Day 1
一、选择题

解析:
在数字不会溢出的前提下,对于正数和负数,有:
1)左移n位,相当于操作数乘以2的n次方;
2)右移n位,相当于操作数除以2的n次方。

解析:
int (*p[10])(int*)
(*p[10]):p是一个数组,这个数组的元素是指针;
这些指针指向的是一个函数;
这个函数的参数是 int *,返回值是int。
因此,p是 元素指向函数的指针 的数组 即 元素为函数指针 的数组。
一般我用来分辨这种 就看(*p),p(),p[]这三类——指针,函数,数组。一般来说()和[]优先级先级相同,比*高。
这题先和[]结合,故为数组,然后再分析各自内容



解析:
STL中一级容器是指, 容器元素本身是基本类型, 非组合类型。
set, multiset中元素类型是pair<key_type, key_type>;
map, multimap中元素类型是pair<key_type, value_type>;
STL中的常用容器包括:顺序性容器(vector、deque、list)、关联容器(map、set)、容器适配器(queue、stac)。

二、编程题
1.计算某天是星期几
输入一个年月日,计算出这个日期对应的是星期几

代码:
#include<iostream>
using namespace std;
int main() {
char weekname[][10] = {
"Monday",
"Tuseday",
"Wednesday",
"Thursday",
"Friday",
"Saturday",
"Sunday"
};
int year;
int month;
int day;
cin >> year;
cin >> month;
cin >> day;
if (month == 1 || month == 2) {
month += 12;
year--;
}
int w;
w = (day + 2 * month + 3 * (month + 1) / 5 + year + year / 4 - year / 100 +
year / 400) % 7;
cout << weekname[w] << endl;
}
Day 2
一、选择题
class XA { private: int x; public: XA(int n) {x=n;} } ; class XB :public XA { private: int y; public: XB(int a,int b); };

这句代码是XB类的构造函数的初始化列表部分。它用于初始化XB类的成员变量,并调用基类XA的构造函数。
这里,XB::XB(int a ,int b)是XB类的构造函数的声明,它接受两个整数参数a和b。
后面的:XA(a),y(b)是初始化列表。它用于初始化类的成员变量和调用基类的构造函数。
- XA(a): 这部分调用了基类XA的构造函数,并将参数a传递给它。这是为了确保在XB的构造函数体执行之前,基类XA的部分已经被正确地初始化。
- y(b): 这部分初始化了XB类自己的成员变量y,使用参数b作为初始值。
初始化列表是一个高效且推荐的方式来初始化类的成员变量,因为它可以避免额外的赋值操作,并且对于某些类型(如引用和常量成员)是必需的。

重复多次fclose一个打开过一次的FILE *fp指针会导致未定义行为。
在C语言中,fclose函数用于关闭文件流,释放与之关联的资源。当你调用fclose时,会将文件缓冲区的内容写入到磁盘中,并清空缓冲区。如果你试图再次关闭已经关闭的文件流,那么就会发生未定义行为,因为文件流已经被关闭并且资源已经被释放,再次调用fclose函数就会导致错误的结果。
|


两个考点:
1.构造函数的调用顺序是:基类》对象》派生类,析构顺序相反;
2.构造函数里初始化列表初始化顺序由成员变量的声明顺序决定。

二、编程题
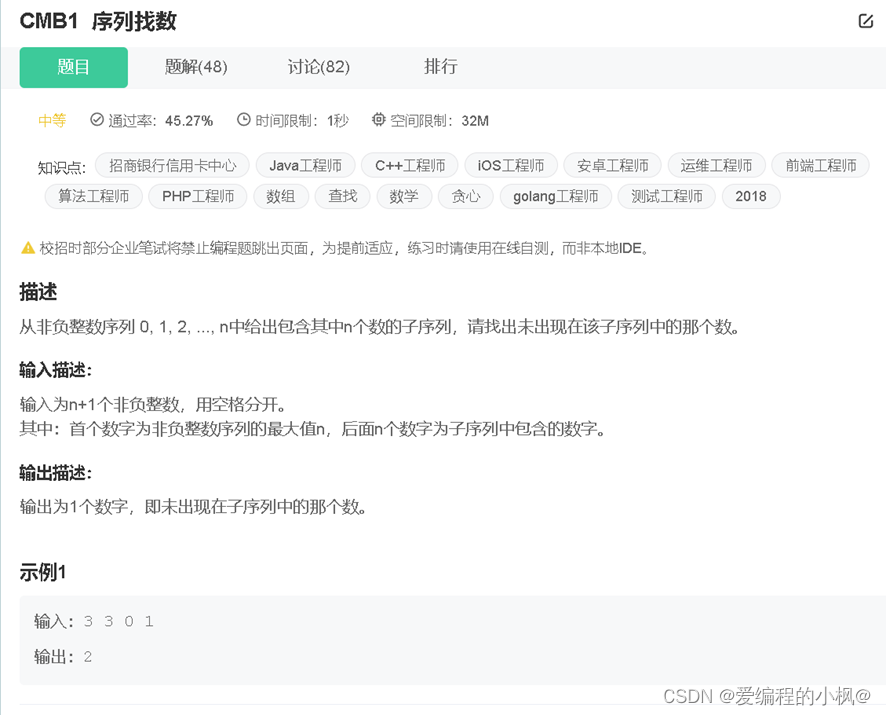
#include<iostream>
#include<algorithm>
#include<stdio.h>
using namespace std;
int main()
{
int nums;
cin>>nums;
int* num = new int[nums];
for (int i = 0; i < nums; ++i)
cin>>num[i];
sort(num, num + nums);
int i = 0;
for (; i < nums; ++i)
{
if (num[i] != i)
break;
}
cout << (i) << endl;
return 0;
}
// 64 位输出请用 printf("%lld")
Day 3
一、选择题


int printf ( const char * format, ... );返回值: 正确返回输出的字符总数,错误返回负值,
与此同时,输入输出流错误标志将被置值,可由指示器ferror来检查输入输出流的错误标志。

在行尾放一个 \ ,编译器会忽略行尾的换行符,起到续行的作用。

逗号表达式优先级最低,从左到右执行,如果逗号左边改变了某些变量的值,右边使用改变后的变量值,整个表达式最终的值为逗号右边的值,-a对a的值没有发生改变,所以a=6,自增自减的优先级高与关系运算符,所以b>a--返回false,c>d返回false,?:组合为如果?前面的表达式为真,则返回?后面的值,为假返回:后面的值,最后返回a>b为false,0。
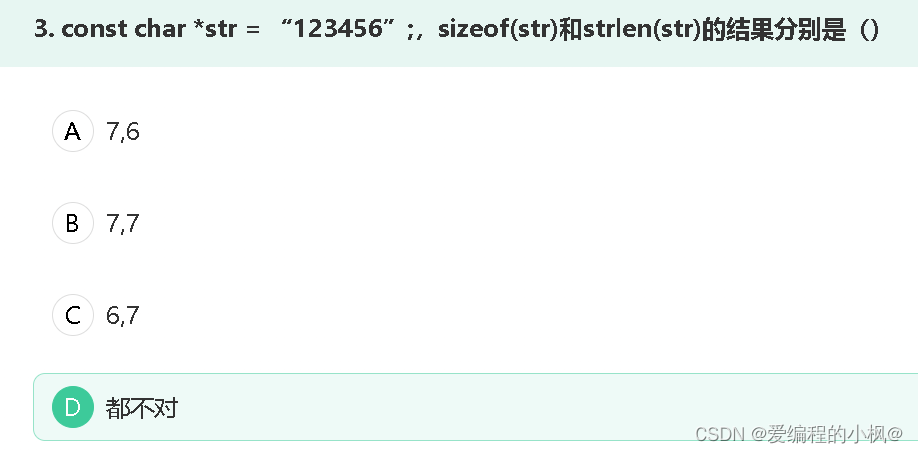
1.这里为指针,那么str存储的是该字符串的地址,所以sizeof(str)则为该字符串的首地址,
如果是64位,地址为8字节(Byte),如果是32位,地址为4字节(Byte)。
2.而strlen(str)就是统计字符串长度,那么就是6。

在什么情况下系统会调用拷贝构造函数:(三种情况)
(1)用类的一个对象去初始化另一个对象时
(2)当函数的形参是类的对象时(也就是值传递时),如果是引用传递则不会调用
(3)当函数的返回值是类的对象或引用时

二、编程题

#include <iostream>
#include<bits/stdc++.h>
using namespace std;
//#include<algorithm> reverse
//2x+1 奇数 n = 2x+1 x = (n - 1)/2
//2x+2 偶数 n = 2x+2 x = (n - 2)/2
int main() {
int n;
cin>>n;
string s="";
while(n)
{
if(n%2==1)//奇数
{
s+='2';
n = (n-1)/2;
}
else//偶数
{
s+='3';
n = (n -2)/2;
}
}
reverse(s.begin(),s.end());
cout<<s<<endl;
}Day 4
一、选择题

1.内联函数的函数体内不能含有复杂的结构控制语句,如switch和while,否则编译器将该函数视同普通函数那样产生函数调用代码。
2.递归函数不能被用来作为内联函数。
3.内联函数一般适合于只有1-5行语句的小函数,对于一个含有很多语句的大函数,没必要使用内联函数来实现。
4.内联函数的定义必须出现在内联函数第一次被调用之前。
5.对内联函数不能进行异常接口声明,就是不能声明可能抛出的异常。
1. 内联函数是通过inline关键字来定义的,它的作用是把函数的代码直接嵌入到调用该函数的地方,而不是通过函数的调用来执行代码。
2. 内联函数的主要优势是可以减少函数调用的开销,从而提高程序的执行效率。但是如果函数体过于庞大,内联可能会导致代码膨胀,增加程序的体积,从而反而降低程序的效率。
3. 内联函数的调用方式和普通函数一样,不同的是编译器不会生成函数调用代码,而是直接拷贝内联函数的代码到调用处。
4. 内联函数适用于一些代码量较小,频繁调用的函数,比如一些简单的getter和setter函数。
5. 在编写内联函数时需要注意,它只是建议编译器将函数呈现为内联形式,而不是强制要求编译器这么做。如果编译器认为内联函数不适合内联,它就会按照普通函数来处理
#define 定义一个预处理宏
#undef 取消宏的定义
#if 编译预处理中的条件命令,相当于C语法中的if语句
#ifdef 判断某个宏是否被定义,若已定义,执行随后的语句
#ifndef 与#ifdef相反,判断某个宏是否未被定义
#elif 若#if, #ifdef, #ifndef或前面的#elif条件不满足,则执行#elif之后的语句,相当于C语法中的else-if(扩展条件)
#else 与#if, #ifdef, #ifndef对应, 若这些条件不满足,则执行#else之后的语句,相当于C语法中的else(扩展条件)
#endif #if, #ifdef, #ifndef这些条件命令的结束标志.
defined 与#if, #elif配合使用,判断某个宏是否被定义
二、编程题
Day 5
一、选择题


A new和delete的释放方法不同.
B 子类重新定义父类虚函数的行为叫做 重写(覆盖)
C C++语言函数可以递归调用但是不能嵌套定义.
D 正确, 在C++语言调用函数中,只能把实参的值传给形参,形参的值不能传给实参.(不考虑引用,指针等情况)

官方解析:正确答案:B
A 选项 static_cast 用于良性转换,一般不会导致意外发生,风险很低。
B 选项 dynamic_cast 借助 RTTI,用于类型安全的向下转型(Downcasting)。
C 选项 const_cast 用于 const 与非 const、volatile 与非 volatile 之间的转换。
D 选项 reinterpret_cast 高度危险的转换,这种转换仅仅是对二进制位的重新解释,不会借助已有的转换规则对数据进行调整,但是可以实现最灵活的 C++ 类型转换。

A:友元函数并不需要通过对象或指针调用,它可以像普通函数一样直接调用。
B:友元函数是独立于类继承机制的,和类是否被继承没有关系。因此,友元函数可以被子类或父类继承。
C:友元函数确实没有 this 指针,因为它不属于类的成员函数,也没有被绑定到任何一个类的对象上。
D:这个说法是错误的。虽然友元函数能够访问类的私有成员,但并没有破坏类的继承性机制。类的派生类仍然可以继承这些私有成员,只是无法在自己的成员函数中访问而已。
二、编程题

#include <iostream>
using namespace std;
int main() {
int n;
cin>>n;
int *num = new int[n];
int f = 0;
int sum = 0;
for(int i = 0;i<n;i++)
{
cin>>num[i];
sum += num[i];
if(num[i] < 0)
{
f++;
sum = 0;
}
}
if(f == n)
{
cout<<num[n-1];
}
else
{
cout<<sum<<endl;
}
return 0;
}
// 64 位输出请用 printf("%lld")标准答案: (连续最大和)
#include<iostream>
using namespace std;
int main(){
int n,*a;
while(cin>>n){
a = new int[n];
for(int i=0;i<n;i++){
cin>>a[i];
}
int sum=a[0],max=a[0];
for(int i=1;i<n;i++){
sum = sum>0? (sum+a[i]): a[i];
if(sum>max){
max = sum;
}
}
cout<<max<<endl;
}
return 0;
}
#include<iostream>
using namespace std;
#include<string>
int main()
{
string a = "11";
//cin >> a;
string b = "10";
//cin >> b;
string res;
int i = a.size() - 1;
int j = b.size() - 1;
int carry = 0;
while (i >= 0 || j >= 0 || carry != 0)
{
int digitA = i >= 0 ? a[i] - '0' : 0;
int digitB = j >= 0 ? b[i] - '0' : 0;
int sum = digitA + digitB + carry;
carry = sum >= 2 ? 1 : 0;
sum = sum >= 2 ? sum - 2 : sum;
res += to_string(sum);
i--;
j--;
}
reverse(res.begin(), res.end());
cout << res << endl;
/*
* 1.字符转整数
* 2.遍历两个字符串,完成进位操作
* 3.整数转换字符串函数to_string
*/
return 0;
}Day 6
一、选择题
不应该说类的大小,具体讲应该是类对象(实例)的大小有关因素:普通成员变量,虚函数、继承;无关因素为:静态成员变量、静态成员函数及普通成员函数。
1、为类的非静态成员数据的类型大小之和.
2.由编译器额外加入的成员变量的大小,用来支持语言的某些特性(如:指向虚函数的指针).
3.为了优化存取效率,进行的边缘调整(字节对齐).
4 与类中的构造函数,析构函数以及其他的成员函数无关
在C++中,每个对象都必须具有非零的大小。即使类A没有显式定义任何成员变量,编译器也会为其分配一个字节的大小,以确保每个对象在内存中都有一个唯一的地址。这个额外的字节被称为“占位符”字节或“填充”字节

print("*")函数调用的返回值是字符串中字符个数,不包含结束标识符`\0’,相当于strlen,即返回值为1,恒成立;而‘0’的asc 码是48,不等于0,也是恒成立,所以选择B

struct 的成员默认是公有的
class 的成员默认是私有的
class继承默认是私有继承
struct 的继承默认是公有的
二、编程题

#include<iostream>
using namespace std;
#include<vector>
#include<unordered_map>
class Solution {
public:
int garbageCollection(vector<string>& garbage, vector<int>& travel)
{
int res = 0;//总时间(包括收集时间和移动时间)
int cur_dis = 0;//车辆当前位置距离起点的移动时间
unordered_map<char, int>distance;//存储每种垃圾类型累计的移动时间
for (int i = 0;i<garbage.size(); i++)
{
res += garbage[i].size();
if (i > 0)//取移动时间,房子序号跟移动时间数组的序号差1
{
cur_dis += travel[i - 1];//加上当前房子的垃圾收集时间
//只有i大于0才累加移动时间
}
for (auto c : garbage[i])//遍历当前房子的垃圾类型
{
distance[c] = cur_dis;//更新移动时间
}
}
for (auto& [k, v] : distance)
{
cout << k << " " << v << endl;
res += v;//计算时间
}
return res;
}
};
int main()
{
vector<string> garbage = { "G","P","GP","GG" };
vector<int> travel = { 2,4,3 };
Solution s;
int time = s.garbageCollection(garbage,travel);
cout << time << endl;
return 0;
}Day 7
一、选择题


数组做函数参数,会退化成指针 故4,4
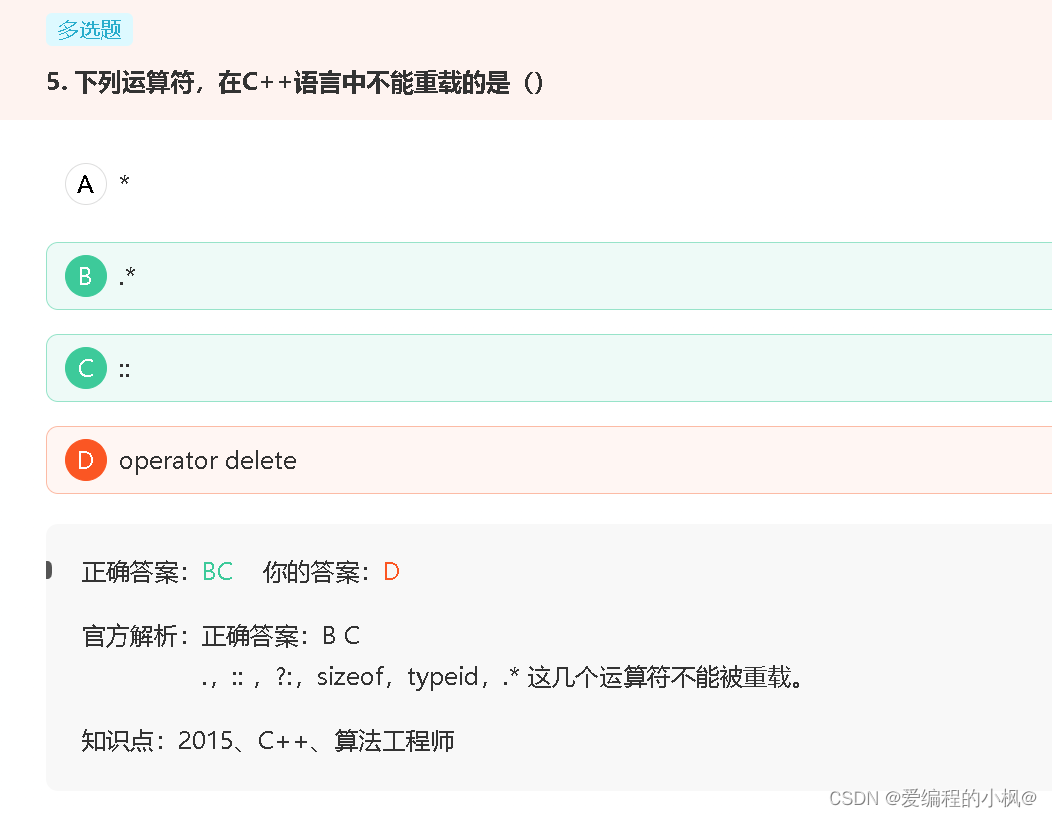
二、编程题

#include<iostream>
using namespace std;
#include<unordered_map>
#include<math.h>
class Sultion
{
unordered_map<int, int>memo;
public:
int minDay(int n)
{
if (n <= 1)
{
return 1;
}
if(memo.contains(n))
{
return memo[n];
}
return memo[n] = min((minDay(n / 2) + n % 2), (minDay(n / 3) + n % 3)) + 1;
}
};
int main()
{
int n;
cin >> n;
Sultion s;
int minDay =s.minDay(n);
cout << minDay << endl;
return 0;
}
大神题解![]() https://leetcode.cn/problems/minimum-number-of-days-to-eat-n-oranges/solutions/2773476/liang-chong-fang-fa-ji-yi-hua-sou-suo-zu-18jv/
https://leetcode.cn/problems/minimum-number-of-days-to-eat-n-oranges/solutions/2773476/liang-chong-fang-fa-ji-yi-hua-sou-suo-zu-18jv/
Day 8
一、选择题

double的范围要比float的范围大,float要比int的范围大
类型转换分两种:
- 自动类型转换(隐式)
- 特点: 代码不需要进行特殊处理,自动完成
- 规则: 数据范围从小到大
- 安全性:安全
- 强制类型转换
- 特点:代码需要进行特殊的格式处理,不能自动完成
- 格式:范围小的类型 范围小的变量名 = (范围小的类型) 原本范围大的数据
- 数据损失,比如3.14(double)转成int,会丢失小数部分
- 安全性:不安全

C语言中以数字1-9开头表示十进制,以0开头表示八进制,以0X开头表示十六进制
Line::Line(Point xp1,Point xp2):p1(xp1),p2(xp2){}
//解释4次的原因:
首先这个方法是Line的构造函数,它有2个参数,类型为Point,(注意:不是引用(Point&),也不是指针(Point*))
其次,冒号后面的叫构造函数的初始化列表,用于初始化成员变量,注意是初始化 知道这两点之后,那么再来说原因:
c++这门语言不像java,如果参数不写成引用(Point&)或者指针(Point*),那么在传递参数的时候会建立一个对象的副本。
Line::Line(Point xp1,Point xp2):p1(xp1),p2(xp2){},
传入xp1时,会去创建一个Point的对象,调用1次Point的拷贝构造,这是第1次,同理xp2,再进行p1(xp1)时,这叫初始化p1,不是定义之后再赋值!这又会调用1次Point的拷贝构造,同理p2(xp2),因此共4次 一般来说这个方法最好这么写Line::Line(const Point& xp1,const Point& xp2):p1(xp1),p2(xp2){},这样就只会调2次了

第一种AI生成解法
class Solution {
public:
int minimumRounds(vector<int>& tasks) {
std::unordered_map<int, int> counts;
for (int task : tasks) {
++counts[task];
}
int totalRounds = 0;
for (const auto& count : counts) {
if (count.second == 1) {
return -1; // 如果有任务数量为1,则无法完成
} else if (count.second % 3 == 0) {
totalRounds += count.second / 3;
} else {
totalRounds += (count.second / 3) + 1;
}
}
return totalRounds;
}
};
第二种大神的解法
https://leetcode.cn/problems/minimum-rounds-to-complete-all-tasks/solutions/1427626/ha-xi-biao-tan-xin-by-endlesscheng-tgtf/
class Solution {
public:
int minimumRounds(vector<int>& tasks) {
unordered_map<int, int> cnt;
for (int t : tasks) {
cnt[t]++;
}
int ans = 0;
for (auto& [_, c] : cnt) {
if (c == 1) {
return -1;
}
ans += (c + 2) / 3;
}
return ans;
}
};持续更新ing!
分享完毕,关注我,带你了解更多的编程知识。
看到这里,不妨点个攒,关注一下吧!

最后,谢谢你的观看!