文章目录
- 简介
- 安装
- pipelines
- 图片转文本
- 文本生成
- 情感分析
- 零训练样本分类
- 遮盖词填充
- 命名实体识别
- 自动问答
- 自动摘要
- pipeline 背后做了什么?
- 使用分词器进行预处理
- 将预处理好的输入送入模型
- 对模型输出进行后处理
简介
Transformers 是由 Hugging Face 开发的一个 NLP 包,支持加载目前绝大部分的预训练模型。随着 BERT、GPT 等大规模语言模型的兴起,越来越多的公司和研究者采用 Transformers 库来构建 NLP 应用,官网地址。
它提供了各种预训练的 Transformer 模型,包括 BERT、GPT、RoBERTa、DistilBERT 等。这些模型在多个 NLP 任务上取得了 state-of-the-art 的性能,并且 Transformers 库提供了简单易用的接口,使得使用这些预训练模型变得非常便捷。
安装
官网安装教程参考:https://huggingface.co/docs/transformers/installation
您可以通过 pip 安装 Transformers 库。在终端或命令行界面中执行以下命令(我这里使用pytorch,如果需要tensorflow的版本参考官网):
pip install 'transformers[torch]'
这将会自动从 PyPI(Python Package Index)下载并安装最新版本的 Transformers 库及其依赖项。
如果您使用的是 Anaconda 环境,您也可以通过 conda 安装:
conda install -c huggingface transformers
这将会从 Anaconda 仓库中下载并安装 Transformers 库及其依赖项。
安装完成后,您就可以在 Python 环境中使用 Transformers 库了。您可以编写代码来加载预训练模型、执行各种 NLP 任务,或者使用 Transformers 提供的高级 API,如 pipelines 来快速完成任务。
pipelines
在 Hugging Face Transformers 中,pipelines 是一种方便的高级 API,用于执行各种自然语言处理(NLP)任务,如文本分类、命名实体识别、问答等。使用 pipelines,您无需编写大量的代码来加载模型、预处理输入数据、执行推理等操作,而是可以通过简单的函数调用来完成这些任务。
ransformers 库将目前的 NLP 任务归纳为几下几类:
- 文本分类:例如情感分析、句子对关系判断等;
- 对文本中的词语进行分类:例如词性标注 (POS)、命名实体识别 (NER) 等;
- 文本生成:例如填充预设的模板 (prompt)、预测文本中被遮掩掉 (masked) 的词语;
- 从文本中抽取答案:例如根据给定的问题从一段文本中抽取出对应的答案;
- 根据输入文本生成新的句子:例如文本翻译、自动摘要等。
Transformers 库最基础的对象就是 pipeline() 函数,它封装了预训练模型和对应的前处理和后处理环节。我们只需输入文本,就能得到预期的答案。目前常用的 pipelines 有:
- audio-classification(音频分类):用于对音频进行分类,识别音频中的类别或属性。
- automatic-speech-recognition(自动语音识别):用于将音频转换为文本,实现语音识别的功能。
- conversational(会话式处理):用于构建和处理对话系统,实现对话式交互的功能。
- depth-estimation(深度估计):用于从单张图片或视频中估计场景的深度信息。
- document-question-answering(文档问答):用于从文档中回答问题,帮助用户获取文档内容中的相关信息。
- feature-extraction(特征提取):用于从文本、图片等数据中提取特征,用于后续的任务或分析。
- fill-mask(填空):用于给定带有空白的句子,预测并填补空白处的单词或短语。
- image-classification(图片分类):用于对图片进行分类,识别图片中的类别或属性。
- image-feature-extraction(图片特征提取):用于从图片中提取特征,用于后续的任务或分析。
- image-segmentation(图片分割):用于将图片分割成不同的区域或对象,进行图像分割任务。
- image-to-image(图片到图片):用于执行图片到图片的转换,如图像风格转换、图像去噪等。
- image-to-text(图片到文本):用于从图片中提取文本信息,实现图片中的文字识别功能。
- mask-generation(遮罩生成):用于生成图片中的遮罩或掩码,用于图像处理或分割任务。
- object-detection(目标检测):用于从图片或视频中检测和识别出图像中的目标对象。
- question-answering(问答):用于回答给定问题的模型,从文本中找出包含答案的部分。
- summarization(摘要生成):用于生成文本的摘要或总结,将文本内容压缩为简短的形式。
- table-question-answering(表格问答):用于从表格数据中回答问题,帮助用户从表格中获取信息。
- text2text-generation(文本到文本生成):用于生成文本的模型,可以执行文本到文本的转换或生成任务。
- text-classification(文本分类):(别名"sentiment-analysis" 可用,情感分析)用于将文本进行分类,识别文本中的类别或属性。
- text-generation(文本生成):用于生成文本的模型,可以生成连续的文本序列。
- text-to-audio(文本到音频):用于将文本转换为语音,实现文本到语音的功能。
- token-classification(标记分类):别名"ner" 可用,命名实体识别,用于将文本中的每个标记或单词进行分类,识别每个标记的类别或属性。
- translation(翻译):用于执行文本的翻译任务,将文本从一种语言翻译成另一种语言。
- video-classification(视频分类):用于对视频进行分类,识别视频中的类别或属性。
- visual-question-answering(视觉问答):用于从图片或视频中回答问题,结合视觉和文本信息进行问答。
- zero-shot-classification(零样本分类):用于执行零样本分类任务,即在没有见过该类别的情况下对新样本进行分类。
- zero-shot-image-classification(零样本图片分类):用于执行零样本分类任务,即在没有见过该类别的情况下对新图片进行分类。
- zero-shot-audio-classification(零样本音频分类):用于执行零样本分类任务,即在没有见过该类别的情况下对新音频进行分类。
- zero-shot-object-detection(零样本目标检测):用于执行零样本目标检测任务,即在没有见过该类别的情况下对新图片中的目标对象进行检测。
如果需要了解更多的task类型更新,参考官网pipeline:
下面我们以常见的几个 NLP 任务为例,展示如何调用这些 pipeline 模型。
图片转文本
教程参考自官网:https://huggingface.co/docs/transformers/v4.40.2/en/main_classes/pipelines#transformers.ImageToTextPipeline

from transformers import pipeline
itt=pipeline("image-to-text",model="ydshieh/vit-gpt2-coco-en") #model不指定会使用默认模型。
rtn=itt("https://huggingface.co/datasets/Narsil/image_dummy/raw/main/parrots.png")
print(rtn)
可以看到输出是需要先下载模型(下载一次,自动缓存),下载在C:\Users\admin.cache\huggingface\hub目录下。
:\python\evn311\Lib\site-packages\huggingface_hub\file_download.py:157: UserWarning: `huggingface_hub` cache-system uses symlinks by default to efficiently store duplicated files but your machine does not support them in C:\Users\admin\.cache\huggingface\hub\models--ydshieh--vit-gpt2-coco-en. Caching files will still work but in a degraded version that might require more space on your disk. This warning can be disabled by setting the `HF_HUB_DISABLE_SYMLINKS_WARNING` environment variable. For more details, see https://huggingface.co/docs/huggingface_hub/how-to-cache#limitations.
To support symlinks on Windows, you either need to activate Developer Mode or to run Python as an administrator. In order to see activate developer mode, see this article: https://docs.microsoft.com/en-us/windows/apps/get-started/enable-your-device-for-development
warnings.warn(message)
最后输出:[{‘generated_text’: 'two birds are standing next to each other '}]
如果希望使用其他的image-to-text模型可以在官网搜索
https://huggingface.co/models?pipeline_tag=image-to-text&sort=trending
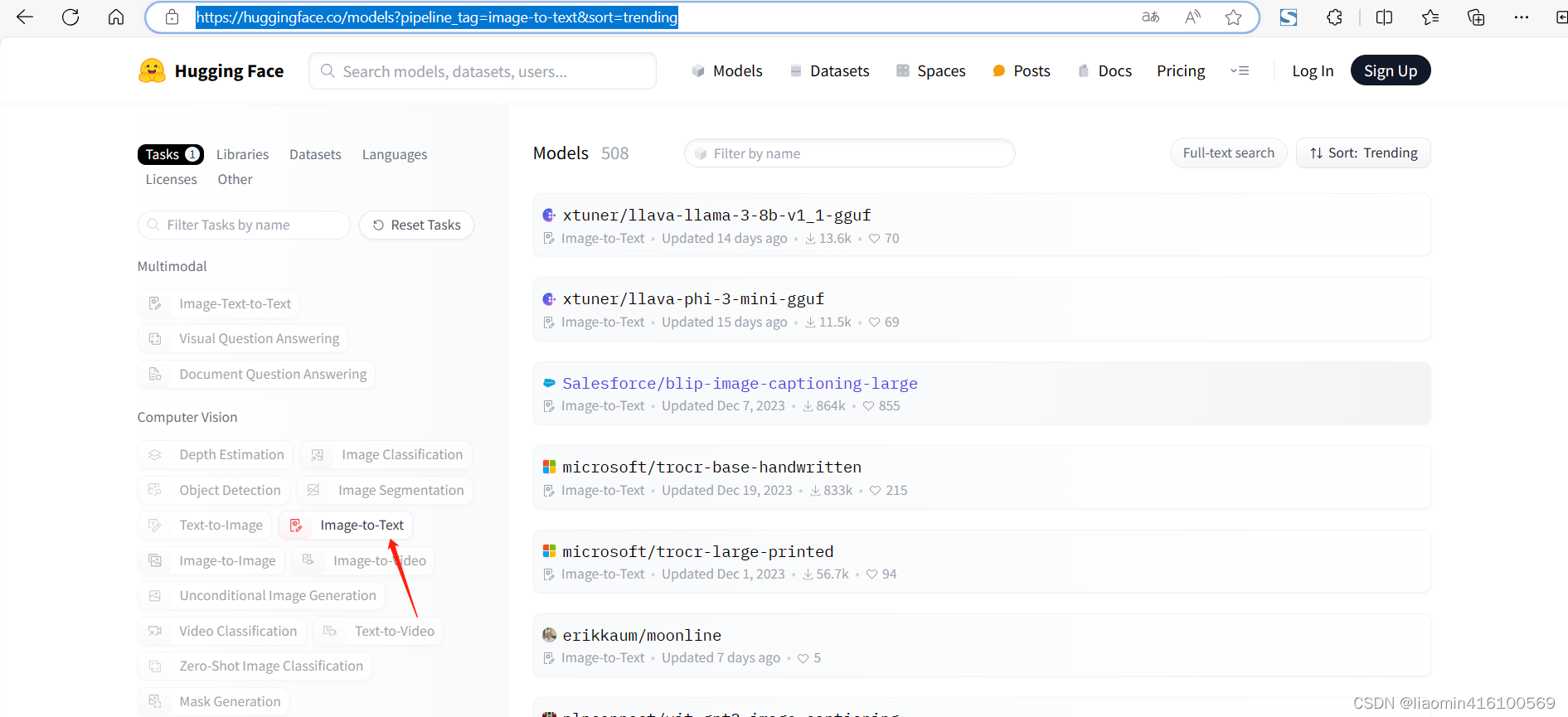
比如选择image-to-text右侧文本框输入chinese,看下是不是有中文描述的
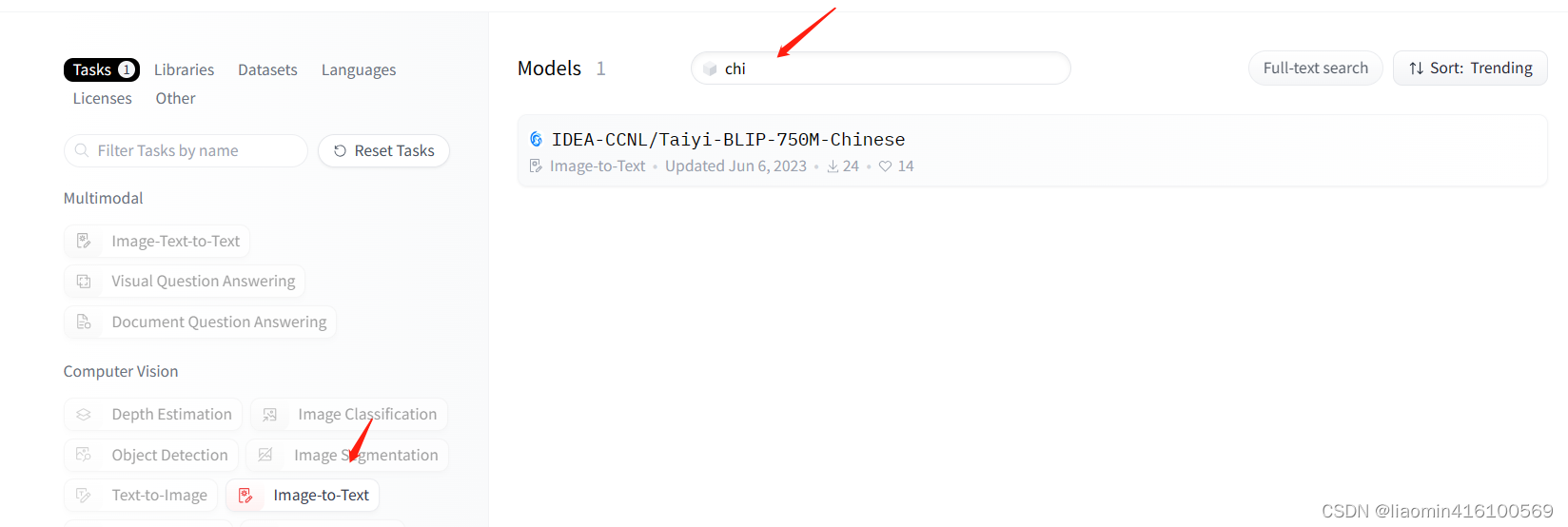
使用这个模型来测试下
image_path="https://huggingface.co/datasets/Narsil/image_dummy/raw/main/parrots.png"
from transformers import pipeline
itt=pipeline("image-to-text",model="IDEA-CCNL/Taiyi-BLIP-750M-Chinese")
rtn=itt(image_path)
print(rtn)
输出(效果没有英文的模型好,明明是两只鹦鹉啊,不过识别出了鹦鹉,英文的只是两只鸟)
[{‘generated_text’: ‘一 只 鹦 鹉 的 黑 白 照 片 。’}]
文本生成
我们首先根据任务需要构建一个模板 (prompt),然后将其送入到模型中来生成后续文本。注意,由于文本生成具有随机性,因此每次运行都会得到不同的结果。
#%%
from transformers import pipeline
generator = pipeline("text-generation",model="openai-community/gpt2")
print(generator("I can't believe you did such a "))
输出:
[{'generated_text': 'I can\'t believe you did such a _____t!"\n\n"You know I\'m kind of an asshole to you, I mean?"\n\n"Just because I had one thing to do doesn\'t mean I hate you. I know you'}]
在huggerface上搜索一个古诗词生成的模型,
左侧选择tag Text Generation ,搜索poem,选择最多人喜欢。
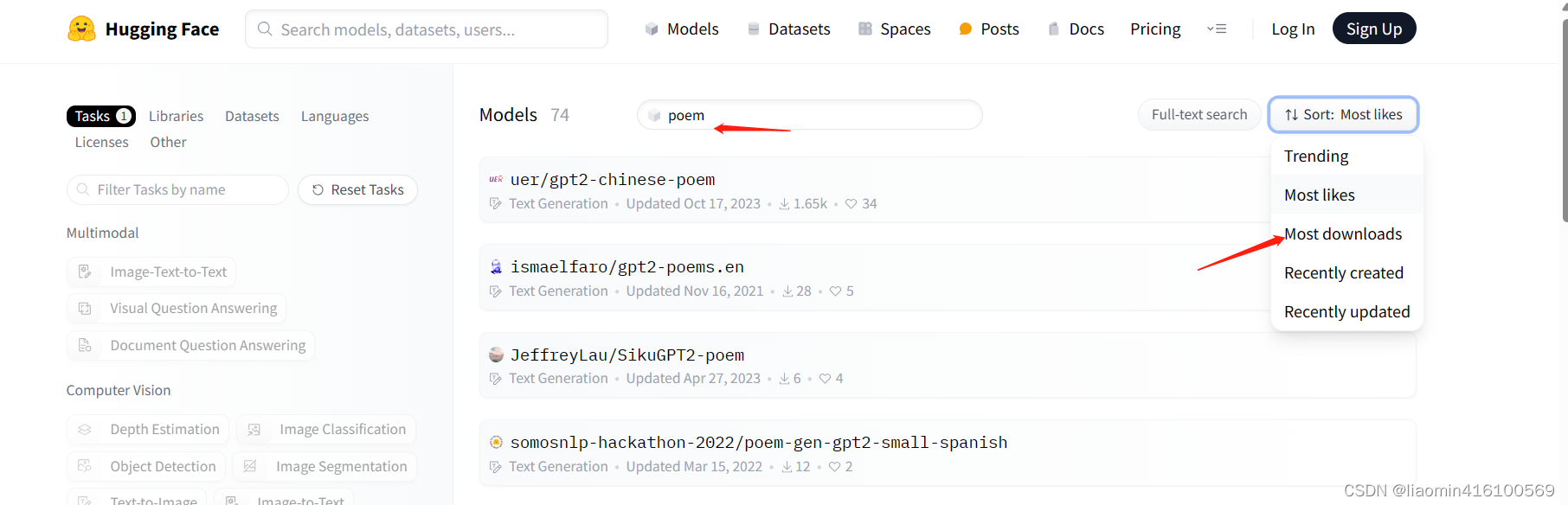
from transformers import pipeline
generator = pipeline("text-generation",model="uer/gpt2-chinese-poem")
print(generator("[CLS] 离 离 原 上 草 ,"))
输出
[{'generated_text': '[CLS] 离 离 原 上 草 , 濯 濯 原 上 桑 。 春 风 吹 罗 衣 , 行 人 泪 成 行 。 离 人 不 可 留 , 况 乃 隔 河 梁 。 当 和 露 餐 , 勿 复 怨 秋 凉 。 愿 言 崇 令 德 , 以 配 君 子 光 。 毋 怀 远 心 , 皓 月 鉴 我 伤 。 莫 怨 东 风 , 飘 然 入 西 楼 。 举 手 倚 阑 干 , 举 酒 相 劝 酬 。 良 时 焉 可 再 , 逝 水 何 悠 悠 。 我 金 石 交 , 沉 邈 焉 能 求'}]
情感分析
借助情感分析 pipeline,我们只需要输入文本,就可以得到其情感标签(积极/消极)以及对应的概率:
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
result = classifier("I've been waiting for a HuggingFace course my whole life.")
print(result)
results = classifier(
["I've been waiting for a HuggingFace course my whole life.", "I hate this so much!"]
)
print(results)
No model was supplied, defaulted to distilbert-base-uncased-finetuned-sst-2-english (https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english)
[{'label': 'POSITIVE', 'score': 0.9598048329353333}]
[{'label': 'POSITIVE', 'score': 0.9598048329353333}, {'label': 'NEGATIVE', 'score': 0.9994558691978455}]
pipeline 模型会自动完成以下三个步骤:
- 将文本预处理为模型可以理解的格式;
- 将预处理好的文本送入模型;
- 对模型的预测值进行后处理,输出人类可以理解的格式。
pipeline 会自动选择合适的预训练模型来完成任务。例如对于情感分析,默认就会选择微调好的英文情感模型 distilbert-base-uncased-finetuned-sst-2-english。
Transformers 库会在创建对象时下载并且缓存模型,只有在首次加载模型时才会下载,后续会直接调用缓存好的模型。
零训练样本分类
零训练样本分类 pipeline 允许我们在不提供任何标注数据的情况下自定义分类标签。
from transformers import pipeline
classifier = pipeline("zero-shot-classification")
result = classifier(
"This is a course about the Transformers library",
candidate_labels=["education", "politics", "business"],
)
print(result)
No model was supplied, defaulted to facebook/bart-large-mnli (https://huggingface.co/facebook/bart-large-mnli)
{'sequence': 'This is a course about the Transformers library',
'labels': ['education', 'business', 'politics'],
'scores': [0.8445973992347717, 0.11197526752948761, 0.043427325785160065]}
可以看到,pipeline 自动选择了预训练好的 facebook/bart-large-mnli 模型来完成任务。
遮盖词填充
给定一段部分词语被遮盖掉 (masked) 的文本,使用预训练模型来预测能够填充这些位置的词语。
from transformers import pipeline
unmasker = pipeline("fill-mask")
results = unmasker("This course will teach you all about <mask> models.", top_k=2)
print(results)
No model was supplied, defaulted to distilroberta-base (https://huggingface.co/distilroberta-base)
[{'sequence': 'This course will teach you all about mathematical models.',
'score': 0.19619858264923096,
'token': 30412,
'token_str': ' mathematical'},
{'sequence': 'This course will teach you all about computational models.',
'score': 0.04052719101309776,
'token': 38163,
'token_str': ' computational'}]
可以看到,pipeline 自动选择了预训练好的 distilroberta-base 模型来完成任务。
命名实体识别
命名实体识别 (NER) pipeline 负责从文本中抽取出指定类型的实体,例如人物、地点、组织等等。
from transformers import pipeline
ner = pipeline("ner", grouped_entities=True)
results = ner("My name is Sylvain and I work at Hugging Face in Brooklyn.")
print(results)
No model was supplied, defaulted to dbmdz/bert-large-cased-finetuned-conll03-english (https://huggingface.co/dbmdz/bert-large-cased-finetuned-conll03-english)
[{'entity_group': 'PER', 'score': 0.9981694, 'word': 'Sylvain', 'start': 11, 'end': 18},
{'entity_group': 'ORG', 'score': 0.97960186, 'word': 'Hugging Face', 'start': 33, 'end': 45},
{'entity_group': 'LOC', 'score': 0.99321055, 'word': 'Brooklyn', 'start': 49, 'end': 57}]
可以看到,模型正确地识别出了 Sylvain 是一个人物,Hugging Face 是一个组织,Brooklyn 是一个地名。
这里通过设置参数
grouped_entities=True,使得 pipeline 自动合并属于同一个实体的多个子词 (token),例如这里将“Hugging”和“Face”合并为一个组织实体,实际上 Sylvain 也进行了子词合并,因为分词器会将 Sylvain 切分为S、##yl、##va和##in四个 token。
自动问答
自动问答 pipeline 可以根据给定的上下文回答问题,例如:
from transformers import pipeline
question_answerer = pipeline("question-answering")
answer = question_answerer(
question="Where do I work?",
context="My name is Sylvain and I work at Hugging Face in Brooklyn",
)
print(answer)
No model was supplied, defaulted to distilbert-base-cased-distilled-squad (https://huggingface.co/distilbert-base-cased-distilled-squad)
{'score': 0.6949771046638489, 'start': 33, 'end': 45, 'answer': 'Hugging Face'}
可以看到,pipeline 自动选择了在 SQuAD 数据集上训练好的 distilbert-base 模型来完成任务。这里的自动问答 pipeline 实际上是一个抽取式问答模型,即从给定的上下文中抽取答案,而不是生成答案。
根据形式的不同,自动问答 (QA) 系统可以分为三种:
- **抽取式 QA (extractive QA):**假设答案就包含在文档中,因此直接从文档中抽取答案;
- **多选 QA (multiple-choice QA):**从多个给定的选项中选择答案,相当于做阅读理解题;
- **无约束 QA (free-form QA):**直接生成答案文本,并且对答案文本格式没有任何限制。
自动摘要
自动摘要 pipeline 旨在将长文本压缩成短文本,并且还要尽可能保留原文的主要信息,例如:
from transformers import pipeline
summarizer = pipeline("summarization")
results = summarizer(
"""
America has changed dramatically during recent years. Not only has the number of
graduates in traditional engineering disciplines such as mechanical, civil,
electrical, chemical, and aeronautical engineering declined, but in most of
the premier American universities engineering curricula now concentrate on
and encourage largely the study of engineering science. As a result, there
are declining offerings in engineering subjects dealing with infrastructure,
the environment, and related issues, and greater concentration on high
technology subjects, largely supporting increasingly complex scientific
developments. While the latter is important, it should not be at the expense
of more traditional engineering.
Rapidly developing economies such as China and India, as well as other
industrial countries in Europe and Asia, continue to encourage and advance
the teaching of engineering. Both China and India, respectively, graduate
six and eight times as many traditional engineers as does the United States.
Other industrial countries at minimum maintain their output, while America
suffers an increasingly serious decline in the number of engineering graduates
and a lack of well-educated engineers.
"""
)
print(results)
No model was supplied, defaulted to sshleifer/distilbart-cnn-12-6 (https://huggingface.co/sshleifer/distilbart-cnn-12-6)
[{'summary_text': ' America has changed dramatically during recent years . The number of engineering graduates in the U.S. has declined in traditional engineering disciplines such as mechanical, civil, electrical, chemical, and aeronautical engineering . Rapidly developing economies such as China and India, as well as other industrial countries in Europe and Asia, continue to encourage and advance engineering .'}]
可以看到,pipeline 自动选择了预训练好的 distilbart-cnn-12-6 模型来完成任务。与文本生成类似,我们也可以通过 max_length 或 min_length 参数来控制返回摘要的长度。
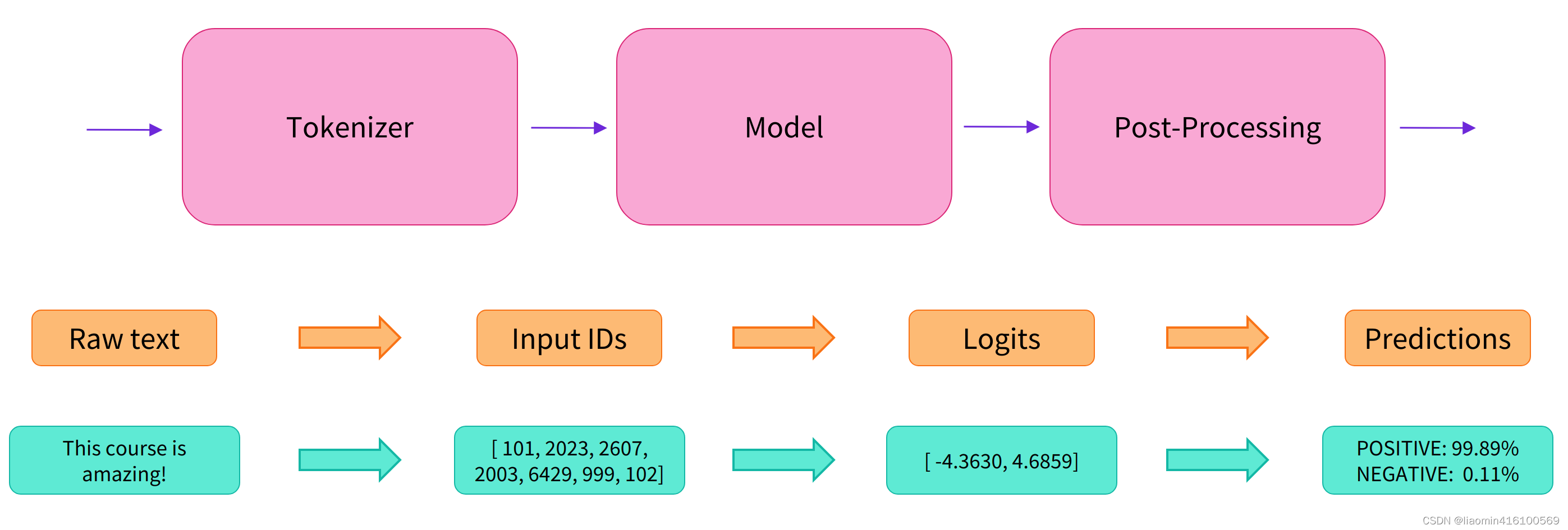
pipeline 背后做了什么?
这些简单易用的 pipeline 模型实际上封装了许多操作,下面我们就来了解一下它们背后究竟做了啥。以第一个情感分析 pipeline 为例,我们运行下面的代码
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
result = classifier("This course is amazing!")
print(result)
就会得到结果:
[{'label': 'POSITIVE', 'score': 0.9998824596405029}]
实际上它的背后经过了三个步骤:
- 预处理 (preprocessing),将原始文本转换为模型可以接受的输入格式;
- 将处理好的输入送入模型;
- 对模型的输出进行后处理 (postprocessing),将其转换为人类方便阅读的格式。
使用分词器进行预处理
因为神经网络模型无法直接处理文本,因此首先需要通过预处理环节将文本转换为模型可以理解的数字。具体地,我们会使用每个模型对应的分词器 (tokenizer) 来进行:
- 将输入切分为词语、子词或者符号(例如标点符号),统称为 tokens;
- 根据模型的词表将每个 token 映射到对应的 token 编号(就是一个数字);
- 根据模型的需要,添加一些额外的输入。
我们对输入文本的预处理需要与模型自身预训练时的操作完全一致,只有这样模型才可以正常地工作。注意,每个模型都有特定的预处理操作,如果对要使用的模型不熟悉,可以通过 Model Hub 查询。这里我们使用 AutoTokenizer 类和它的 from_pretrained() 函数,它可以自动根据模型 checkpoint 名称来获取对应的分词器。
情感分析 pipeline 的默认 checkpoint 是 distilbert-base-uncased-finetuned-sst-2-english,下面我们手工下载并调用其分词器:
from transformers import AutoTokenizer
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
print(inputs)
{
'input_ids': tensor([
[ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102],
[ 101, 1045, 5223, 2023, 2061, 2172, 999, 102, 0, 0,
0, 0, 0, 0, 0, 0]
]),
'attention_mask': tensor([
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]
])
}
可以看到,输出中包含两个键 input_ids 和 attention_mask,其中 input_ids 对应分词之后的 tokens 映射到的数字编号列表,而 attention_mask 则是用来标记哪些 tokens 是被填充的(这里“1”表示是原文,“0”表示是填充字符)。
先不要关注
padding、truncation这些参数,以及attention_mask项,后面我们会详细介绍:)。
将预处理好的输入送入模型
预训练模型的下载方式和分词器 (tokenizer) 类似,Transformers 包提供了一个 AutoModel 类和对应的 from_pretrained() 函数。下面我们手工下载这个 distilbert-base 模型:
from transformers import AutoModel
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModel.from_pretrained(checkpoint)
预训练模型的本体只包含基础的 Transformer 模块,对于给定的输入,它会输出一些神经元的值,称为 hidden states 或者特征 (features)。对于 NLP 模型来说,可以理解为是文本的高维语义表示。这些 hidden states 通常会被输入到其他的模型部分(称为 head),以完成特定的任务,例如送入到分类头中完成文本分类任务。
其实前面我们举例的所有 pipelines 都具有类似的模型结构,只是模型的最后一部分会使用不同的 head 以完成对应的任务。
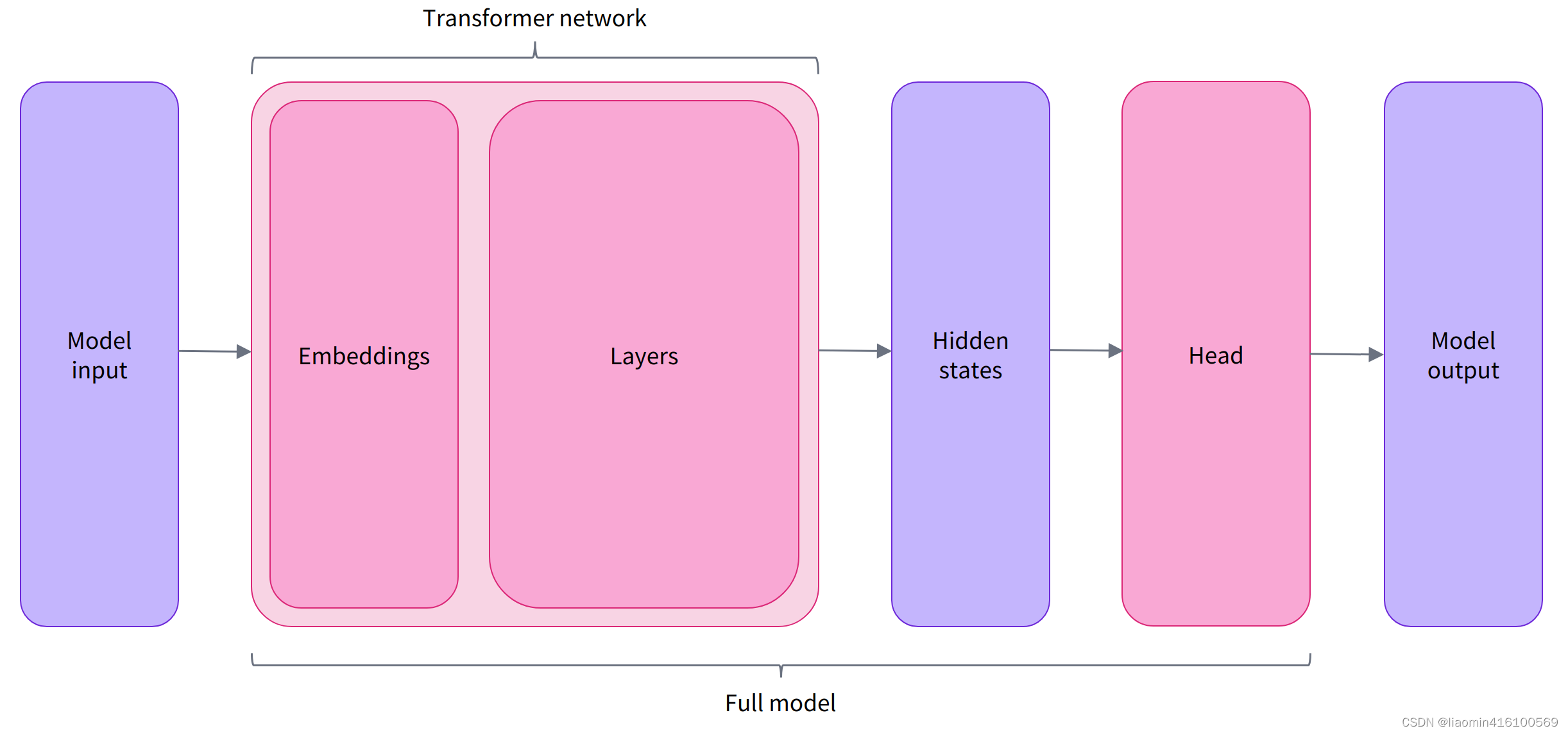
Transformers 库封装了很多不同的结构,常见的有:
*Model(返回 hidden states)*ForCausalLM(用于条件语言模型)*ForMaskedLM(用于遮盖语言模型)*ForMultipleChoice(用于多选任务)*ForQuestionAnswering(用于自动问答任务)*ForSequenceClassification(用于文本分类任务)*ForTokenClassification(用于 token 分类任务,例如 NER)
Transformer 模块的输出是一个维度为 (Batch size, Sequence length, Hidden size) 的三维张量,其中 Batch size 表示每次输入的样本(文本序列)数量,即每次输入多少个句子,上例中为 2;Sequence length 表示文本序列的长度,即每个句子被分为多少个 token,上例中为 16;Hidden size 表示每一个 token 经过模型编码后的输出向量(语义表示)的维度。
预训练模型编码后的输出向量的维度通常都很大,例如 Bert 模型 base 版本的输出为 768 维,一些大模型的输出维度为 3072 甚至更高。
我们可以打印出这里使用的 distilbert-base 模型的输出维度:
from transformers import AutoTokenizer, AutoModel
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModel.from_pretrained(checkpoint)
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
outputs = model(**inputs)
print(outputs.last_hidden_state.shape)
torch.Size([2, 16, 768])
Transformers 模型的输出格式类似 namedtuple 或字典,可以像上面那样通过属性访问,也可以通过键(outputs["last_hidden_state"]),甚至索引访问(outputs[0])。
对于情感分析任务,很明显我们最后需要使用的是一个文本分类 head。因此,实际上我们不会使用 AutoModel 类,而是使用 AutoModelForSequenceClassification:
from transformers import AutoTokenizer
from transformers import AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
outputs = model(**inputs)
print(outputs.logits.shape)
torch.Size([2, 2])
可以看到,对于 batch 中的每一个样本,模型都会输出一个两维的向量(每一维对应一个标签,positive 或 negative)。
对模型输出进行后处理
由于模型的输出只是一些数值,因此并不适合人类阅读。例如我们打印出上面例子的输出:
from transformers import AutoTokenizer
from transformers import AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
raw_inputs = [
"I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt")
outputs = model(**inputs)
print(outputs.logits)
tensor([[-1.5607, 1.6123],
[ 4.1692, -3.3464]], grad_fn=<AddmmBackward0>)
模型对第一个句子输出 [−1.5607,1.6123],对第二个句子输出 [4.1692,−3.3464],它们并不是概率值,而是模型最后一层输出的 logits 值。要将他们转换为概率值,还需要让它们经过一个 SoftMax 层,例如:
import torch
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print(predictions)
tensor([[4.0195e-02, 9.5980e-01],
[9.9946e-01, 5.4418e-04]], grad_fn=<SoftmaxBackward0>)
所有 Transformers 模型都会输出 logits 值,因为训练时的损失函数通常会自动结合激活函数(例如 SoftMax)与实际的损失函数(例如交叉熵 cross entropy)。
这样模型的预测结果就是容易理解的概率值:第一个句子 [0.0402,0.9598],第二个句子 [0.9995,0.0005]。最后,为了得到对应的标签,可以读取模型 config 中提供的 id2label 属性:
print(model.config.id2label)
{0: 'NEGATIVE', 1: 'POSITIVE'}
于是我们可以得到最终的预测结果:
- 第一个句子: NEGATIVE: 0.0402, POSITIVE: 0.9598
- 第二个句子: NEGATIVE: 0.9995, POSITIVE: 0.0005
本文部分文本引用自:https://transformers.run/