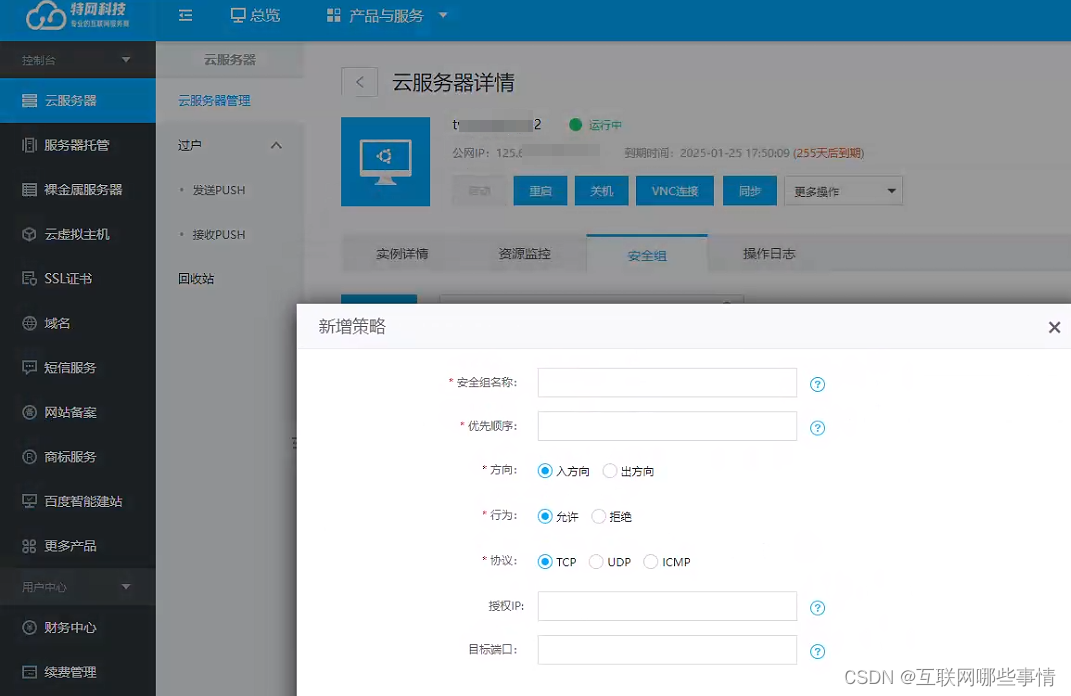
在Google I/O 2024大会上,Google推出了Veo,这是一款能够根据文本提示生成1080p视频的AI模型。这次发布标志着Google在生成式AI领域的又一重大突破。
Veo的强大功能
Veo不仅能够生成各种视觉和电影风格的视频片段,包括风景镜头和延时摄影,还能对已有的片段进行编辑和调整。Google DeepMind的负责人Demis Hassabis表示,他们正在探索更多功能,例如故事板生成和更长场景的制作。

Veo是Google在视频生成领域的最新尝试,基于此前发布的Imagen 2图像生成模型。然而,Veo的能力远超Imagen 2,它不仅能够生成高分辨率的视频,还能与市场上领先的模型如OpenAI的Sora竞争。
在发布会上,DeepMind的研究负责人Douglas Eck展示了一些Veo的生成实例,其中一个繁忙的海滩场景尤其突出,显示了Veo在处理复杂动态场景方面的优势。

训练数据与道德争议
Veo的训练数据来源于大量视频素材。虽然Eck没有具体说明数据来源,但他暗示部分数据可能来自Google自己的YouTube平台。这引发了关于数据使用和版权的问题。
去年,Google修改了其服务条款,以允许公司利用更多数据来训练其AI模型。这一调整使得Google可以更自由地使用YouTube数据进行产品开发,尽管这可能让部分创作者感到不满。
Eck强调,Google正在努力与电影、音乐等各行业的利益相关者合作,以确定数据使用的下一步措施,并确保模型训练的道德规范。然而,Google并未提供让创作者从其训练数据集中移除作品的机制,这在一定程度上限制了创作者的选择。

技术细节与未来发展
Veo模型在技术上具有较高的可控性,能够理解相机运动和特效,例如“平移”、“缩放”和“爆炸”等描述。此外,Veo还支持掩码编辑,可以对视频的特定区域进行修改,并能够从静态图像生成视频。
然而,Veo并非完美。当前的生成AI技术仍存在局限性,例如对象在视频中消失和重现的现象,以及物理规律的错误应用。Eck表示,Veo将继续在Google Labs的等待名单上进行测试和改进,未来将逐步引入YouTube Shorts等产品。

结语
Google Veo的发布展示了生成式AI在视频制作领域的巨大潜力。尽管目前仍有许多挑战需要克服,但Veo为未来的电影制作和视频创作带来了新的可能性。
Google将在未来继续改进Veo模型,并探索更多应用场景,期待这一技术能够为创作者和用户带来更多惊喜。





![[vue] nvm](https://img-blog.csdnimg.cn/direct/8d8f3c4cc22747658dcd267f9f6298a6.png)