本文来源公众号“DeepDriving”,仅用于学术分享,侵权删,干货满满。
原文链接:CUDA编程-02: 初识CUDA编程
上一篇文章DeepDriving | CUDA编程-01: 搭建CUDA编程环境-CSDN博客介绍了如何搭建CUDA编程环境,从这篇文章开始正式开始介绍如何使用CUDA进行编程。
1 异构计算架构
如下图所示,一个典型的异构计算架构节点由一个多核CPU和一个或多个GPU组成,每个CPU和GPU都是独立的设备,它们之间通过PCIe总线连接。GPU作为CPU的协处理器用于执行一些并行计算任务。CPU适合用于做一些逻辑控制任务,而GPU则适合作为CPU的协处理器用于做一些大计算量的数据并行计算任务。
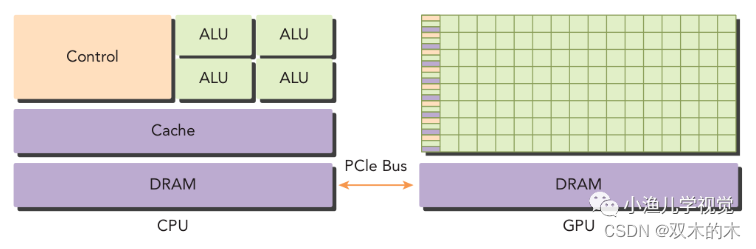
heterogeneous_architecture
一般我们称CPU为host,称GPU为device,相应地,一个异构计算的应用程序代码也被分为两部分:运行在CPU上的程序被称为host代码,运行在GPU上的程序被称为device代码。
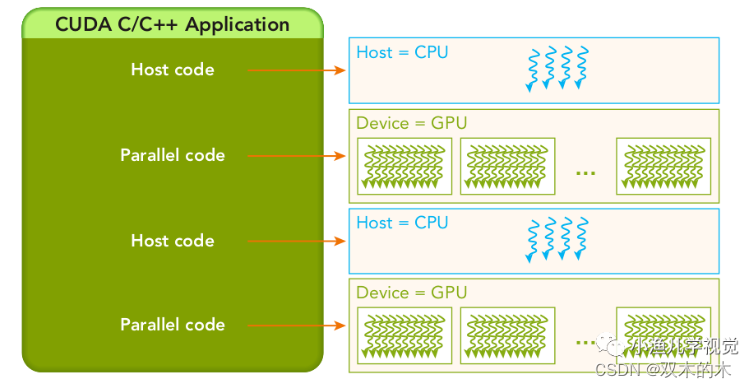
heterogeneous_architecture
2 一个Hello World
在我们学习一种新的编程语言的时候,一般都是先从打印一句"Hello World"开始,今天开始学习CUDA编程,按照国际惯例,也从打印"Hello World"开始。
首先新建一个CUDA C源文件hello_world.cu,然后输入下面的内容:
#include <stdio.h>
int main(void)
{
printf("Hello World from CPU\n");
return 0;
}
用nvcc进行编译生成可执行文件:
nvcc hello_world.cu -o hello_world
运行可执行文件hello_world,没有意外的话就能在终端看到打印出的"Hello World from CPU"了。这是在CPU上运行代码打印了这句话,那么怎么在GPU上打印呢?
要在GPU上运行程序,我们需要写一个能在GPU上执行的函数,然后在CPU上调用这个函数。来看一个例子:
#include <stdio.h>
__global__ void HelloFromGPU(void)
{
printf("Hello from GPU\n");
}
int main(void)
{
printf("Hello from CPU\n");
HelloFromGPU<<<1, 5>>>();
cudaDeviceReset();
return 0;
}
在上面的这段代码里,我添加了一个用__global__函数类型限定符修饰的函数HelloFromGPU,然后在main函数中去调用它。在CUDA中,有以下3种函数类型限定符:
_global_
被__global__函数类型限定符修饰的函数被称为内核函数,该函数在host上被调用,在device上执行,只能返回void类型,不能作为类的成员函数。调用__global__修饰的函数是异步的,也就是说它未执行完就会返回。
_device_
被__device__函数类型限定符修饰的函数只能在device上被调用,在device上执行,用于在device代码中内部调用。
_host_
被__host__函数类型限定符修饰的函数只能在host上被调用,在host上执行,也就是host上的函数,__host__函数类型限定符可以省略。
与调用一般CPU函数不同的是,调用HelloFromGPU函数的时候会在后面写上<<< >>>,意思这是从host端到device端的内核函数调用,里面的参数是执行配置,用来说明使用多少线程来执行内核函数。一个内核函数是通过一组线程来执行的,所有线程执行的同样的代码,我这里设置的是用了5个线程来执行。程序编译成功后运行得到如下结果:
Hello from CPU
Hello from GPU
Hello from GPU
Hello from GPU
Hello from GPU
Hello from GPU
可以看到,内核函数里的打印语句被执行了5次。
3 用CUDA实现数组相加
一个典型的CUDA程序结构一般由以下5个步骤组成:
-
分配
GPU内存; -
从
CPU内存中拷贝数据到GPU内存中; -
调用
CUDA内核函数执行程序指定的计算任务; -
从
GPU内存中把数据拷贝回CPU内存中; -
释放
GPU内存;
下面以一个数组相加的例子来展示以上过程,数组相加的计算过程比较简单:数组a和数组b中对应下标的元素相加然后存入数组c中。
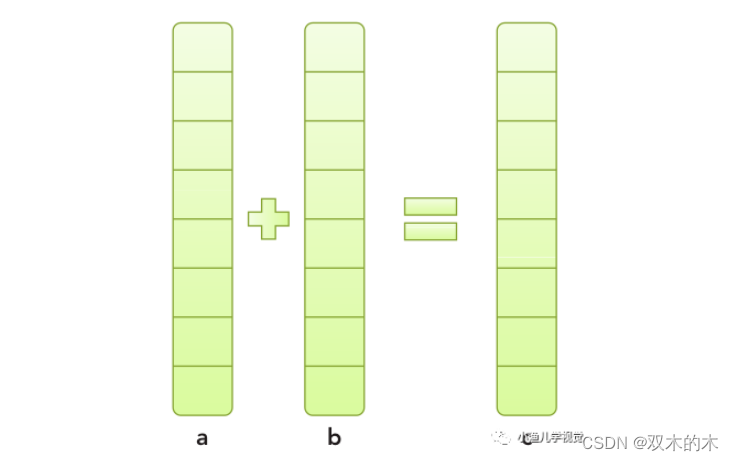
vector_add
首先来看一下在CPU上实现数组相加的代码:
#include <iostream>
void VectorAddCPU(const float *const a, const float *const b, float *const c,
const int n) {
for (int i = 0; i < n; ++i) {
c[i] = a[i] + b[i];
}
}
int main(void) {
// alloc memory for host
const size_t size = 1024;
float *ha = new float[size]();
float *hb = new float[size]();
float *hc = new float[size]();
for (int i = 0; i < size; ++i) {
ha[i] = i;
hb[i] = size - i;
}
VectorAddCPU(ha, hb, hc, size);
delete[] ha;
delete[] hb;
delete[] hc;
return 0;
}
函数VectorAddCPU用了一个for循环在CPU上实现数组相加的过程。如果要用GPU来实现该过程,则调用CUDA的API按照前面说的5个步骤编写代码:
#include <cuda_runtime.h>
#include <iostream>
__global__ void VectorAddGPU(const float *const a, const float *const b,
float *const c, const int n) {
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < n) {
c[i] = a[i] + b[i];
}
}
int main(void) {
// 分配CPU内存
const size_t size = 1024;
float *ha = new float[size]();
float *hb = new float[size]();
float *hc = new float[size]();
for (int i = 0; i < size; ++i) {
ha[i] = i;
hb[i] = size - i;
}
// 分配GPU内存
float *da = nullptr;
float *db = nullptr;
float *dc = nullptr;
cudaMalloc((void **)&da, size);
cudaMalloc((void **)&db, size);
cudaMalloc((void **)&dc, size);
// 把数据从CPU拷贝到GPU
cudaMemcpy(da, ha, size, cudaMemcpyHostToDevice);
cudaMemcpy(db, hb, size, cudaMemcpyHostToDevice);
cudaMemcpy(dc, hc, size, cudaMemcpyHostToDevice);
const int thread_per_block = 256;
const int block_per_grid = (size + thread_per_block - 1) / thread_per_block;
// 调用核函数
VectorAddGPU<<<block_per_grid, thread_per_block>>>(da, db, dc, size);
// 把数据从GPU拷贝回CPU
cudaMemcpy(hc, dc, size, cudaMemcpyDeviceToHost);
// 释放GPU内存
cudaFree(da);
cudaFree(db);
cudaFree(dc);
// 释放CPU内存
delete[] ha;
delete[] hb;
delete[] hc;
return 0;
}
在这段代码里,用到了几个CUDA的内存管理函数:
cudaMalloc
函数原型:
cudaError_t cudaMalloc(void** devPtr, size_t size)
该函数用于在GPU上分配指定大小的内存空间,类似于标准C语言中的malloc函数。
cudaMemcpy
函数原型:
cudaError_t cudaMemcpy(void* dst, const void* src, size_t count, cudaMemcpyKind kind)
该函数用于内存拷贝,类似于标准C语言中的memcpy函数。数据拷贝的流向由参数kind指定,分为以下4种方式:
-
cudaMemcpyHostToHost
-
cudaMemcpyHostToDevice
-
cudaMemcpyDeviceToHost
-
cudaMemcpyDeviceToDevice
从它们的字面意思就能知道,如果是从host拷贝数据到device,那么kind参数应该设置为cudaMemcpyHostToDevice;如果是从device拷贝数据到host,那么kind参数应该设置为cudaMemcpyDeviceToHost。上面的代码体现了这一点。
cudaFree
udaError_t cudaFree(void* devPtr)
该函数用于释放已分配的GPU内存空间,类似于标准C语言中的free函数。
在上面的代码中,内核函数VectorAddGPU用于实现数组相加,与前面的代码中VectorAddCPU函数不同的是,VectorAddGPU函数里面并没有用for循环,因为在GPU中是将数据进行并行化划分,然后通过线程组去实现计算过程的,线程组中的每个线程都是执行c[i] = a[i] + b[i]这个计算过程。在这个程序里,数组的长度为1024,我设置了每个线程组中的线程数量为256,总共用了4个线程组去进行计算。
关于GPU中线程和线程组的相关知识,我将在下一篇文章中进行阐述。
4 参考资料
-
《
Professional CUDA C Programming》 -
《
CUDA C Programming_Guide》
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。