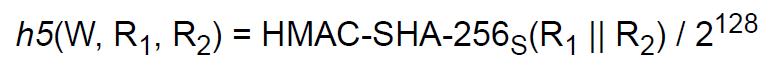使用决策树对金融贷款数据进行分析
在本篇博客中,我们将通过使用 Python、Pandas 和多种机器学习技术,对一组贷款数据进行全面分析。通过详细的步骤展示,你将学会如何进行数据预处理、可视化分析以及构建预测模型。
第一步:导入数据和必要的库
首先,我们需要导入数据并加载所需的库:
import pandas as pd
data = pd.read_csv("new_file.csv").sample(n=20000, random_state=42)
第二步:数据预处理
在数据预处理中,我们主要解决数据类型问题、处理缺失值以及删除无关特征:
data.drop(['id', 'url', 'desc', 'member_id'], axis=1, inplace=True)
可以通过指定 dtype 选项或者设置 low_memory=False 来解决此警告。
检查和处理缺失值和无限值
import numpy as np
inf_values = data[data == np.inf].values.any()
print(inf_values)
data.fillna(data.mean(), inplace=True)
data.interpolate(method='linear', inplace=True)
第三步:数据可视化
贷款金额分布
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(10, 6))
sns.histplot(data['loan_amnt'], bins=30, kde=True, color='skyblue')
plt.title('贷款金额分布')
plt.xlabel('贷款金额')
plt.ylabel('频率')
plt.show()

信用等级分布
plt.figure(figsize=(10, 6))
data['grade'].value_counts().plot(kind='bar', color='lightgreen')
plt.title('信用等级分布')
plt.xlabel('信用等级')
plt.ylabel('频率')
plt.show()

按贷款状态划分的年收入分布
plt.figure(figsize=(10, 6))
sns.boxplot(x='loan_status', y='annual_inc', data=data)
plt.title('按贷款状态划分的年收入分布')
plt.xlabel('贷款状态')
plt.ylabel('年收入')
plt.show()

第四步:特征工程
处理日期特征
data['earliest_cr_line'] = pd.to_datetime(data['earliest_cr_line'])
data['issue_d'] = pd.to_datetime(data['issue_d'])
data['credit_hist'] = (data['issue_d'] - data['earliest_cr_line']).dt.days
data.drop(['earliest_cr_line', 'issue_d'], axis=1, inplace=True)
编码类别型特征
from sklearn.preprocessing import LabelEncoder
cat_cols = data.select_dtypes(include=['object']).columns
le = LabelEncoder()
for col in cat_cols:
data[col] = le.fit_transform(data[col])
第五步:相关性分析
最后,我们通过热图来展示特征之间的相关性:
plt.figure(figsize=(12, 8))
corr = data.corr()
sns.heatmap(corr, cmap='coolwarm', annot=False)
plt.title('相关性热图')
plt.show()

第六步:划分训练集和测试集
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
X = data.drop('loan_status', axis=1)
y = data['loan_status']
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
第七步:构建和评估模型
我们使用决策树分类器来进行预测,并评估模型的性能:
from sklearn.metrics import accuracy_score, classification_report
from sklearn.tree import DecisionTreeClassifier
dt_model = DecisionTreeClassifier(random_state=42)
dt_model.fit(X_train, y_train)
y_pred = dt_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)
print("分类报告:\n", classification_report(y_test, y_pred))

通过这些步骤,我们成功地对贷款数据进行了分析和建模,希望这篇教程能够帮助你更好地理解数据科学的工作流程。
**如有遇到问题可以找小编沟通交流哦。另外小编帮忙辅导大课作业,学生毕设等。不限于MapReduce, MySQL, python,java,大数据,模型训练等。 hadoop hdfs yarn spark Django flask flink kafka flume datax sqoop seatunnel echart可视化 机器学习等 **