异常反馈
如有问题可通过微信公众号“假装正经的程序员”反馈
为什么要多源
在项目的实际开发过程中通常会有两种常见的使用Flowable的方式,一种是以独立的服务提供工作流的能力,另一种是以Jar包的形式进行内部集成。
这两种方式各有利弊,具体如下:
独立服务形式
优点:
- 独立部署,独立维护,后续的工作流升级不会影响到业务系统;
- 工作流由服务统一管理,便于后期的维护与业务迭代;
缺点:
- 有额外的网络开销,对服务有一定的性能影响;
- 需要额外的资源去部署服务,需要强有力的保障服务的稳定性;
- 需要解决分布式的事务问题;
Jar包形式
优点:
- 没有额外的网络开销,性能更佳;
- 不依赖于第三方服务,稳定性更好;
- 无需额外部署,节约资源;
- 服务内部集成了Jar包,事务问题简单化了;
缺点:
- 后续的版本迭代影响面会辐射到业务;
- Jar集成后,后续工作流的业务迭代相对会更复杂,改动点会更多;
上述两种方案各有利弊,通常情况下独立服务的形式比较适合大公司,他们拥有相对完善的技术体系,能够保障服务的稳定性,同时对于业务的迭代频率也会更高。Jar包的形式比较适合相对规模较小、技术体系相对不够完善的公司,通常以面向B端业务为主,他们无法像C端业务那样保障独立服务的超高稳定性,通过技术手段来解决分布式事务的成本较高。
原因
在独立服务中,多数据源常用于不同业务调用方使用不同数据库的场景,通过不同数据库或同一个数据库不同的schema进行数据隔离,避免相互之间业务干扰。
在Jar包形式中,多数据源是为了将工作流的数据与业务的数据进行隔离,工作流的数据库独立配置,这样做的好处有很多,比如可以防止在业务操作过程中误操作了工作流相关的表、可将业务与工作流数据隔离便于问题排查(毕竟工作流本身的表也不少)等。
多源配置项
#数据源
workflow:
datasource:
url: jdbc:postgresql://XXXXX:5432/a?serverTimezone=UTC&nullCatalogMeansCurrent=true
username: XXXXXX
password: XXXXXX
driverClass: org.postgresql.Driver
workflow2:
datasource:
url: jdbc:postgresql://XXXX:5432/b?serverTimezone=UTC&nullCatalogMeansCurrent=true
username: XXXXXX
password: XXXXXX
driverClass: org.postgresql.Driver构建多源Bean
@Configuration
public class DataSourceConfig {
@Bean(name = "workflowDataSource")
@Qualifier("workflowDataSource")
@Primary
@ConfigurationProperties(prefix = "workflow.datasource")
public DataSource dataSource() {
DriverManagerDataSource dataSource = new DriverManagerDataSource();
return dataSource;
}
@Bean(name = "workflowDataSource2")
@Qualifier("workflowDataSource2")
@ConfigurationProperties(prefix = "workflow2.datasource")
public DataSource secDataSource() {
DriverManagerDataSource dataSource = new DriverManagerDataSource();
return dataSource;
}
}自定义引擎配置以及指定Schema
@Slf4j
@Component
public class CustomEngineConfigurator implements EngineConfigurator {
@Autowired
@Qualifier("workflowDataSource")
private DataSource workflowDataSource;
public void beforeInit(AbstractEngineConfiguration engineConfiguration) {
engineConfiguration.setDatabaseSchema("workflow");
engineConfiguration.setDataSource(workflowDataSource);
}
@Override
public void configure(AbstractEngineConfiguration engineConfiguration) {
}
@Override
public int getPriority() {
return 600000;
}
}Flowable设置引擎配置
@Configuration
public class FlowableConfig implements EngineConfigurationConfigurer<SpringAppEngineConfiguration>{
@Autowired
private CustomEngineConfigurator customEngineConfigurator;
@Override
public void configure(SpringAppEngineConfiguration engineConfiguration) {
engineConfiguration.addConfigurator(customEngineConfigurator);
}
}注意点
JDBC上设置schema无效
jdbc:postgresql://hostname:port/database?currentSchema=your_schema网上很多说可以通过“?currentSchema=your_schema”来修改schema,这方案在Flowable上行不通的,为什么呢?我们来看源码

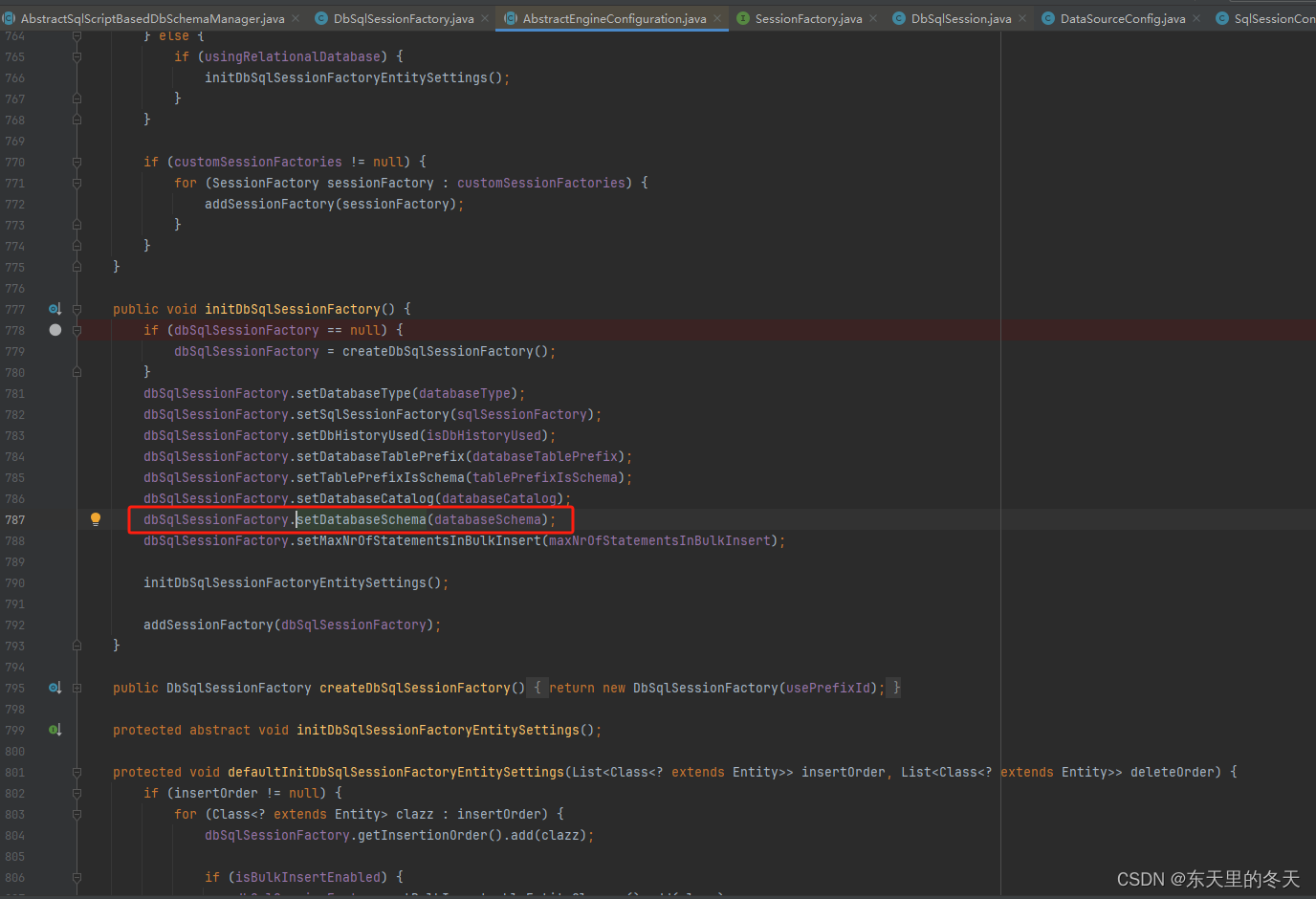
原因
这儿就是为什么在配置中设置flowable.database-schema可以修改schema的原因
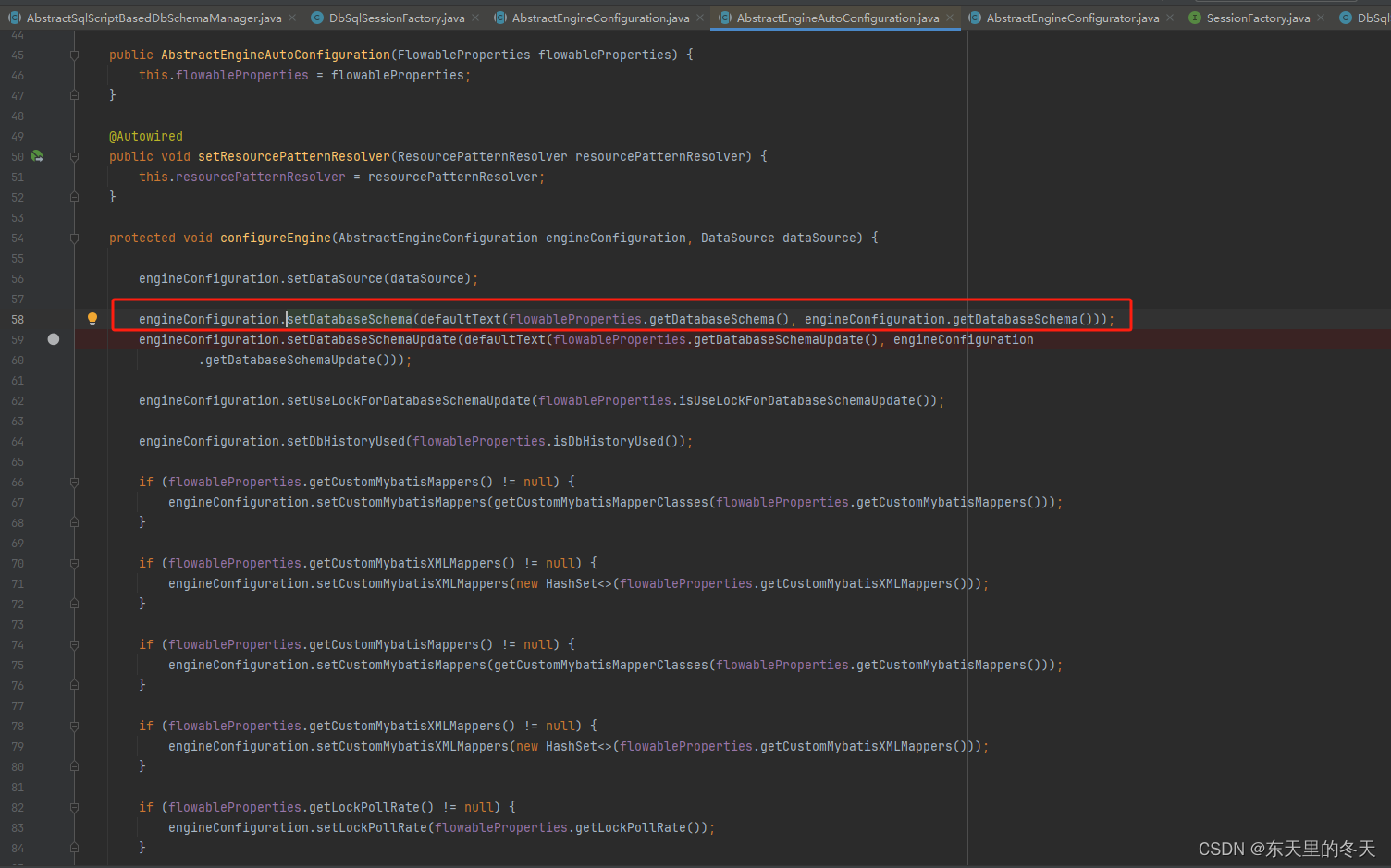
DbSqlSessionFactory是flowable包下的,它的schema有两个来源,一个是配置项,另一个是AbstractEngineConfiguration的schema,因此通过上述jdbc的设置是无效的;
JDBC上设置connectionMetadataDefaultSchema无效
jdbc:postgresql://XXXX/gmpcloud?serverTimezone=UTC&nullCatalogMeansCurrent=true&connectionMetadataDefaultSchema=workflow从源码上大致看来可以通过connectionMetadataDefaultSchema来设置schema
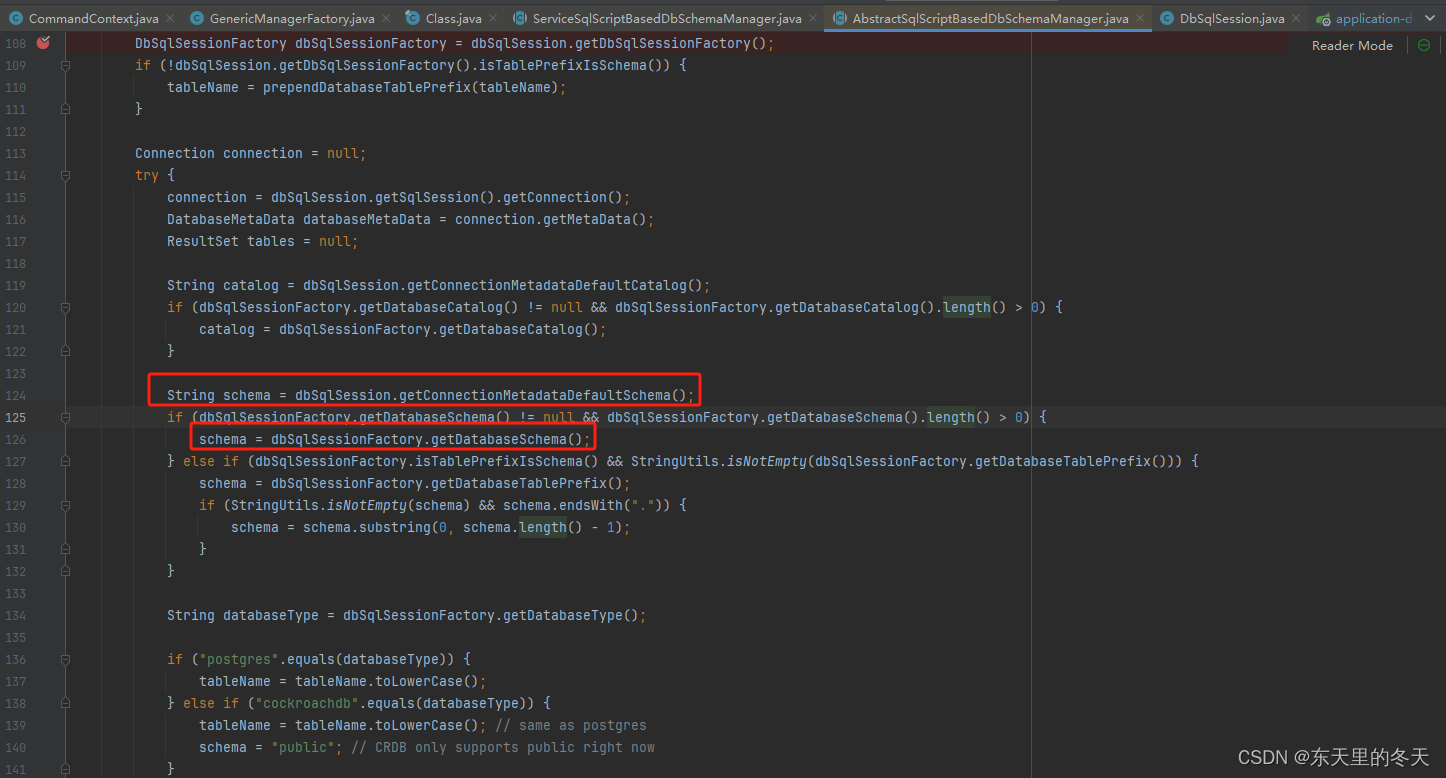
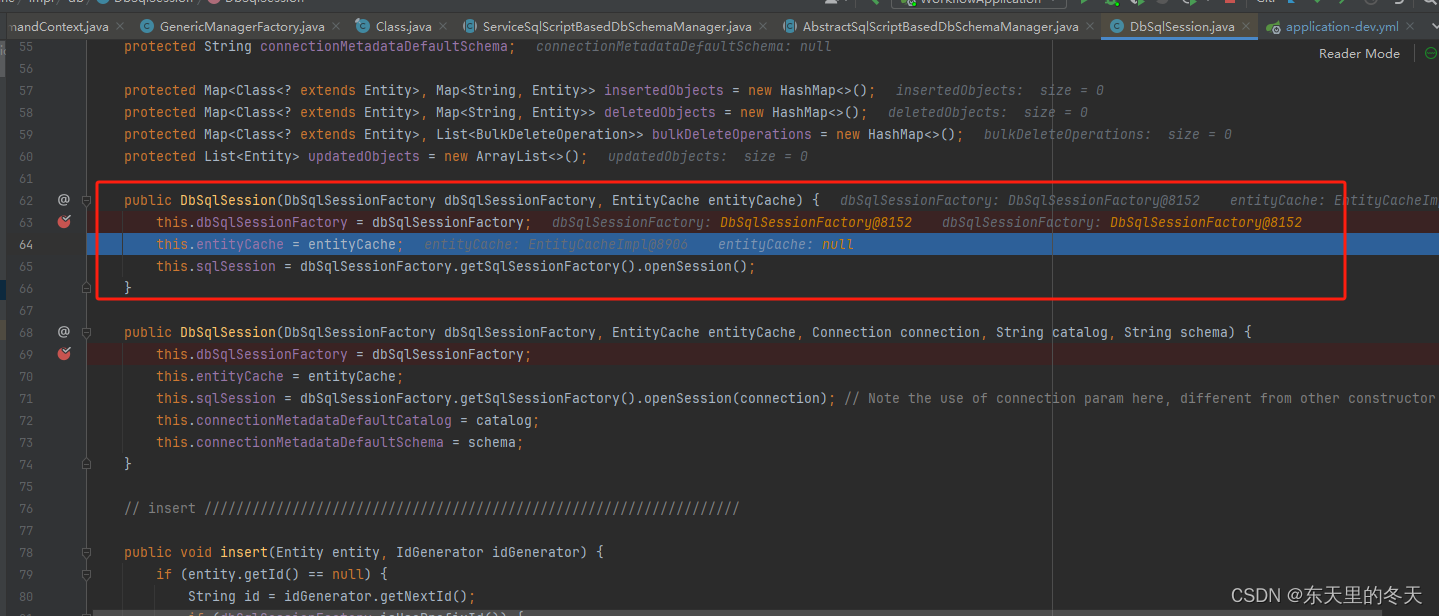
原因
但是追踪代码会发现DbSqlSession的初始化走的是上面一个方法,不会设置connectionMetadataDefaultSchema属性,因此不会有值,不会生效
SpringAppEngineConfiguration
实现的是SpringAppEngineConfiguration而非SpringProcessEngineConfiguration等其他引擎配置,具体区别后续会专门讲






![P8805 [蓝桥杯 2022 国 B] 机房](https://img-blog.csdnimg.cn/direct/b377f531555a497a9f0c96be83937da7.png)