前言
做数仓开发离不开 SQL ,写了很多 HQL 回头再看 MySQL 才发现,很多东西并不是 HQL 所独创的,而是几乎都来自于关系型数据库通用的 SQL;想到以后需要每天和数仓打交道,那么不管是 MySQL 还是 Oracle ,都需要深入了解一下,不能只停留在之前的 CRUD 上了。
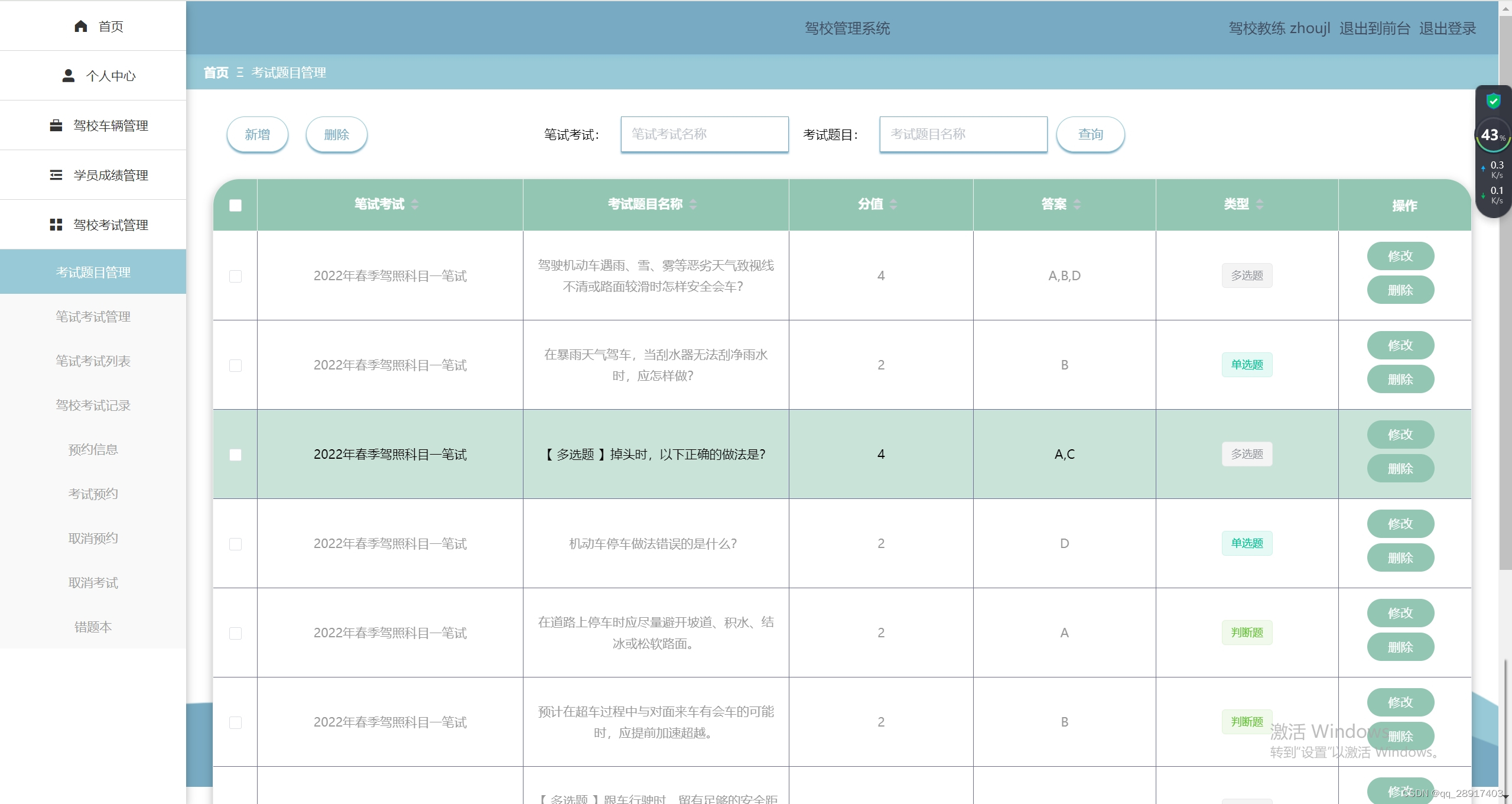
1、MySQL 函数
1.1、GROUP_CONCAT 聚合函数
1.1.1、语法
GROUP_CONCAT([DISTINCT] 字段名* [ORDER BY DESC|ASC] [SEPARATOR] )1.1.2、使用案例
把不同部门的员工合并到一行,按照 id 进行升序排序,并用 '-' 分割开来:
SELECT department,GROUP_CONCAT(DISTINCT emp_id,emp_name ORDER BY emp_id SEPARATOR '-') AS id_with_name
FROM emp
GROUP BY department;运行结果:

1.2、数学函数
简单的函数没有必要啰嗦,这里只介绍一些常用的:
- ABS:绝对值
- CEIL:向上取整
- FLOOR:向下取整
- RAND:0~1随机数
- ROUND(x):四舍五入取整
- ROUND(x,y):四舍五入保留 y 位小数
- TRUNCATE(x,y):不四舍五入保留 y 位小数
1.3、字符串函数
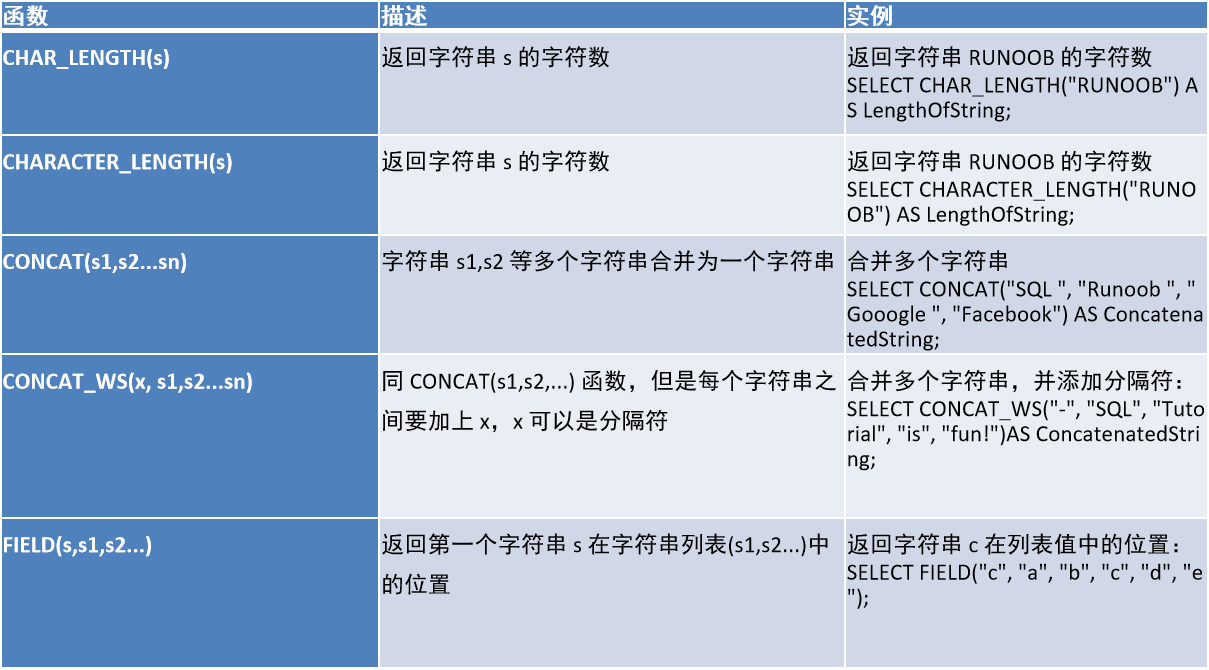
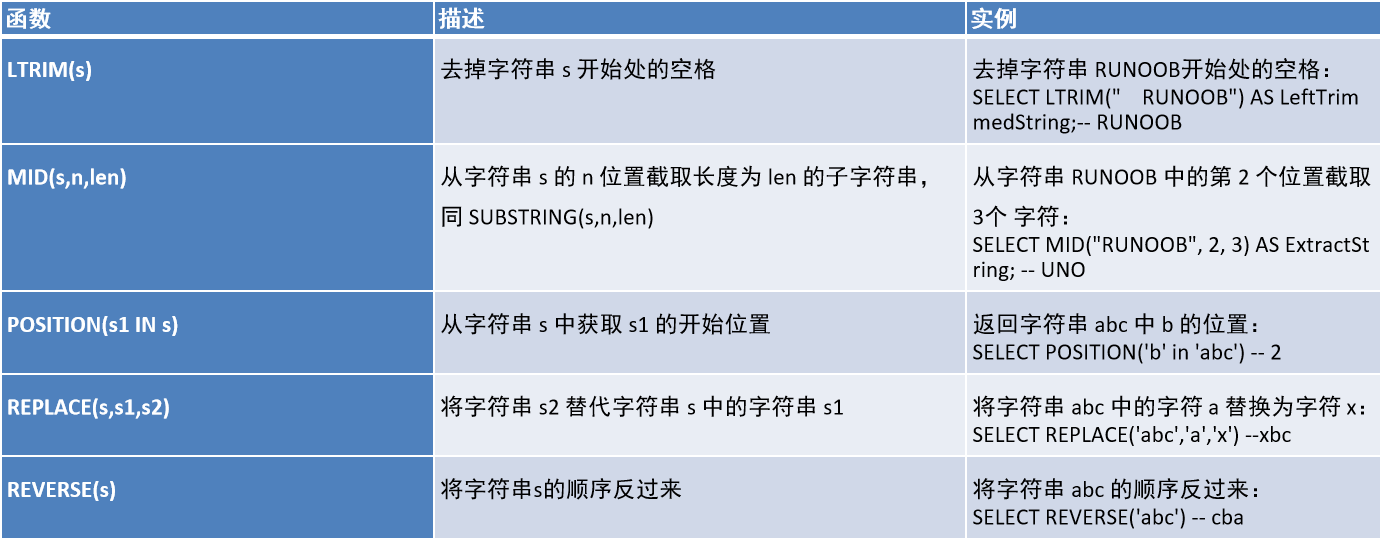
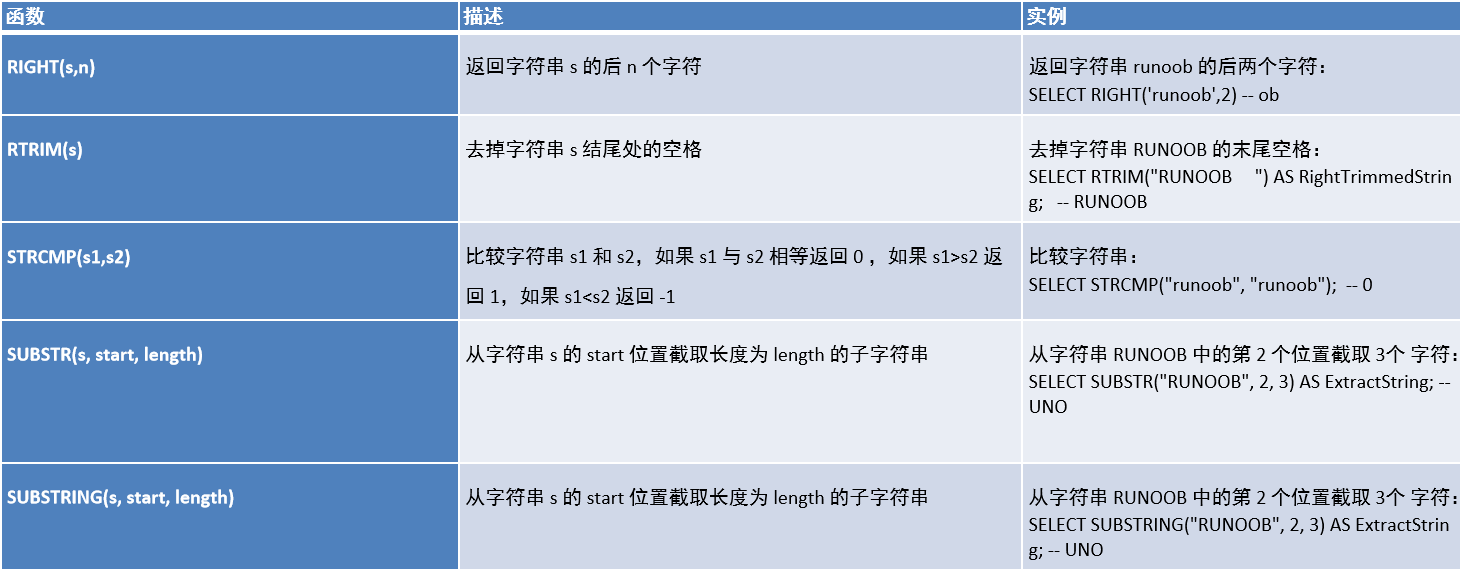
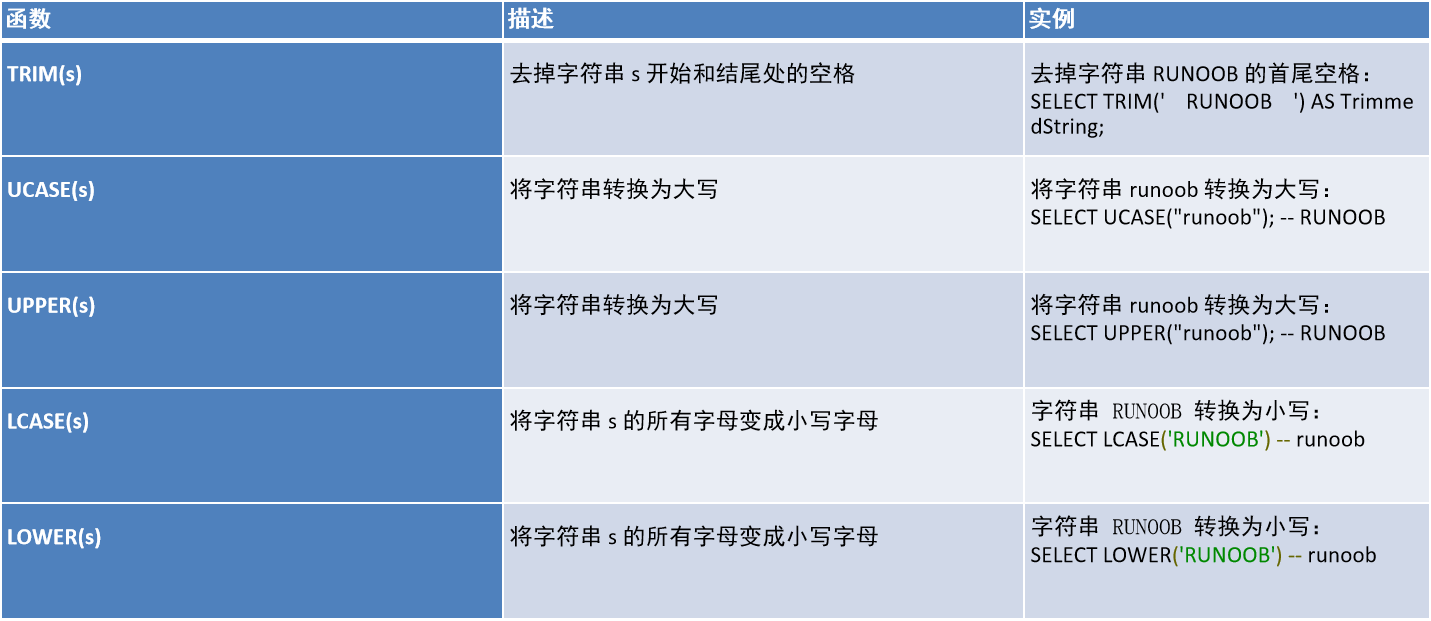
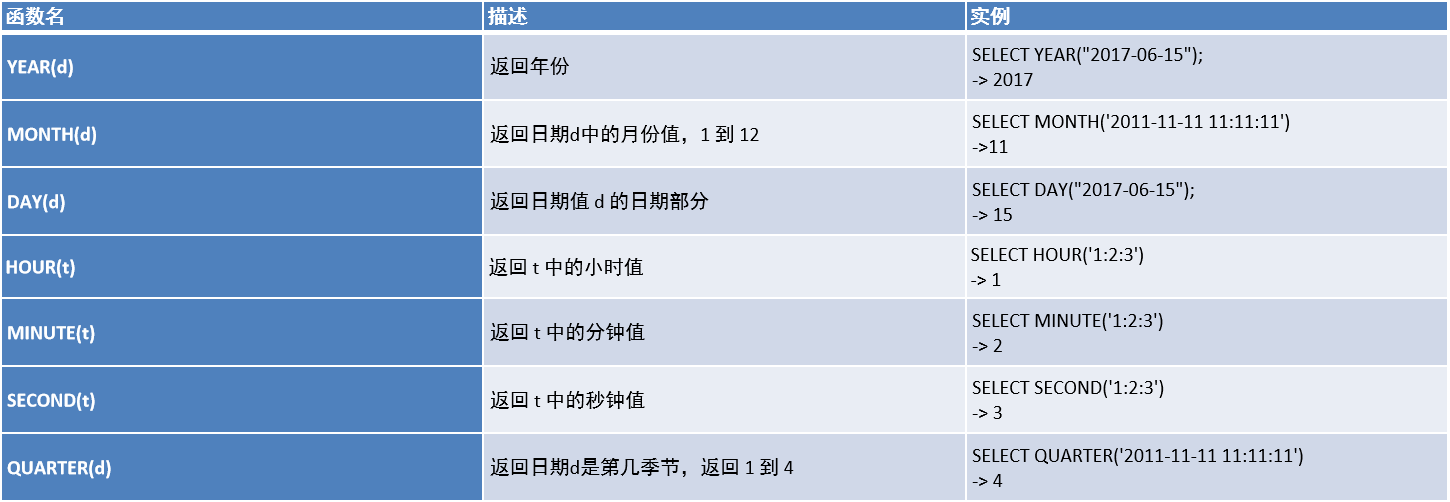
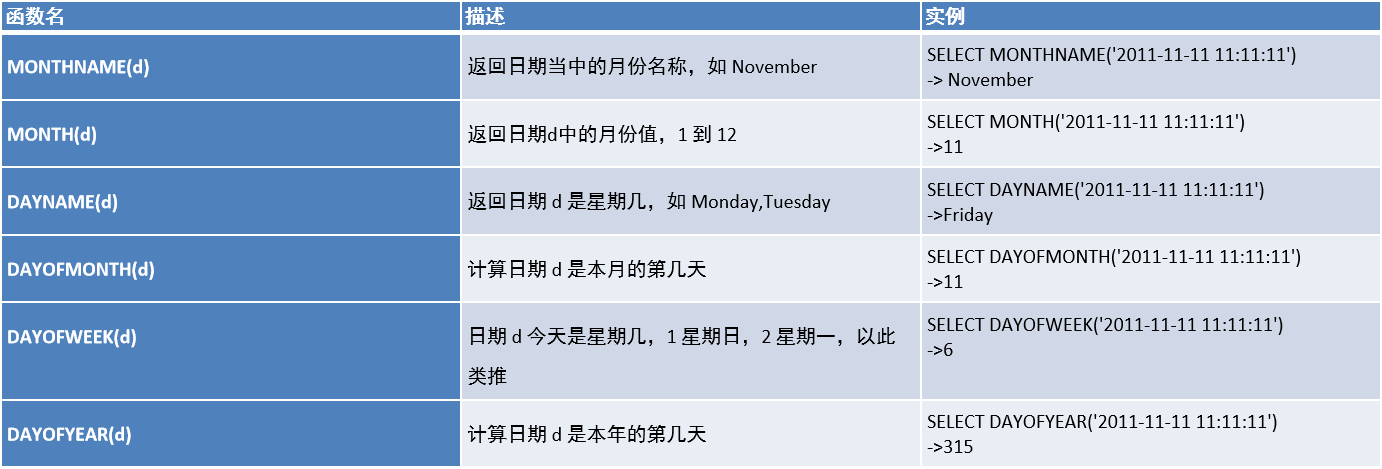
1.4、日期函数
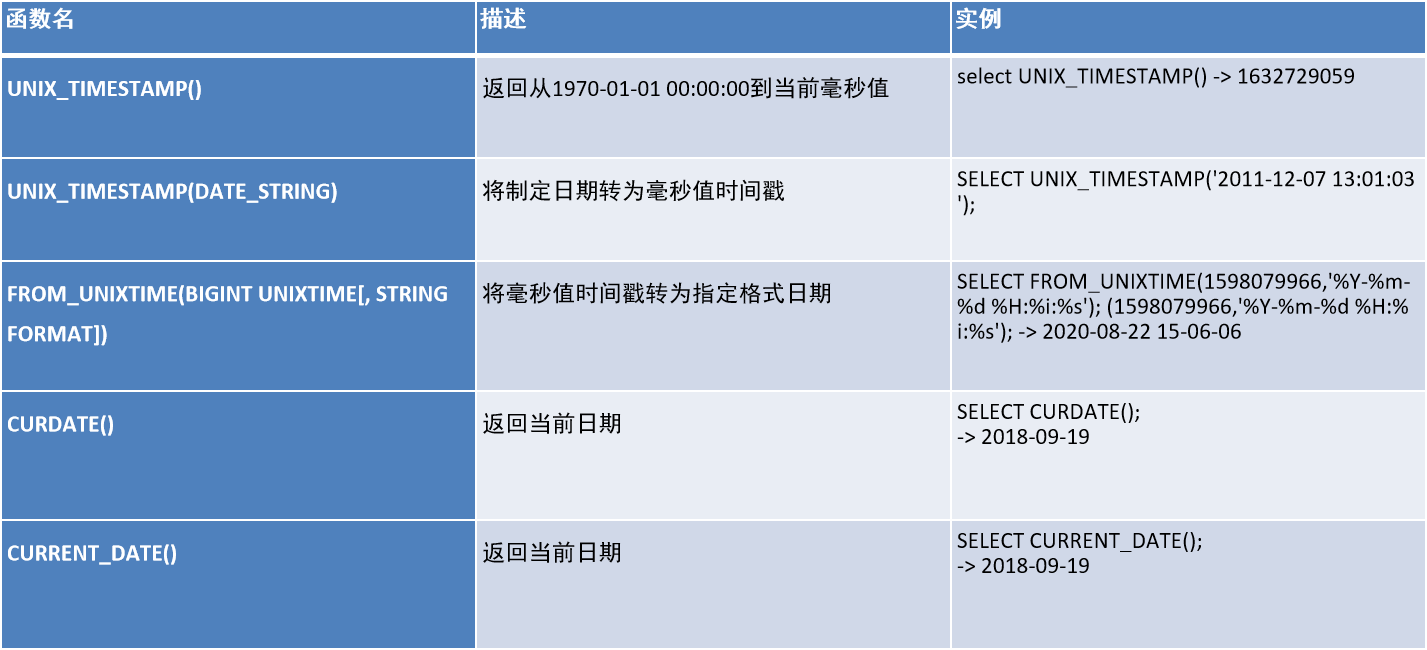
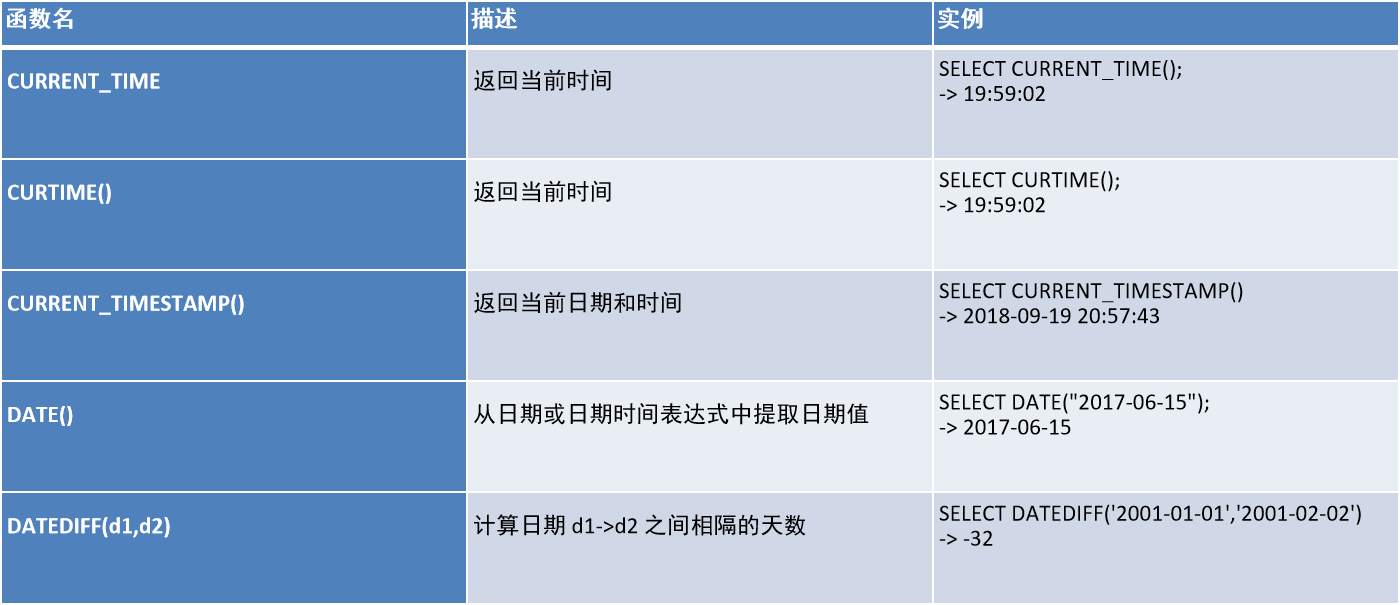
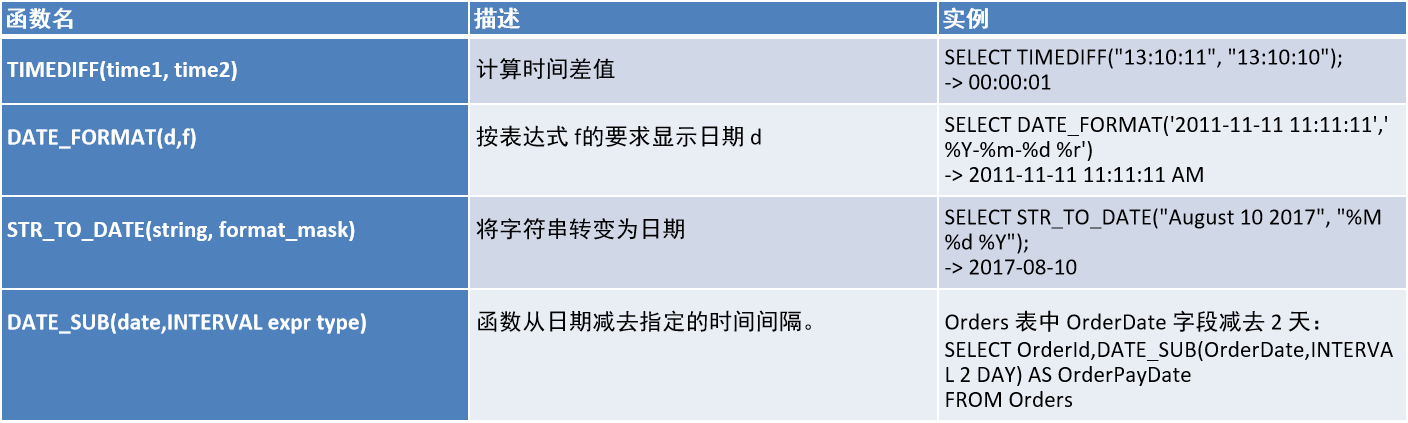
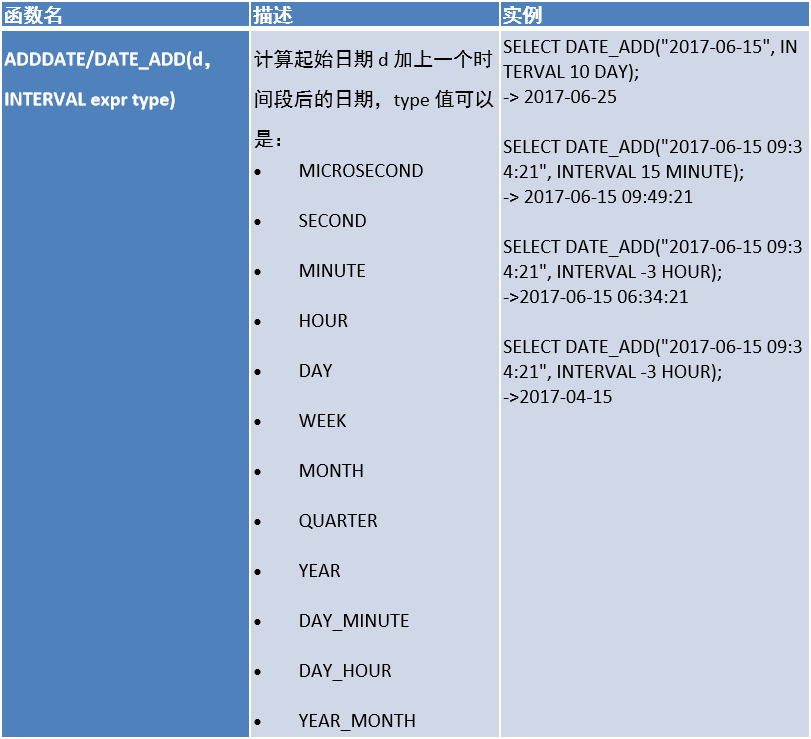

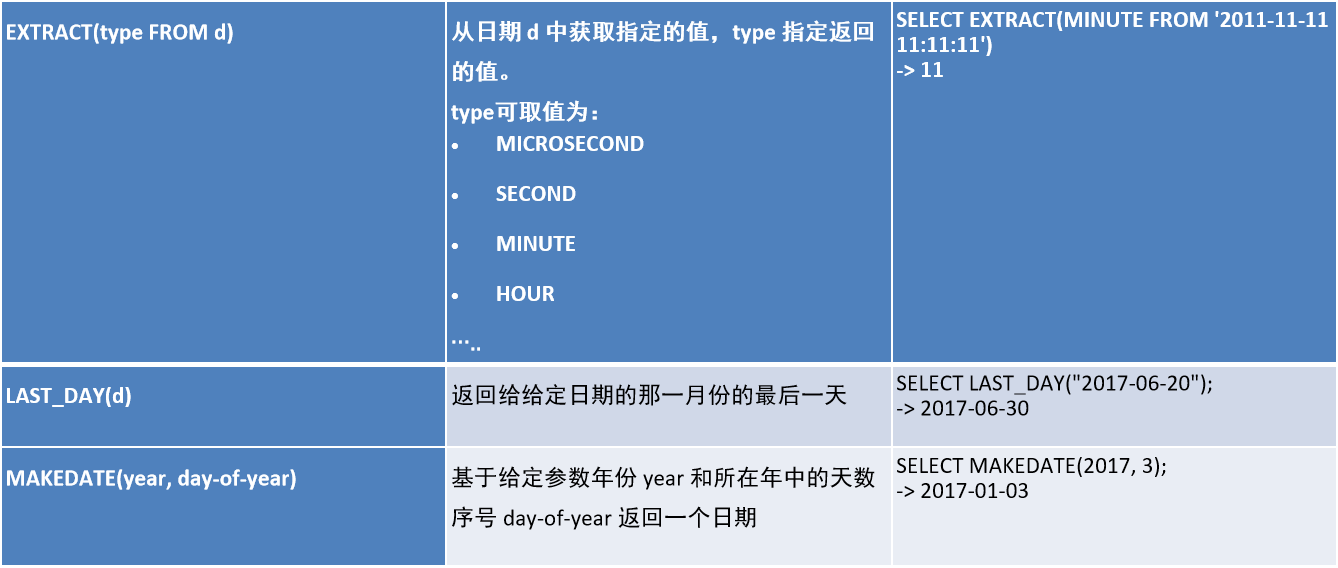

1.5、if 函数
MySQL 的 IF 函数和 HQL 是一样的,这里不做介绍。
1.6、窗口函数
窗口函数一般都是配合聚合函数使用的,毕竟使用窗口就是为了把一类时间或者其它属性有关系的数据联系在一起。这里同样只介绍一些我没用过的函数:
1.6.1、CUME_DIST
用途:分组内小于、等于当前rank值的行数 / 分组内总行数
公式:rank / rows
场景:查询小于等于当前行某个值的记录占总记录的比例
解释:其实就是用 rank 函数的结果 / 记录总数
-- 该员工的薪资超过了相同部门多少人
SELECT emp_id,
emp_name,
department,
salary,
ROUND(CUME_DIST() OVER (PARTITION BY department ORDER BY salary),2) AS rate
FROM emp;1.6.2、FIRST_VALUE 和 LAST_VALUE
用途:分组内的第一条/最后一条记录的某个字段的值
应用场景:截止目前按照xx排序后的第一名/最后一名的值
注意:它是对每一条记录都进行一次计算(相当于 rows between unbounded preceding and current row),而不是全局进行计算(它不会把该行之后考虑进计算范围)
-- 查询出同部门内工资最低和最高的人的薪资
SELECT emp_name,
salary,
FIRST_VALUE(salary) OVER (PARTITION BY department ORDER BY salary) AS first,
LAST_VALUE(salary) OVER (PARTITION BY department ORDER BY salary) AS last
FROM emp;1.6.3、NTH_VALUE
用途:返回窗口内地 exper 个值。(expr 可以是表达式,也可以是数字)
SELECT emp_name,
department,
salary,
NTH_VALUE(salary,2) over (PARTITION BY department ORDER BY salary) AS second
FROM emp;1.6.4、NTILE
用途:将分区中的有序数据分为n个等级,记录等级数(等级规则取决于是否分区和排序字段)
应用场景:将员工按照薪资进行划分等级
SELECT emp_name,
department,
salary,
NTILE(3) over (ORDER BY salary) AS grade
FROM emp;2、视图
2.1、视图的概念
介绍
- 视图(view)是一个虚拟表,非真实存在,其本质是根据SQL语句获取动态的数据集,并为其命名,用户使用时只需使用视图名称即可获取结果集,并可以将其当作表来使用。
- 数据库中只存放了视图的定义,而并没有存放视图中的数据。
- 这些数据存放在原来的表中。 使用视图查询数据时,数据库系统会从原来的表中取出对应的数据。因此,视图中的数据是依赖于原来的表中的数据的。一旦表中的数据发生改变,显示在视图中的数据也会发生改变。
作用
- 简化代码,可以把重复使用的查询封装成视图重复使用,同时可以使复杂的查询易于理解和使用。
- 安全原因,如果一张表中有很多数据,很多信息不希望让所有人看到,此时可以使用视图视,如:社会保险基金表,可以用视图只显示姓名,地址,而不显示社会保险号和工资数等,可以对不同的用户,设定不同的视图。
2.2、创建视图
这里只介绍常用的创建方法:
语法:
CREATE [OR REPLACE]
VIEW 视图名称
AS SELECT语句案例:
CREATE OR REPLACE
VIEW salary_grade
AS SELECT *, NTILE(3) over (ORDER BY salary) AS grade FROM emp;2.3、查看所有表和视图
SHOW FULL TABLES;2.4、修改视图
-- 1.通过alter修改视图
ALTER VIEW 视图名 AS SELECT语句;
-- 2.通过 create or replace 覆盖视图
CREATE OR REPLACE
VIEW 视图名
AS SELECT语句;某些视图是可更新的,比如基表。对于可更新的视图,在视图中的行和基表中的行之间必须具有一对一的关系。如果视图包含下述结构中的任何一种,那么它就是不可更新的:
- 聚合函数(SUM(), MIN(), MAX(), COUNT()等)
- DISTINCT
- GROUP BY
- HAVING
- UNION或UNION ALL
- 位于选择列表中的子查询
- JOIN
- FROM子句中的不可更新视图
- WHERE子句中的子查询,引用FROM子句中的表。
- 仅引用文字值(在该情况下,没有要更新的基本表)
注意:视图中虽然可以更新数据,也就是说,可以在UPDATE、DELETE或INSERT等语句中使用它们,以更新基表的内容。但是有很多的限制。一般情况下,最好将视图作为查询数据的虚拟表,而不要通过视图更新数据。因为,使用视图更新数据时,如果没有全面考虑在视图中更新数据的限制,就可能会造成数据更新失败。
-- 往视图中插入数据
INSERT INTO emp_order_by_salary(emp_id, emp_name, salary, department) VALUES (1001,'谢永强',3500,'人事部');
-- 修改视图数据
UPDATE emp_order_by_salary SET emp_name='狄仁杰' WHERE emp_id=1001;
-- 删除视图数据
DELETE FROM emp_order_by_salary WHERE emp_id=1001;注意:
- 视图永远只是一个虚拟表,不存储数据,修改视图就是修改基表!
3、存储过程
3.1、存储过程介绍
什么是存储过程:
- MySQL 5.0 版本开始支持存储过程。
- 简单的说,存储过程就是一组SQL语句集,功能强大,可以实现一些比较复杂的逻辑功能,类似于JAVA语言中的方法;
- 存储过就是数据库 SQL 语言层面的代码封装与重用。
特性:
- 有输入输出参数,可以声明变量,有if/else, case,while等控制语句,通过编写存储过程,可以实现复杂的逻辑功能;
- 函数的普遍特性:模块化,封装,代码复用;
- 速度快,只有首次执行需经过编译和优化步骤,后续被调用可以直接执行,省去以上步骤;
其实也就是把可以实现某一功能的一堆 SQL 封装起来,等到需要用的时候直接调用即可,大大提高了SQL 的复用。
3.2、入门案例
为了区分普通的 SQL ,我们需要自定义 SQL 的结束符。下面我们看看存储过程的基本语法:
delimiter 自定义结束符号
create procedure 储存名([ in ,out ,inout ] 参数名 数据类形...)
begin
sql语句
end 自定义的结束符号
delimiter ; -- 恢复为原本的结束符 ';'自定义存储过程:
-- 自定义存储过程
DELIMITER $$
CREATE PROCEDURE func01()
BEGIN
SELECT * FROM emp;
END $$
DELIMITER ;
-- 调用存储过程
call func01();3.3、存储过程的使用
3.3.1、局部变量的定义
- 局部变量是用户自定义,在 begin/end 快中有效
1)使用 declare 声明局部变量
declare 变量名 变量类型 [default 默认值]测试:
DELIMITER $$
CREATE PROCEDURE func2()
BEGIN
declare tmp int default 1;
set tmp = 2;
SELECT tmp;
end $$
DELIMITER ;
call func2(); -- 22)使用 select into 语句
注意:select into 只能给变量赋值,变量依然需要使用 declare 声明!
语法:
-- 把查询结果赋值给变量
SELECT col1, col2 into var1, var2 from table where condition;注意:返回结果只能是单行结果!
测试:
DELIMITER $$
CREATE PROCEDURE func03()
BEGIN
declare eid int;
declare ename varchar(20);
declare esalary double;
declare dname varchar(20);
SELECT emp_id, emp_name, salary, department
INTO eid,ename,esalary,dname
FROM emp WHERE emp_id=1;
SELECT eid,ename,esalary,dname;
END $$
DELIMITER ;
call func03();注意:局部变量名不能和表字段相同,否则查询为 null (字段类型可以不同)。
3.3.2、用户变量的定义
语法:
@@变量名注意:
- 不需要像局部变量一样提前声明!(要声明也可以 直接 set @变量名 = xxx)
- 生命周期是当前会话
DELIMITER $$
CREATE PROCEDURE func04()
BEGIN
SET @result = 1;
end $$
delimiter ;
call func04();
SELECT @result; -- 必须调用之后才能被初始化赋值 否则为null3.3.3、系统变量
- 系统变量又分为全局变量与会话变量
- 全局变量在 MYSQL 启动的时候由服务器自动将它们初始化为默认值,这些默认值可以通过更改my.ini这个文件来更改。
- 会话变量在每次建立一个新的连接的时候,由MYSQL来初始化。MYSQL会将当前所有全局变量的值复制一份。来做为会话变量。
- 也就是说,如果在建立会话以后,没有手动更改过会话变量与全局变量的值,那所有这些变量的值都是一样的。
- 全局变量与会话变量的区别就在于,对全局变量的修改会影响到整个服务器,但是对会话变量的修改,只会影响到当前的会话(也就是当前的数据库连接)。
- 有些系统变量的值是可以利用语句来动态进行更改的,但是有些系统变量的值却是只读的,对于那些可以更改的系统变量,我们可以利用set语句进行更改。
1. 全局变量
注意:全局变量由系统提供,整个数据库有效。
语法:
@@global.变量名查看全局变量:
show global variables ;查看某个全局变量的值:
SELECT @@global.binlog_format;设置全局变量(两种方式):
set global sort_buffer_size = 40000;
set @@global.sort_buffer_size = 40000;2. 会话变量
语法:
@@session.变量名查看会话变量:
show session variables;查看某个会话变量的值:
SELECT @@session.auto_increment_increment;修改会话变变量的值(两种方法):
set session sort_buffer_size = 50000;
set @@session.sort_buffer_size = 50000;3.3.4、存储过程传参 in
in 表示传入的参数, 可以传入数值或者变量,即使传入变量,并不会更改变量的值,可以内部更改,仅仅作用在函数范围内。
-- in 传参
delimiter $$
create procedure func05(in id int)
begin
select * from emp where emp.emp_id = id;
end $$
delimiter ;
call func05(1); -- 查询 emp_id = 1 的员工信息3.3.5、存储过程传参 out
out 表示从存储过程内部传值给调用者(内部值指的是用户变量),用户变量作用于整个会话,所以调用这个方法时,用户变量就会被初始化并赋值。
delimiter $$
create procedure func06(in id int,out ename varchar(20))
begin
select emp_name into ename from emp where emp_id=id;
end $$
delimiter;
call func06(1,@ename); -- 这里的@name是用户变量所以并不需要声明
select @ename; -- 张晶晶3.3.6、存储过程传参 inout
inout 表示从外部传入的参数经过修改后可以返回的变量,既可以使用传入变量的值也可以修改变量的值(即使函数执行完)。
说人话就是:这个参数既可以当做普通参数用,也可以当做用户变量对它进行赋值
delimiter $$
create procedure func07(inout id int,inout name varchar(20))
begin
update emp set emp_name = name where emp_id = id;
end $$
delimiter ;
set @name = '李大喜';
set @id = 1;
call func07(@id,@name);
select * from emp where emp_id = 1; -- 张晶晶变成了李大喜3.3.7、存储过程传参总结
- in 输入参数,意思说你的参数要传到存过过程的过程里面去,在存储过程中修改该参数的值不能被返回
- out 输出参数:该值可在存储过程内部被改变,并向外输出
- inout 输入输出参数,既能输入一个值又能传出来一个值
3.3.8、存储过程流程控制 - if 语句
DELIMITER $$
CREATE PROCEDURE func08(in id int)
begin
declare num int default 0;
declare result varchar(50);
select count(*) into num from emp;
if id < 1 || id > num
then set result = '超出范围';
else
set result = (select emp_name from emp where emp_id = id);
end if;
select result;
end $$
delimiter ;
call func08(1);3.3.9、存储过程控制流程 - case 语句
需要注意的是 case 语句有两种语法:一种是匹配变量是否等于某个值,一种是匹配变量是否符合某种条件。
匹配条件:
DELIMITER $$
CREATE PROCEDURE func09(in salary int)
BEGIN
DECLARE grade VARCHAR(3);
CASE
WHEN salary > 5000 THEN SET grade = '高';
WHEN salary > 3000 THEN SET grade = '中';
ELSE SET grade = '低';
END CASE;
SELECT grade;
END $$
DELIMITER ;
CALL func09(8000); -- 高匹配值:
delimiter $$
create procedure func10(in grade varchar(1))
begin
declare result varchar(20);
case grade
when 'A' then set result = '90~100';
when 'B' then set result = '80~90';
when 'C' then set result = '70~80';
when 'D' then set result = '60~70';
when 'E' then set result = '0~60';
else set result = '参数错误';
end case;
select result;
end $$
delimiter ;
call func10('B');3.3.10、循环语句和循环控制
先介绍循环控制:
- leave:类似于 break
- iterate:类似于 continue
1. while 循环
语法:
[标签]: while 循环条件 do
循环体
end while [标签];测试:
delimiter $$
create procedure func11()
begin
declare i int default 0;
declare num int default (select count(*) from emp);
while i<num do
select i;
set i = i+1;
end while;
end $$
delimiter ;
call func11();测试结果就是会创建 num 张表,表内就是 i 的值。
2. repeat 循环
语法:
[标签:] repeat
循环体;
until 条件表达式
end repeat 标签;测试:
delimiter $$
create procedure func12()
begin
declare i int default 0;
label: repeat
set i = i+1;
until i > 10
end repeat label;
select '循环结束';
end $$
delimiter ;
call func12();3. loop 循环
语法:
[标签:] loop
循环体
if 条件表达式 then
leave 标签;
endif;
end loop;测试:
delimiter $$
create procedure func13()
begin
declare i int default 0;
label: loop
if i!=5 then
set i = i+1;
else leave label;
end if;
end loop;
end $$
delimiter ;
call func13();3.3.11、存储过程之游标(Cursor)
游标(cursor)是用来存储查询结果集的数据类型 , 在存储过程和函数中可以使用光标对结果集进行循环的处理。光标的使用包括光标的声明、OPEN、FETCH 和 CLOSE.
语法:
-- 声明语法
declare cursor_name cursor for select_statement
-- 打开语法
open cursor_name
-- 取值语法
fetch cursor_name into var_name [, var_name] ...
-- 关闭语法
close cursor_name
测试:
-- 游标
delimiter $$
create procedure func14(in id int)
begin
-- 声明局部变量
declare eid int;
declare ename char(20);
declare esalary decimal(10,2);
-- 声明游标
declare my_cursor cursor for
select emp_id,emp_name,salary
from emp
where emp_id=id;
-- 打开游标
open my_cursor;
-- 通过游标获取每一行
label: loop
fetch my_cursor into eid,ename,esalary;
select eid,ename,esalary;
leave label;
end loop;
-- 关闭游标
close my_cursor;
end $$
delimiter ;
drop procedure func14;
call func14(1);注意:循环体中必须有退出的条件,否则就是死循环!
3.3.12、句柄 handler
4、存储函数(自定义函数)
注意:自定义函数之前必须设置全局变量:
-- 信任函数的创建者
set global log_bin_trust_function_creators=TRUE;
-- 信任函数的创建者
set global log_bin_trust_function_creators=TRUE;
delimiter $$
create function oneToNum(n int) returns int
begin
declare sum int default 0;
while n!=0 do
set sum = sum + n;
set n = n-1;
end while;
return sum;
end $$
delimiter ;
select oneToNum(3); --6注意:自定义函数不能包含递归,递归需要使用专门的语法。
5、触发器
5.1、介绍
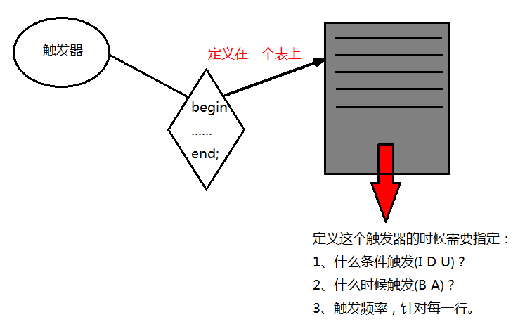
- 触发器,就是一种特殊的存储过程。触发器和存储过程一样是一个能够完成特定功能、存储在数据库服务器上的SQL片段,但是触发器无需调用,当对数据库表中的数据执行DML操作时自动触发这个SQL片段的执行,无需手动条用。
- 在MySQL中,只有执行insert,delete,update操作时才能触发触发器的执行
- 触发器的这种特性可以协助应用在数据库端确保数据的完整性 , 日志记录 , 数据校验等操作 。
- 使用别名 OLD 和 NEW 来引用触发器中发生变化的记录内容,这与其他的数据库是相似的。现在触发器还只支持行级触发,不支持语句级触发。
5.2、触发器的特性
- 什么条件会触发:I、D、U
- 什么时候触发:在增删改前或者后
- 触发频率:针对每一行执行
- 触发器定义在表上,附着在表上
5.3、触发器语法
5.3.1、创建只有一个执行语句方触发器
注意:这里的触发事件只能是 insert、update、delete。
create trigger 触发器名 before|after 触发事件
on 表名 for each row
执行语句;5.3.2、创建有多个执行语句的触发器
create trigger 触发器名 before|after 触发事件
on 表名 for each row
begin
执行语句列表
end;5.4、触发器的使用
5.4.1.创建触发器
-- 触发器
drop trigger if exists trigger_emp;
-- 创建受触发器影响的表格
create table emp_log(
id int primary key auto_increment,
time timestamp,
log_text varchar(255)
);
-- 创建触发器
create trigger trigger_emp
after insert on emp
for each row
insert into emp_log values (NULL,now(),'新的员工注册');
insert into emp values (NULL,'刘海柱',8999,'技术部');
当向 emp 表进行 insert 操作时,就会触发触发器向 emp_log 插入一条日志。
5.4.2、NEW 和 OLD
MySQL 中定义了 NEW 和 OLD,用来表示触发器的所在表中,触发了触发器的那一行数据,来引用触发器中发生变化的记录内容,具体地:
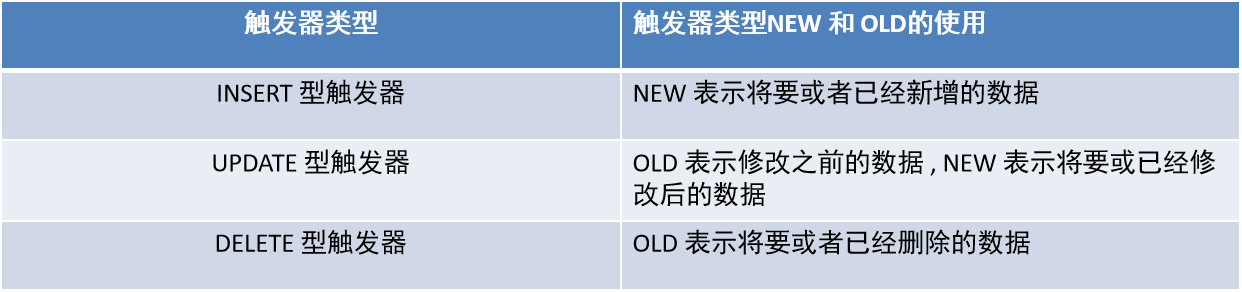
这让我很自然的联想到了 MySQL 的 binlog 功能,我们数仓中使用 MaxWell 来监听 binlog 实现数据同步,但是 binlog 的底层并不是触发器。
语法:
NEW.列名
OLD.列名测试:
-- 不要影响到其它触发器对 emp_log 的操作,比如这里增加了两个字段,
-- 当对该表进行insert 操作时,因为给 emp_log 增加字段之后没有更新触发器的行为
-- 就会导致给 emp 和 emp_log 插入数据是全部失败
alter table emp_log add old varchar(50);
alter table emp_log add new varchar(50);
create trigger trigger_test
after update
on emp for each row
insert into emp_log values (
null,now(),
concat('更新数据'),
concat(OLD.emp_id,OLD.emp_name,OLD.salary,OLD.department),
concat(NEW.emp_id,NEW.emp_name,NEW.salary,NEW.department)
);
update emp set emp_name = '李元芳' where emp_id = 3;
select * from emp_log;5.5、触发器使用的注意事项
- MYSQL中触发器中不能对本表进行 insert ,update ,delete 操作,以免递归循环触发
- 尽量少使用触发器,假设触发器触发每次执行1s,insert table 500条数据,那么就需要触发500次触发器,光是触发器执行的时间就花费了500s,而insert 500条数据一共是1s,那么这个insert的效率就非常低了。
- 触发器是针对每一行的;对增删改非常频繁的表上切记不要使用触发器,因为它会非常消耗资源。