目录
- bib 文献整理脚本
- 前提条件与主要功能
- 原理
- 编程语言与宏包基础
- 完整程序
bib 文献整理脚本
本文主要用于解决 Latex 写作过程中遇到的 bib 文献整理问题,可处理中文文献。
LaTeX是一种基于ΤΕΧ的排版系统,它非常适用于生成高印刷质量的科技和数学类文档,同样适用于生成从简单的信件到完整书籍的所有其他种类的文档。
前提条件与主要功能
前提条件:bib文件中参考文献格式正确。
主要功能:
- 参考文献去重
- 参考文献排序
Vscode 已有参考文献排序功能,本文主要解决的痛点问题是:
将两个 project 里面的 bib 文件合并后,参考文献重复会导致编译不通过
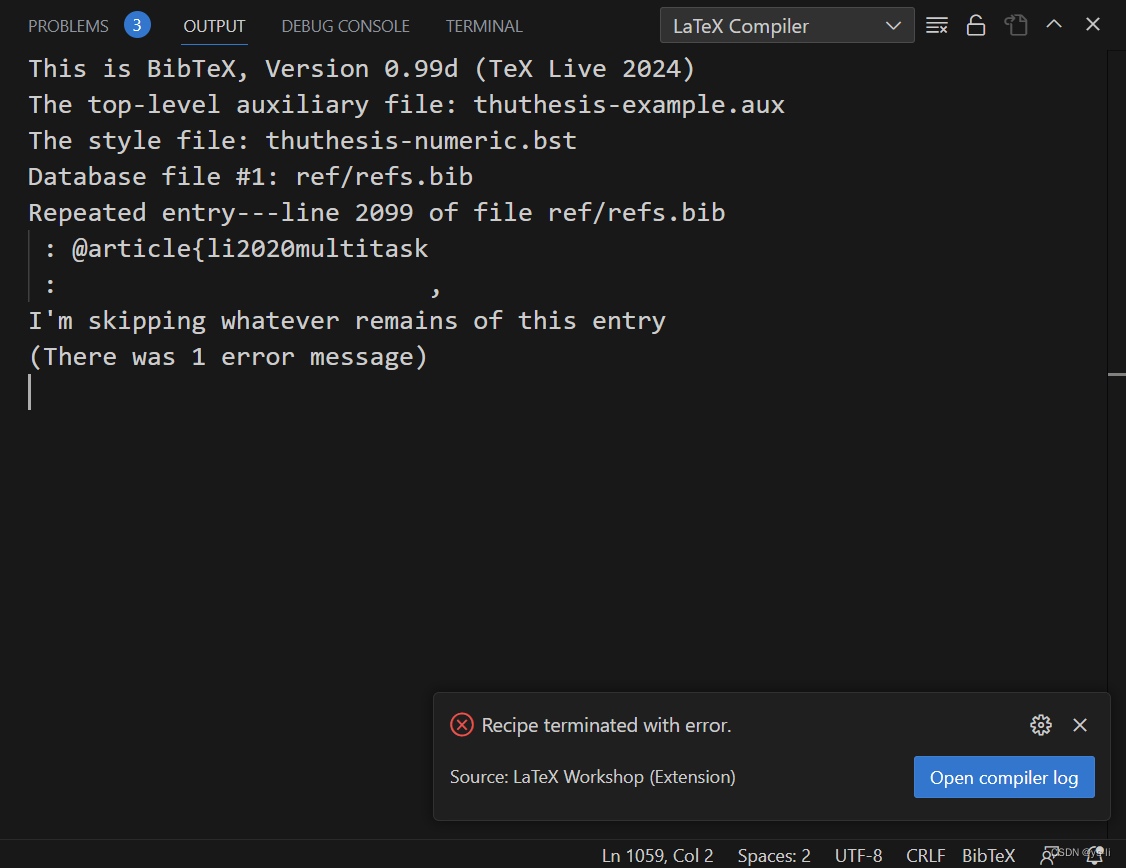
原理
读取 bib 文件内容后,识别所有的参考文献字段,提取关键词并进行排序,参考文献字段示例:
@article{li2020multitask,
title = {Multitask learning for super-resolution of seismic velocity model},
author = {Li, Yinshuo and Song, Jianyong and Lu, Wenkai and Monkam, Patrice and Ao, Yile},
journal = {IEEE Transactions on Geoscience and Remote Sensing},
volume = {59},
number = {9},
pages = {8022--8033},
year = {2020},
publisher = {IEEE}
}
其中 li2020multitask 即为关键词
编程语言与宏包基础
选用 python 语言,对环境基本没有要求,只需要调用 argparse,re 两个包分别用于识别脚本参数与正则匹配。
re 正则匹配基础:
.匹配任意单个字符*匹配前面的字符0次或多次+匹配前面的字符1次或多次?匹配前面的字符0次或1次|匹配两个或多个表达式中的任意一个[]匹配括号中的任意一个字符()匹配括号中的表达式\d匹配任何数字字符\w匹配任何字母数字字符\s匹配空格字符\b匹配单词边界^匹配字符串的开头$匹配字符串的结尾
完整程序
import argparse
import re
if __name__ == '__main__':
# 设置脚本参数,包括输入和输出文件
parser = argparse.ArgumentParser(
description='manual to this script')
parser.add_argument(
"--bib_path", type=str, default="ref/refs.bib")
parser.add_argument(
"--bib_out", type=str, default=None)
# 读取并设置脚本参数
args = parser.parse_args()
bib_path = args.bib_path
bib_out = bib_path if args.bib_out is None else args.bib_out
# 读取数据,根据@进行字段分割,@前可能有换行加若干空格
with open(bib_path, 'r', encoding='utf-8') as f:
bib_data = re.split('[\n|\r]\s*\@', f.read())
# 处理第一个参考文献字段,统一成缺少@的参考文献字段
#(后面会统一补充@符号)
if bib_data[0][0] == '@':
bib_data[0] = bib_data[0][1:]
else:
bib_data.pop(0)
# 提取关键字和完整字段字典,实现去重,关键字全部为小写
bib_dict = dict()
for bib in bib_data:
key = re.findall('{(.*?),', bib)[0].lower()
bib_dict[key] = '@' + bib
# 升序排序
keys = sorted(bib_dict.keys())
bib_list = [bib_dict[key] for key in keys]
bib_data = '\n\n'.join(bib_list)
# 输出结果
with open(bib_out, 'w', encoding='utf-8') as f:
f.write(bib_data)