基本上涉及将“让我们逐步思考”添加到原始提示中。让我们尝试一个简单的问题,看看模型的表现如何:
提示:
我去市场买了10个苹果。我给了邻居2个苹果和修理工2个苹果。然后我去买了5个苹果并吃了1个。我还剩下多少苹果?
输出:
11个苹果
答案是不正确的!现在让我们尝试使用特殊提示。
提示:
我去市场买了10个苹果。我给了邻居2个苹果和修理工2个苹果。然后我去买了5个苹果并吃了1个。我还剩下多少苹果?
让我们逐步思考。
输出:
首先,您从10个苹果开始。
您给了邻居和修理工各2个苹果,所以您还剩下6个苹果。
然后您买了5个苹果,所以现在您有11个苹果。
最后,您吃了1个苹果,所以您还剩下10个苹果。
令人印象深刻的是,这个简单的提示在这个任务中非常有效。这在您没有太多示例可用于提示时特别有用。
自动思维链(Auto-CoT)
当使用思维链提示时,这个过程需要手工制作有效且多样化的例子。这种手动工作可能会导致次优解决方案。
Zhang et al. (2022) 提出了一种消除人工的方法,即利用 LLMs “让我们一步一步地思考” 提示来生成一个接一个的推理链。这种自动过程仍然可能在生成的链中出现错误。
为了减轻错误的影响,演示的多样性很重要。这项工作提出了Auto-CoT,它对具有多样性的问题进行采样,并生成推理链来构建演示。
Auto-CoT 主要由两个阶段组成:
- 阶段1:问题聚类:将给定问题划分为几个聚类
- 阶段2:演示抽样:从每组数组中选择一个具有代表性的问题,并使用带有简单启发式的 Zero-Shot-CoT 生成其推理链
简单的启发式方法可以是问题的长度(例如,60 个 tokens)和理由的步骤数(例如,5 个推理步骤)。这鼓励模型使用简单而准确的演示。
该过程如下图所示:

图片来源:Zhang等人(2022)
Auto-CoT 的代码: https://github.com/amazon-science/auto-cot 。
4、自我一致性
也许在提示工程中更高级的技术之一是自我一致性。
由 Wang等人(2022) 提出,自我一致性旨在“替换链式思维提示中使用的天真贪婪解码方法”。
其想法是通过少样本 CoT 采样多个不同的推理路径,并使用生成结果选择最一致的答案。
这有助于提高 CoT 提示在涉及算术和常识推理的任务中的性能。
让我们尝试以下算术推理示例:
提示:
当我6岁时,我的妹妹是我的一半年龄。现在我70岁了,我的妹妹多大?
输出:
35
输出是错误的!我们如何通过自我一致性来改进这个问题?让我们试试。我们将使用 Wang 等人 2022 年的少量样本范例(表 17 ):
提示:
Q:林中有15棵树。林业工人今天将在林中种树。完成后,将有21棵树。林业工人今天种了多少棵树?
A:我们从15棵树开始。后来我们有21棵树。差异必须是他们种树的数量。因此,他们必须种了21-15 = 6棵树。答案是6。
Q:停车场有3辆汽车,又来了2辆汽车,停车场有多少辆汽车?
A:停车场已经有3辆汽车。又来了2辆。现在有3 + 2 = 5辆汽车。答案是5。
Q:Leah有32块巧克力,她的姐姐有42块。如果他们吃了35块,他们总共还剩多少块?
A:Leah有32块巧克力,Leah的姐姐有42块。这意味着最初有32 + 42 = 74块巧克力。已经吃了35块。因此,他们总共还剩74-35 = 39块巧克力。答案是39。
Q:Jason有20个棒棒糖。他给Denny一些棒棒糖。现在Jason只有12个棒棒糖。Jason给Denny多少棒棒糖?
A:Jason有20个棒棒糖。因为他现在只有12个,所以他必须把剩下的给Denny。他给Denny的棒棒糖数量必须是20-12 = 8个棒棒糖。答案是8。
Q:Shawn有五个玩具。圣诞节,他从他的父母那里得到了两个玩具。他现在有多少个玩具?
A:他有5个玩具。他从妈妈那里得到了2个,所以在那之后他有5 + 2 = 7个玩具。然后他从爸爸那里得到了2个,所以总共他有7 + 2 = 9个玩具。答案是9。
Q:服务器房间里有9台计算机。从周一到周四,每天都会安装5台计算机。现在服务器房间里有多少台计算机?
A:从周一到周四有4天。每天都添加了5台计算机。这意味着总共添加了4 * 5 =
20台计算机。一开始有9台计算机,所以现在有9 + 20 = 29台计算机。答案是29。
Q:Michael有58个高尔夫球。星期二,他丢失了23个高尔夫球。星期三,他又丢失了2个。星期三结束时他还剩多少个高尔夫球?
A:Michael最初有58个球。星期二他丢失了23个,所以在那之后他有58-23 = 35个球。星期三他又丢失了2个,所以现在他有35-2 = 33个球。答案是33。
Q:Olivia有23美元。她用每个3美元的价格买了五个百吉饼。她还剩多少钱?
A:她用每个3美元的价格买了5个百吉饼。这意味着她花了15美元。她还剩8美元。
Q:当我6岁时,我的妹妹是我的一半年龄。现在我70岁了,我的妹妹多大?
A:
输出 1:
当我6岁时,我的妹妹是我的一半年龄,也就是3岁。现在我70岁了,所以她是70-3 = 67岁。答案是67。
输出 2:
当叙述者6岁时,他的妹妹是他年龄的一半,也就是3岁。现在叙述者70岁了,他的妹妹应该是70-3 = 67岁。答案是67。
输出 3:
当我6岁时,我的妹妹是我的一半年龄,也就是3岁。现在我70岁了,所以她是70/2 = 35岁。答案是35。
计算最终答案涉及几个步骤(详见论文),但为了简单起见,我们可以看到已经出现了大多数答案,因此这基本上将成为最终答案。
5、生成知识提示
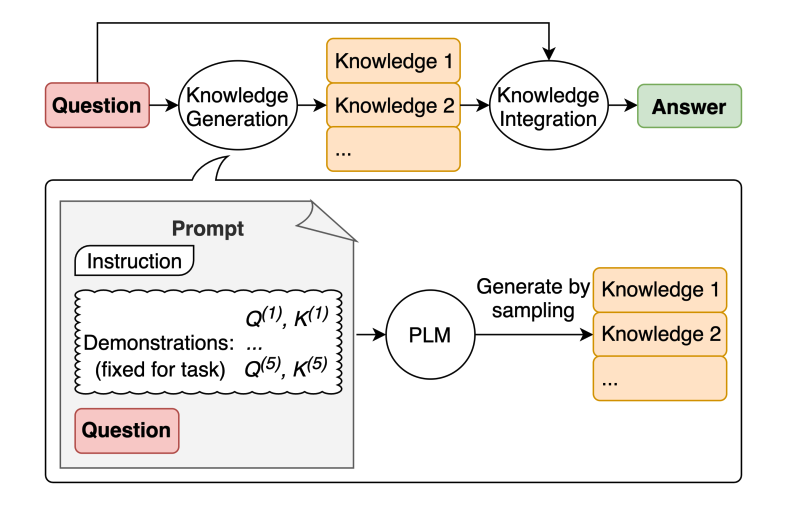
图片来源:Liu 等人 2022
LLM 继续得到改进,其中一种流行的技术是能够融合知识或信息,以帮助模型做出更准确的预测。
使用类似的思路,模型是否也可以在做出预测之前用于生成知识呢?这就是 Liu 等人 2022 的论文所尝试的——生成知识以作为提示的一部分。特别是,这对于常识推理等任务有多大帮助?
让我们尝试一个简单的提示:
提示:
高尔夫球的一部分是试图获得比其他人更高的得分。是或否?
输出:
是。
这种错误揭示了 LLM 在执行需要更多关于世界的知识的任务时的局限性。我们如何通过生成知识来改进呢?
首先,我们生成一些“知识”:
提示:
输入:希腊比墨西哥大。
知识:希腊的面积约为131,957平方公里,而墨西哥的面积约为1,964,375平方公里,使墨西哥比希腊大了1,389%。
输入:眼镜总是会起雾。
知识:当你的汗水、呼吸和周围的湿度中的水蒸气落在冷的表面上,冷却并变成微小的液滴时,会在眼镜镜片上产生冷凝。你看到的是一层薄膜。你的镜片相对于你的呼吸会比较凉,尤其是当外面的空气很冷时。
输入:鱼有思考能力。
知识:鱼比它们看起来更聪明。在许多领域,如记忆力,它们的认知能力与或超过非人类灵长类动物等“更高级”的脊椎动物。鱼的长期记忆帮助它们跟踪复杂的社交关系。
输入:一个人一生中吸烟很多香烟的常见影响是患肺癌的几率高于正常水平。
知识:那些一生中平均每天吸烟不到一支香烟的人,患肺癌的风险是从不吸烟者的9倍。在每天吸烟1到10支香烟之间的人群中,死于肺癌的风险几乎是从不吸烟者的12倍。
输入:一块石头和一颗卵石大小相同。
知识:卵石是一种根据Udden-Wentworth沉积学尺度的颗粒大小为4到64毫米的岩屑。卵石通常被认为比颗粒(直径2到4毫米)大,比卵石(直径64到256毫米)小。
输入:高尔夫球的一部分是试图获得比其他人更高的得分。
知识:
知识1:
高尔夫球的目标是以最少的杆数打完一组洞。一轮高尔夫球比赛通常包括18个洞。每个洞在标准高尔夫球场上一轮只打一次。每个杆计为一分,总杆数用于确定比赛的获胜者。
知识2:
高尔夫球是一项精密的球杆运动,竞争选手(或高尔夫球手)使用许多类型的球杆,用最少的杆数将球打入球场上一系列洞中。目标是以最低的分数完成比赛,该分数是通过将每个洞上所用的杆数相加计算出来的。得分最低的选手赢得比赛。
我们使用 Liu等人2022 的论文中提供的提示。
下一步是将知识整合并得出预测。我将问题重新格式化为 QA 格式,以指导答案格式。
提示:
问题:高尔夫球的一部分是试图获得比其他人更高的得分。是或否?
知识:高尔夫球的目标是以最少的杆数打完一组洞。一轮高尔夫球比赛通常包括18个洞。每个洞在标准高尔夫球场上一轮只打一次。每个杆计为一分,总杆数用于确定比赛的获胜者。解释和答案:
答案 1(置信度非常高):
不是,高尔夫球的目标不是获得比其他人更高的得分。相反,目标是以最少的杆数打完一组洞。总杆数用于确定比赛的获胜者,而不是总得分。
问题:高尔夫球的一部分是试图获得比其他人更高的得分。是或否?知识:高尔夫球是一项精密的球杆运动,竞争选手(或高尔夫球手)使用许多类型的球杆,用最少的杆数将球打入球场上一系列洞中。目标是以最低的分数完成比赛,该分数是通过将每个洞上所用的杆数相加计算出来的。得分最低的选手赢得比赛。解释和答案:
答案 2(置信度要低得多):
是的,高尔夫球的一部分是试图获得比其他人更高的得分。每个选手都试图以最少的杆数打完一组洞。总杆数用于确定比赛的获胜者,而不是总得分。得分最低的选手赢得比赛。
这个例子发生了一些非常有趣的事情。在第一个答案中,模型非常自信,但在第二个答案中不太自信。我简化了过程以进行演示,但在得出最终答案时还有一些细节需要考虑。请查看论文以了解更多。
6、链式提示
简介
为了提高大语言模型的性能使其更可靠,一个重要的提示工程技术是将任务分解为许多子任务。
确定子任务后,将子任务的提示词提供给语言模型,得到的结果作为新的提示词的一部分。
这就是所谓的链式提示(prompt chaining),一个任务被分解为多个子任务,根据子任务创建一系列提示操作。
链式提示可以完成很复杂的任务。LLM 可能无法仅用一个非常详细的提示完成这些任务。
在链式提示中,提示链对生成的回应执行转换或其他处理,直到达到期望结果。
除了提高性能,链式提示还有助于提高 LLM 应用的透明度,增加控制性和可靠性。这意味着您可以更容易地定位模型中的问题,分析并改进需要提高的不同阶段的性能。
链式提示在构建 LLM 驱动的对话助手和提高应用程序的个性化用户体验方面非常有用。
链式提示使用示例
文档问答中的链式提示
提示链可以用于不同的场景,这些场景可能涉及多个操作或转换。
例如,LLM 的一个常见用途是根据大型文本文档回答问题。
想要更好阅读大文本文档,可以设计两个不同的提示,第一个提示负责提取相关引文以回答问题,第二个提示则以引文和原始文档为输入来回答给定的问题。
换句话说,可以创建两个不同的提示来执行根据文档回答问题的任务。
下面的第一个提示根据问题从文档中提取相关引文。
请注意,为了简化,我们为文档添加了一个占位符{{文档}}。
要测试此提示,您可以从维基百科复制并粘贴一篇文章,例如这个关于提示工程 的页面。
由于此任务使用了较长的上下文,我们使用了 OpenAI 的 gpt-4-1106-preview 模型。您也可以将此提示与其他长上下文 LLM(如 Claude)一起使用。
提示 1:
你是一个很有帮助的助手。你的任务是根据文档回答问题。第一步是从文档中提取与问题相关的引文,由####分隔。请使用<quotes></quotes>输出引文列表。如果没有找到相关引文,请回应“未找到相关引文!”。
####
{{文档}}
####
这是整个提示的截图,包括通过 user 角色传递的问题。
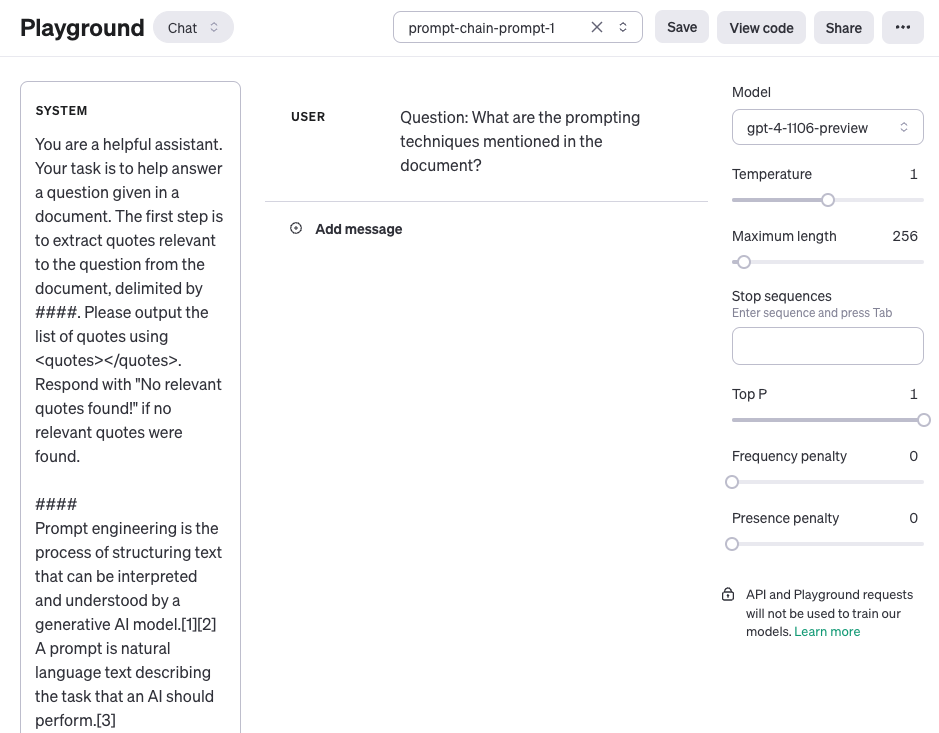
提示 1 的输出:
<quotes>
- Chain-of-thought (CoT) prompting[27]
- Generated knowledge prompting[37]
- Least-to-most prompting[38]
- Self-consistency decoding[39]
- Complexity-based prompting[41]
- Self-refine[42]
- Tree-of-thought prompting[43]
- Maieutic prompting[45]
- Directional-stimulus prompting[46]
- Textual inversion and embeddings[59]
- Using gradient descent to search for prompts[61][62][63][64]
- Prompt injection[65][66][67]
</quotes>
在第一个提示中返回的引文现在可以用作下面第二个提示的输入。
您可以对这些引文进行清理,比如移除引用标志。
可以在提示链中新建另一个提示来移除或使用这些引用标志,但现在您可以忽略这些。
然后,第二个提示接收由第一个提示提取的相关引文,并根据文档和这些提取的引文生成一个有帮助的回答。第二个提示可以是以下内容:
提示 2:
根据从文档中提取的相关引文(由<quotes></quotes>分隔)和原始文档(由####分隔),请构建对问题的回答。请确保答案准确、语气友好且有帮助。
####
{{文档}}
####
<quotes>
- Chain-of-thought (CoT) prompting[27]
- Generated knowledge prompting[37]
- Least-to-most prompting[38]
- Self-consistency decoding[39]
- Complexity-based prompting[41]
- Self-refine[42]
- Tree-of-thought prompting[43]
- Maieutic prompting[45]
- Directional-stimulus prompting[46]
- Textual inversion and embeddings[59]
- Using gradient descent to search for prompts[61][62][63][64]
- Prompt injection[65][66][67]
</quotes>
提示 2 的输出:
文档中提到的提示技术包括:
1. Chain-of-thought (CoT) prompting[27]
2. Generated knowledge prompting[37]
3. Least-to-most prompting[38]
4. Self-consistency decoding[39]
5. Complexity-based prompting[41]
6. Self-refine[42]
7. Tree-of-thought prompting[43]
8. Maieutic prompting[45]
9. Directional-stimulus prompting[46]
10. Textual inversion and embeddings[59]
11. Using gradient descent to search for prompts[61][62][63][64]
12. Prompt injection[65][66][67]
每一种技术都采用独特的策略来增强或明确与大型语言模型的互动,以产生期望的结果。
如您所见,简化并创建提示链是一种有用的提示方法,其中响应需要经过多个操作或转换。
作为练习,您可以自由设计一个提示,它会在将响应作为最终回应发送给应用程序用户之前,移除响应中的引用标志(例如,[27])。
您还可以在这份文档 中找到更多关于提示链的示例,这些示例利用了 Claude LLM。我们的示例灵感来源于他们,并采用了他们的示例。
7、思维树 (ToT)
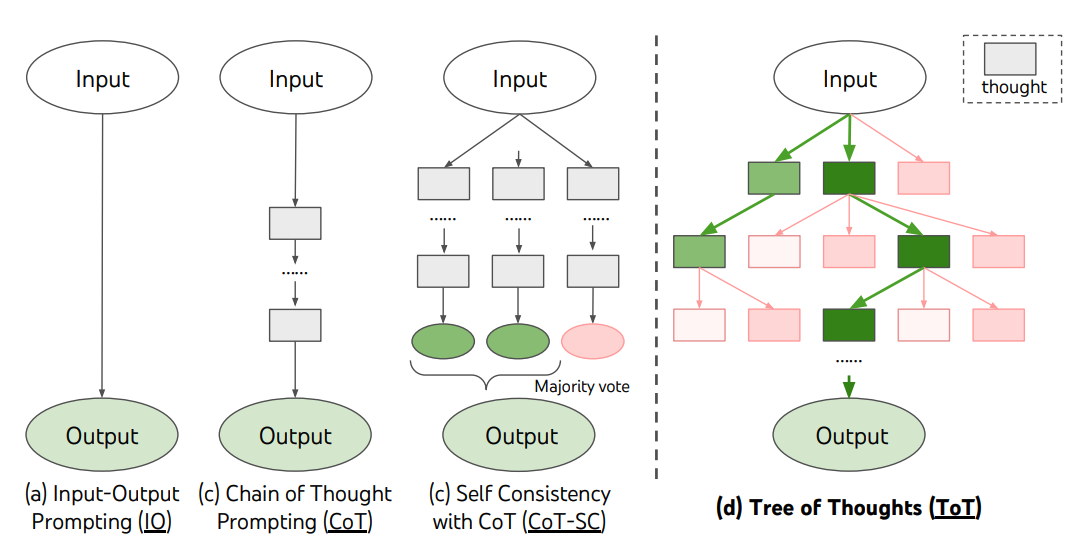
对于需要探索或预判战略的复杂任务来说,传统或简单的提示技巧是不够的。最近,Yao et el. (2023) 提出了思维树(Tree of Thoughts,ToT)框架,该框架基于思维链提示进行了总结,引导语言模型探索把思维作为中间步骤来解决通用问题。
ToT 维护着一棵思维树,思维由连贯的语言序列表示,这个序列就是解决问题的中间步骤。使用这种方法,LM 能够自己对严谨推理过程的中间思维进行评估。LM 将生成及评估思维的能力与搜索算法(如广度优先搜索和深度优先搜索)相结合,在系统性探索思维的时候可以向前验证和回溯。
ToT 框架原理如下:
图片援引自:Yao et el. (2023)
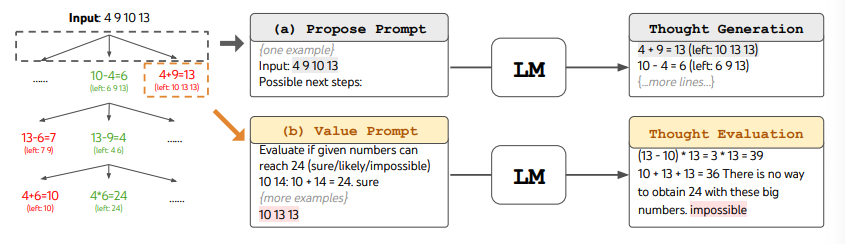
ToT 需要针对不同的任务定义思维/步骤的数量以及每步的候选项数量。例如,论文中的“算 24 游戏”是一种数学推理任务,需要分成 3 个思维步骤,每一步都需要一个中间方程。而每个步骤保留最优的(best) 5 个候选项。
ToT 完成算 24 的游戏任务要执行广度优先搜索(BFS),每步思维的候选项都要求 LM 给出能否得到 24 的评估:“sure/maybe/impossible”(一定能/可能/不可能) 。作者讲到:“目的是得到经过少量向前尝试就可以验证正确(sure)的局部解,基于‘太大/太小’的常识消除那些不可能(impossible)的局部解,其余的局部解作为‘maybe’保留。”每步思维都要抽样得到 3 个评估结果。整个过程如下图所示:
图片援引自:Yao et el. (2023)
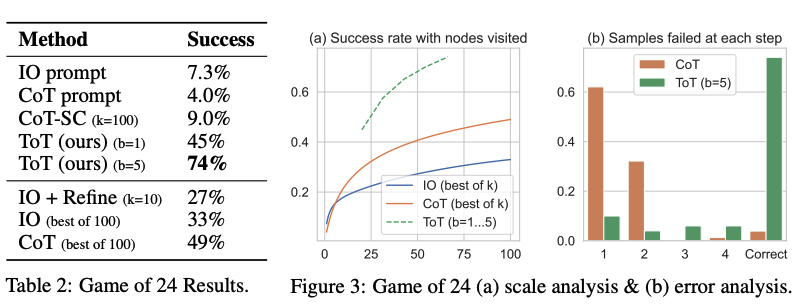
从下图中报告的结果来看,ToT 的表现大大超过了其他提示方法:
图片援引自:Yao et el. (2023)
代码例子:
https://github.com/princeton-nlp/tree-of-thought-llm
https://github.com/jieyilong/tree-of-thought-puzzle-solver
从大方向上来看,Yao et el. (2023) 和 Long (2023) 的核心思路是类似的。两种方法都是以多轮对话搜索树的形式来增强 LLM 解决复杂问题的能力。
主要区别在于 Yao et el. (2023) 采用了深度优先(DFS)/广度优先(BFS)/集束(beam)搜索,而 Long (2023) 则提出由强化学习(Reinforcement Learning)训练出的 “ToT 控制器”(ToT Controller)来驱动树的搜索策略(包括什么时候回退和搜索到哪一级回退等等)。深度优先/广度优先/集束搜索是通用搜索策略,并不针对具体问题。相比之下,由强化学习训练出的 ToT 控制器有可能从新的数据集学习,或是在自对弈(AlphaGo vs. 蛮力搜索)的过程中学习。因此,即使采用的是冻结的 LLM,基于强化学习构建的 ToT 系统仍然可以不断进化,学习新的知识。
Hulbert (2023) 提出了思维树(ToT)提示法,将 ToT 框架的主要概念概括成了一段简短的提示词,指导 LLM 在一次提示中对中间思维做出评估。ToT 提示词的例子如下:
假设三位不同的专家来回答这个问题。
所有专家都写下他们思考这个问题的第一个步骤,然后与大家分享。
然后,所有专家都写下他们思考的下一个步骤并分享。
以此类推,直到所有专家写完他们思考的所有步骤。
只要大家发现有专家的步骤出错了,就让这位专家离开。
请问...
8、检索增强生成 (RAG)
通用语言模型通过微调就可以完成几类常见任务,比如分析情绪和识别命名实体。这些任务不需要额外的背景知识就可以完成。
要完成更复杂和知识密集型的任务,可以基于语言模型构建一个系统,访问外部知识源来做到。这样的实现与事实更加一性,生成的答案更可靠,还有助于缓解“幻觉”问题。
Meta AI 的研究人员引入了一种叫做检索增强生成(Retrieval Augmented Generation,RAG) 的方法来完成这类知识密集型的任务。RAG 把一个信息检索组件和文本生成模型结合在一起。RAG 可以微调,其内部知识的修改方式很高效,不需要对整个模型进行重新训练。
RAG 会接受输入并检索出一组相关/支撑的文档,并给出文档的来源(例如维基百科)。这些文档作为上下文和输入的原始提示词组合,送给文本生成器得到最终的输出。这样 RAG 更加适应事实会随时间变化的情况。这非常有用,因为 LLM 的参数化知识是静态的。RAG 让语言模型不用重新训练就能够获取最新的信息,基于检索生成产生可靠的输出。
Lewis 等人(2021)提出一个通用的 RAG 微调方法。这种方法使用预训练的 seq2seq 作为参数记忆,用维基百科的密集向量索引作为非参数记忆(使通过神经网络预训练的检索器访问)。这种方法工作原理概况如下:
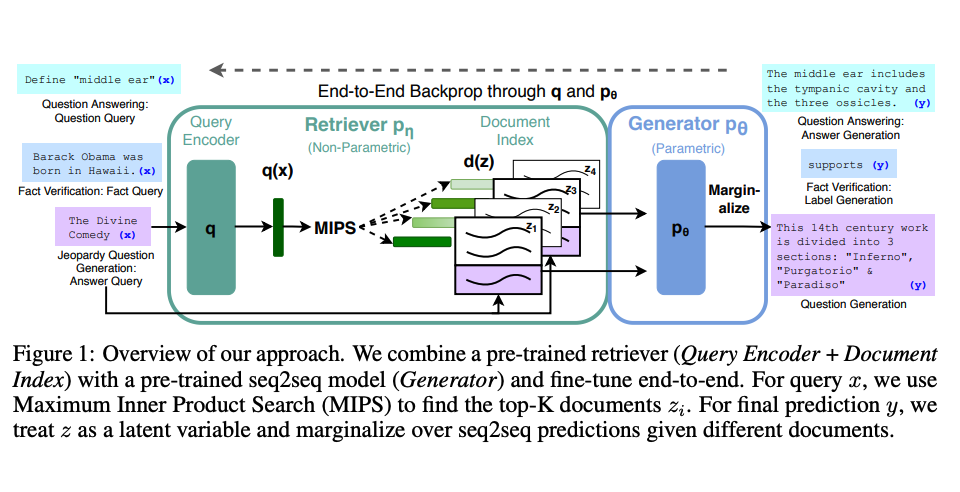
图片援引自: Lewis et el. (2021)
RAG 在 Natural Questions 、WebQuestions 和 CuratedTrec 等基准测试中表现抢眼。用 MS-MARCO 和 Jeopardy 问题进行测试时,RAG 生成的答案更符合事实、更具体、更多样。FEVER 事实验证使用 RAG 后也得到了更好的结果。
这说明 RAG 是一种可行的方案,能在知识密集型任务中增强语言模型的输出。
最近,基于检索器的方法越来越流行,经常与 ChatGPT 等流行 LLM 结合使用来提高其能力和事实一致性。
LangChain 文档中可以找到 一个使用检索器和 LLM 回答问题并给出知识来源的简单例子。
9、自动推理并使用工具 (ART)
使用 LLM 完成任务时,交替运用 CoT 提示和工具已经被证明是一种即强大又稳健的方法。这类方法通常需要针对特定任务手写示范,还需要精心编写交替使用生成模型和工具的脚本。Paranjape et al., (2023) 提出了一个新框架,该框架使用冻结的 LLM 来自动生成包含中间推理步骤的程序。
ART(Automatic Reasoning and Tool-use)的工作原理如下:
- 接到一个新任务的时候,从任务库中选择多步推理和使用工具的示范。
- 在测试中,调用外部工具时,先暂停生成,将工具输出整合后继续接着生成。
ART 引导模型总结示范,将新任务进行拆分并在恰当的地方使用工具。ART 采用的是零样本形式。ART 还可以手动扩展,只要简单地更新任务和工具库就可以修正推理步骤中的错误或是添加新的工具。这个过程如下:
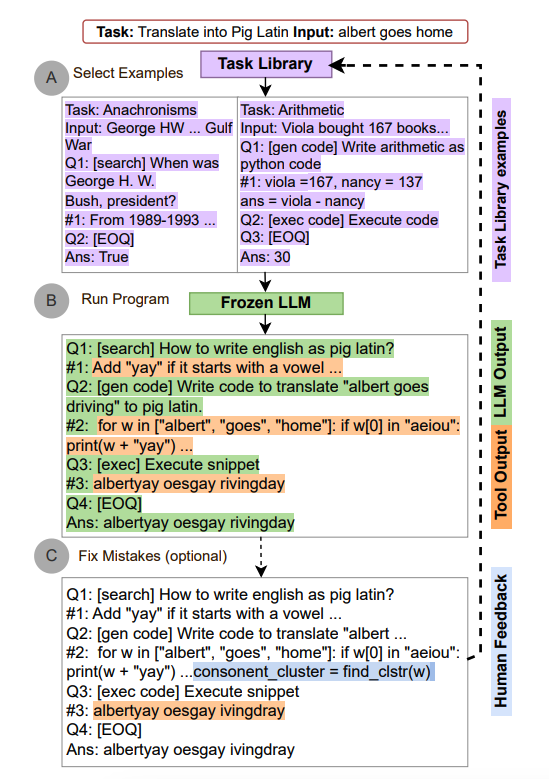
图片援引自: Paranjape et al., (2023)
在 BigBench 和 MMLU 基准测试中,ART 在未见任务上的表现大大超过了少样本提示和自动 CoT;配合人类反馈后,其表现超过了手写的 CoT 提示。
下面这张表格展示了 ART 在 BigBench 和 MMLU 任务上的表现:
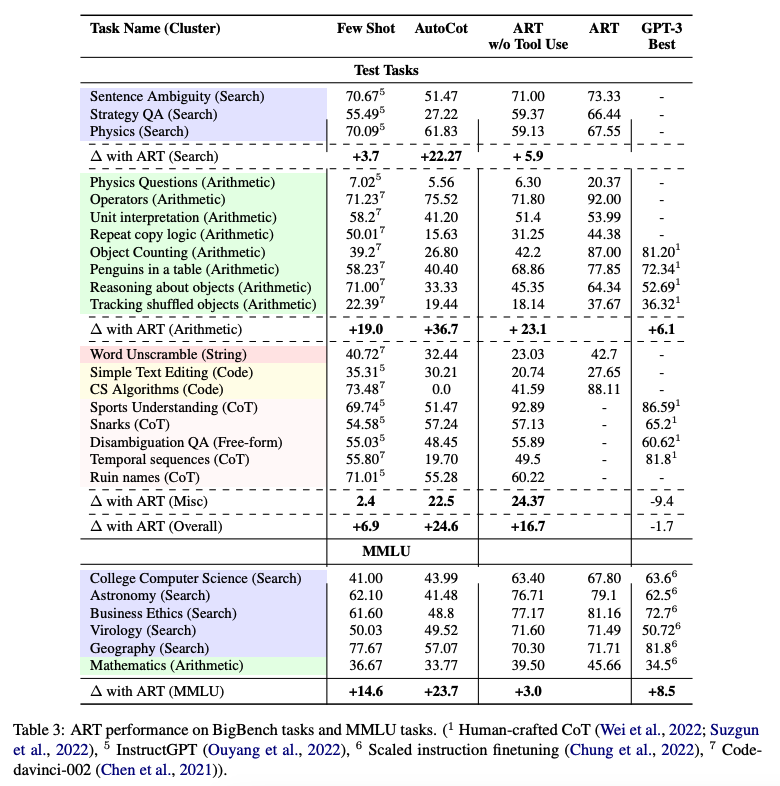
图片援引自: Paranjape et al., (2023)
10、自动提示工程师(APE)
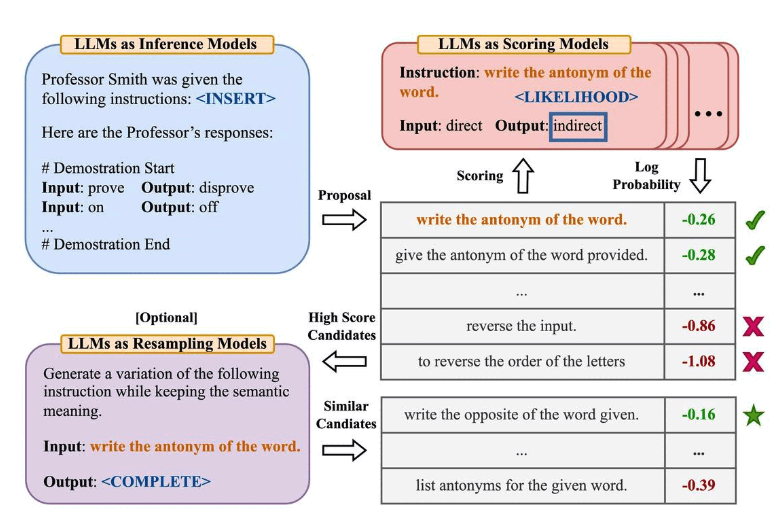
图片来源:Zhou等人,(2022)
Zhou等人,(2022) 提出了自动提示工程师 (APE),这是一个用于自动指令生成和选择的框架。指令生成问题被构建为自然语言合成问题,使用 LLMs 作为黑盒优化问题的解决方案来生成和搜索候选解。
第一步涉及一个大型语言模型(作为推理模型),该模型接收输出演示以生成任务的指令候选项。这些候选解将指导搜索过程。使用目标模型执行指令,然后根据计算的评估分数选择最合适的指令。
APE 发现了一个比人工设计的“让我们一步一步地思考”提示更好的零样本 CoT 提示 (Kojima 等人,2022 )。
提示“让我们一步一步地解决这个问题,以确保我们有正确的答案。”引发了思维链的推理,并提高了 MultiArith 和 GSM8K 基准测试的性能:
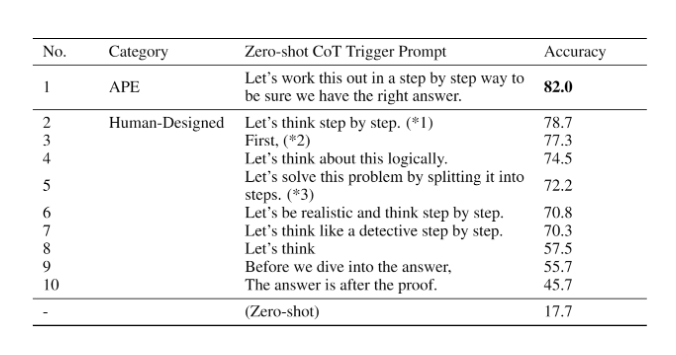
图片来源:Zhou等人,(2022)
本文涉及与提示工程相关的重要主题,即自动优化提示的想法。虽然我们在本指南中没有深入探讨这个主题,但如果您对此主题感兴趣,以下是一些关键论文:
- Prompt-OIRL - 使用离线逆强化学习来生成与查询相关的提示。
- OPRO - 引入使用 LLMs 优化提示的思想:让 LLMs “深呼吸”提高数学问题的表现。
- AutoPrompt - 提出了一种基于梯度引导搜索的方法,用于自动创建各种任务的提示。
- Prefix Tuning - 是一种轻量级的 fine-tuning 替代方案,为 NLG 任务添加可训练的连续前缀。
- Prompt Tuning - 提出了一种通过反向传播学习软提示的机制。
11、Active-Prompt
思维链(CoT)方法依赖于一组固定的人工注释范例。问题在于,这些范例可能不是不同任务的最有效示例。为了解决这个问题,Diao 等人(2023) 最近提出了一种新的提示方法,称为 Active-Prompt,以适应 LLMs 到不同的任务特定示例提示(用人类设计的 CoT 推理进行注释)。
下面是该方法的说明。第一步是使用或不使用少量 CoT 示例查询 LLM。对一组训练问题生成 k 个可能的答案。基于 k 个答案计算不确定度度量(使用不一致性)。选择最不确定的问题由人类进行注释。然后使用新的注释范例来推断每个问题。
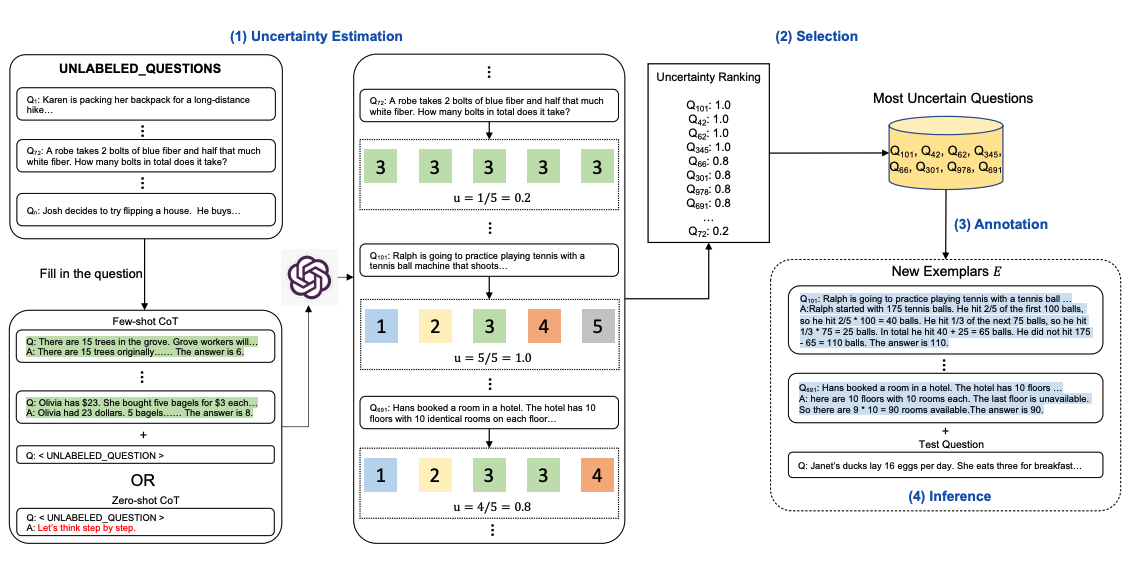
图片来源:Diao等人(2023)
12、方向性刺激提示
Li 等人,(2023) 提出了一种新的提示技术,以更好地指导 LLM 生成所需的摘要。
训练了一个可调节的策略 LM 来生成刺激/提示。越来越多地使用RL来优化 LLM。
下图显示了方向性刺激提示与标准提示的比较。策略 LM 可以很小,并且可以优化以生成指导黑盒冻结 LLM 的提示。

图片来源:Li 等人,(2023)
完整示例即将推出!
13、PAL(程序辅助语言模型)
Gao 等人(2022) 提出了一种使用 LLMs 读取自然语言问题并生成程序作为中间推理步骤的方法。被称为程序辅助语言模型(PAL),它与思维链提示不同,因为它不是使用自由形式文本来获得解决方案,而是将解决步骤卸载到类似 Python 解释器的编程运行时中。

图片来源:Gao 等人(2022)
让我们以 LangChain 和 OpenAI GPT-3 为例。我们有兴趣开发一个简单的应用程序,它能够解释所提出的问题,并利用 Python 解释器提供答案。
具体来说,我们有兴趣创建一个功能,允许使用 LLM 回答需要日期理解的问题。我们将为 LLM 提供一个提示,其中包括一些示例,这些示例是从这里 采用的。
这是我们需要导入的包:
import openaifrom datetime import datetimefrom dateutil.relativedelta import relativedeltaimport osfrom langchain.llms import OpenAIfrom dotenv import load_dotenv
让我们先配置一些环境:
load_dotenv() # API configurationopenai.api_key = os.getenv("OPENAI_API_KEY") # for LangChainos.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")
设置模型实例:
llm = OpenAI(model_name='text-davinci-003', temperature=0)
设置提示+问题:
question = "Today is 27 February 2023. I was born exactly 25 years ago. What is the date I was born in MM/DD/YYYY?" DATE_UNDERSTANDING_PROMPT = """# Q: 2015 is coming in 36 hours. What is the date one week from today in MM/DD/YYYY?# If 2015 is coming in 36 hours, then today is 36 hours before.today = datetime(2015, 1, 1) - relativedelta(hours=36)# One week from today,one_week_from_today = today + relativedelta(weeks=1)# The answer formatted with %m/%d/%Y isone_week_from_today.strftime('%m/%d/%Y')# Q: The first day of 2019 is a Tuesday, and today is the first Monday of 2019. What is the date today in MM/DD/YYYY?# If the first day of 2019 is a Tuesday, and today is the first Monday of 2019, then today is 6 days later.today = datetime(2019, 1, 1) + relativedelta(days=6)# The answer formatted with %m/%d/%Y istoday.strftime('%m/%d/%Y')# Q: The concert was scheduled to be on 06/01/1943, but was delayed by one day to today. What is the date 10 days ago in MM/DD/YYYY?# If the concert was scheduled to be on 06/01/1943, but was delayed by one day to today, then today is one day later.today = datetime(1943, 6, 1) + relativedelta(days=1)# 10 days ago,ten_days_ago = today - relativedelta(days=10)# The answer formatted with %m/%d/%Y isten_days_ago.strftime('%m/%d/%Y')# Q: It is 4/19/1969 today. What is the date 24 hours later in MM/DD/YYYY?# It is 4/19/1969 today.today = datetime(1969, 4, 19)# 24 hours later,later = today + relativedelta(hours=24)# The answer formatted with %m/%d/%Y istoday.strftime('%m/%d/%Y')# Q: Jane thought today is 3/11/2002, but today is in fact Mar 12, which is 1 day later. What is the date 24 hours later in MM/DD/YYYY?# If Jane thought today is 3/11/2002, but today is in fact Mar 12, then today is 3/12/2002.today = datetime(2002, 3, 12)# 24 hours later,later = today + relativedelta(hours=24)# The answer formatted with %m/%d/%Y islater.strftime('%m/%d/%Y')# Q: Jane was born on the last day of Feburary in 2001. Today is her 16-year-old birthday. What is the date yesterday in MM/DD/YYYY?# If Jane was born on the last day of Feburary in 2001 and today is her 16-year-old birthday, then today is 16 years later.today = datetime(2001, 2, 28) + relativedelta(years=16)# Yesterday,yesterday = today - relativedelta(days=1)# The answer formatted with %m/%d/%Y isyesterday.strftime('%m/%d/%Y')# Q: {question}""".strip() + '\n'
llm_out = llm(DATE_UNDERSTANDING_PROMPT.format(question=question))print(llm_out)
这将输出以下内容:
# If today is 27 February 2023 and I was born exactly 25 years ago, then I was born 25 years before.today = datetime(2023, 2, 27)# I was born 25 years before,born = today - relativedelta(years=25)# The answer formatted with %m/%d/%Y isborn.strftime('%m/%d/%Y')
llm_out 是一段 python 代码,我们可以使用 exec 执行它:
exec(llm_out)print(born)
这将输出以下内容:02/27/1998
14、ReAct 框架
从 Yao 等人,2022 引入了一个框架,其中 LLMs 以交错的方式生成 推理轨迹 和 任务特定操作 。
生成推理轨迹使模型能够诱导、跟踪和更新操作计划,甚至处理异常情况。操作步骤允许与外部源(如知识库或环境)进行交互并且收集信息。
ReAct 框架允许 LLMs 与外部工具交互来获取额外信息,从而给出更可靠和实际的回应。
结果表明,ReAct 可以在语言和决策任务上的表现要高于几个最先进水准要求的的基线。ReAct 还提高了 LLMs 的人类可解释性和可信度。总的来说,作者发现了将 ReAct 和链式思考 (CoT) 结合使用的最好方法是在推理过程同时使用内部知识和获取到的外部信息。
它是如何运作的?
ReAct 的灵感来自于 “行为” 和 “推理” 之间的协同作用,正是这种协同作用使得人类能够学习新任务并做出决策或推理。
链式思考 (CoT) 提示显示了 LLMs 执行推理轨迹以生成涉及算术和常识推理的问题的答案的能力,以及其他任务 (Wei 等人,2022) 。但它因缺乏和外部世界的接触或无法更新自己的知识,而导致事实幻觉和错误传播等问题。
ReAct 是一个将推理和行为与 LLMs 相结合通用的范例。ReAct 提示 LLMs 为任务生成口头推理轨迹和操作。这使得系统执行动态推理来创建、维护和调整操作计划,同时还支持与外部环境(例如,Wikipedia)的交互,以将额外信息合并到推理中。下图展示了 ReAct 的一个示例以及执行问题回答所涉及的不同步骤。

图片来源:Yao等人,2022
在上面的例子中,我们将如下问题作为提示给出,该问题出自 HotpotQA :
除了苹果遥控器,还有哪些设备可以控制苹果遥控器最初设计用来交互的程序?
请注意,上下文中的示例也被添加到提示符中,但为了简单起见,我们在这里排除了它。我们可以看到,该模型生成了 “任务解决轨迹” (思考,行动)。Obs 对应与之交互的环境的观察 (例如搜索引擎)。从本质上讲,ReAct 可以检索信息来支持推理,而推理则有助于确定下一步检索的目标。
ReAct 提示
为了更好的阐释 ReAct 提示是如何运作的,我们继续跟随论文的示例。
第一步是从训练集 (例如 HotPotQA) 中选择案例,并组成 ReAct 格式的轨迹。这些在提示中作为少样本示例。轨迹由多思考-操作-观察步骤组成,如图所示。自由形式的思考用来完成不同的任务,如分解问题、提取信息、执行常识或算术推理、引导搜索公式和合成最终答案。
下面是一个 ReAct 提示的示例(摘自论文,为简单起见缩短为一个示例):
问题 科罗拉多造山带东部区域延伸到的区域的海拔范围是多少?思考 1 我需要搜索科罗拉多造山带,找到科罗拉多造山带东段延伸的区域,然后找到该区域的海拔范围。操作 1 搜索 [科罗拉多造山带]观察 1 科罗拉多造山带是科罗拉多及其周边地区造山运动的一段。思考 2 它没有提到东部地区。所以我需要查一下东部地区。操作 2 查找 [东部地区]观察 2 (结果 1 / 1) 东部区域延伸至高平原,称为中原造山带。思考 3 科罗拉多造山运动的东部区域延伸到高平原。所以我需要搜索高平原,找到它的海拔范围。操作 3 搜索 [高平原]观察 3 高平原指的是两个截然不同的陆地区域之一。思考 4 我需要搜索高平原(美国)操作 4 搜索 [高平原(美国)]观察 4 高平原是大平原的一个分区。从东到西,高平原的海拔从 1800 到 7000 英尺 (550 到 2130 米) 不等。[3]思考 5 高平原海拔高度从 1800 到 7000 英尺,所以答案是 1800 到 7000 英尺。操作 5 结束 [1800 到 7000 英尺]...
请注意,不同的提示设置用于不同类型的任务。对那些以推理为主要目标的任务 (例如 HotpotQA),多思考-操作-观察步骤用于任务-解决轨迹。对于涉及许多操作步骤的决策任务来说,则较少使用思考。
在知识密集型任务上的表现结果
论文首先对 ReAct 在知识密集型推理任务如问答 (HotPotQA) 和事实验证 (Fever ) 上进行了评估。PaLM-540B 作为提示的基本模型。
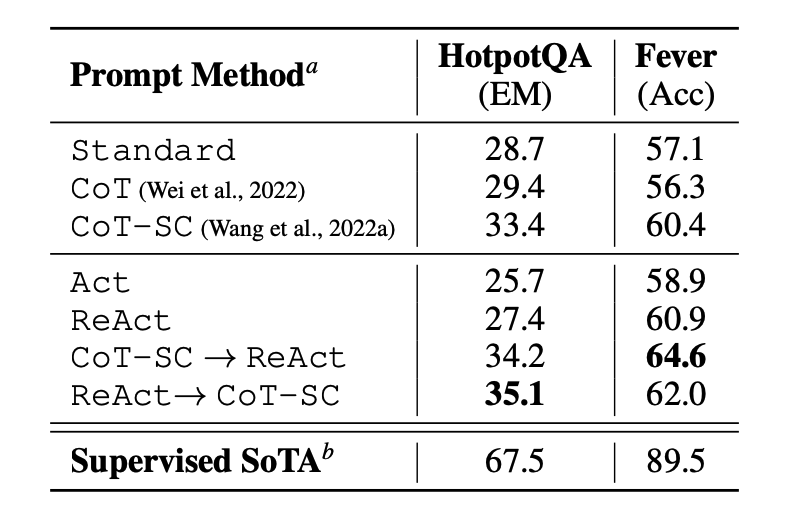
图片来源: Yao et al., 2022
通过在 HotPotQA 和 Fever 上使用不同提示方法得到的提示的表现结果说明了 ReAct 表现结果通常优于 Act (只涉及操作)。
我们还可以观察到 ReAct 在 Fever 上的表现优于 CoT,而在 HotpotQA 上落后于 CoT。文中对该方法进行了详细的误差分析。总而言之:
- CoT 存在事实幻觉的问题
- ReAct 的结构性约束降低了它在制定推理步骤方面的灵活性
- ReAct 在很大程度上依赖于它正在检索的信息;非信息性搜索结果阻碍了模型推理,并导致难以恢复和重新形成思想
结合并支持在 ReAct 和链式思考+自我一致性之间切换的提示方法通常优于所有其他提示方法。
在决策型任务上的表现结果
论文还给出了 ReAct 在决策型任务上的表现结果。ReAct 基于两个基准进行评估,分别是 ALFWorld (基于文本的游戏) 和 WebShop (在线购物网站环境)。两者都涉及复杂的环境,需要推理才能有效地行动和探索。
请注意,虽然对这些任务的 ReAct 提示的设计有很大不同,但仍然保持了相同的核心思想,即结合推理和行为。下面是一个涉及 ReAct 提示的 ALFWorld 问题示例。
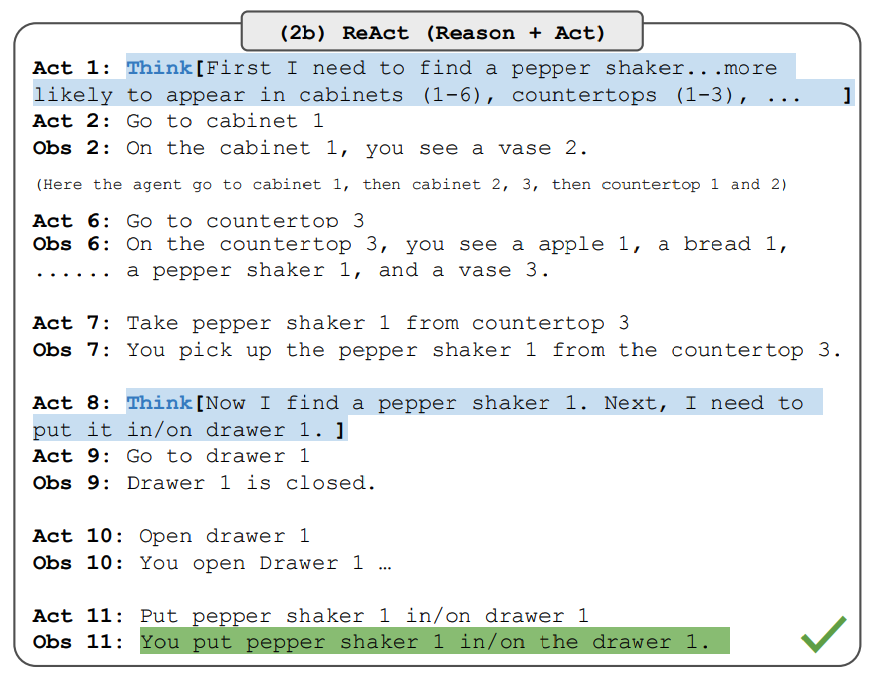
图片来源: Yao et al., 2022
ReAct 在 ALFWorld 和 Webshop 上都优于 Act。没有思考的 Act 不能正确地把目标分解成子目标。尽管在这些类型的任务中,ReAct 的推理显露出优势,但目前基于提示的方法在这些任务上的表现与人类专家相差甚远。
查看这篇论文了解结果详情。
长链 ReAct 的使用
下面是 ReAct 提示方法在实践中如何工作的高阶示例。我们将在 LLM 和 长链 中使用OpenAI,因为它已经具有内置功能,可以利用 ReAct 框架构建代理,这些代理能够结合 LLM 和其他多种工具的功能来执行任务。
首先,让我们安装并导入必要的库:
%%capture# 更新或安装必要的库!pip install --upgrade openai!pip install --upgrade langchain!pip install --upgrade python-dotenv!pip install google-search-results # 引入库import openaiimport osfrom langchain.llms import OpenAIfrom langchain.agents import load_toolsfrom langchain.agents import initialize_agentfrom dotenv import load_dotenvload_dotenv() # 载入 API keys; 如果没有,你需要先获取。 os.environ["OPENAI_API_KEY"] = os.getenv("OPENAI_API_KEY")os.environ["SERPER_API_KEY"] = os.getenv("SERPER_API_KEY")
现在我们可以配置 LLM,我们要用到的工具,以及允许我们将 ReAct 框架与 LLM 和其他工具结合使用的代理。请注意,我们使用搜索 API 来搜索外部信息,并使用 LLM 作为数学工具。
llm = OpenAI(model_name="text-davinci-003" ,temperature=0)tools = load_tools(["google-serper", "llm-math"], llm=llm)agent = initialize_agent(tools, llm, agent="zero-shot-react-description", verbose=True)
配置好之后,我们就可以用所需的查询或提示运行代理了。请注意,在这里,我们不会像论文中阐释的那样提供少样本的示例。
agent.run("奥利维亚·王尔德的男朋友是谁?他现在的年龄的0.23次方是多少?")
链执行如下所示:
> 正在输入新代理执行器链...... 我得查出奥利维亚·王尔德的男友是谁然后计算出他的年龄的 0.23 次方。操作: 搜索操作输入: “奥利维亚·王尔德的男友”观察: 奥利维亚·王尔德与杰森·苏代基斯在多年前订婚,在他们分手后,她开始与哈里·斯泰尔斯约会 — 参照他们的关系时间线。思考: 我需要找出哈里·斯泰尔斯的年龄。操作: 搜索操作输入: “哈里·斯泰尔斯的年龄”观察: 29 岁思考: 我需要计算 29 的 0.23 次方。操作: 计算器操作输入: 29^0.23观察: 答案: 2.169459462491557 思考: 现在我知道最终答案了。最终答案: 哈里·斯泰尔斯, 奥利维亚·王尔德的男朋友, 29 岁。他年龄的 0.23 次方是 2.169459462491557。 > 结束链。
我们得到如下输出:
"哈里·斯泰尔斯, 奥利维亚·王尔德的男朋友, 29 岁。他年龄的 0.23 次方是 2.169459462491557。"
这个例子我们摘自 LangChain 文档 并修改,所以这些都要归功于他们。我们鼓励学习者去探索工具和任务的不同组合。
您可以在这里找到这些代码:
https://github.com/dair-ai/Prompt-Engineering-Guide/blob/main/notebooks/react.ipynb
15、自我反思(Reflexion)
自我反思是一个通过语言反馈来强化基于语言的智能体的框架。根据 Shinn et al. (2023) ,“自我反思是一种‘口头’强化的新范例,它将策略参数化为智能体的记忆编码与 LLM 的参数选择配对。”
在高层次上,自我反思将来自环境的反馈(自由形式的语言或者标量)转换为语言反馈,也被称作 self-reflection,为下一轮中 LLM 智能体提供上下文。这有助于智能体快速有效地从之前的错误中学习,进而提升许多高级任务的性能。
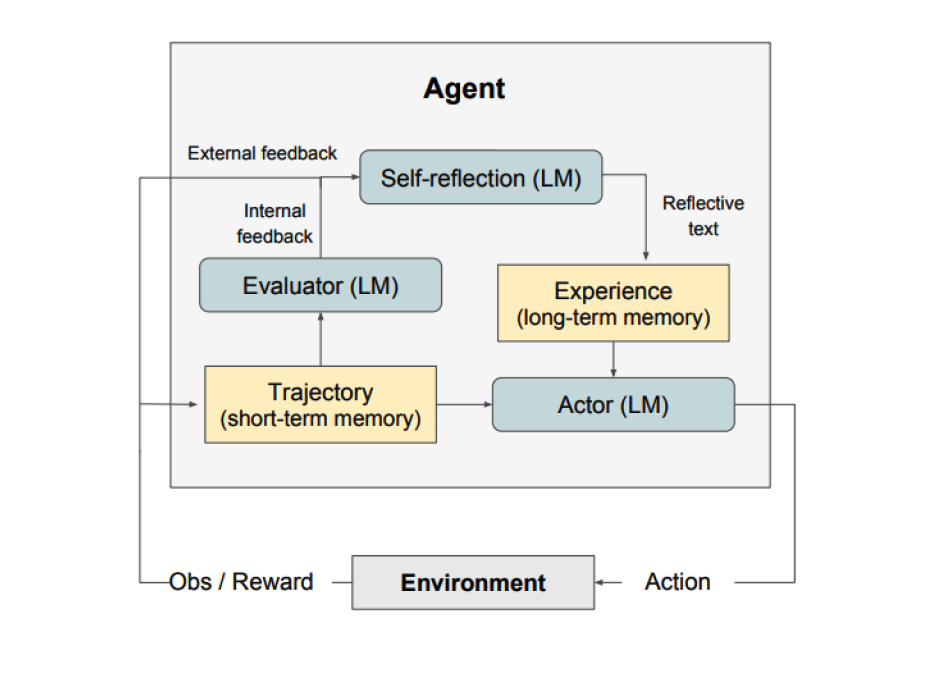
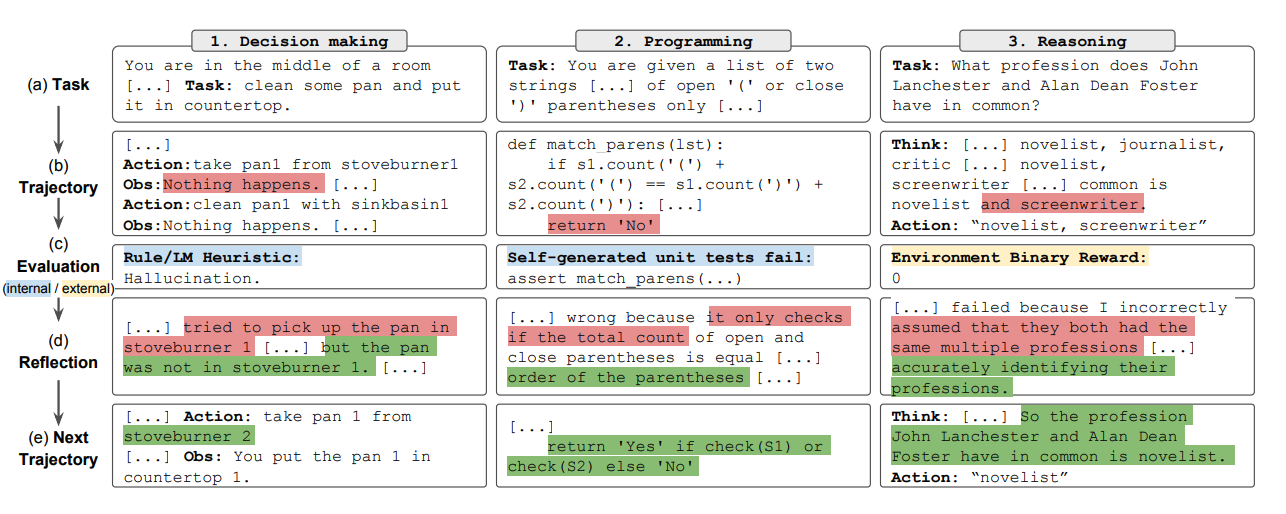
如上图所示,自我反思由三个不同的模型组成:
- 参与者(Actor):根据状态观测量生成文本和动作。参与者在环境中采取行动并接受观察结果,从而形成轨迹。链式思考(CoT) 和 ReAct 被用作参与者模型。此外,还添加了记忆组件为智能体提供额外的上下文信息。
- 评估者(Evaluator):对参与者的输出进行评价。具体来说,它将生成的轨迹(也被称作短期记忆)作为输入并输出奖励分数。根据人物的不同,使用不同的奖励函数(决策任务使用LLM和基于规则的启发式奖励)。
- 自我反思(Self-Reflection):生成语言强化线索来帮助参与者实现自我完善。这个角色由大语言模型承担,能够为未来的试验提供宝贵的反馈。自我反思模型利用奖励信号、当前轨迹和其持久记忆生成具体且相关的反馈,并存储在记忆组件中。智能体利用这些经验(存储在长期记忆中)来快速改进决策。
总的来说,自我反思的关键步骤是a)定义任务,b)生成轨迹,c)评估,d)执行自我反思,e)生成下一条轨迹。
下图展示了自我反思的智能体学习迭代优化其行为来解决决策、编程和推理等各种人物的例子。
自我反思(Refelxion)通过引入自我评估、自我反思和记忆组件来拓展 ReAct 框架。
结果
实验结果表明,自我反思能够显著提高 AlfWorld 上的决策任务、HotPotQA 中的问题推理以及在 HumanEval 上的 Python 编程任务性能。
在序列决策 (AlfWorld) 任务上进行评估时,ReAct + Reflexion 用启发式和 GPT 的自我评估进行二元分类,完成了 130/134 项任务,显着优于 ReAct。
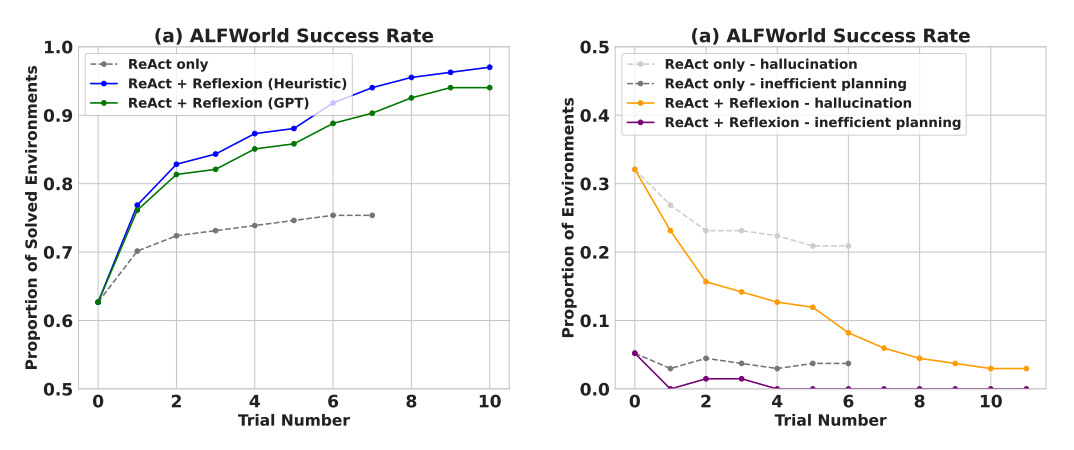
在仅仅几个学习步骤中,自我反思显著优于所有基线方法。仅对于推理以及添加由最近轨迹组成的情景记忆时,Reflexion + CoT 的性能分别优于仅 CoT 和具有情景记忆的 CoT。
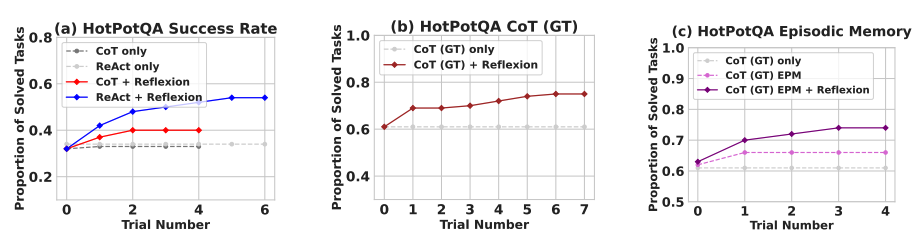
如下表所示,在 MBPP、HumanEval 和 Leetcode Hard 上编写 Python 和 Rust 代码时,Reflexion 通常优于之前的 SOTA 方法。

何时自我反思?
自我反思最适合以下情况:
- 智能体需要从尝试和错误中学习:自我反思旨在通过反思过去的错误并将这些知识纳入未来的决策来帮助智能体提高表现。这非常适合智能体需要通过反复试验来学习的任务,例如决策、推理和编程。
- 传统的强化学习方法失效:传统的强化学习(RL)方法通常需要大量的训练数据和昂贵的模型微调。自我反思提供了一种轻量级替代方案,不需要微调底层语言模型,从而使其在数据和计算资源方面更加高效。
- 需要细致入微的反馈:自我反思利用语言反馈,这比传统强化学习中使用的标量奖励更加细致和具体。这让智能体能够更好地了解自己的错误,并在后续的试验中做出更有针对性的改进。
- 可解释性和直接记忆很重要:与传统的强化学习方法相比,自我反思提供了一种更可解释、更直接的情景记忆形式。智能体的自我反思存储在其记忆组件中,让分析和理解其学习过程变得更加简单。
自我反思在以下任务中是有效的:
- 序列决策:自我反思提高了智能体在 AlfWorld 任务中的表现,涉及在各种环境中导航并完成多步目标。
- 推理:自我反思提高了 HotPotQA 上智能体的性能,HotPotQA 是一个需要对多个文档进行推理的问答数据集。
- 编程:自我反思的智能体在 HumanEval 和 MBPP 等基准测试上编写出了更好的代码,在某些情况下实现 SOTA 结果。
以下是自我反思的一些限制:
- 依赖自我评估能力:反思依赖于智能体准确评估其表现并产生有用反思的能力。这可能是具有挑战性的,尤其是对于复杂的任务,但随着模型功能的不断改进,预计自我反思会随着时间的推移而变得更好。
- 长期记忆限制:自我反思使用最大容量的滑动窗口,但对于更复杂的任务,使用向量嵌入或 SQL 数据库等高级结构可能会更有利。
- 代码生成限制:测试驱动开发在指定准确的输入输出映射方面存在限制(例如,受硬件影响的非确定性生成器函数和函数输出)。
图像来源:Reflexion: Language Agents with Verbal Reinforcement Learning
参考文献
- Reflexion: Language Agents with Verbal Reinforcement Learning
- Can LLMs Critique and Iterate on Their Own Outputs?
16、多模态思维链提示方法
最近,Zhang等人(2023) 提出了一种多模态思维链提示方法。传统的思维链提示方法侧重于语言模态。相比之下,多模态思维链提示将文本和视觉融入到一个两阶段框架中。第一步涉及基于多模态信息的理性生成。接下来是第二阶段的答案推断,它利用生成的理性信息。
多模态CoT模型(1B)在ScienceQA基准测试中的表现优于GPT-3.5。
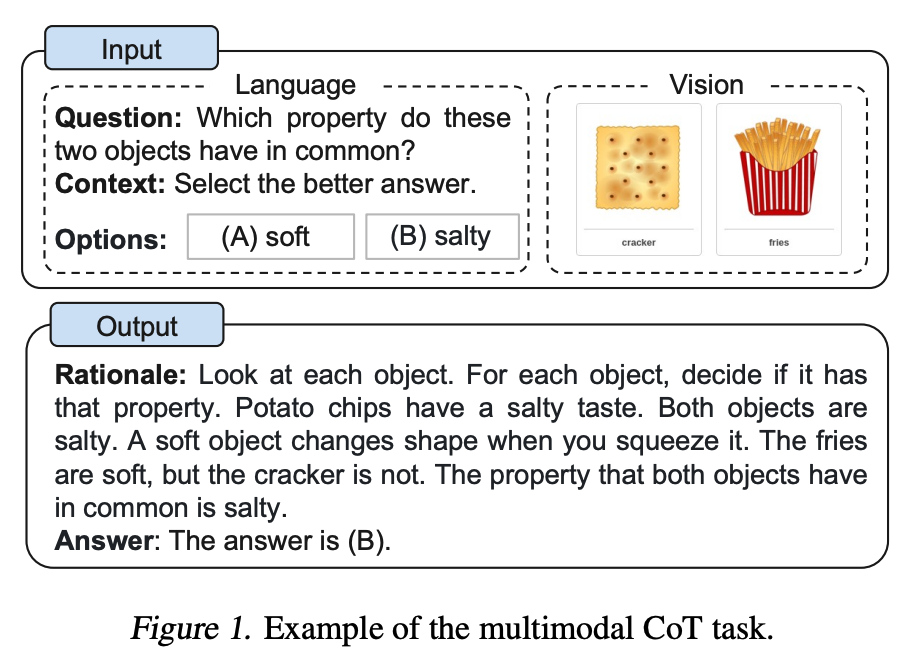
图片来源:Zhang et al. (2023)
进一步阅读:
- 语言不是你所需要的全部:将感知与语言模型对齐 (2023年2月)
17、GraphPrompts
Liu等人,2023 介绍了GraphPrompt,一种新的图形提示框架,用于提高下游任务的性能。
2024-05-21(二)