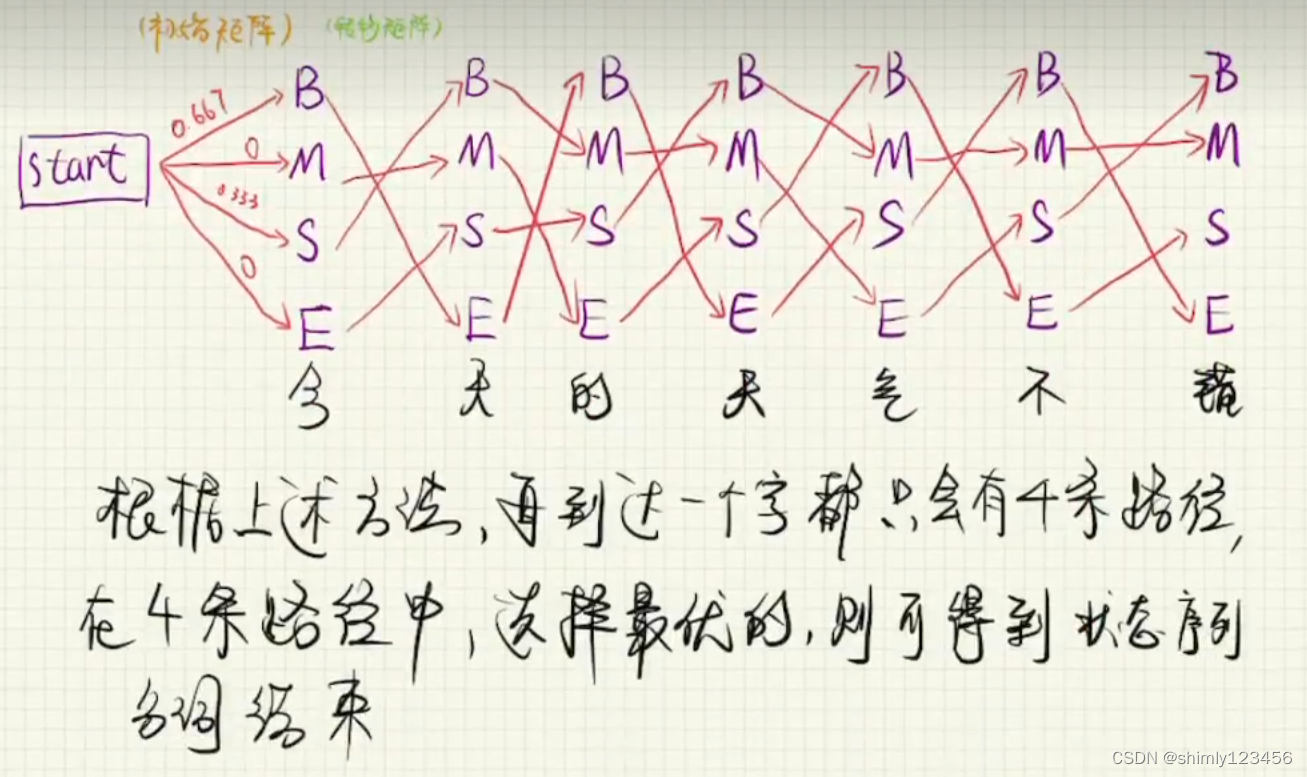
应用于应用环境的配置.测试.发布
假如你写了一个web,并且测试调试都没有问题
并且,你想发给你的朋友,导师,或者部署到远程云服务器上
那么,你需要配置相同的软件,比如数据库,web服务器,必要的插件,库,etc…但这并不一定能保证软件的正常运行,因为别人可能使用完全不同的操作系统,甚至不同的Linux发行版本也会有差别
为了模拟完全相同的本地开发环境,我们自然想到会使用虚拟机
但是,虚拟机需要完全模拟硬件,并且运行整个OS,不但体积臃肿且内存占用极高,程序的性能多多少少也会受到影响

这时,docker就派上了用场

Docker的概念和虚拟机很拟合,但由于不用模拟底层的硬件,只会为每一个应用提供完全隔离的运行环境,所以轻量级很多
这个环境可以用来配置不同的工具软件,并且这个环境相互独立互不影响
大伙一般称这个环境叫Container/容器
Docker中的三个重要概念:

镜像:可以理解为虚拟机的快照snapshot,里面包含了要部署的应用程序以及它关联的所有库
通过镜像,我们可以创建很多独立的容器
容器:类似一台台独立运行你的程序的虚拟机
文件:自动化脚本,用以创建镜像(类似于在虚拟机中安装OS及软件,只不过通过DockerFile这个脚本自动完成了)
桌面版安装部分参考来源
WSL2:windows旗下Linux子系统
1.查看自己电脑有无虚拟化
 添加Hyper-V:
添加Hyper-V:
txt文件内复制下列代码并重命名:Hyper-V.cmd
pushd "%~dp0"
dir /b %SystemRoot%\servicing\Packages\*Hyper-V*.mum >hyper-v.txt
for /f %%i in ('findstr /i . hyper-v.txt 2^>nul') do dism /online /norestart /add-package:"%SystemRoot%\servicing\Packages\%%i"
del hyper-v.txt
Dism /online /enable-feature /featurename:Microsoft-Hyper-V-All /LimitAccess /ALL
管理员权限运行Hyper:
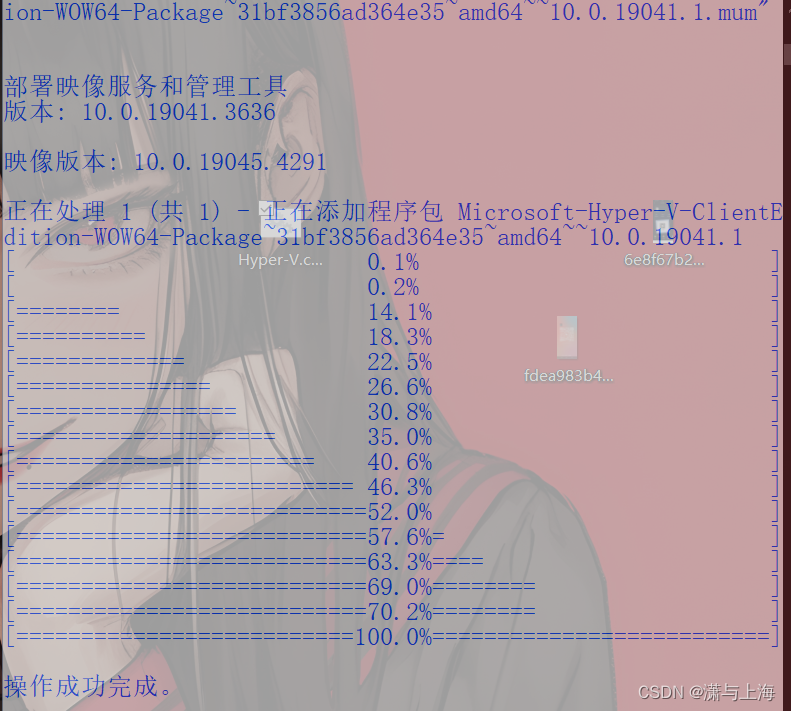
启用Hyper-V,子系统,虚拟机平台:
打开搜索栏,输入windows,出现一个启用或关闭Windows功能,并打开
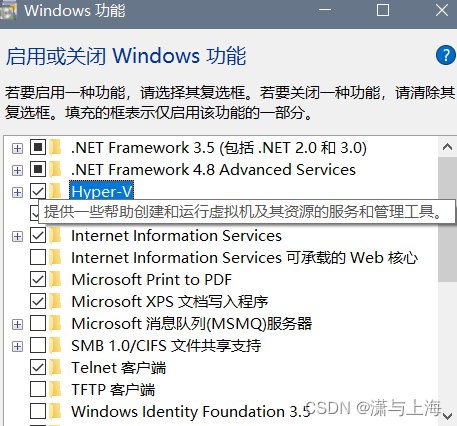
也勾上

...
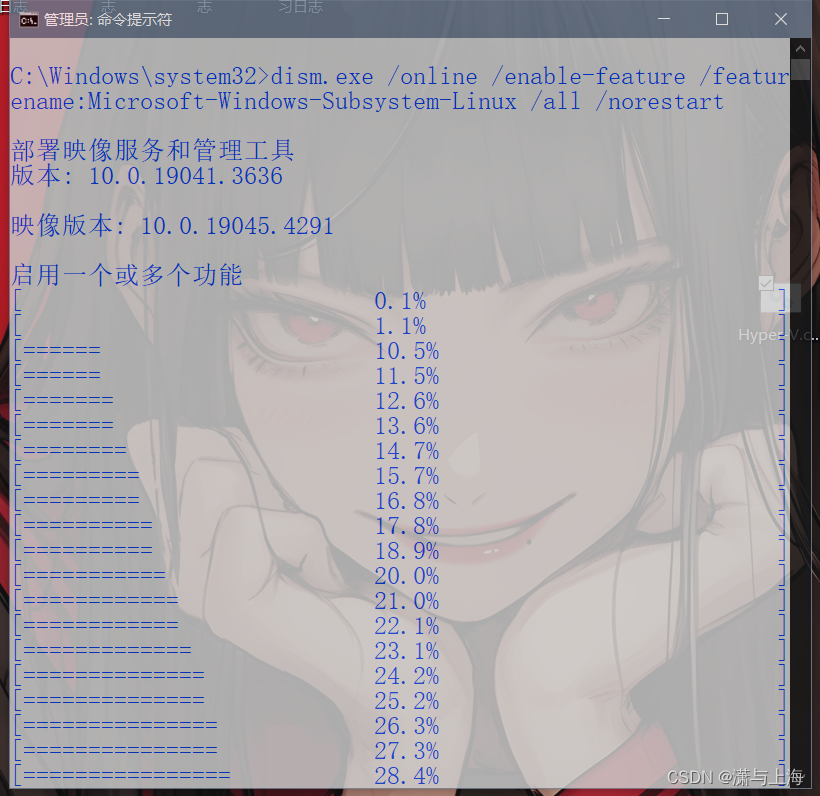
安装wsl
这里我不太清楚怎么安装好的
如果是安好了误删,则需要微软商店下载WINDOWS SUBSYSTEM FOT LINUX
但好像是,如果windows功能开启了适用于linux的子系统则会自动有
微软商店的WSL
检查wsl并更新
wsl -l
wsl若报错,没有则跳过
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
更新WSL2的Linux内核:官方下载地址
https://wslstorestorage.blob.core.windows.net/wslblob/wsl_update_x64.msi
点击更新WSL2的Linux内核
此时提示没有安装Linux子系统发行版,不管,将默认安装的Linux子系统版本设置为WSL2
将wsl版本设置为2
wsl.exe --set-default-version 2

1、关闭 Docker
2、“以管理员身份运行 powershell,输入以下命令,升级wsl,耐心等待升级完成后,再启动Docker就好了。
C:\WINDOWS\system32> wsl --update
修改默认安装位置
安装界面上是没有提供修改安装目录的地方的,但官方提供了参数修改:
安装包自己就提供了修改安装路径的功能,CMD中运行:
<path> 改成你需要的目录,默认是:C:\Program Files\Docker\Docker
"Docker Desktop Installer.exe" install --installation-dir=<path>


....
打开后自动开始安装,有下一步点下一步,全部选项默认即可。这里不能选择安装位置,Docker默认安装必须是C盘,后续更改的是镜像加载位置。虽然可以通过修改注册表改变默认安装位置,但是会引起问题,同时殃及一大堆其他软件,极不推荐!
安装完成后打开Docker,会出现引导界面,点击右下方skip跳过
点击下载docker


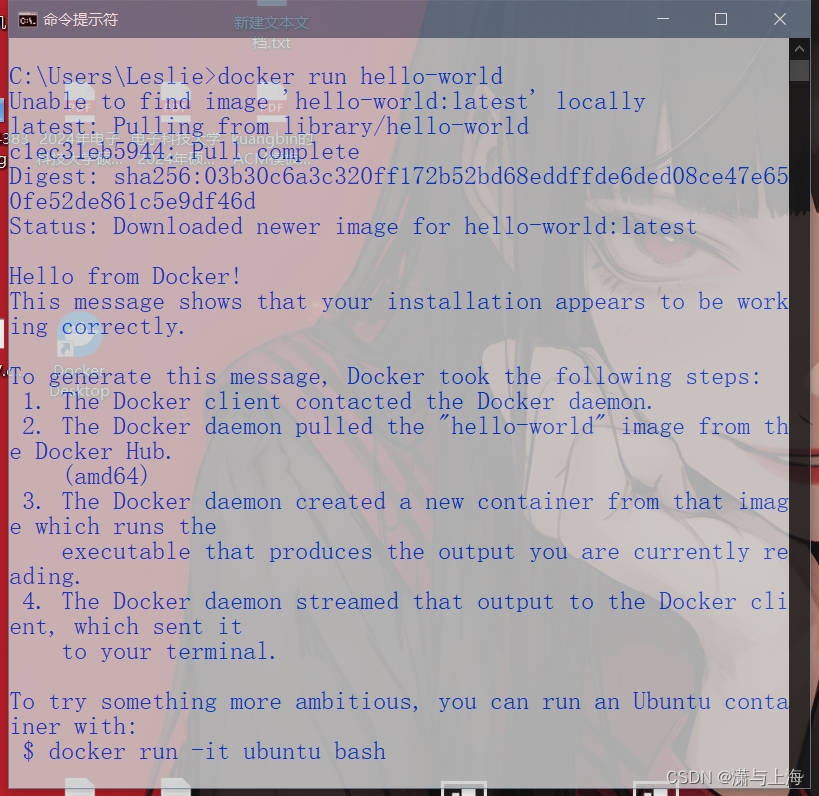
出现helloworld镜像

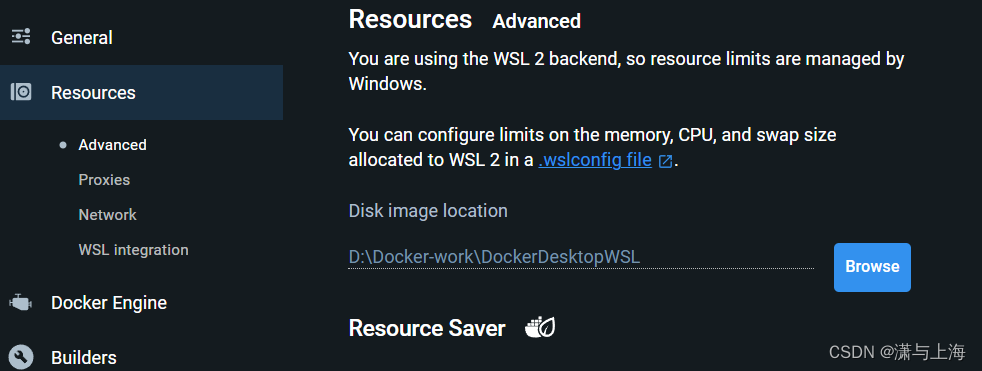
修改Docker镜像的加载路径
如果您的C盘空间够用,完全没有必要迁移,请跳转至“配置WRF”。
Docker默认安装位置为C盘,不建议修改,但是镜像的存储和加载路径可以被修改,前提是Docker采用的是WSL2的模式,即wsl -l -v看到的两行docker相关的VERSION都是2,否则迁移会使docker难以加载并且效率变低(这是我自己的经验不代表官方)。
同时,迁移前Docker内不应该有任何需要用的容器、镜像存在,迁移已有的容器到其他盘我也不知道会出什么问题,保险起见、效率起见还是清空。
清空方法:Docker右上角小虫子(Troubleshoot)- Clean / Purge data,弹出窗口全部打勾。
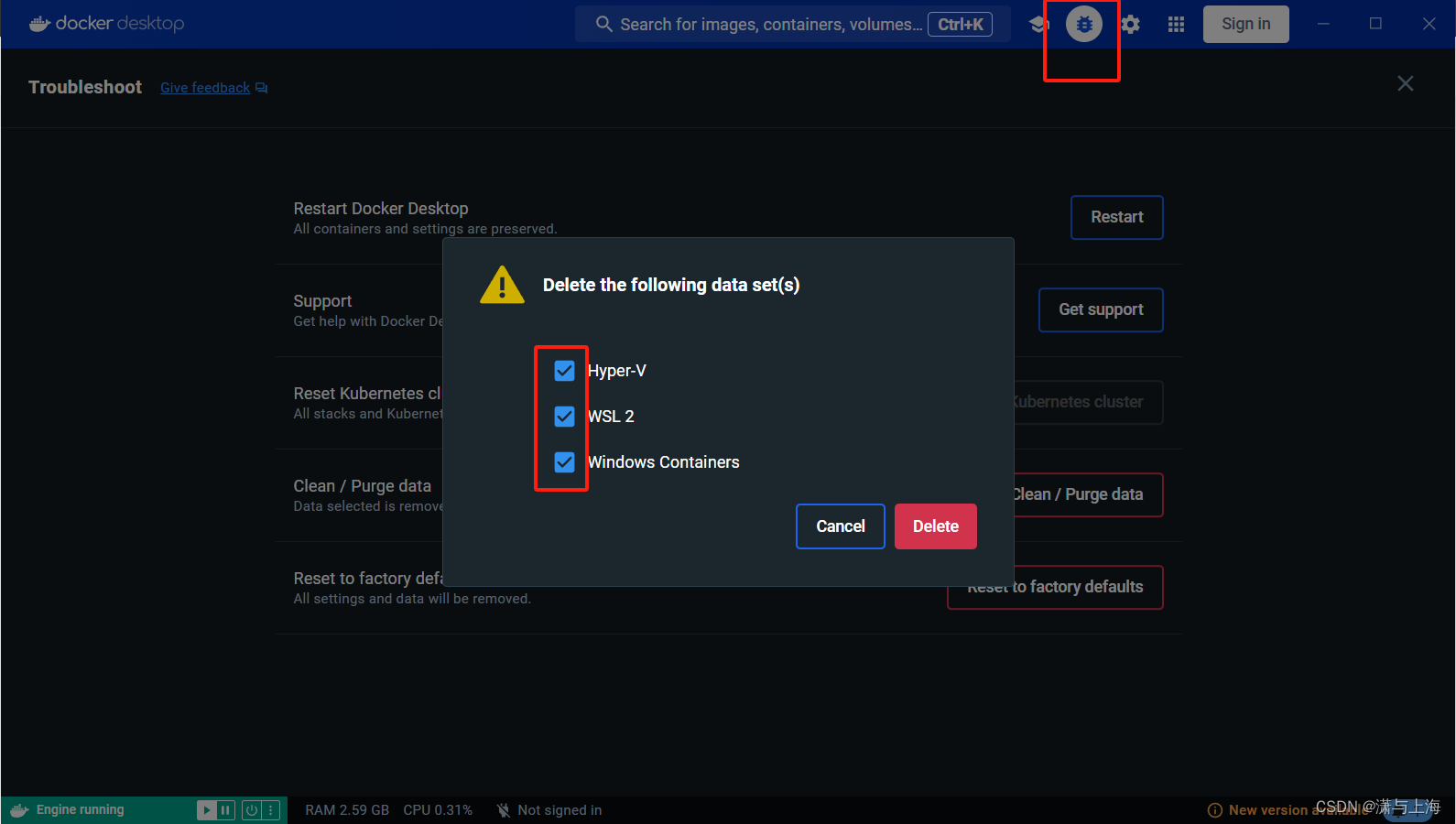
清空后Docker内所有镜像消失,之前的hello-world也消失,此时先选择好自己想要迁移到哪里
比如D盘,然后新建文件夹,比如DockerImages,打开以后在里面继续创建两个文件夹:docker-desktop和docker-desktop-data,名字不用完全一致,只是为了好区分。
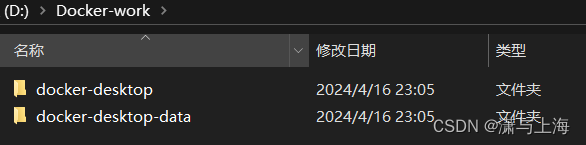
创建这两个文件夹的原因是在Terminal中之前看到的docker-desktop和docker-desktop-data一个存放程序,一个存放镜像,路径不能一样。
然后把Docker完全退出!否则会出问题!
Docker任务栏图标消失后,还需要使用命令
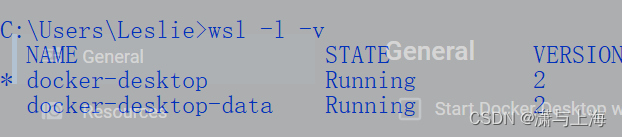
wsl -l -v
确认docker-desktop和docker-desktop-data两项右侧的状态是stop而非running,才是彻底停止了。
如果仍是running的话,使用wsl --shutdown,停止所有wsl虚拟环境。


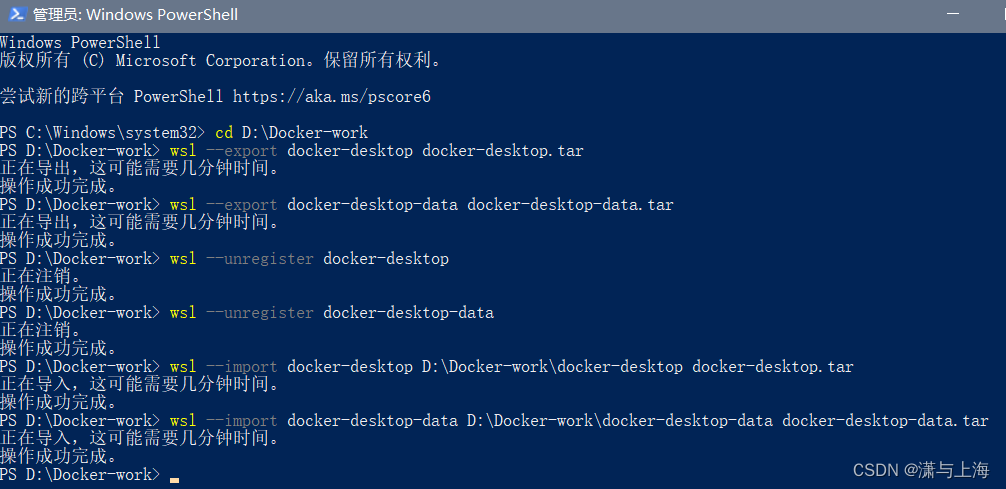
wsl --export docker-desktop docker-desktop.tar
wsl --export docker-desktop-data docker-desktop-data.tar
这一步是将原来的docker镜像导出,由于之前进行过清理,所以两个都不会太大。命令中的“docker-desktop.tar”是相对位置,即保存在现在的DockerImages文件夹下,也可以填自己想要的绝对位置,data同理。

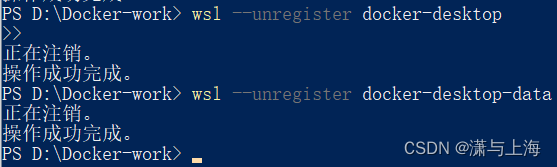
然后注销docker的wsl子系统
wsl --unregister docker-desktop
wsl --unregister docker-desktop-data
再在新位置重新创建
wsl --import docker-desktop D:\Docker-work\docker-desktop docker-desktop.tar
wsl --import docker-desktop-data D:\Docker-work\docker-desktop-data docker-desktop-data.tar
这里的命令可以分段来看,“D:\DockerImages\docker-desktop”是目标目录,用绝对位置,新的子系统会创建在这里;空格以后的“docker-desktop.tar”是刚刚导出的镜像的相对位置,意思是把这个镜像导入到前面的目标目录里面。
docker-desktop-data同理。

导入以后,在相应的两个目标文件夹里就会显示出后缀为.vhdx的虚拟磁盘,大小和之前导出的两个tar相比量级相同,会大一些。


再次启动Docker,短暂等待之后坐下小鲸鱼变绿,说明迁移成功,软件没受影响。

更改镜像地址
点击右下应用
Docker操作-桌面/VS
下面所有的操作,均有桌面版和插件版的对应方法,我各自举例一点:
桌面版操作:
图形界面可以在后台查看应用所有的输出,便于调试
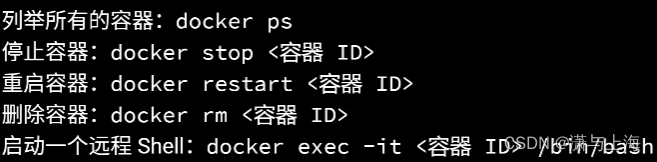
也可看见当前容器的信息,状态…可以停止,重启,删除容器,可shell远程调试这个容器
若删除一个容器,之前对该容器所有的操作和添加的数据都会丢失(类似于虚拟机的删除)
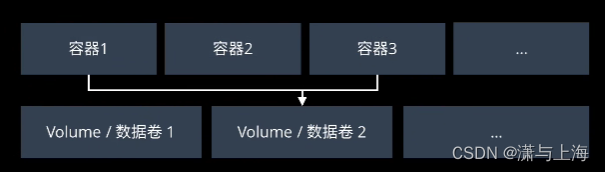
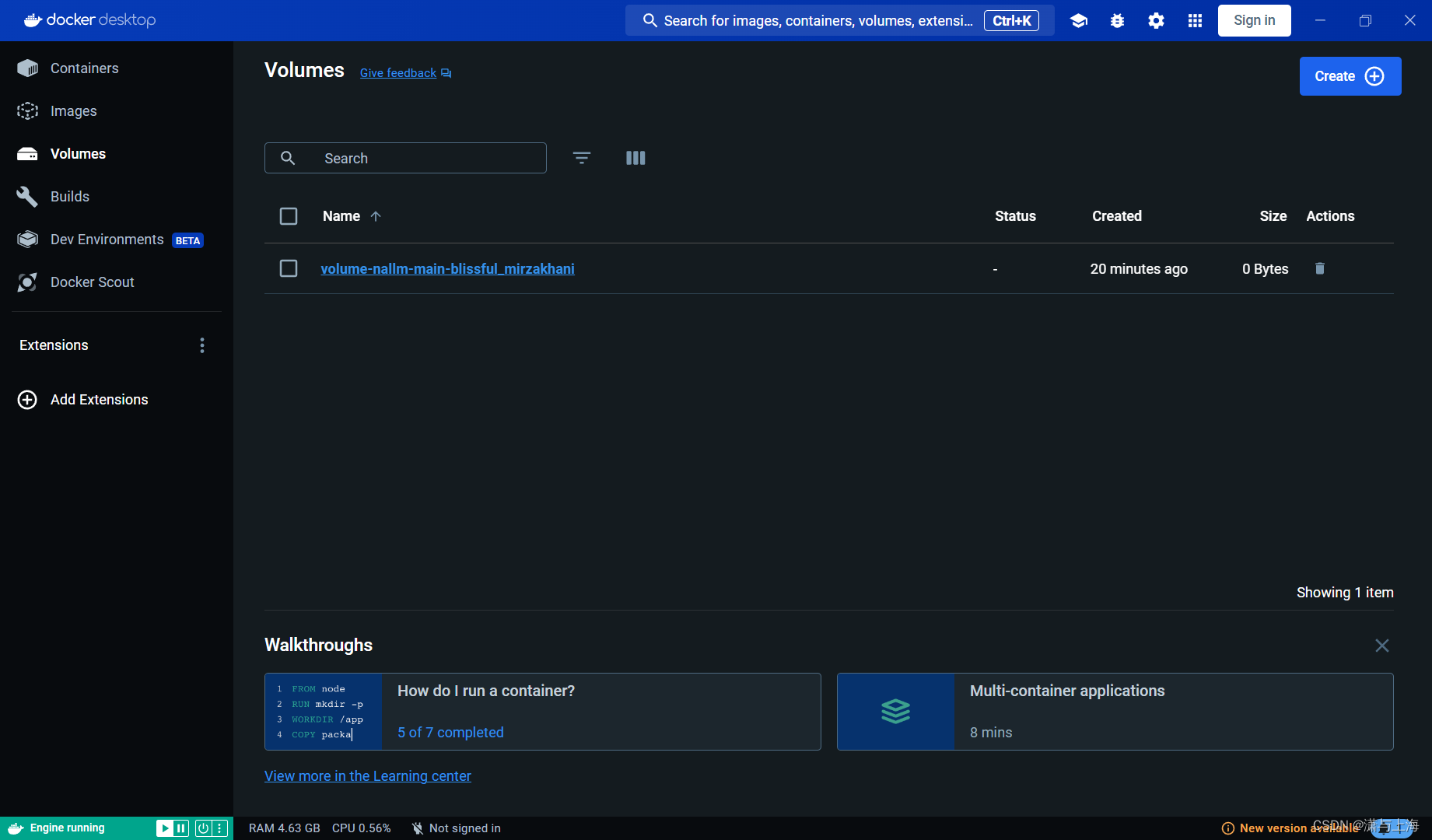
若想要保存容器的数据,可以使用docker中提供的volume数据卷,可以将其当作一个在本地主机和不同容器间共享的文件夹,比如下面在容器1中修改了volume2,则容器3享用v2时是被修改了的
创建数据卷-终端
docker volume create
docker run -dp 80:5000 -v 数据卷名haha:/etc/ha 容器名c
//-v将数据卷挂载mount到容器的哪一个路径上,此处将haha挂在到容器名c的/etc/ha这个路径下,向这个路径写入的任何数据都会被永久保存在数据卷中

VSCODE推荐安装其扩展:
DockerHub上有很多高质量的操作系统镜像,不同的OS提供不同的包管理工具:
Ubantu:apt
Fedora:dnf
也有许多方便某一种语言,某种框架开发的框架:
node,redis,nginx,py,tomcat
使用>docker来运行各种Docker命令,并且在左侧面板中看到所有的镜像,容器等
在应用的根目录下创建一个DockerFile文件
完成一个DOCKER-IMAGE镜像创建,通过自动化脚本DOCKERFILE
FROM python:3.8-slim-buster//指定一个基础镜像basic-image
//官方镜像:pyhton
//这个镜像的版本标签Tags:3.8-slim-buster
WORKDIR /app //指定了该命令之后所有Docker命令的工作路径,若不存在会自动创建该路径,避免绝对路径和手动cd切换
COPY..
//<本地路径><目标路径(Docker镜像中的路径)>
//将所有的程序拷贝导Docker镜像中
//第一个"."表示程序根目录下的所有文件
//第二个"."代表当前的工作路径,即之前指定的app目录
RUN pip3 Install -r requirement.txt //允许创建镜像时运行任意的shell命令,这里是安装py程序的所有关联
CMD["python3","app.py"] //CMD["可执行文件","参数1",..,"参数n"]指定当docker容器运行起来以后需要执行的指令
//RUN是创建镜像时使用,CMD运行容器的时候使用
终端terminal运行创建镜像(首次慢,但docker会缓存每一个操作,二次快,这个在docker中被称为分层layer)
docker built -t 名字 .
//-t:指定镜像名字/标签
//最后的"."告诉docker应该在当前目录下寻找这个dockerfile
有了镜像,启动
docker run -p 80:5000 -d 名字
//-p:映射容器的某个端口到本地主机上,这样才能从主机访问这个应用
//80主机端口
//5000容器的端口
//-d让容器在后台运行(detach):使容器的输出不显示在控制台
浏览器地址栏输入localhost访问这个应用即可
多个容器可以干嘛?
一个运行web
一个运行数据库
->数据和应用逻辑分离,各自独立:web程序宕机,数据库依旧运转,此时仅修复web容器即可
docker-compose.yml
services://定义多个container
web://容器1
build:.
ports:
- "80:5000"
db://容奇2
image:"mysql"
enviroment:
MYSQL_DATABASE:finance-db
MYSQL_ROOT_PASSWORD:secret
volumes:
- my-data:/var/lib/mysql
volumes:
my-data:
//可通过这两个环境变量指定数据库的名字和连接密码
定义完毕,保存文件
使用docker compose up来运行所有的容器
使用docker compose down来停止并删除所有的容器
新创建的数据卷需要手动删除,除非手动后面加入–volumes参数
很多应用,数据库容器都运行在同一个计算机中,随着应用规模的增大,一台计算机无法满足我们的所有需求,我们需要一个集群来提供服务,负载均衡,故障转移,则用kubernetes
kubernetes就是将各个容器分发到一个集群cluster上运行,并进行全自动化的管理,包括应用的部署和升级
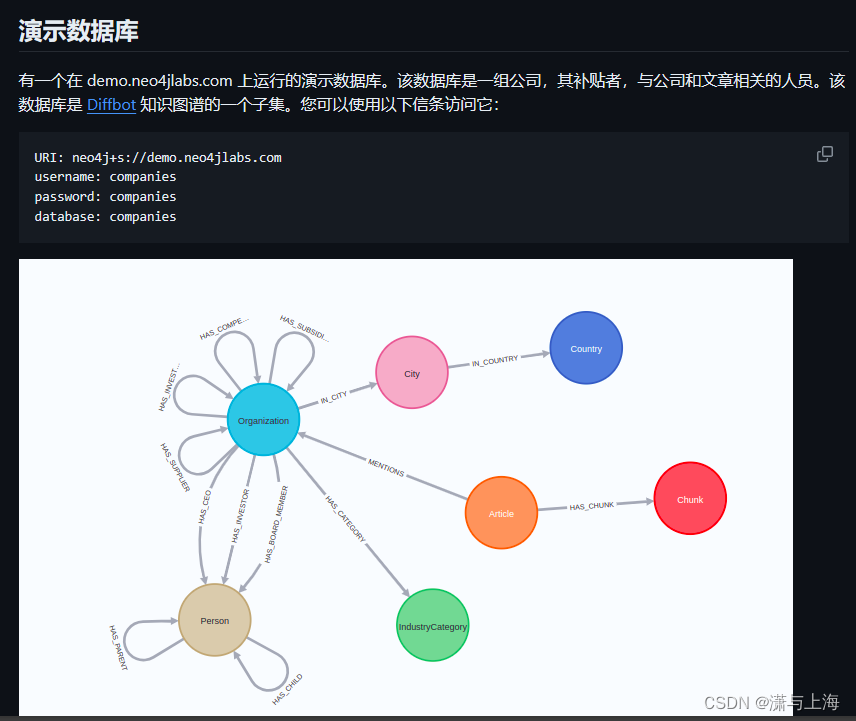
知识图谱开发日志

...
下载的GitHub最好置入新建文件夹,然后导入以此为根目录

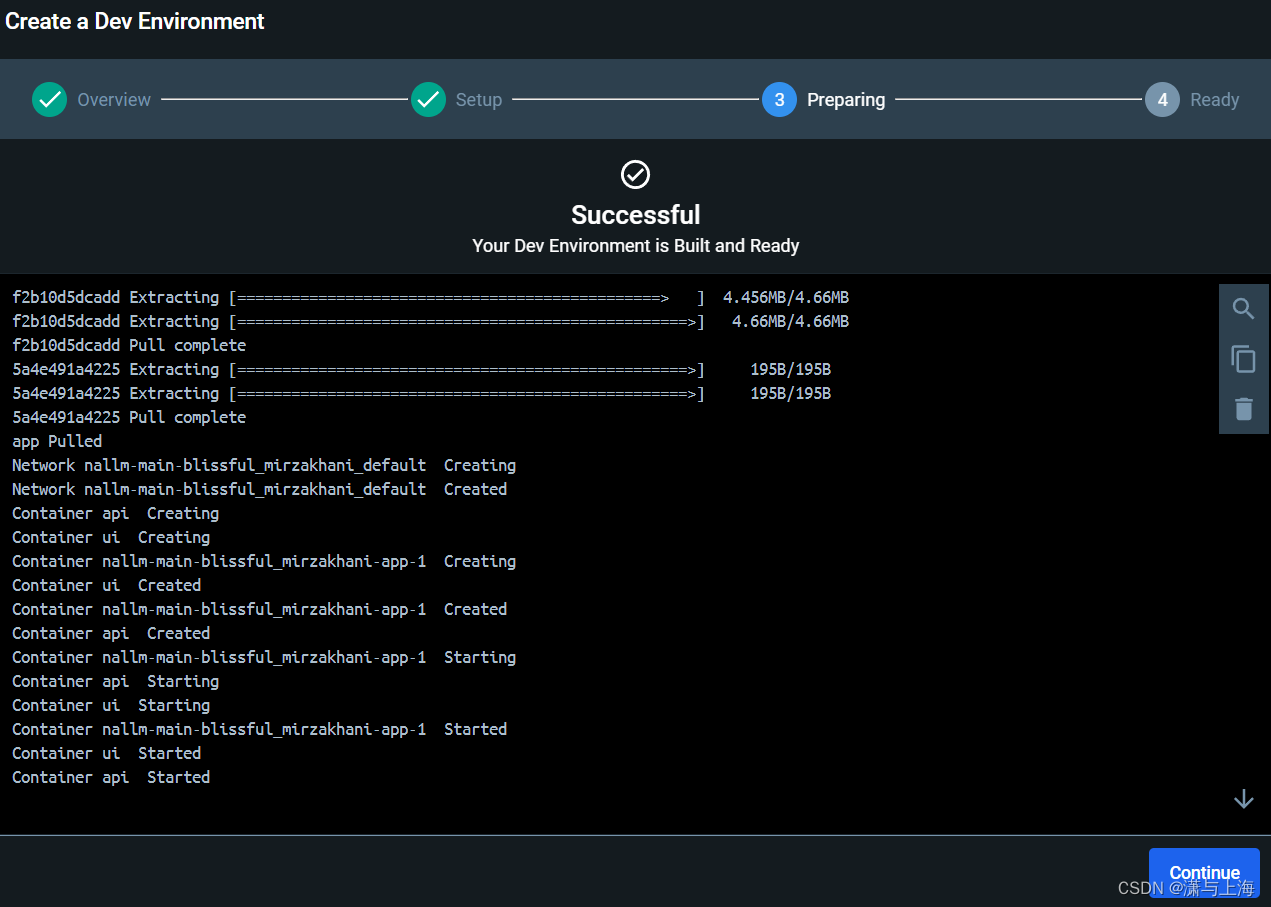
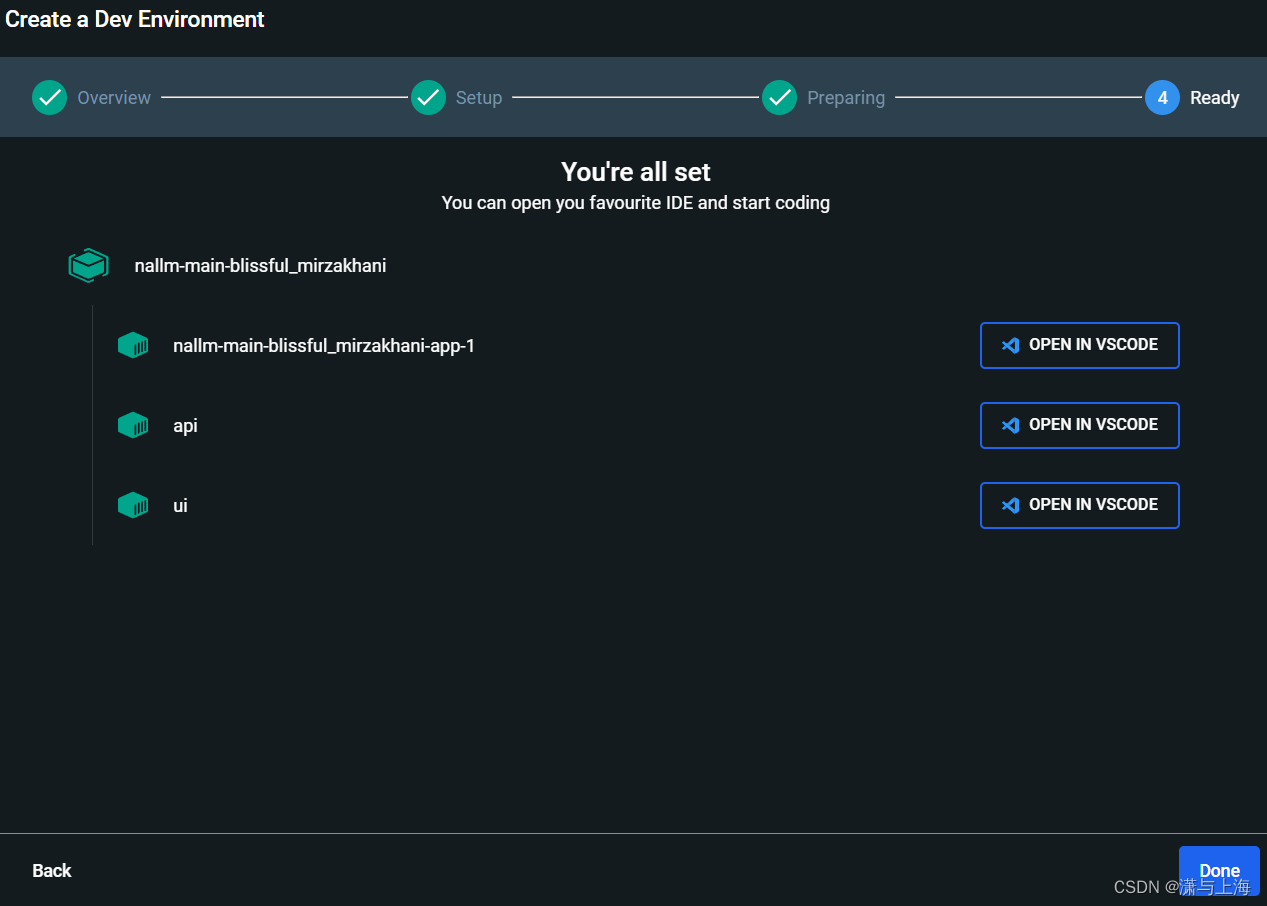
返回,分别有:
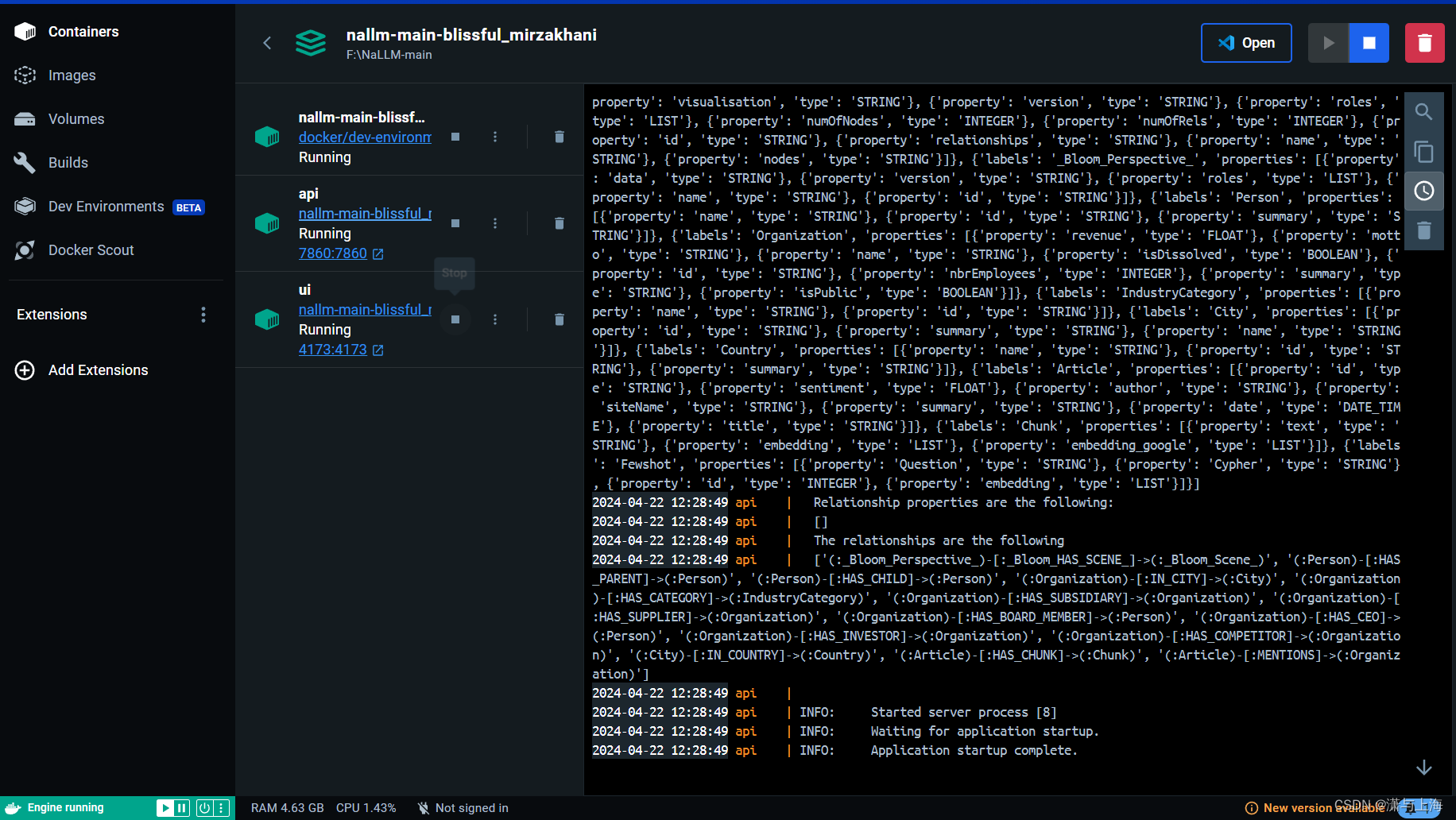
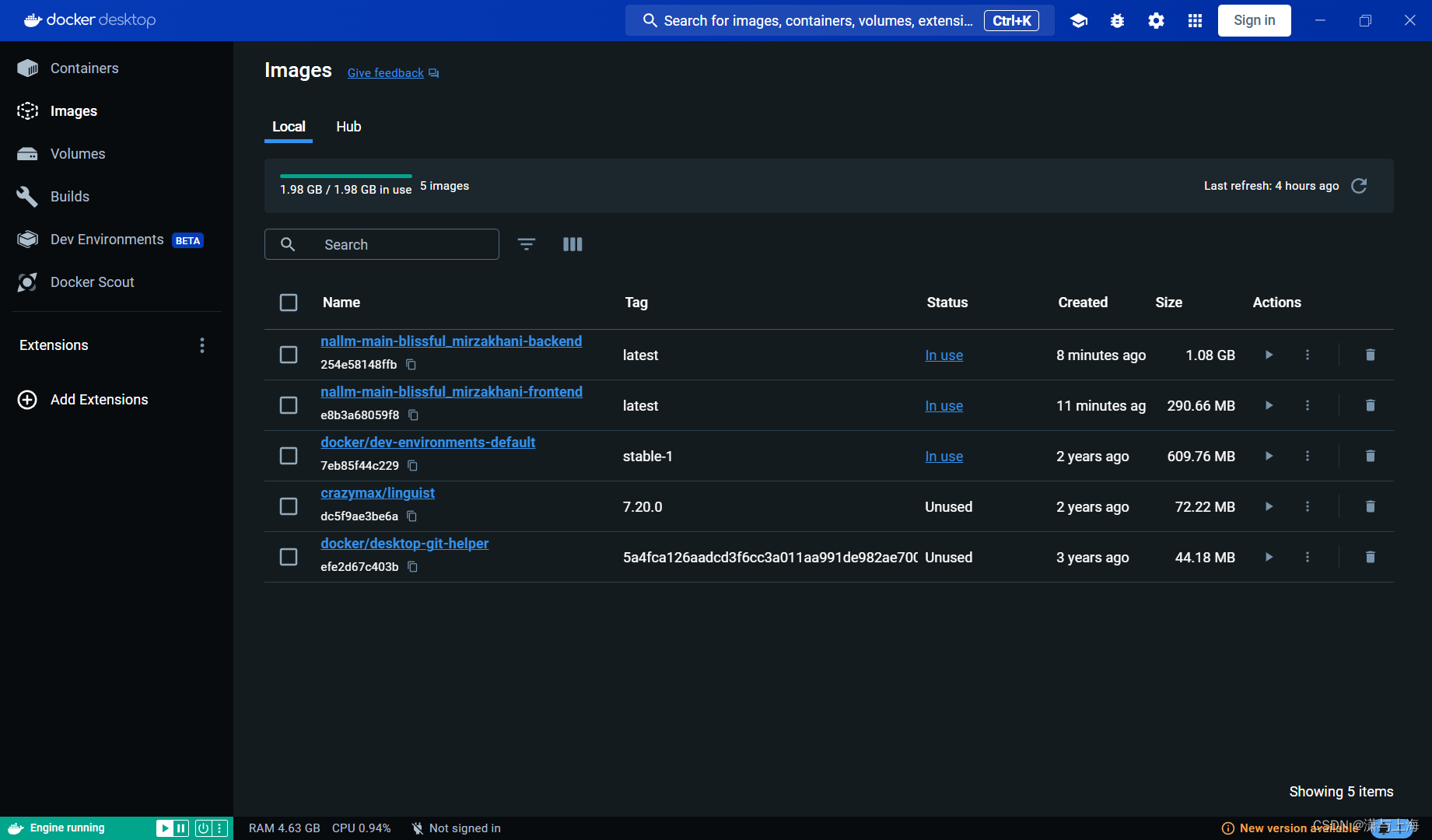
那里报错下哪个插件(这里的vue,vite,react,json)
确保dc已安装docker-compose --version
文件资源管理器找到对应含docker-compose.yml的地方
将.env.example文件修改为.env

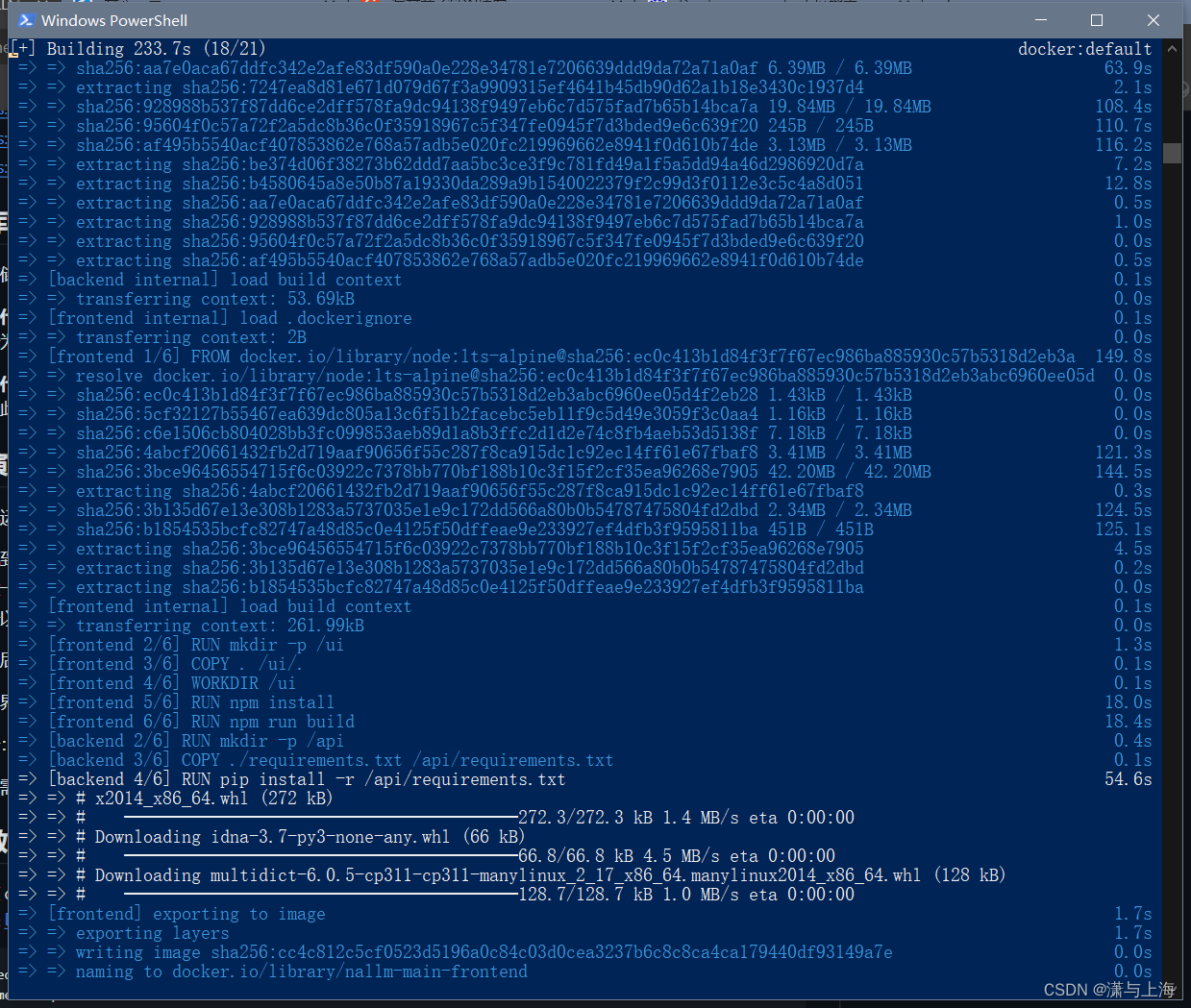
这个时候就是你的localhost在docker容器端口与应用端口连接的情况下可以访问这个相连端口了
好好好,4个G的项目干到37个G
...
环境
官方
镜像
生成镜像
git
docker使用
使用2
3
4
大学
docker使用
Neo4j-APOC扩展与使用
neo4j:browser
知识图谱构建:图数据库Neo4j的节点和关系的新增、删除
vue+neo4j +纯前端(neovis.js / neo4j-driver) 实现 知识图谱的集成
图数据库Neo4j实战
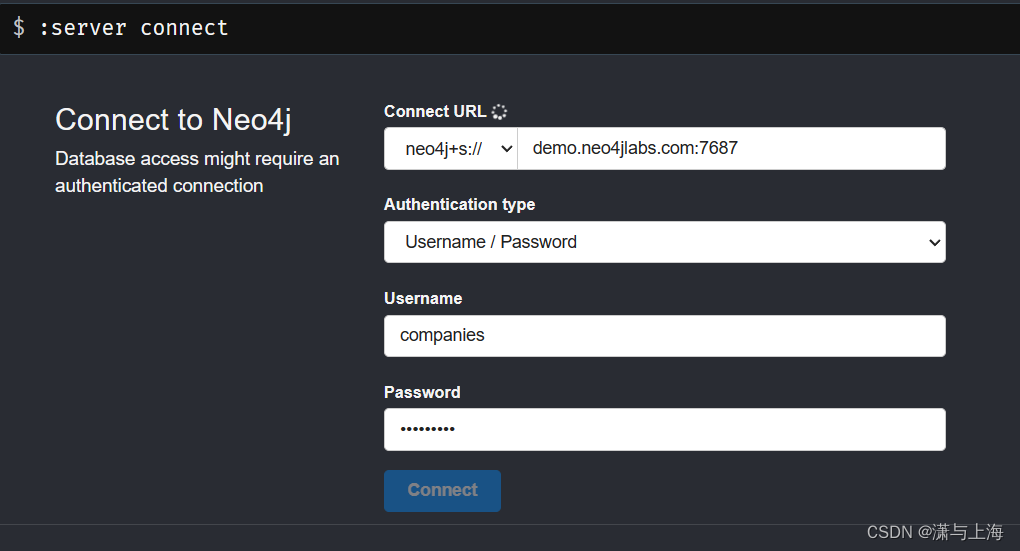
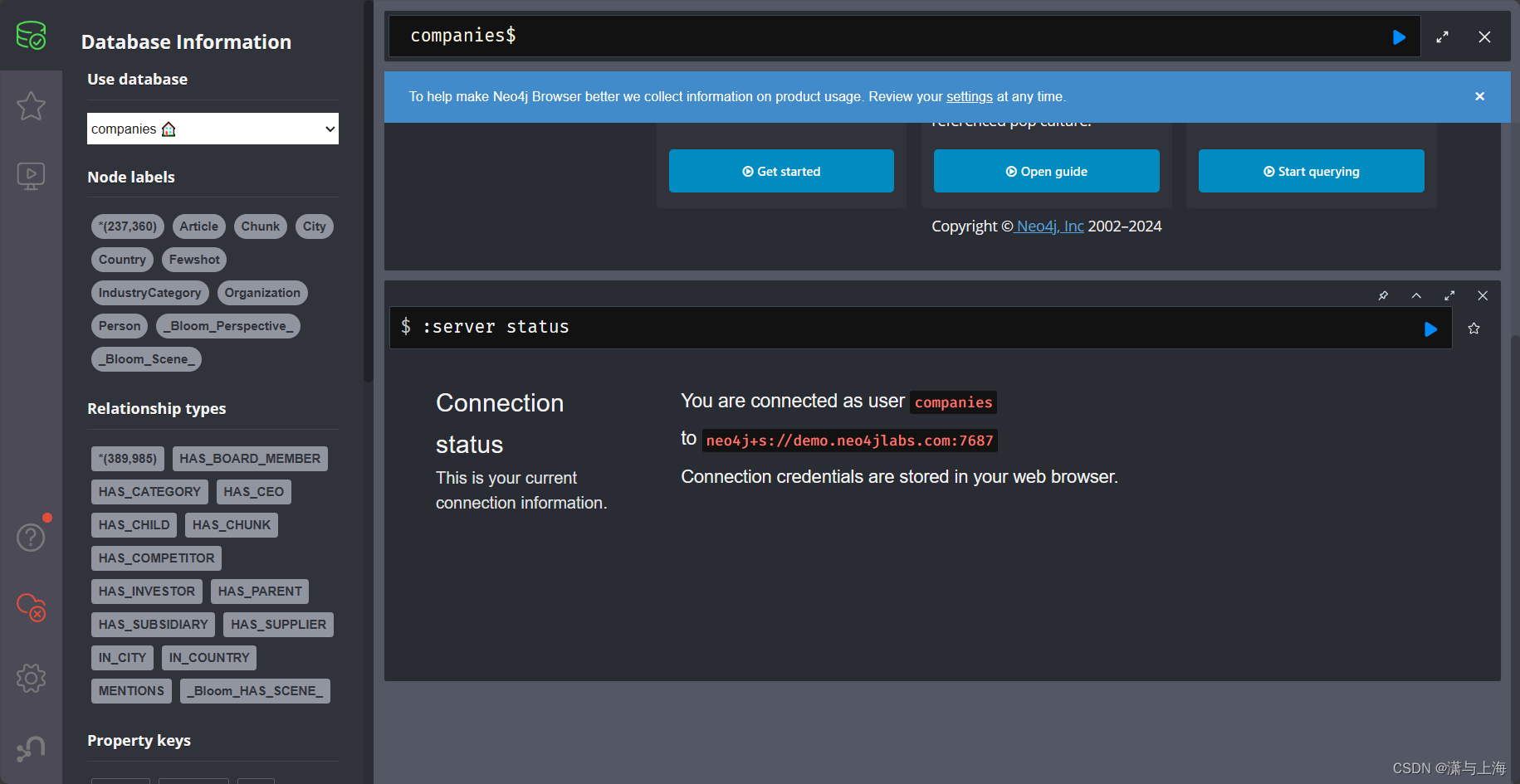
$后面输入查询语句
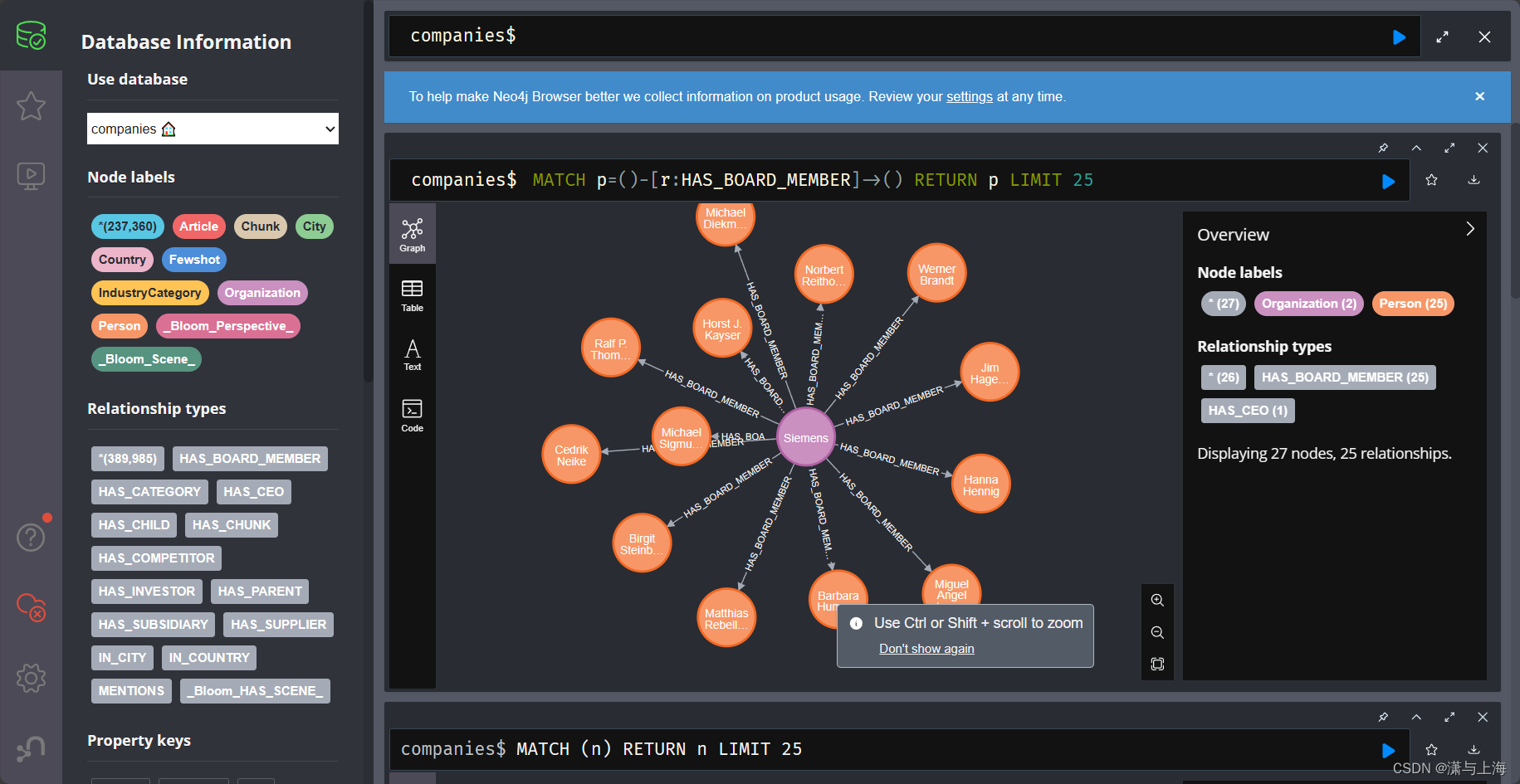
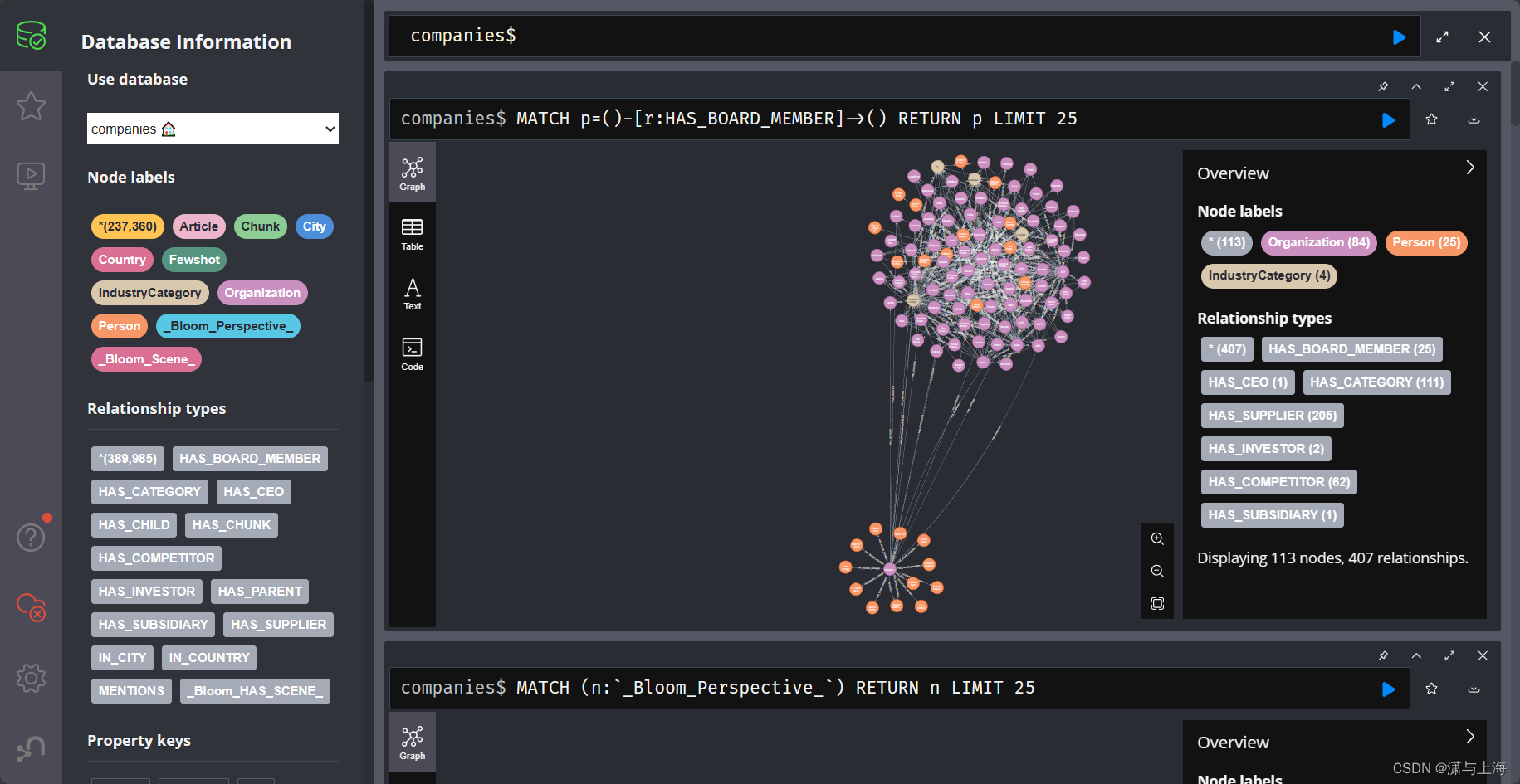
1.
往Neo4j里放数据有多种方式,具体取决于你的数据格式、数据量大小以及你的个人偏好。以下是一些常见的方法:
使用Cypher语法直接创建:
适用于数据量较小的情况。你可以直接编写Cypher语句来创建节点、关系和属性。
例如:CREATE (n:Person {name: '张三', age: 30}) 会创建一个名为“张三”的Person节点,并设置其age属性为30。
使用LOAD CSV导入数据:
如果你的数据是CSV格式的,你可以使用LOAD CSV语句将数据导入Neo4j。
首先,确保CSV文件符合Neo4j的要求(如编码格式、字段分隔符等)。
然后,编写包含LOAD CSV的Cypher语句,指定CSV文件的路径,并定义如何创建节点和关系。
例如:LOAD CSV WITH HEADERS FROM "file:///your_data.csv" AS row CREATE (n:Person {name: row.name, age: toInteger(row.age)})。
使用neo4j-admin工具导入:
适用于大量数据的导入。neo4j-admin工具提供了高效的数据导入功能。
你需要按照工具的格式要求准备数据,然后使用命令行调用neo4j-admin进行导入。
使用编程语言导入数据:
如果你熟悉编程,可以使用Neo4j提供的Java API、Python驱动程序等,通过编程方式将数据导入Neo4j。
这通常涉及到连接到Neo4j数据库,然后执行相应的Cypher语句或操作来创建节点和关系。
使用ETL工具:
ETL(Extract, Transform, Load)工具可以帮助你从各种数据源中提取数据,进行必要的转换,然后加载到Neo4j中。
这通常需要一些配置和映射工作,但一旦设置完成,就可以自动化地导入数据。
使用第三方插件或工具:
有些第三方插件或工具提供了额外的数据导入功能,如APOC插件等。
你可以根据具体需求选择适合的插件或工具来导入数据。
在选择导入方法时,请考虑你的数据量、数据格式、导入频率以及你的技术栈和偏好。对于大量数据的导入,通常建议使用更高效的方法,如neo4j-admin工具或ETL工具。对于小量数据或需要灵活处理的情况,使用Cypher语法或编程语言可能更为方便。
2.
您上传的文件可以是多种格式,具体取决于您选择的数据导入方法以及您的具体需求。Neo4j支持多种数据格式的导入,包括但不限于以下几种常见的格式:
CSV格式:CSV(逗号分隔值)是一种通用的表格数据格式,非常适合用于存储结构化的数据。Neo4j提供了LOAD CSV语句,允许您直接从CSV文件中导入数据。此外,如果您使用py2neo等库,也可以方便地将CSV文件导入Neo4j。
JSON格式:JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人类阅读和编写,同时也易于机器解析和生成。Neo4j可以直接将JSON格式的数据导入为图结构。
GraphML格式:GraphML是一种用于表示图形数据的XML格式。如果您的数据已经是GraphML格式,那么可以直接导入Neo4j。
在选择文件格式时,请考虑您的数据来源、数据量和数据处理需求。如果您的数据已经是上述某种格式,那么可以直接使用该格式进行导入。如果需要进行数据转换或处理,您可能需要使用编程语言或ETL工具将数据转换为适当的格式。
此外,无论使用哪种格式,都需要确保数据的完整性和准确性,以及符合Neo4j的导入要求。例如,CSV文件需要符合特定的编码和格式要求,JSON文件需要具有正确的结构和键值对等。
最后,根据您的具体需求和使用的导入方法,您可能需要编写一些自定义的脚本或语句来处理数据导入过程中的特定问题。
3.
将 JSON 文件导入 Neo4j 的方法取决于您使用的具体工具和 Neo4j 的版本。Neo4j 本身并不直接支持从 JSON 文件导入数据。通常,您需要使用 Cypher 查询语言或其他工具/插件来解析 JSON 并将其转换为图结构。
以下是一些可能的方法:
使用 APOC 插件:APOC 是一个流行的 Neo4j 插件,它提供了许多有用的功能和过程,包括处理 JSON 数据。如果您已经安装了 APOC,您可以使用其提供的函数来解析和导入 JSON 数据。
编写自定义脚本:您可以使用 Python、Java 或其他语言编写一个脚本,该脚本读取 JSON 文件,解析其内容,并使用 Neo4j 驱动程序(如 Neo4j Driver for Python 或 Neo4j Java Driver)将数据作为 Cypher 语句发送到 Neo4j 数据库。
转换为 CSV 并导入:如果您熟悉 CSV 格式并且数据量适中,您可以考虑将 JSON 数据转换为 CSV 格式,然后使用 Neo4j 的 LOAD CSV 功能将数据导入图数据库。
使用第三方工具:有些第三方工具可能支持直接从 JSON 文件导入数据到 Neo4j。您可以查找并评估这些工具,看看是否有适合您需求的。
请注意,无论您选择哪种方法,都需要确保您的 JSON 数据结构与您的图模型相匹配,并且正确地映射了节点、关系和属性。
4.
在Neo4j中,如果你收到错误消息“Create node with labels 'Person' on database 'companies' is not allowed for user 'companies' with roles [PUBLIC, companies]”,这意味着当前用户(在本例中是'companies'用户)没有足够的权限在'companies'数据库上创建带有'Person'标签的节点。
Neo4j支持基于角色的权限管理,以确保不同用户只能执行他们被授权的操作。在这种情况下,'companies'用户只拥有PUBLIC和companies这两个角色的权限,而这些权限可能不包括在'companies'数据库上创建特定标签的节点的能力。
要解决这个问题,你需要做以下几步:
登录为具有管理权限的用户:通常,这是neo4j超级用户,它拥有所有数据库的完全访问权限。
检查并修改用户权限:使用Cypher查询或Neo4j的管理界面来检查'companies'用户的当前权限,并根据需要修改它们。你可能需要给用户分配额外的角色或直接授予创建节点的权限。
例如,使用以下Cypher查询来查看用户的角色和权限:
cypher
SHOW GRANTS FOR USER 'companies';
要授予用户创建节点的权限,你可以使用类似以下的命令(这取决于你的具体需求和安全策略):
cypher
GRANT CREATE ON NODE Labels TO 'companies';
重新尝试操作:一旦权限被正确设置,'companies'用户应该能够在'companies'数据库上创建带有'Person'标签的节点了。
请注意,直接修改用户权限可能会带来安全风险,因此请确保你了解这些更改的含义,并遵循你的组织的安全最佳实践。如果你不确定如何操作,最好咨询你的数据库管理员或具有Neo4j管理经验的专业人员。
5.
在Neo4j中,如果你想授予用户在特定标签的节点上创建节点的权限,你应该使用以下格式的Cypher语句:
cypher
GRANT CREATE ON LABELS <label_name> TO <user_name>;
这里,<label_name> 是你想要授予创建权限的节点标签的名称,<user_name> 是你想要授予权限的用户的名称。注意,ON LABELS 而不是 ON NODE Labels 是正确的语法。
例如,如果你想给 'companies' 用户授予创建标签为 'Person' 的节点的权限,你应该这样写:
cypher
GRANT CREATE ON LABELS Person TO 'companies';
请确保将 'Person' 替换为你实际想要授予权限的标签名称,并且 'companies' 是正确的用户名。
如果你正在尝试为多个标签授予权限,你需要为每个标签单独执行 GRANT 语句,或者在一些Neo4j的版本中,可以使用逗号分隔标签名称:
cypher
GRANT CREATE ON LABELS Person, Employee TO 'companies';
请根据你的Neo4j版本和配置调整语句。如果你不确定版本或具体的语法,建议查阅对应版本的Neo4j官方文档。此外,请确保执行此操作的用户具有足够的权限来修改其他用户的权限。
6.
您提供的Cypher语句是有效的,用于在Neo4j数据库中创建一个新的节点,并给它赋予Person标签以及name和age两个属性。这里是完整的语句:
cypher
CREATE (n:Person {name: 'John Doe', age: 30})
这条语句做了以下几件事情:
CREATE:这是一个Cypher命令,用于在数据库中创建新的节点或关系。
(n:Person {name: 'John Doe', age: 30}):这定义了一个新节点n,并给它分配了Person标签。同时,它还设置了两个属性,name的值是'John Doe',age的值是30。
要执行这条语句,您需要:
确保您已经连接到Neo4j数据库。
打开Neo4j Browser(或您选择的任何Neo4j客户端)。
在命令输入框中输入上述Cypher语句。
执行该语句(通常是通过点击“运行”按钮或使用快捷键)。
如果一切正常,Neo4j将在数据库中创建一个新的Person节点,并且该节点将具有指定的属性。您可以使用MATCH和RETURN语句来检索并验证新创建的节点:
MATCH (n:Person {name: 'John Doe'})
RETURN n;
这条查询会找到所有标签为Person且name属性为'John Doe'的节点,并返回它们。如果您刚刚创建了该节点,那么应该只返回一个结果。





![[启明智显技术分享] 在ESP32环境搭建过程中,如果在VS Code中遇到乱码问题应该怎么解决](https://img-blog.csdnimg.cn/direct/67626088eb5048a7a777a454aa3d562f.png)