25. Plug-and-Play: Diffusion Features for Text-Driven Image-to-Image Translation
该文提出一种文本驱动的图像转换方法,输入一张图像和一个目标文本描述,按照文本描述对输入图像进行转换,得到目标图像。图像转换任务其实本质上属于图像编辑任务的一种,在保留输入图像原有的姿态、布局不变的情况下,修改图像的背景、纹理、材质等内容,而不能改变图像的内容、语义、视角等。本文提出在解码器阶段的特征图能够保留局部语义信息,并且不会受到对象外观的影响,而自注意力层中的相似性图能够保留布局和形状的细节。作者对输入图像进行重建,并将重建过程中的特征图和自注意力层中的相似性图抽取出来,注入到目标图像的生成过程中,从而实现对生成图像的布局、形状的约束和引导。文本的特征还是通过交叉注意力机制引入,来实现对目标图像的修改。
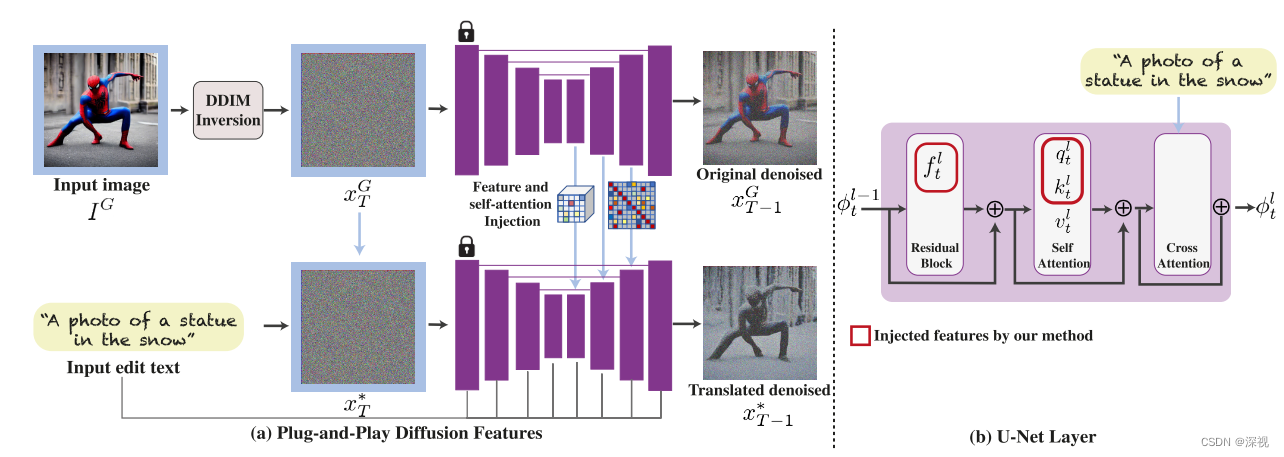
首先,输入图像
I
G
I^G
IG经过一个DDIM的扩散过程得到噪声图
x
T
G
x^G_T
xTG,将
x
T
G
x^G_T
xTG输入到一个预训练好的LDM中得到去噪重建的图像
x
T
−
1
G
x^G_{T-1}
xT−1G。在解码过程中,将特征图
f
t
l
f^l_t
ftl和自注意力层中的相似性图
A
t
l
=
S
o
f
t
m
a
x
(
q
t
l
k
t
l
T
)
A_t^l=\mathrm{Softmax}(\boldsymbol{q}_t^l{\boldsymbol{k}_t^l}^T)
Atl=Softmax(qtlktlT)提取出来。为了展示特征图和相似性图所包含的信息,作者使用PCA提取特征图中前三个主成分,并进行可视化展示,效果如下图所示

可以看到,在较浅的层级中,特征图只保留了非常粗糙的前景物体信息。而在中间层级(layer=4)中,就能观察到不同领域的对象之间共享的局部语义信息,物体中相同的部分对应的颜色也相同(例如人物的头部都是黄绿色,而躯干都是红紫色),即使他们的外观存在很大的差别。在更高的层级中,特征图就包含了更多高频的低级纹理信息。同理,我们再看一下不同层级中自注意力层的相关性图的可视化效果,如下图所示。在较低的层级中,相似性图和图像的语义布局是对齐的,随着层级不断地加深,能够提取到更多的高频信息。

可视化的结果表明了,中层级的特征图保留了局部的语义信息,而相似性图保留了布局和形状信息。作者的想法也非常简单,直接把这些信息注入到目标图像的生成过程中,取代对应位置的特征图和相似性图,从而实现对生成过程的引导。保持生成图像的语义、布局和形状不会发生改变。
可以看到生成过程中,初始的噪声图
x
T
∗
x^*_T
xT∗直接使用原图的扩散结果
X
T
G
X^G_T
XTG,对噪声图使用预训练的LDM进行扩散生成,并将第4层特征图
{
f
t
∗
l
}
\{f_t^{*l}\}
{ft∗l}和自注意力层的相似性图
A
t
l
A_t^l
Atl直接用前面提取得到特征图和相似图替换掉,而文本特征
P
P
P仍通过交叉注意力机制引入,得到生成的结果
z
t
−
1
∗
=
ϵ
^
θ
(
x
t
,
P
,
t
;
f
t
4
,
{
A
t
l
}
)
z_{t-1}^*=\hat{\epsilon}_{\boldsymbol{\theta}}(\boldsymbol{x}_t,P,t;\boldsymbol{f}_t^4,\{\boldsymbol{A}_t^l\})
zt−1∗=ϵ^θ(xt,P,t;ft4,{Atl})为什么选择第4层的特征图而不是选择所有的特征图呢?是因为作者发现,如果全部都用会使得的生成结果保留原有图像的一些纹理和外观信息,只用第4层特征图就能够很好的保留语义信息。此外,如果只注入相似性图而不注入特征图,则会导致引导特征和生成特征之间没有语义关联,从而导致结构上的不对齐,如下图所示

在生成过程中,作者使用两个参数
τ
f
\tau_f
τf和
τ
A
\tau_A
τA分别来控制注入特征图和相似性图的时间步数,当生成步数
t
t
t大于
τ
f
\tau_f
τf和
τ
A
\tau_A
τA,才开始注入特征图或相似性图,整个流程如下图所示

此外,作者还引入了输入图像的文本描述作为负提示(Negative-prompting),作为无分类器的引导来修正预测的噪声
ϵ
\epsilon
ϵ
ϵ
=
w
ϵ
θ
(
x
t
,
P
,
t
)
+
(
1
−
w
)
ϵ
~
\epsilon=w\boldsymbol{\epsilon}_{\theta}(\boldsymbol{x}_{t},P,t)+(1-w)\tilde{\boldsymbol{\epsilon}}
ϵ=wϵθ(xt,P,t)+(1−w)ϵ~其中
ϵ
~
=
α
ϵ
θ
(
x
t
,
∅
,
t
)
+
(
1
−
α
)
ϵ
θ
(
x
t
,
P
n
,
t
)
\tilde{\boldsymbol{\epsilon}}=\alpha\boldsymbol{\epsilon}_\theta(\boldsymbol{x}_t,\varnothing,t)+(1-\alpha)\boldsymbol{\epsilon}_\theta(\boldsymbol{x}_t,P_n,t)
ϵ~=αϵθ(xt,∅,t)+(1−α)ϵθ(xt,Pn,t)
α
\alpha
α和
w
w
w分别来控制负提示的影响和无分类器引导的影响。但作者通过实验发现,这个改进对于缺少纹理的轮廓图像效果更明显,而对于拥有正常外观的引导图片作用较小。本文的转换效果与其他的图像编辑方法对比如下