目录
16.1 数据字典架构
如何升级数据字典
使用MySQL的调试版本查看数据字典表
16.2 删除基于文件的元数据存储
.frm文件
.par文件
.TRN文件
.TRG文件
.isl文件
db.opt文件
ddl_log.log文件
16.3 字典数据的事务存储
16.4 字典对象缓存
表空间定义缓存分区:
架构定义缓存分区:
表定义缓存分区:
存储程序定义缓存分区:
字符集定义缓存分区:
排序规则定义缓存分区:
16.5 INFORMATION_SCHEMA与数据字典集成
16.6 序列化字典信息(SDI)
16.7 数据字典用法差异
16.7.1 innodb_read_only
16.7.2 字典表可见性
16.7.3 INFORMATION_SCHEMA
16.7.3.1行顺序
16.7.3.2 大小写列名
16.7.3.3 mysqlpump不再转储INFORMATION_SCHEMA数据库
16.7.3.4 src_tbl
16.7.3.5 固定表头大写
16.7.4 转储
16.8 数据字典限制
通俗的说,数据字典就是用于存放Mysql某个数据库实例本身描述信息,特征信息,元数据信息的字典表。
官方文档全翻译:
MySQL 服务器包含一个事务数据字典,用于存储有关数据库对象的信息。在以前的 MySQL 版本中,字典数据存储在元数据文件、非事务表和特定于存储引擎的数据字典中。
本章介绍数据字典的主要特性、优点、使用差异和局限性。有关数据字典功能的其他含义,请参阅 MySQL 8.0 发行说明中的“数据字典说明”部分。
MySQL 数据字典的优点包括:
1.统一存储字典数据的集中式数据字典模式的简单性。
删除基于文件的元数据存储
字典数据的事务性、防崩溃存储
字典对象的统一集中缓存
一些表的更简单和改进的实现 INFORMATION_SCHEMA
原子 DDL
16.1 数据字典架构
数据字典表受到保护,只能在 MySQL 的调试版本中访问。但是,MySQL支持通过INFORMATION_SCHEMA表和SHOW关键字访问数据字典表中存储的数据。有关组成数据字典的表的概述,请参阅 数据字典表。
MySQL 8.0中仍然存在MySQL系统表,可以通过在MySQL系统数据库上发出SHOW tables语句来查看这些表。通常,MySQL数据字典表和系统表的区别在于,数据字典表包含执行SQL查询所需的元数据,而系统表包含时区和帮助信息等辅助数据。MySQL系统表和数据字典表在升级方式上也有所不同。MySQL服务器管理数据字典升级。请参阅如何升级数据字典。升级MySQL系统表需要运行完整的MySQL升级过程。请参阅第3.4节“MySQL升级过程的升级内容”。
如何升级数据字典
MySQL的新版本可能包括对数据字典表定义的更改。这些更改存在于新安装的MySQL版本中,但在执行MySQL二进制文件的就地升级时,当使用新的二进制文件重新启动MySQL服务器时,会应用这些更改。在启动时,将服务器的数据字典版本与存储在数据字典中的版本信息进行比较,以确定是否应该升级数据字典表。如果需要并支持升级,服务器将创建具有更新定义的数据字典表,将持久化元数据复制到新表,用新表原子替换旧表,并重新初始化数据字典。如果不需要升级,则在不更新数据字典表的情况下继续启动。
数据字典表的升级是一个原子操作,这意味着所有数据字典表都会根据需要进行升级,否则操作将失败。如果升级操作失败,则服务器启动将失败并出现错误。在这种情况下,旧的服务器二进制文件可以与旧的数据目录一起使用以启动服务器。当新的服务器二进制文件再次用于启动服务器时,将重新尝试数据字典升级。
通常,在成功升级数据字典表后,无法使用旧的服务器二进制文件重新启动服务器。因此,在升级数据字典表后,不支持将MySQL服务器二进制文件降级到以前的MySQL版本。
mysqld--no-dd升级选项可用于防止启动时自动升级数据字典表。当--no指定dd升级,并且服务器发现服务器的数据字典版本与数据字典中存储的版本不同时,启动失败,并显示一个错误,说明禁止数据字典升级。
使用MySQL的调试版本查看数据字典表
默认情况下,数据字典表是受保护的,但可以通过编译带有调试支持的MySQL(使用-DITH_DEBUG=1 CMake选项)并指定+d,skip_dd_table_access_check调试选项和修饰符来访问。有关编译调试版本的信息,请参阅第7.9.1.1节“编译MySQL进行调试”。
警告
不建议直接修改或写入数据字典表,这可能会导致MySQL实例无法运行。
在使用调试支持编译MySQL之后,使用此SET语句使数据字典表对MySQL客户端会话可见:
mysql>SET SESSION debug='+d,skip_dd_table_access_check';使用此查询可以检索数据字典表的列表:
mysql>SELECT name, schema_id, hidden, type FROM mysql.tables where schema_id=1 AND hidden='System';使用SHOW CREATE TABLE可以查看数据字典表定义。例如
mysql>SHOW CREATE TABLE mysql.catalogs\G16.2 删除基于文件的元数据存储
在以前的MySQL版本中,字典数据部分存储在元数据文件中。
基于文件的元数据存储的问题包括昂贵的文件扫描、易受文件系统相关错误的影响、处理复制和崩溃恢复故障状态的复杂代码,以及缺乏可扩展性,难以为新功能和关系对象添加元数据。
下面列出的元数据文件已从MySQL中删除。
除非另有说明,以前存储在元数据文件中的数据现在存储在数据字典表中。
.frm文件
表元数据文件。随着.frm文件的删除:
1.取消了.frm文件结构施加的64KB表定义大小限制。
2.Information Schema TABLES表的VERSION列报告硬编码值10,这是MySQL 5.7中使用的最后一个.frm文件版本。
.par文件
分区定义文件。InnoDB停止使用MySQL 5.7中的分区定义文件,引入了对InnoDB表的本地分区支持。
.TRN文件
触发命名空间文件。
.TRG文件
触发器参数文件。
.isl文件
InnoDB符号链接文件,包含在数据目录之外创建的每个表空间文件的文件位置
db.opt文件
数据库配置文件。这些文件(每个数据库目录一个)包含数据库默认字符集属性。
ddl_log.log文件
该文件包含由数据定义语句(如DROP TABLE和ALTER TABLE)生成的元数据操作的记录。
16.3 字典数据的事务存储
数据字典数据库将字典数据存储在事务(InnoDB)表中。数据字典数据库与非数据字典数据库一起位于mysql实例中。
以下为本博主Anakki发言:
原文是The data dictionary schema,我这里将schema理解为数据字段字典库。
我们日常使用可知,一个Mysql实例下有多个数据库实例,一个数据库实例有多个表实例。
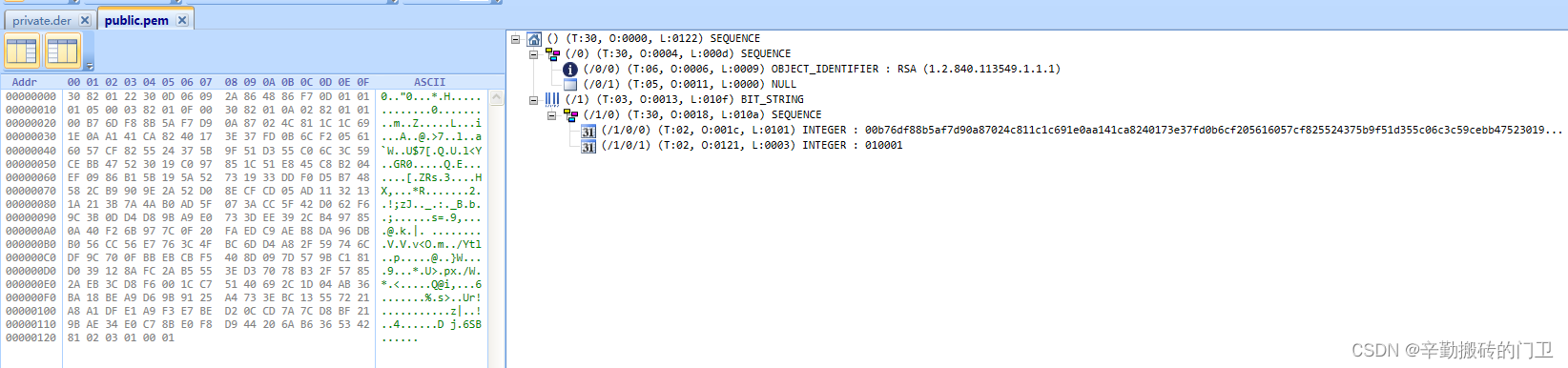
数据字典表是在一个名为mysql.ibd的InnoDB表空间中创建的,该表空间位于mysql数据目录中。mysql.ibd表空间文件必须位于mysql数据目录中,其名称不能被其他表空间修改或使用。
字典数据受到提交、回滚和崩溃恢复功能的保护,与保护存储在InnoDB表中的用户数据相同。
以下为本博主Anakki发言:
也就是说字典数据也提供事务的管理。与用户数据平起平坐。
16.4 字典对象缓存
字典对象缓存是一种共享的全局缓存,它将以前访问的数据字典对象存储在内存中,以实现对象重用并最大限度地减少磁盘I/O。与MySQL使用的其他缓存机制类似,字典对象缓存使用基于LRU的逐出策略来从内存中逐出最近使用最少的对象。
字典对象缓存包括存储不同对象类型的缓存分区。一些缓存分区大小限制是可配置的,而另一些则是硬编码的。
表空间定义缓存分区:
存储表空间定义对象。tablespace_definition_cache选项设置可以存储在字典对象缓存中的表空间定义对象的数量限制。默认值为256。
架构定义缓存分区:
存储架构定义对象。schema_dition_cache选项设置可以存储在字典对象缓存中的模式定义对象的数量限制。默认值为256。
表定义缓存分区:
存储表定义对象。对象限制被设置为max_connectionss的值,其默认值为151。表定义缓存分区与使用table_definition_cache配置选项配置的表定义缓存并行存在。这两个缓存都存储表定义,但为MySQL服务器的不同部分提供服务。一个缓存中的对象不依赖于另一个缓存是否存在对象。
存储程序定义缓存分区:
存储的程序定义对象。stored_program_definition_cache选项设置可存储在字典对象缓存中的已存储程序定义对象的数量限制。默认值为256。
存储程序定义缓存分区与使用stored_program_cache选项配置的存储过程和存储函数缓存并行存在。
stored_program_cache选项为每个连接缓存的存储过程或函数的数量设置了一个软上限,每次连接执行存储过程或功能时都会检查该限制。另一方面,存储程序定义缓存分区是一个共享缓存,用于存储用于其他目的的存储程序定义对象。对象在存储程序定义缓存分区中的存在与对象在存储过程缓存或存储函数缓存中的存在无关,反之亦然。
字符集定义缓存分区:
存储字符集定义对象,硬编码对象限制为256。
排序规则定义缓存分区:
存储排序规则定义对象,硬编码对象限制为256。
有关字典对象缓存配置选项的有效值的信息,请参阅第7.1.8节“服务器系统变量”
以下为本博主Anakki发言:
总结起来有5个缓存分区,缓存淘汰策略使用基于LRU的逐出策略来从内存中逐出最近使用最少的对象。
| 缓存名称 | 对象数量上限设置 |
| 表空间定义缓存 | stored_program_definition_cache 默认256 |
| 架构定义缓存 | schema_dition_cache 默认256 |
| 表定义缓存 | table_definition_cache max_connectionss:默认151 |
| 存储程序定义缓存 | stored_program_definition_cache 默认256 |
| 字符集定义缓存 | 固定为256 |
| 排序规则定义缓存 | 固定为256 |
16.5 INFORMATION_SCHEMA与数据字典集成
随着数据字典的引入,以下INFORMATION_SCHEMA表被实现为数据字典表上的视图:
CHARACTER_SETS
CHECK_CONSTRAINTS
COLLATIONS
COLLATION_CHARACTER_SET_APPLICABILITY
COLUMNS
COLUMN_STATISTICS
EVENTS
FILES
INNODB_COLUMNS
INNODB_DATAFILES
INNODB_FIELDS
INNODB_FOREIGN
INNODB_FOREIGN_COLS
INNODB_INDEXES
INNODB_TABLES
INNODB_TABLESPACES
INNODB_TABLESPACES_BRIEF
INNODB_TABLESTATS
KEY_COLUMN_USAGE
KEYWORDS
PARAMETERS
PARTITIONS
REFERENTIAL_CONSTRAINTS
RESOURCE_GROUPS
ROUTINES
SCHEMATA
STATISTICS
ST_GEOMETRY_COLUMNS
ST_SPATIAL_REFERENCE_SYSTEMS
TABLES
TABLE_CONSTRAINTS
TRIGGERS
VIEWS
VIEW_ROUTINE_USAGE
VIEW_TABLE_USAGE
对这些表的查询现在更高效,因为它们从数据字典库中获取信息,而不是通过其他较慢的方式。特别是,对于作为数据字典库视图的每个INFORMATION_SCHEMA表:
1.服务器不再需要为INFORMATION_SCHEMA表的每个查询创建临时表。
2.当底层数据字典表存储以前通过目录扫描(例如,枚举数据库中的数据库名称或表名)或文件打开操作(例如,从.frm文件读取信息)获得的值时,information_SCHEMA对这些值的查询现在改为使用表查找。(此外,即使对于非视图INFORMATION_SCHEMA表,也可以通过从数据字典中查找来检索数据库和表名等值,并且不需要扫描目录或文件。
3.底层数据字典表上的索引允许优化器构建高效的查询执行计划,而对于以前使用临时表处理INFORMATION_SCHEMA表的实现来说,这是不正确的。
前面的改进也适用于显示与 INFORMATION_SCHEMA表相对应的信息的SHOW语句, INFORMATION_SCHEMA是数据字典表上的视图。例如,SHOW DATABASES显示与SCHEMATA表相同的信息。
除了引入数据字典表的视图外,现在还缓存了statistics和tables表中包含的表统计信息,以提高INFORMATION_SCHEMA查询性能。information_schema_stats_expiry系统变量定义缓存的表统计信息过期前的一段时间。默认值为86400秒(24小时)。如果没有缓存的统计信息或统计信息已过期,则在查询表统计信息列时会从存储引擎中检索统计信息。要随时更新给定表的缓存值,请使用ANALYZE table
information_schema_stas_experity可以设置为0,以使information_schema查询直接从存储引擎检索最新的统计信息,这不如检索缓存的统计信息快。
有关更多信息,请参阅第10.2.3节“优化INFORMATION_SCHEMA查询”。
MySQL 8.0中的INFORMATION_SCHEMA表与数据字典紧密相连,导致了一些用法差异。参见第16.7节“数据字典用法差异”。
以下为本博主Anakki发言:
简而言之就是数据字典从以前的用文件存储元数据信息到现在使用表结构存储信息,可以用到表的缓存,以及索引,提高查询速度。
16.6 序列化字典信息(SDI)
MySQL除了将数据库对象的元数据存储在数据字典中之外,还将其以序列化的形式存储。这些数据被称为序列化字典信息(SDI)。
InnoDB将SDI数据存储在其表空间文件中。
NDBCLUSTER将SDI数据存储在NDB字典中。
(博主PS:)
NDBCLUSTER (也称为NDB)是一种内存存储引擎,提供高可用性和数据持久性功能
其他存储引擎将SDI数据存储在.SDI文件中,这些文件是为表的数据库目录中的给定表创建的。
SDI数据以紧凑的JSON格式生成。
串行字典信息(SDI)存在于除临时表空间和撤消表空间文件之外的所有InnoDB表空间文件中。
InnoDB表空间文件中的SDI记录仅描述表空间中包含的表和表空间对象。
SDI数据由表上的DDL操作或CHECK table FOR UPGRADE更新。当MySQL服务器升级到新版本或新版本时,SDI数据不会更新。
SDI数据的存在提供了元数据冗余。例如,如果数据字典变得不可用,则可以使用ibd2sdi工具直接从InnoDB表空间文件中提取对象元数据。
对于InnoDB,SDI记录需要一个单独的索引页,默认大小为16KB。但是,SDI数据经过压缩以减少存储占用空间。
对于由多个表空间组成的分区InnoDB表,SDI数据存储在第一个分区的表空间文件中。
MySQL服务器使用在DDL操作期间访问的内部API来创建和维护SDI记录。
IMPORT TABLE语句根据.sdi文件中包含的信息导入MyISAM表。有关更多信息,请参阅第15.2.6节“IMPORT TABLE语句”。
(博主PS:)
可以理解为,之前提到的数据字典库是对Mysql中各个数据库的定义,那么SDI就是对表的定义。
1.序列化存放在每个表的表空间中(Innodb)。
2.NDBCLUSTER将SDI数据存储在NDB字典中。
3.其他存储引擎将SDI数据存储在.SDI文件中
16.7 数据字典用法差异
与没有数据字典的服务器相比,使用启用数据字典的MySQL服务器会带来一些操作差异:
以前,启用innodb_read_only系统变量可以防止仅为innodb存储引擎创建和删除表。
16.7.1 innodb_read_only
从MySQL 8.0开始,启用innodb_read_only会阻止所有存储引擎执行这些操作。任何存储引擎的表创建和删除操作都会修改mysql系统数据库中的数据字典表,但这些表使用InnoDB存储引擎,在启用InnoDB_read_only时无法修改。同样的原理也适用于其他需要修改数据字典表的表操作。示例:
ANALYZE TABLE失败,因为它更新了存储在数据字典中的表统计信息。
ALTER TABLE tbl_name ENGINE=ENGINE_name失败,因为它更新了存储在数据字典中的存储引擎名称。
启用innodb_read_only对mysql系统数据库中的非数据字典表也有重要意义。有关详细信息,请参阅第17.14节“innodb启动选项和系统变量”中对innodb_read_only的描述
(博主PS:)
意思就是说其他数据库修改元数据时会去修改innodb数据引擎的数据(前文提到数据字典放在了innodb),如果你把它设置为只读了,那么其他数据库都修改不了元数据(例如表创建和删除操作)了。所以这里要注意innodb_read_only这个参数的使用,以前只影响你自己的innodb,现在影响大家的
16.7.2 字典表可见性
以前,mysql系统数据库中的表对DML和DDL语句是可见的。从MySQL 8.0开始,数据字典表是不可见的,不能直接修改或查询。但是,在大多数情况下,可以查询相应的INFORMATION_SCHEMA表。这使得底层数据字典表能够随着服务器开发的进行而更改,同时为应用程序使用维护稳定的INFORMATION_SCHEMA接口。
16.7.3 INFORMATION_SCHEMA
MySQL 8.0中的INFORMATION_SCHEMA表与数据字典紧密相连,导致了以下几个用法差异:
以前,INFORMATION_SCHEMA查询statistics和TABLES表中的表统计信息直接从存储引擎检索统计信息。从MySQL 8.0开始,默认情况下使用缓存的表统计信息。information_schema_stats_expiry系统变量定义缓存的表统计信息过期前的一段时间。默认值为86400秒(24小时)。(要随时更新给定表的缓存值,请使用ANALYZE TABLE.。)如果没有缓存的统计信息或统计信息已过期,则在查询表统计信息列时会从存储引擎中检索统计信息。要始终直接从存储引擎中检索最新的统计信息,请将information_schema_stats_experity设置为0。有关更多信息,请参阅第10.2.3节“Section 10.2.3, “Optimizing INFORMATION_SCHEMA Queries”.。
16.7.3.1行顺序
几个INFORMATION_SCHEMA表是数据字典表上的视图,使优化器能够使用这些底层表上的索引。因此,根据优化器的选择,INFORMATION_SCHEMA查询的结果的行顺序可能与以前的结果不同。如果查询结果必须具有特定的行排序特征,请包括ORDER BY子句。
16.7.3.2 大小写列名
INFORMATION_SCHEMA表上的查询可能会返回与早期MySQL系列不同的大小写列名。应用程序应该以不区分大小写的方式测试结果集列名。如果这不可行,解决方法是在选择列表中使用列别名,这些别名以所需的字母大小写返回列名。例如
SELECT TABLE_SCHEMA AS table_schema, TABLE_NAME AS table_name FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME = 'users';
16.7.3.3 mysqlpump不再转储INFORMATION_SCHEMA数据库
mysqldump和mysqlpump不再转储INFORMATION_SCHEMA数据库,即使在命令行上显式命名也是如此。
16.7.3.4 src_tbl
CREATE TABLE dst_tbl LIKE src_tbl要求src_tbl是基表,如果它是作为数据字典表视图的INFORMATION_SCHEMA表,则会失败。
16.7.3.5 固定表头大写
以前,从INFORMATION_SCHEMA表中选择的列的结果集标题使用查询中指定的大小写。此查询生成一个标题为table_name的结果集:
SELECT table_name FROM INFORMATION_SCHEMA.TABLES;
(博主PS:)
亲测这个会返回Mysql实例中所有数据库下的所有表名。
毕竟到这里我们已经知道数据库所有的元数据都存在INFORMATION_SCHEMA中了
这里的区别也就是表头现在固定为大写了

从MySQL 8.0开始,这些头都是大写的;前面的查询生成一个具有TABLE_NAME头的结果集。如有必要,可以使用列别名来实现不同的字母大小写。例如
SELECT table_name AS 'table_name' FROM INFORMATION_SCHEMA.TABLES;
16.7.4 转储
数据目录影响mysqldump和mysqlpump如何从mysql系统数据库中转储信息:
以前,可以转储mysql系统数据库中的所有表。从MySQL 8.0开始,mysqldump和mysqlpump只转储该数据库中的非数据字典表。
以前,当使用--all-databases选项时,--routines和--events选项不需要包括存储的例程和事件:转储包括mysql系统数据库,因此也包括包含存储的例程定义和事件定义的proc和事件表。
从MySQL 8.0开始,不使用事件表和进程表。对应对象的定义存储在数据字典表中,但这些表不会转储。要将存储的例程和事件包括在使用--all数据库生成的转储中,请显式使用--routines和--events选项。
以前,--routines选项需要proc表的SELECT权限。从MySQL 8.0开始,该表未被使用--例程需要全局SELECT权限。
以前,可以通过转储proc和事件表来转储存储的例程和事件定义及其创建和修改时间戳。
由于MySQL 8.0没有使用这些表,因此不可能转储时间戳。
以前,创建包含非法字符的存储例程会产生警告。从MySQL 8.0开始,这是一个错误。
博主PS:存储例程包含存储函数和存储过程
16.8 数据字典限制
本节介绍MySQL数据字典引入的临时限制。
不支持在数据目录下手动创建数据库目录(例如,使用mkdir)。MySQL Server无法识别手动创建的数据库目录。
由于写入存储、撤消日志和重做日志代替了.frm文件,DDL操作需要更长的时间。