Hadoop的安装
1.拖拽安装包上传到/opt/software
2.解压文件到/opt/module
[itwise@node2 software]$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
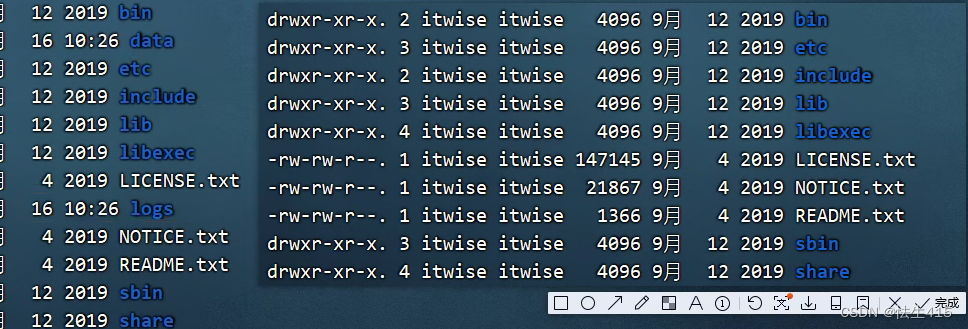
3查看文件
drwxr-xr-x. 2 itwise itwise 4096 9月 12 2019 bin
drwxr-xr-x. 3 itwise itwise 4096 9月 12 2019 etc
drwxr-xr-x. 2 itwise itwise 4096 9月 12 2019 include
drwxr-xr-x. 3 itwise itwise 4096 9月 12 2019 lib
drwxr-xr-x. 4 itwise itwise 4096 9月 12 2019 libexec
-rw-rw-r--. 1 itwise itwise 147145 9月 4 2019 LICENSE.txt
-rw-rw-r--. 1 itwise itwise 21867 9月 4 2019 NOTICE.txt
-rw-rw-r--. 1 itwise itwise 1366 9月 4 2019 README.txt
drwxr-xr-x. 3 itwise itwise 4096 9月 12 2019 sbin
drwxr-xr-x. 4 itwise itwise 4096 9月 12 2019 share
4.配置环境变量法
[itwise@node2 ~]$ sudo vim /etc/profile.d/my_env.sh
#HADOOP
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=:$PATH:$HADOOP_HOME/bin
export PATH=:$PATH:$HADOOP_HOME:/sbin
重置环境变量
[itwise@node2 ~]$ source /etc/profil
记得测试
5.HADOOP的配置文件修改

(1)hadoop_env.sh 默认目录,不需要修改
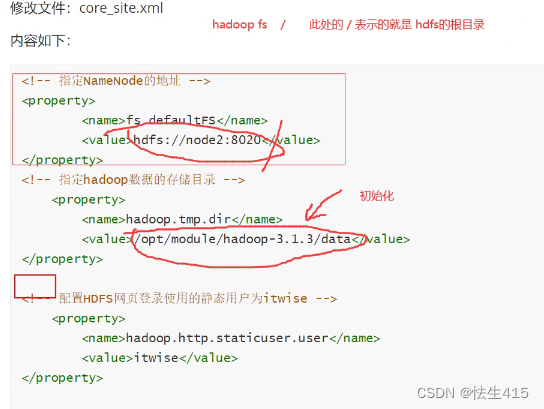
(2)修改配置文件core_site.xml
[itwise@node2 hadoop-3.1.3]$ cd etc/hadoop/
vim core-site.xml
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node2:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为itwise -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>itwise</value>
</property>
<!-- 配置该itwise(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.itwise.hosts</name>
<value>*</value>
</property>
<!-- 配置该itwise(superUser)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.itwise.groups</name>
<value>*</value>
</property>
<!-- 配置该itwise(superUser)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.itwise.users</name>
<value>*</value>
</property>
配置文件分析
(3)修改hdfs-site.xml
执行命令:
vim hdfs-site.xml
配置文件节点分配角色:
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>node2:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node4:9868</value>
</property>
<!-- 测试环境指定HDFS副本的数量1 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
(4)修改mapred-site.xml
执行命令:
vim mapred-site.xml
配置文件:
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
(5)yarn-site.xml
执行命令:
vim yarn-site.xml
配置文件:
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node3</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn容器允许管理的物理内存大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 关闭yarn对物理内存和虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
配置集群的信息1个:
修改workers
vim workers
录入内容如下:
node2
node3
node4
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
1.7 配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
修改mapred_site.xml
执行命令:
vim mapred-site.xml
录入内容
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node2:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node2:19888</value>
</property>
1.8 配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。
开启日志聚集功能具体步骤如下:
修改yarn_site.xml
执行命令
vim yarn-site.xml
录入内容
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node2:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
9同步分发文件**
将hadoop安装报和环境变量分发到 node3、node4节点上:
cd /opt/module
rsync.sh hadoop-3.1.3/
cd /etc/profile.d/
scp my_env.sh root@node3:$PWD
scp my_env.sh root@node4:$PWD
10重新加载环境
ssh node3 source /etc/profile
ssh node4 source /etc/profile
11验证环境变量
ssh node3 hadoop version
ssh node4 hadoop version
12启动集群:
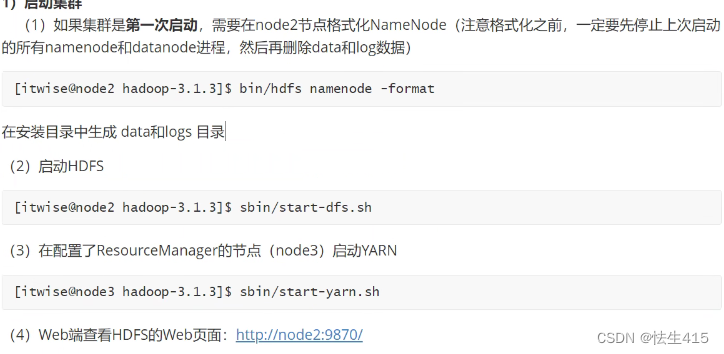
如果集群是第一次启动,需要在node2节点格式化NameNode(注意格式化之前,一定要先停止上次启动 的所有namenode和datanode进程,然后再删除data和log数据
初始化启动集群:
[itwise@node2 hadoop-3.1.3]$ bin/hdfs namenode -format
开启dfs node3 node4自动生产了目录
[itwise@node2 hadoop-3.1.3]$ sbin/start-dfs.sh
在resourceManage节点
[itwise@node2 hadoop-3.1.3]$ sbin/start-yarn.sh
e2 hadoop-3.1.3]$ bin/hdfs namenode -format
开启dfs node3 node4自动生产了目录
[itwise@node2 hadoop-3.1.3]$ sbin/start-dfs.sh
在resourceManage节点
[itwise@node2 hadoop-3.1.3]$ sbin/start-yarn.sh







![51 单片机[2-2]:LED闪烁](https://img-blog.csdnimg.cn/img_convert/31b43210cc0f152868ad4d19d8c3dfd0.png)