目录标题
- 1,python统计一段话每个单词出现的次数
- 2,SQL中如何利用replace函数统计给定重复字段在字符串中的出现频率?
- 3,常见的统计分析方法有哪些?拿到数据如何分析
- 4,参数估计和假设检验的联系和区别
- 5,如何用统计学的角度看待新冠疫情?
- 6,方差分析
- 7,商城每天的人流量属于什么分布?泊松分布和二项分布的关系
- 8,各种分布之间的关系
- 9,简述逻辑回归
- 10,解释正态分布
- 11,100个人,初始各有100块,每人每分钟随机给别人1块钱,问最后的分布
- 12,随机误差的分布
- 13,两类错误
- 14,置信区间、置信度
- 15,辛普森悖论的例子
- 16,相关系数
- 17,滴滴出行中,司机端的订单构成是什么样的? 头部优秀司机聚集大量订单,还是订单分布比较发散。
牛客网
1,python统计一段话每个单词出现的次数
sentence = 'XXX XX XXX XX X'
words = sentence.split()
dic = {}
for w in words:
if w in dic:
dic[w] +=1
else:
dic[w] = 1
for w,cnt in dic.items():
print('单词%s出现%d'%(w,cnt))
2,SQL中如何利用replace函数统计给定重复字段在字符串中的出现频率?
出现次数/总字符串长度
# all_string代指完整字符串, target_string指代目标字段
select (length('All_string')-length(replace('All_string','target_string','')))/length('All_string') as p
from table
replace(‘All_string’,‘target_string’,‘’)–将字符串中目标字段替换为空,再计算长度
3,常见的统计分析方法有哪些?拿到数据如何分析
1,描述统计
数据的概括性度量(集中趋势、离散趋势、偏态和峰度等)、数理统计(概率分布等)
图表描述方法就是使用各类图表在不同的维度下描述数据,比如直方图、饼图、雷达图、散点图等等。
而数学描述方法的分析方法更丰富,常有集中趋势分析、离散程度分析、相关分析三种分析方法。
2,推断统计
检验统计量及抽样分布、参数估计、假设检验,以及它们间的联系和区别
重点关注假设检验的思想及使用场景,以及一些重要的概念(第一类和第二类错误、置信区间和置信度)
3,列联分析与独立性检验
4,方差分析
方差分析是通过检验各总体的均值是否相等来判断分类型自变量是否对数值型因变量有影响
5,相关分析与回归分析
相关分析是相关关系,回归分析是因果关系,各自的使用场景
6,主成分分析与因子分析
7,时间序列分析
8,非参数检验
4,参数估计和假设检验的联系和区别
联系:
都是样本估计总体,都是建立在概率基础上的统计,可以相互转换
区别:
1,目的不同:参数估计是用样本统计量估计总体参数的方法;假设检验是先对总体参数提出一个假设,然后利用样本信息去检验这个假设是否成立
2,方法不同:参数估计是以置信区间(大概率)估计总体参数;假设检验是利用小概率事件是否发生来判断假设是否成立
5,如何用统计学的角度看待新冠疫情?
1,新冠病毒潜伏期(统计学知识点:数据分布)
疾病的潜伏期通常可以用对数正态分布来近似,我们现阶段采取的隔离措施是将一般潜伏期设定为14天内,但是在后续的病例中我们发现个别患者的潜伏期长达24天,并不是病毒发生了变异,而是新冠病毒的潜伏期实际呈右偏状态,属于长尾分布,较长潜伏期的病例并非不会出现,而是概率很小。
2,新冠病毒传播(统计学知识点:随机过程)
病毒传播实际上是一个随机事件,这一过程可以用随机微分方程来进行模拟,比如SEIR模型。
(1)易感状态S (Susceptible)∶表示潜在的可感染个体。在以往的一些文章中,会有学者将S设置为一个地区的总人口数,导致模型中的感染人数预测结果偏高,这是因为实际上只有有机会接触到感染者的个体才属于易感人群,因此易感状态个体的数量最好由实际数据去拟合。
(2)潜伏状态E(Exposed)∶已被感染但尚未表现出感染症状的个体。
(3)感染状态I(Infected)∶已有感染症状并且可以将疾病传染给其他人的个体。
(4)移除状态R(Removed)∶已经治愈并获得免疫力或已经死亡等不会再被传染的个体。记N为人群中个体的总数量,则有N = S+E+Ⅰ+R。
3,新冠患者诊断(统计学知识点:模型评价)
各种检测手段和医生的诊断结合起来类似一个判别模型,患者的各项指标输入到这个模型得出最终的分类结果,患者的实际患病情况和医生的诊断结果共同构成混淆矩阵,当误诊率越低,说明当前的模型(诊断方法)越好。
4,疫情分析观测指标(统计学知识点:基本统计指标)
感染率=感染人数/总人口数
病死率=因某种病死亡人数/患病人数
死亡率=因某种疾病死亡人数/总人口数=感染率*病死率
6,方差分析
研究内容:连续型因变量与类别型自变量的关系,当自变量的因子中包含等于或超过三个类别情况下,检验其各类别间平均数是否相等的统计模式
分类:依照因子数量而可分为单因子方差分析、双因子方差分析、多因子方差分析三大类
7,商城每天的人流量属于什么分布?泊松分布和二项分布的关系
1,泊松分布。泊松分布是指某段连续的时间内某件事情发⽣的次数
2,泊松分布是⼆项分布的近似,当⼆项分布的p很⼩,重复试验次数n很⼤时,两者分布接近。
如果把一段时间分割成⽆数的⼩份,那么每⼀小段时间内发生的事件都是独立的,在⼀个极小的时间内,⼈们进出的概率为p。那么在一天内,就有n次发⽣⼈们进出这个事件。⽽当n很⼤,p很⼩,二项分布计算概率的公式会趋向于泊松分布。
8,各种分布之间的关系
二项分布的极限是泊松分布,几何分布的极限是指数分布。由正态分布可推导出卡方分布、t分布、f分布
9,简述逻辑回归
用于二分类问题,logsistic函数+回归模型。Sigmoid 函数是一个S形曲线,可以将任意值映射到介于0到1之间的值,然后使用阈值分类器转化为0或者1,最终得到离散结果
10,解释正态分布
对于成绩、身高等,当数量足够大时,总体都是服从正态分布的,符合大部分在中间,只有极少数分布在极大值或者极小值,画在图中是一个钟型的分布。
正态分布是生活中最常见的分布,因为根据中心极限定理,不管总体的分布是什么,从均值为a,方差为b的任意一个总体中抽取样本量为n的样本,当n充分大时,样本均值的抽样分布近似服从均值为a,方差为b/n的正态分布
11,100个人,初始各有100块,每人每分钟随机给别人1块钱,问最后的分布
每个人的条件完全相同时:均匀分布。因为在每个人发钱和得钱的概率及金额完全相等的情况下,最终的结果将是大家的财富值一样。(完全公平情况)
每个人之间并非独立时:正态分布。根据中心极限定理说明,在适当的条件下,大量相互独立随机变量的均值经适当标准化后依分布收敛于正态分布。
幂律分布:在每个人发钱和得钱的概率及金额不等时,最终的财富分配是少数人掌握社会中大量的财富。(类似于现实生活中的社会财富分配)
12,随机误差的分布
正态分布
13,两类错误
第一类错误α叫弃真错误或显著性水平,即原假设为真时却被我们拒绝的概率;第二类错误β叫采伪错误,即原假设为伪我们没有拒绝的概率。在一定样本量的情况下,减小一类错误必然会增大另一类错误,在实践中我们一般会优先控制第一类错误,因为原假设是非常明确的
14,置信区间、置信度
不能简单给出一个估计值,还需要给出一个可信度及在此置信度下对未知参数进行估计的置信区间
经过多次抽样(一次抽样有多个数据,一次抽样构建一个置信区间),重复构建多次的置信区间中覆盖总体参数真值的次数所占比例为置信度,也称为置信水平或置信系数。置信度通常有90%、95%和99%,由于95%的置信度计算出来的置信区间具有较高的可信度,而且波动幅度相对不会太大,在区间估计中普遍会将置信度设置为95%。
在此置信度下,再由样本统计量对总体参数进行区间估计得到置信区间。
15,辛普森悖论的例子
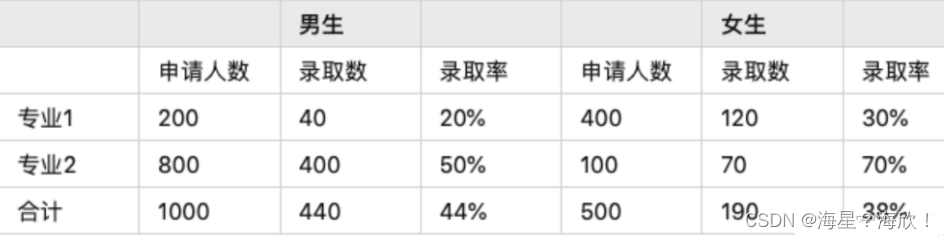
美国加州大学研究生录取数据中,总计来看,男生录取率为44%,女生录取率为35%。虽然总体上,男生录取率高于女生,但是拆开专业后发现,几乎每个专业均是女生的录取率更高。
造成原因:男女生在专业上的分布不一样,男生人数主要集中在录取率较高的专业,女生主人数要集中在录取率较低的专业,这样整体看来,就是女生录取率更低了。
定义:⾟普森悖论指在某个条件下的两组数据,分别讨论时都会满⾜某种性质,可是⼀旦合并考虑却可能导致相反的结论。
如何避免:需要选择将数据分组or将 它们聚合在⼀起。我们就要思考因果关系:数据如何⽣成,基于此,哪些因素会影响我们未展示的结果?
本例中,性别会导致兴趣的不同,而兴趣会决定专业的不同。所以专业因素不可忽略,应该选择拆分专业去观察,操作是控制男女在专业上人数是相同的,这样更有利于判断因果关系
16,相关系数
协方差的大小受变量的相关程度及变量的方差影响,并不能真实反映两个变量的相关程度,而统计学家皮尔逊为了充分反映变量之间线性相关程度引入了相关系数。
相关系数在协方差基础上进行了标准化,消除了两个变量变化幅度的影响,能够充分反应两个变量的相关关系。
范围是[-1,1]。相关系数越趋近于0,表示两个变量相关程度越弱。相关系数越接近于1,两个变量的正相关程度越高。相关系数越接近于-1,两个变量的负相关程度越高。
17,滴滴出行中,司机端的订单构成是什么样的? 头部优秀司机聚集大量订单,还是订单分布比较发散。
在较健康的供给端体系中,司机端的订单构成应为倒三角或者菱形分布,即头部和腰部司机的订单较多,尾部的订单较少;而在初期时则是头部效应明显,订单集中在头部,后期随着司机和订单量的增多,不可能由头部司机撑起大部分订单的。