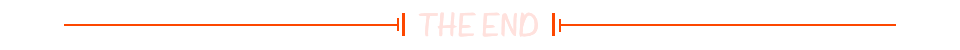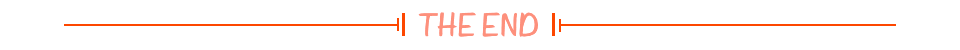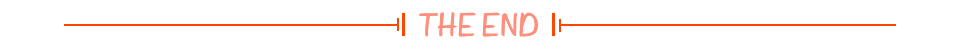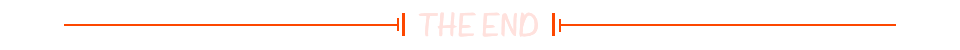一、k8s整体架构

二、k8s的作用,为什么要用k8s,以及服务器的发展历程
1、服务器:缺点容易浪费资源,且每个服务器都要装系统,且扩展迁移成本高
2、虚拟机很好地解决了服务器浪费资源的缺点,且部署快,成本低但每台虚拟机需要安装系统,从而对内存等资源造成了一定的浪费
3、容器恰好解决了虚拟机装系统浪费资源的缺点,也能很好地实现隔离,且一台机器上可以部署好多容器,但当机器出现宕机时,一台机器上的所有容器都会停止运行,不能自我修复
因此需要一个资源管理,资源编排的工具即k8s应用而生
三、k8s基本概念
1、pod
Pod本身是豌豆荚,为k8s的最小调度单元,里面会包含一个或多个容器(Container),Pod内的容器共享存储及网络,可通过localhost通信。

2、Deployment
pod 上层的一个抽象,它可以定义一组 Pod 的副本数目、以及这个 Pod 的版本。一般用 Deployment 来做应用的真正的管理,而 Pod 是组成 Deployment 最小的单元
- 定义一组Pod的副本数量,版本等;
- 通过控制器维护Pod的数目;
- 自动恢复失败的Pod;
- 通过控制器以指定的策略控制版本

3、Service
Pod是不稳定的,IP会发生变化,因此需要一层抽象来屏蔽这种变化,Service可以实现,其主要功能为:
- 提供访问一个或者多个Pod实例稳定的访问地址;
- 支持多种访问方式ClusterIP(对集群内部访问)NodePort(对集群外部访问)LoadBalancer(集群外部负载均衡)。

4、Volume
Volume表示存储卷,Pod访问文件系统的抽象层,具体的后端存储可以是本地存储、NFS网络存储、云存储以及分布式存储等。
- 声明在Pod中容器可以访问的文件系统;
- 可以被挂载在Pod中一个或多个容器的指定路径下;
- 支持多种后端储存

5、NameSpace
用以资源的逻辑隔离,上述小节均属于资源,不同ns下可以同名,相同ns下需唯一。
- 一个集群内部的逻辑隔离机制(鉴权、资源等);
- 每个资源都属于一个Namespace;
- 同一个Namespace中资源命名唯一;
- 不同Namespace中资源可重名;

6、Master组件

kube-apiserver:Kubernetes API,集群统一入口,各组件协调者,以RESTful API提供接口服务,所有对象的资源的增删改查和监听操作都交给APIServer处理后在提交给Etcd存储。
1)提供了集群管理的REST API接口(包括认证授权、数据校验以及集群状态变更);
2)提供其他模块之间的数据交互和通信的枢纽(其他模块通过API Server查询或修改数据,只有API Server才直接操作etcd);
3)是资源配额控制的入口;
controller-manager:是 Kubernetes 的大脑,它通过 apiserver 监控整个集群的状态,并确保集群处于预期的工作状态。
scheduler:scheduler 负责分配调度 Pod 到集群内的节点上,它监听 kube-apiserver,查询还未分配 Node 的 Pod,然后根据调度策略为这些 Pod 分配节点(更新 Pod 的 NodeName 字段)
工作原理:
kube-scheduler 调度分为两个阶段,predicate 和 priority
1)predicate:过滤不符合条件的节点
2)priority:优先级排序,选择优先级最高的节点
etcd:Etcd 是 CoreOS 基于 Raft 开发的分布式 key-value 存储,可用于服务发现、共享配置以及一致性保障(如数据库选主、分布式锁等)。etcd作为一个受到ZooKeeper与doozer启发而催生的项目,除了拥有与之类似的功能外,更专注于以下四点:
1)简单:基于HTTP+JSON的API让你用curl就可以轻松使用。
2)安全:可选SSL客户认证机制。
3)快速:每个实例每秒支持一千次写操作。
4)可信:使用Raft算法充分实现了分布式。
主要功能:
1)基本的 key-value 存储
2)监听机制
3)key 的过期及续约机制,用于监控和服务发现
4)原子性操作(CAS 和 CAD),用于分布式锁和 leader 选举
7、Node组件
kubelet:kubelet是Master在Node节点上的Agent,管理本机运行容器的生命周期,比如创建容器、Pod挂载数据卷、下载Secret、获取容器节点状态工作。kubelet将每个Pod转换成一组容器。
每个节点上都运行一个 kubelet 服务进程,默认监听 10250 端口,接收并执行 master 发来的指令,管理 Pod 及 Pod 中的容器。每个 kubelet 进程会在 API Server 上注册节点自身信息,定期向 master 节点汇报节点的资源使用情况,并通过 cAdvisor 监控节点和容器的资源。
kube-proxy:在node节点上实现Pod网络代理,维护网络规则和四层负载均衡工作。
每台机器上都运行一个 kube-proxy 服务,它监听 API server 中 service 和 endpoint 的变化情况,并通过 iptables 等来为服务配置负载均衡(仅支持 TCP 和 UDP)。
kube-proxy 可以直接运行在物理机上,也可以以 static pod 或者 daemonset 的方式运行。
docker或rocket:容器引擎,运行容器。

8、K8S创建一个Pod的流程
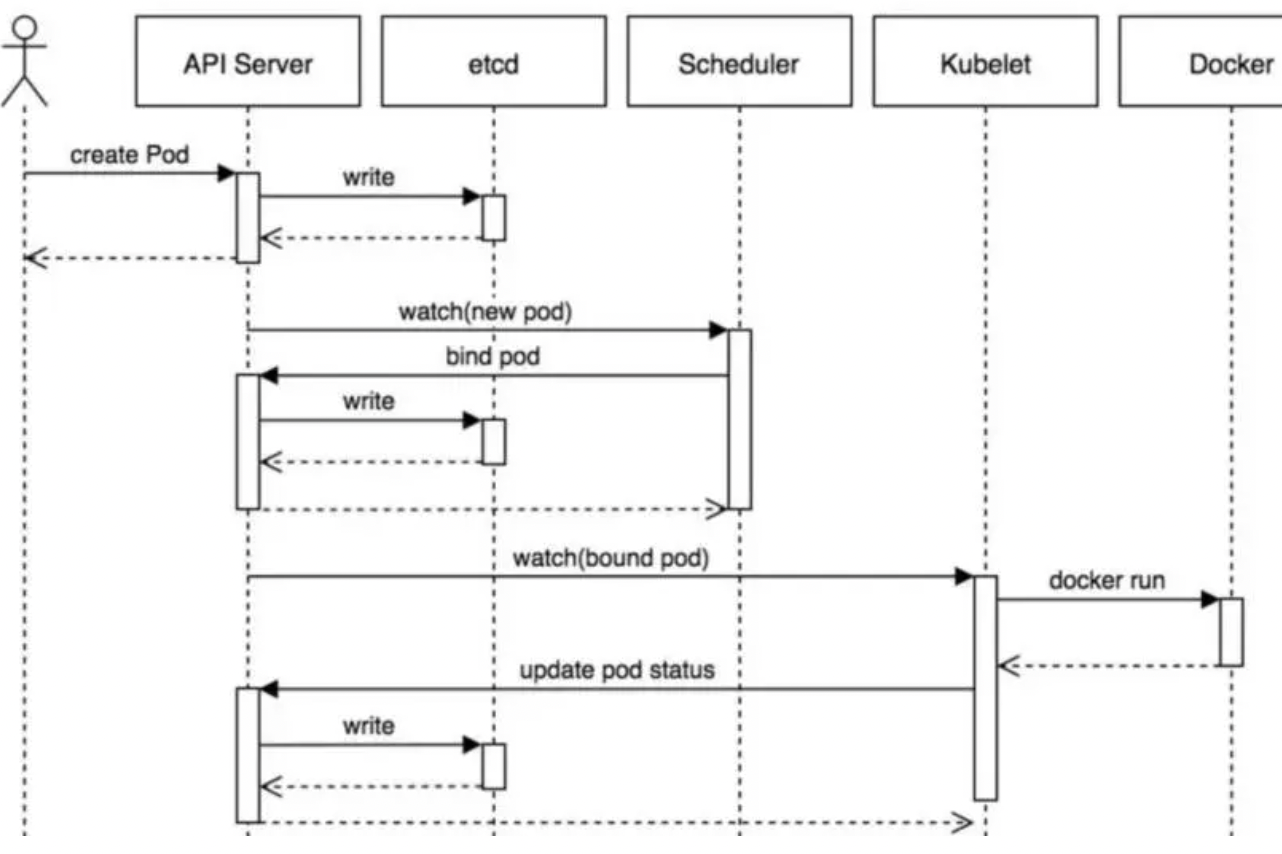
1、用户通过kubectl向api-server发起创建pod请求。
2、apiserver通过对应的kubeconfig进行认证,认证通过后将yaml中的po信息存到etcd。
3、Controller-Manager通过apiserver的watch接口发现了pod信息的更新,执行该资源所依赖的拓扑结构整合,整合后将对应的信息交给apiserver,apiserver写到etcd,此时pod已经可以被调度。4、Scheduler同样通过apiserver的watch接口更新到pod可以被调度,通过算法给pod分配节点,并将pod和对应节点绑定的信息交给apiserver,apiserver写到etcd,然后将pod交给kubelet。
5、kubelet收到pod后,调用CNI接口给pod创建pod网络,调用CRI接口去启动容器,调用CSI进行存储卷的挂载。
6、网络,容器,存储创建完成后pod创建完成,等业务进程启动后,pod运行成功。
流程图如下: