讲transformer的文章已经铺天盖地了,但是大部分都是从原理的角度出发的文章,原理与实现之间的这部分讲解的较少,想要了解实现细节,还是要去看代码才行。记录一下自己学习过程中遇见的细节问题和实现问题。
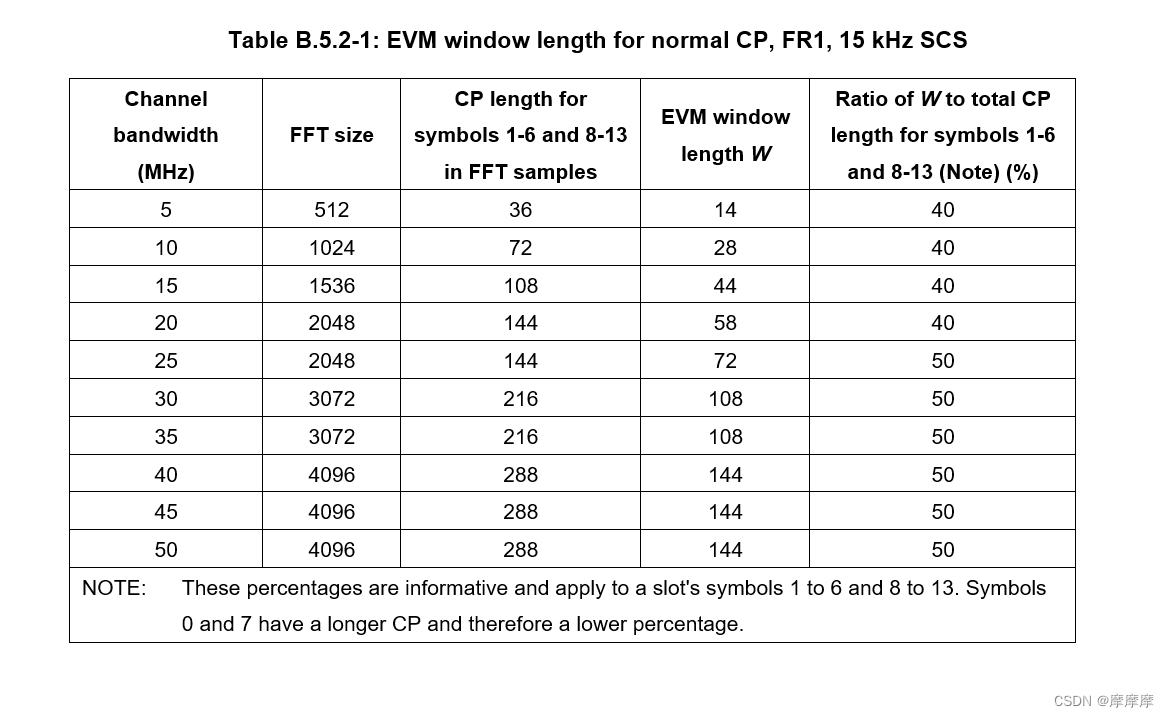
Transformer整体架构

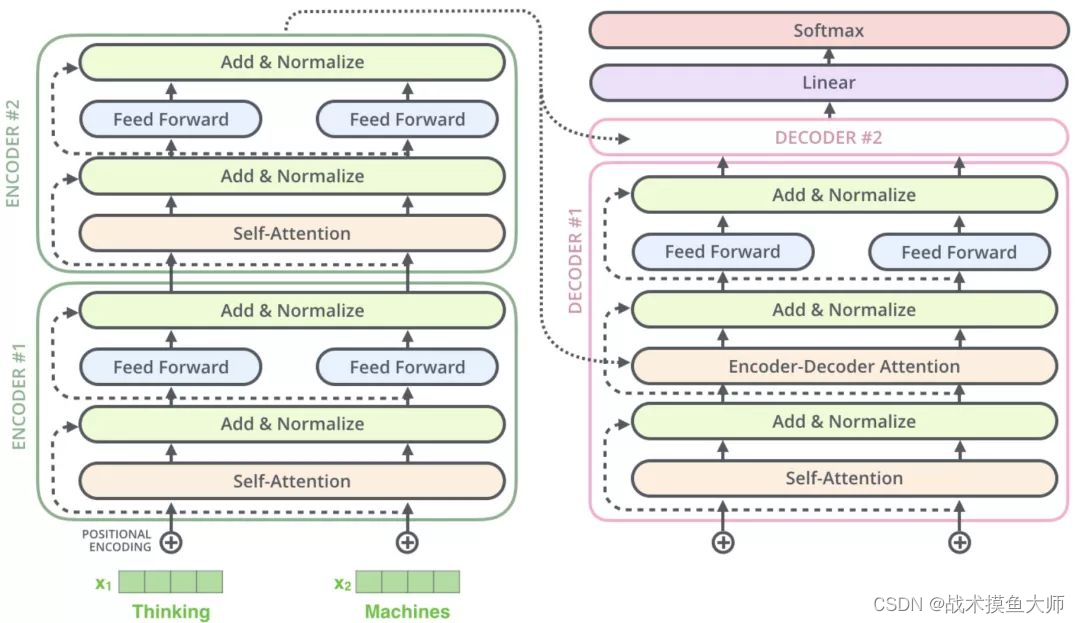
图片来源:文章
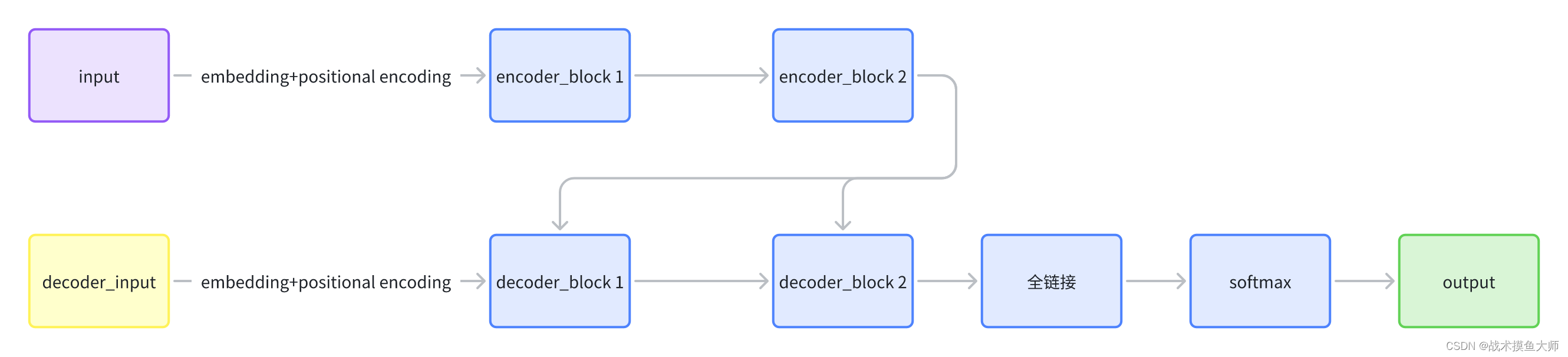
- 这里的decoder input在训练时是直接将期望输出进行embedding作为输入,在推理时是将上一层decoder的输出作为输入。
- encoder的输出在decoder中起作用的地方是在encoder-decoder attention部分
输入
transformer是一次性输入所有的token,不是一个encoder接受一个token。
整个句子经过embedding和positional,变成一个大的向量。
embedding的维度很大程度上影响计算量的大小,而且embedding的方法有很多例如one-hot独热码。
positional encoding位置编码方式
位置编码信息,这部分只会出现在直接接受input的编码器前,用于为词嵌入添加单词位置信息
添加位置信息的方法有两种:绝对位置编码,相对位置编码。
class PositionalEncoding(nn.Module):
"""
compute sinusoid encoding.
"""
def __init__(self, d_model, max_len, device):
"""
constructor of sinusoid encoding class
:param d_model: dimension of model
:param max_len: max sequence length
:param device: hardware device setting
"""
super(PositionalEncoding, self).__init__()
# same size with input matrix (for adding with input matrix)
self.encoding = torch.zeros(max_len, d_model, device=device)
self.encoding.requires_grad = False # we don't need to compute gradient
pos = torch.arange(0, max_len, device=device)
pos = pos.float().unsqueeze(dim=1)
# 1D => 2D unsqueeze to represent word's position
_2i = torch.arange(0, d_model, step=2, device=device).float()
# 'i' means index of d_model (e.g. embedding size = 50, 'i' = [0,50])
# "step=2" means 'i' multiplied with two (same with 2 * i)
self.encoding[:, 0::2] = torch.sin(pos / (10000 ** (_2i / d_model)))
self.encoding[:, 1::2] = torch.cos(pos / (10000 ** (_2i / d_model)))
# compute positional encoding to consider positional information of words
def forward(self, x):
# self.encoding
# [max_len = 512, d_model = 512]
batch_size, seq_len = x.size()
# [batch_size = 128, seq_len = 30]
return self.encoding[:seq_len, :]
# [seq_len = 30, d_model = 512]
# it will add with tok_emb : [128, 30, 512]
MHA多头注意力机制实现
自注意力机制的目的是计算出多个矩阵的关联性,并根据根据该关联性得到一个对该矩阵本身的编码。
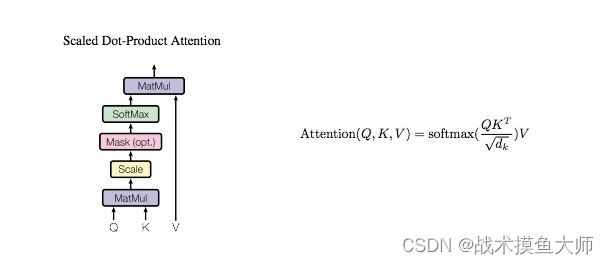
假设输入句子长度为max_len,单词token的尺寸为d_model=
d
k
d_k
dk
注意力的计算公式为:
A
t
t
e
n
t
i
o
n
(
X
i
)
=
∑
j
=
0
n
s
o
f
t
m
a
x
(
Q
i
∗
K
j
d
k
)
V
j
Attention(X_i) = \sum_{j=0}^{n} softmax(\frac{Q_i*K_j}{\sqrt{d_k}})V_j
Attention(Xi)=j=0∑nsoftmax(dkQi∗Kj)Vj
三个向量Q,K,V分别是:
- Q向量: Query查询向量, Q = W Q X Q=W^Q X Q=WQX
- K向量: Key键向量, K = W K X K=W^K X K=WKX
- V向量: Value值向量, V = W V X V=W^V X V=WVX
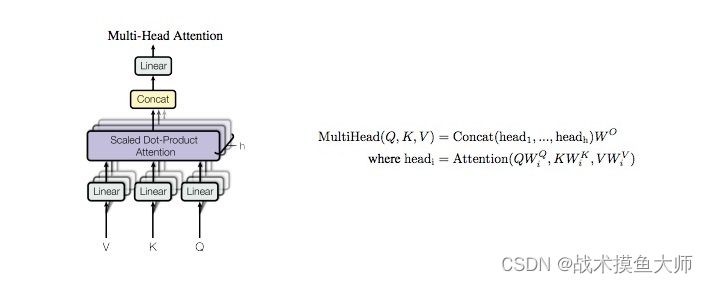
多头注意力机制相较于自注意力机制,区别在于原本只需要一个Q, K,V,现在是多个Q,K,V,对应也有多个 W Q , W Q , W V W^Q,W^Q,W^V WQ,WQ,WV参数矩阵,得到 [ Q i , 1 , Q i , 2 ] [Q^{i,1},Q^{i,2}] [Qi,1,Qi,2],两套QKV计算出两套Attention[以Z矩阵代替]: Z 1 , Z 2 Z_1,Z_2 Z1,Z2,再乘以一个矩阵 W W W计算出最后的矩阵 Z = W O ∗ [ Z 1 , Z 2 ] T Z=W^O*[Z_1,Z_2]^T Z=WO∗[Z1,Z2]T
以上是最原始的MHA实现,后续不同的模型有些许改动。
最原始的Transformer不支持动态长度,max_len的大小就是最大长度的大小,小于该长度时补0,大于该长度时裁剪,后续还有一些针对这个问题的改进自行搜索。
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_head):
super(MultiHeadAttention, self).__init__()
self.n_head = n_head
self.attention = ScaleDotProductAttention()
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.w_concat = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask=None):
# 1. dot product with weight matrices
q, k, v = self.w_q(q), self.w_k(k), self.w_v(v)
# 2. split tensor by number of heads
q, k, v = self.split(q), self.split(k), self.split(v)
# 3. do scale dot product to compute similarity
out, attention = self.attention(q, k, v, mask=mask)
# 4. concat and pass to linear layer
out = self.concat(out)
out = self.w_concat(out)
# 5. visualize attention map
# TODO : we should implement visualization
return out
def split(self, tensor):
"""
split tensor by number of head
:param tensor: [batch_size, length, d_model]
:return: [batch_size, head, length, d_tensor]
"""
batch_size, length, d_model = tensor.size()
d_tensor = d_model // self.n_head
tensor = tensor.view(batch_size, length, self.n_head, d_tensor).transpose(1, 2)
# it is similar with group convolution (split by number of heads)
return tensor
def concat(self, tensor):
"""
inverse function of self.split(tensor : torch.Tensor)
:param tensor: [batch_size, head, length, d_tensor]
:return: [batch_size, length, d_model]
"""
batch_size, head, length, d_tensor = tensor.size()
d_model = head * d_tensor
tensor = tensor.transpose(1, 2).contiguous().view(batch_size, length, d_model)
return tensor
class ScaleDotProductAttention(nn.Module):
"""
compute scale dot product attention
Query : given sentence that we focused on (decoder)
Key : every sentence to check relationship with Qeury(encoder)
Value : every sentence same with Key (encoder)
"""
def __init__(self):
super(ScaleDotProductAttention, self).__init__()
self.softmax = nn.Softmax(dim=-1)
def forward(self, q, k, v, mask=None, e=1e-12):
# input is 4 dimension tensor
# [batch_size, head, length, d_tensor]
batch_size, head, length, d_tensor = k.size()
# 1. dot product Query with Key^T to compute similarity
k_t = k.transpose(2, 3) # transpose
score = (q @ k_t) / math.sqrt(d_tensor) # scaled dot product
# 2. apply masking (opt)
if mask is not None:
score = score.masked_fill(mask == 0, -10000)
# 3. pass them softmax to make [0, 1] range
score = self.softmax(score)
# 4. multiply with Value
v = score @ v
return v, score
Encoder & Decoder
Encoder:
class EncoderLayer(nn.Module):
def __init__(self, d_model, ffn_hidden, n_head, drop_prob):
super(EncoderLayer, self).__init__()
self.attention = MultiHeadAttention(d_model=d_model, n_head=n_head) # 多头注意力机制
self.norm1 = LayerNorm(d_model=d_model) # 层归一化
self.dropout1 = nn.Dropout(p=drop_prob)
self.ffn = PositionwiseFeedForward(d_model=d_model, hidden=ffn_hidden, drop_prob=drop_prob) # FFN网络
self.norm2 = LayerNorm(d_model=d_model)
self.dropout2 = nn.Dropout(p=drop_prob)
def forward(self, x, src_mask):
# 1. compute self attention
_x = x
x = self.attention(q=x, k=x, v=x, mask=src_mask)
# 2. add and norm
x = self.dropout1(x)
x = self.norm1(x + _x)
# 3. positionwise feed forward network
_x = x
x = self.ffn(x)
# 4. add and norm
x = self.dropout2(x)
x = self.norm2(x + _x)
return x
class Encoder(nn.Module):
def __init__(self, enc_voc_size, max_len, d_model, ffn_hidden, n_head, n_layers, drop_prob, device):
super().__init__()
self.emb = TransformerEmbedding(d_model=d_model,
max_len=max_len,
vocab_size=enc_voc_size,
drop_prob=drop_prob,
device=device)
self.layers = nn.ModuleList([EncoderLayer(d_model=d_model,
ffn_hidden=ffn_hidden,
n_head=n_head,
drop_prob=drop_prob)
for _ in range(n_layers)])
def forward(self, x, src_mask):
x = self.emb(x)
for layer in self.layers:
x = layer(x, src_mask)
return x
Decoder
decoder中有trg_mask,trg_mask是因为要避免后面的token对当下token生成的影响,所以使用mask来避免,在大模型中根据mask的不同,可以分为不同的技术路线。
class DecoderLayer(nn.Module):
def __init__(self, d_model, ffn_hidden, n_head, drop_prob):
super(DecoderLayer, self).__init__()
self.self_attention = MultiHeadAttention(d_model=d_model, n_head=n_head)
self.norm1 = LayerNorm(d_model=d_model)
self.dropout1 = nn.Dropout(p=drop_prob)
self.enc_dec_attention = MultiHeadAttention(d_model=d_model, n_head=n_head) # encoder-decoder注意力
self.norm2 = LayerNorm(d_model=d_model)
self.dropout2 = nn.Dropout(p=drop_prob)
self.ffn = PositionwiseFeedForward(d_model=d_model, hidden=ffn_hidden, drop_prob=drop_prob)
self.norm3 = LayerNorm(d_model=d_model)
self.dropout3 = nn.Dropout(p=drop_prob)
def forward(self, dec, enc, trg_mask, src_mask):
# Decoder的输入:
#
# 1. compute self attention
_x = dec
x = self.self_attention(q=dec, k=dec, v=dec, mask=trg_mask)
# 2. add and norm
x = self.dropout1(x)
x = self.norm1(x + _x)
if enc is not None:
# 3. compute encoder - decoder attention
_x = x
x = self.enc_dec_attention(q=x, k=enc, v=enc, mask=src_mask)
# 4. add and norm
x = self.dropout2(x)
x = self.norm2(x + _x)
# 5. positionwise feed forward network
_x = x
x = self.ffn(x)
# 6. add and norm
x = self.dropout3(x)
x = self.norm3(x + _x)
return x
class Decoder(nn.Module):
def __init__(self, dec_voc_size, max_len, d_model, ffn_hidden, n_head, n_layers, drop_prob, device):
super().__init__()
self.emb = TransformerEmbedding(d_model=d_model,
drop_prob=drop_prob,
max_len=max_len,
vocab_size=dec_voc_size,
device=device)
self.layers = nn.ModuleList([DecoderLayer(d_model=d_model,
ffn_hidden=ffn_hidden,
n_head=n_head,
drop_prob=drop_prob)
for _ in range(n_layers)])
self.linear = nn.Linear(d_model, dec_voc_size)
def forward(self, trg, src, trg_mask, src_mask):
trg = self.emb(trg) # 在训练是trg输入是目标输出序列,在推理时是上一次decoder的输出token,对于第一个token的预测,是输入</S>起始符。
for layer in self.layers:
trg = layer(trg, src, trg_mask, src_mask)
# pass to LM head
output = self.linear(trg)
return output