机器学习实验报告:决策树与随机森林数据分类
实验背景与目的
在机器学习领域,决策树和随机森林是两种常用的分类算法。决策树以其直观的树形结构和易于理解的特点被广泛应用于分类问题。随机森林则是一种集成学习算法,通过构建多个决策树并进行投票,以提高分类的准确性和鲁棒性。本实验的目的在于让学生通过实践,深入理解这两种算法的工作原理,掌握使用Python的sklearn库对数据进行分类的方法,并熟悉数据预处理的相关技术。
数据集
关注公众号:码银学编程,回复:income_classification。
income_classification
实验环境配置
实验在配置较高的个人计算机上进行,具体配置如下:
- 开发工具:PyCharm 2021.3.1
- 操作系统:Windows 11
- 处理器:Intel® Core™ i5-10210U CPU @ 1.60GHz 2.11 GHz
- 内存:16.0 GB (15.8 GB 可用)
- 系统类型:64 位操作系统,基于 x64 的处理器
实验内容与过程
实验内容主要围绕使用决策树和随机森林算法对收入水平数据集income_classification.csv进行分类。具体步骤如下:
实验步骤1:数据载入与展示
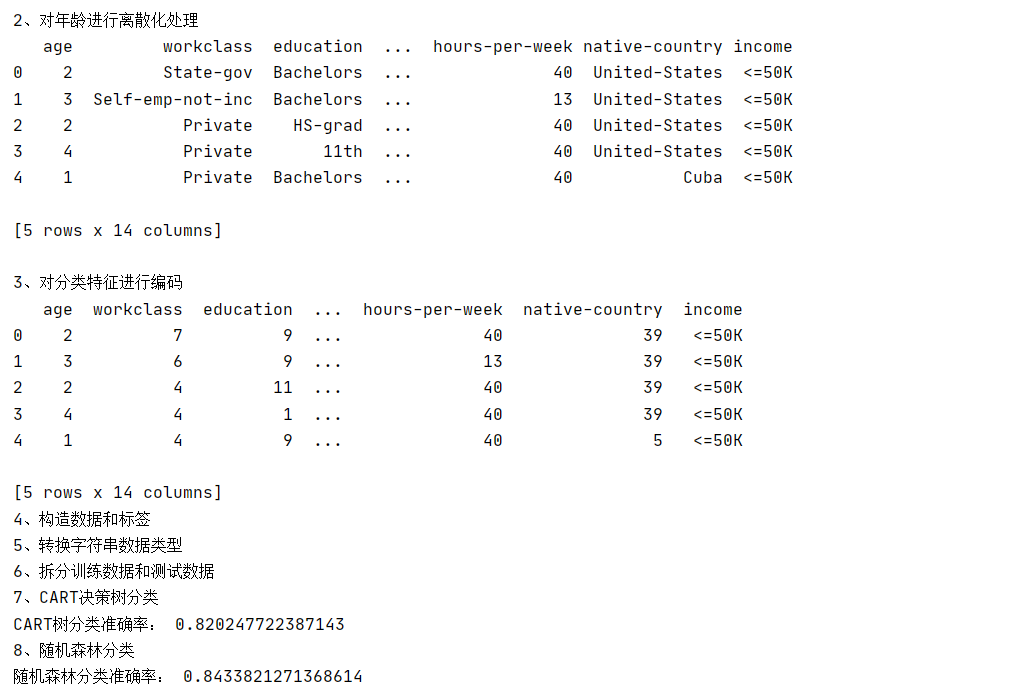
首先,实验从载入数据集开始。使用pandas库的read_csv函数读取数据集,并使用shape属性获取数据集的维度,即行数和列数,以及使用head()函数展示前5行数据。
实验步骤2:数据离散化处理
对于连续变量age,实验采用分位数的方法进行离散化处理。pd.qcut函数根据数据的分布将age分为5个区间,每个区间的数据被赋予一个从0开始的整数标签。
实验步骤3:特征编码
对于分类特征,实验使用LabelEncoder进行编码,将每个类别的字符串标签转换为整数。这一步骤是必要的,因为机器学习模型只能处理数值型数据。
实验步骤4:数据预处理及构造标签
接下来,实验对数据进行预处理,构造模型的输入数据和标签。数据集中的income字段被用作标签,根据其值将标签分为0和1两类。
实验步骤5:转换字符串数据类型为数值型
由于决策树和随机森林算法只能处理数值型数据,实验使用DictVectorizer将数据转换为数值型。
实验步骤6:训练集与测试集拆分
实验将数据集按照7:3的比例随机划分为训练集和测试集,以便于后续的训练和测试。
实验步骤7:CART决策树分类
使用CART算法训练决策树分类器,并计算其在测试集上的分类准确率。
实验步骤8:随机森林分类
使用随机森林算法训练分类器,并同样计算其在测试集上的分类准确率。
实验步骤9:结果可视化
最后,实验通过柱状图可视化了两种模型的分类准确率,直观展示了随机森林相对于决策树在本次实验中的优势。

实验结果
实验结果显示,CART决策树的分类准确率为82.61%,而随机森林的分类准确率达到了84.83%,后者在本次实验中表现更优。
结果分析
决策树的生成是基于递归分裂过程,每一次分裂都旨在最大化类别的同质性。然而,决策树容易过拟合,特别是当数据集未经过适当的离散化处理时。随机森林通过构建多个决策树并进行投票,有效地提高了分类的准确性和鲁棒性。在本次实验中,随机森林的准确率超过了决策树,这可能是因为随机森林在处理复杂的分类问题时,能够更好地泛化。
整体代码分析
以下是实验中使用的关键代码的详细分析:
# 导入所需库
import numpy as np
import pandas as pd
from sklearn import tree
from sklearn.ensemble import RandomForestClassifier
from sklearn.feature_extraction import DictVectorizer
from sklearn.preprocessing import LabelEncoder
import matplotlib.pyplot as plt
# 1. 载入数据
print('1、载入数据')
data = pd.read_csv("income_classification.csv", header=0)
print('数据维度:', data.shape)
print(data.head())
# 2. 对连续变量 'age' 进行离散化处理
print('\n2、对年龄进行离散化处理')
data['age'] = pd.qcut(data['age'], q=5, labels=False) # 使用分位数进行离散化
print(data.head())
# 3. 将分类特征进行编码
print('\n3、对分类特征进行编码')
class_le = LabelEncoder()
categorical_features = ['workclass',
'marital-status',
'occupation',
'education',
'native-country',
'relationship',
'race',
'sex']
for feature in categorical_features:
data[feature] = class_le.fit_transform(data[feature])
print(data.head())
# 4. 数据预处理及构造标签
print('4、构造数据和标签')
data1 = data.drop('income', axis=1).to_dict(orient='records')
labels = np.where(data['income'] == '<=50K', 0, 1)
# 5. 转换字符串数据类型为数值型
print('5、转换字符串数据类型')
vec = DictVectorizer()
x = vec.fit_transform(data1).toarray()
# 6. 拆分训练集与测试集
print('6、拆分训练数据和测试数据')
ratio = 0.7
indices = np.random.permutation(len(x))
split_index = int(ratio * len(indices))
x_train, x_test = x[indices[:split_index]], x[indices[split_index:]]
y_train, y_test = labels[indices[:split_index]], labels[indices[split_index:]]
# 7. CART决策树分类
print('7、CART决策树分类')
clf_cart = tree.DecisionTreeClassifier(criterion='entropy')
clf_cart.fit(x_train, y_train)
accuracy_cart = clf_cart.score(x_test, y_test)
print('CART树分类准确率:', accuracy_cart)
# 8. 随机森林分类
print('8、随机森林分类')
clf_random = RandomForestClassifier()
clf_random.fit(x_train, y_train)
accuracy_random = clf_random.score(x_test, y_test)
print('随机森林分类准确率:', accuracy_random)
# 可视化分类准确率
models = ['CART', 'Random Forest']
accuracies = [accuracy_cart, accuracy_random]
plt.figure(figsize=(5, 5))
plt.bar(models, accuracies, color=['blue', 'green'])
plt.yticks(np.arange(0, 1, 0.05))
for i, v in enumerate(accuracies):
plt.text(i, v + max(accuracies) * 0.05, str(v), ha='center', va='bottom')
plt.title('Model Accuracies')
plt.xlabel('Model')
plt.ylabel('Accuracy Score')
plt.show()
在上述代码中,首先导入了实验所需的库,然后按步骤执行了数据载入、离散化处理、特征编码、数据预处理、模型训练和分类准确率计算。最后,使用matplotlib库对分类准确率进行了可视化展示。



![[Bootloader][uboot]code总结](https://img-blog.csdnimg.cn/direct/14408d46114b497998f3590c131f9e42.png)